

本文为您介绍使用Tunnel命令过程中的常见问题。
Tunnel Upload是否支持通配符或正则表达式?
使用Tunnel Upload命令上传数据时,不支持通配符或正则表达式。
Tunnel Upload对文件大小是否有限制?记录大小是否有限制?是否要使用压缩?
使用Tunnel Upload命令上传文件时,对文件大小没有限制,但一次上传时长不能超过2小时。您可以根据实际上传速度和时间估算能够上传的数据量。
记录大小不能超过200 MB。
Tunnel Upload默认会使用压缩,如果带宽允许的情况下,可以通过
-cp
参数关掉压缩。
同一个表或分区是否可以并行上传数据?
可以并行上传。
是否支持多个客户端同时上传数据至同一张表?
支持。
使用Tunnel Upload命令上传数据时一定要先存在分区吗?
是的,Tunnel命令不会自动创建分区。
Tunnel Upload是追加还是覆盖模式?
追加模式。
使用Tunnel Upload命令上传数据时,如何实现覆盖重写的功能?
Tunnel只提供追加的插入方式,如果用户需要覆盖重写,请先删除分区里的数据后再插入数据。
-
如果表是分区表,可以使用
alter table table_name drop [if exists] partition partition_spec;命令。 -
如果是非分区表,可以使用
truncate table table_name;命令。
使用Tunnel Upload命令上传数据时,是按照数据压缩前还是压缩后的大小计费?
按照压缩后的大小进行计费。
使用Tunnel Upload命令上传数据时,是否支持限速?
不支持限速。
使用Tunnel Upload命令上传数据时,速度太慢,如何解决?
如果上传数据太慢,可以考虑使用
-threads
参数将数据切片上传,例如将文件切分为10片上传。命令示例如下。
tunnel upload C:\userlog.txt userlog1 -threads 10 -s false -fd "\u0000" -rd "\n";使用Tunnel Upload命令上传数据时,设置了经典网络的Endpoint,但为什么会连接到外网的Tunnel Endpoint?
MaxCompute客户端的配置文件 odps_config.ini 中除了Endpoint之外还需要配置Tunnel Endpoint。请根据 Endpoint 进行配置。目前只有华东2(上海)区域不需要设置Tunnel Endpoint。
在DataStudio上执行Tunnel Upload命令上传分区数据时报错,如何解决?
-
问题现象
在DataStudio上执行Tunnel Upload命令上传分区数据时,返回报错如下。
FAILED: error occurred while running tunnel command. -
产生原因
DataStudio不支持Tunnel Upload命令。
-
解决措施
根据DataWorks提供的可视化导入数据功能进行操作,请参见 上传数据 。
使用Tunnel Upload命令上传数据时,如果数据中有回车或空格,为什么上传会失败?
如果数据中有回车或空格,可以给数据设置不同于回车或空格的分隔符后,用
-rd
和
-fd
指定对应的分隔符实现数据的上传。如果无法更换数据中的分隔符,可以将数据作为单独一行上传,然后使用UDF解析。
如下示例数据中包含回车,使用
“,”
作为列分隔符
-rd
,使用
“@”
作为行分隔符
-fd
,可以正常上传。
shopx,x_id,100@
shopy,y_id,200@
shopz,z_id,300@上传命令示例如下。
tunnel upload d:\data.txt sale_detail/sale_date=201312,region=hangzhou -s false -fd "," -rd "@";上传结果如下。
+-----------+-------------+-------------+-----------+--------+
| shop_name | customer_id | total_price | sale_date | region |
+-----------+-------------+-------------+-----------+--------+
| shopx | x_id | 100.0 | 201312 | hangzhou |
| shopy | y_id | 200.0 | 201312 | hangzhou |
| shopz | z_id | 300.0 | 201312 | hangzhou |
+-----------+-------------+-------------+-----------+--------+使用Tunnel Upload命令上传数据时,提示内存溢出,如何解决?
Tunnel Upload命令支持上传海量数据,如果出现内存溢出,可能是因为数据的行分隔符和列分隔符设置错误,导致整个文本被认为是同一条数据,全部缓存至内存中,导致内存溢出报错。
这种情况下可以先用少量的数据进行测试,当
-td
及
-fd
调试成功后再上传全量数据。
使用Tunnel Upload命令上传数据时,需要上传很多数据文件到一个表中,是否有方法写一个脚本就可以把文件夹下的所有数据文件上传上去?
Tunnel Upload命令支持文件或目录(指一级目录)的上传,详情请参见 Tunnel使用说明 。
例如执行如下命令上传文件夹 d:\data 下的所有数据。
tunnel upload d:\data sale_detail/sale_date=201312,region=hangzhou -s false;使用Tunnel Upload命令上传数据时,如何实现批量上传一个目录下的多个文件到同一张表,并且每个文件放在不同的分区内?
您可以利用Shell脚本实现,以在Windows环境下配合MaxCompute客户端使用Shell脚本为例,Linux环境下原理相同,Shell脚本内容如下。
#!/bin/sh
C:/odpscmd_public/bin/odpscmd.bat -e "create table user(data string) partitioned by (dt int);" //首先创建一个分区表user,分区关键字为dt,本例中MaxCompute客户端的安装路径为C:/odpscmd_public/bin/odpscmd.bat,您可以根据您的实际环境调整路径。
dir=$(ls C:/userlog) //定义变量dir,为存放文件的文件夹下所有文件的名称。
pt=0 //变量pt用于作为分区值,初始为0,每上传好一个文件+1,从而实现每个文件都存放在不同的分区。
for i in $dir //定义循环,遍历文件夹C:/userlog下的所有文件。
let pt=pt+1 //每次循环结束,变量pt+1。
echo $i //显示文件名称。
echo $pt //显示分区名称。
C:/odpscmd_public/bin/odpscmd.bat -e "alter table user add partition (dt=$pt);tunnel upload C:/userlog/$i user/dt=$pt -s false -fd "%" -rd "@";" //利用odpscmd首先添加分区,然后向分区中上传文件。
done
实际运行Shell脚本效果如下,本例中以两个文件userlog1及userlog2举例。
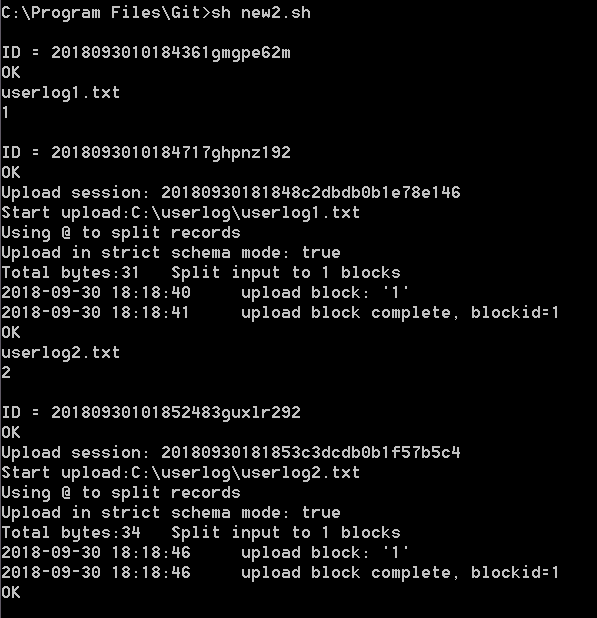
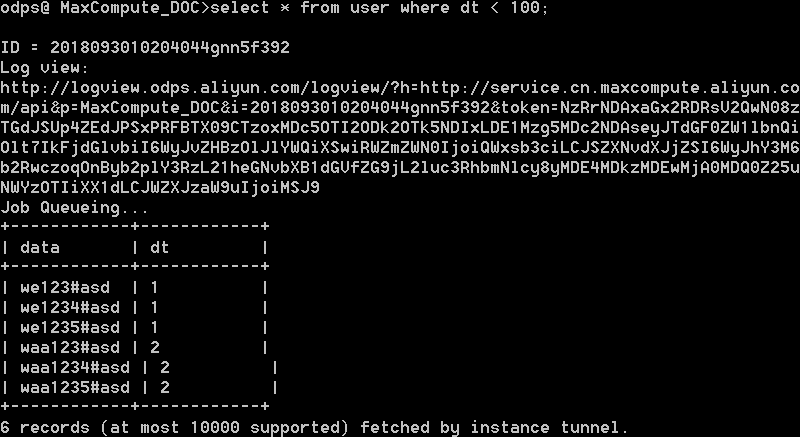
完成上传后,您可以在MaxCompute客户端查看表数据。
使用Tunnel Upload命令上传数据报错,是否有类似MySQL的-f参数,可以强制跳过错误数据继续进行上传?
您可以在Tunnel Upload命令中使用
-dbr true
参数忽略脏数据(多列、少列及列数据类型不匹配等情况)。
-dbr
参数默认值为False,表示不忽视脏数据;当值为True时,会将不符合表定义的数据全部忽略。详情请参见
Upload
。
使用Tunnel Upload命令上传数据时,报错You cannot complete the specified operation under the current upload or download status,如何解决?
-
问题现象
使用Tunnel Upload命令上传数据时,返回如下报错。
java.io.IOException: RequestId=XXXXXXXXXXXXXXXXXXXXXXXXX, ErrorCode=StatusConflict, ErrorMessage=You cannot complete the specified operation under the current upload or download status. at com.aliyun.odps.tunnel.io.TunnelRecordWriter.close(TunnelRecordWriter.java:93) at com.xgoods.utils.aliyun.maxcompute.OdpsTunnel.upload(OdpsTunnel.java:92) at com.xgoods.utils.aliyun.maxcompute.OdpsTunnel.upload(OdpsTunnel.java:45) at com.xeshop.task.SaleStatFeedTask.doWork(SaleStatFeedTask.java:119) at com.xgoods.main.AbstractTool.excute(AbstractTool.java:90) at com.xeshop.task.SaleStatFeedTask.main(SaleStatFeedTask.java:305)java.io.IOException: RequestId=XXXXXXXXXXXXXXXXXXXXXXXXX, ErrorCode=StatusConflict, ErrorMessage=You cannot complete the specified operation under the current upload or download status. -
产生原因
当前文件已经在上传中,无法重复操作。
-
解决措施
无需重复执行上传操作,等待已有上传任务执行完毕。
使用Tunnel Upload命令上传数据时,报错Error writing request body to server,如何解决?
-
问题现象
使用Tunnel Upload命令上传数据时,返回如下报错。
java.io.IOException: Error writing request body to server -
产生原因
这是上传数据到服务器时产生的异常,通常是因为上传过程中的网络连接断开或超时导致的:
-
当您的数据源并非是本地文件,需要从数据库等地方获取时,数据在写入的过程中还需要等待数据获取从而导致超时。在上传数据的过程中,如果600秒没有数据上传,则被认为超时。
-
用户通过外网的Endpoint上传数据,由于外网网络质量不稳定导致超时。
-
-
解决措施
-
在上传的过程中,先获取数据,再调用Tunnel SDK上传数据。
-
一个Block可以上传64 MB~100 GB的数据,最好不要超过1万条数据以免因重试导致超时。一个Session可以拥有最多2万个Block。如果您的数据在ECS上,Endpoint信息请参见 Endpoint 。
-
使用Tunnel Upload命令上传数据时,报错The specified partition does not exist,如何解决?
-
问题现象
在执行Tunnel上传数据操作时,返回报错如下。
ErrorCode=NoSuchPartition, ErrorMessage=The specified partition does not exist -
产生原因
数据要插入的目标分区不存在。
-
解决措施:
您可以先通过
show partitions table_name;命令来判断分区是否存在,并通过alter table table_name add [if not exists] partition partition_spec来创建对应的分区。
使用Tunnel Upload命令上传数据时,报错Column Mismatch,如何解决?
通常是因为数据源文件的行分隔符有问题,将多条记录当成了一条记录。您需要查看是否存在此问题,并重新设置
-rd
参数。
多线程上传数据时,报错ODPS-0110061,如何解决?
-
问题现象
在多线程上传数据场景,返回报错如下。
FAILED: ODPS-0110061: Failed to run ddltask - Modify DDL meta encounter exception : ODPS-0010000:System internal error - OTS transaction exception - Start of transaction failed. Reached maximum retry times because of OTSStorageTxnLockKeyFail(Inner exception: Transaction timeout because cannot acquire exclusive lock.) -
产生原因
上传数据时高并发写入同一个表,频繁的并发操作导致报错。
-
解决措施
适当减少并发数,在请求之间加入延迟时间,并且在出错的时候重试。
使用Tunnel Upload命令行上传CSV文件时,如何跳过第一行表头上传其他数据?
在Tunnel Upload命令中添加
-h true
参数即可跳过第一行表头。
使用Tunnel Upload命令行上传CSV文件时,为什么导入成功后原文本中有很大一部分内容莫名消失?
这种情况是因为数据编码格式错误或分隔符使用错误导致上传到表的数据错误。建议规范原始数据后再执行上传操作。
如何在Shell脚本中将一个TXT文件中的数据上传到MaxCompute的表中?
在系统的命令行执行窗口,您可以通过指定参数快速执行上传操作,上传数据至MaxCompute表的命令如下。
...\odpscmd\bin>odpscmd -e "tunnel upload "$FILE" project.table"更多命令行启动信息,请参见 启动参数 。
导入文件夹中的文件数据时,提示字段不匹配,但是文件夹下的文件可以单独导入,如何解决?
在Tunnel Upload命令后加上
-dbr=false -s true
属性对数据格式进行验证。
出现
column mismatch
通常是由于列数不匹配导致的。例如列分隔符设置的不对或文件最后有空行,导致空行通过分隔符进行分割时列数不对。
使用Tunnel Upload命令上传两个文件时,第一个文件上传结束之后,第二个文件没有上传且没有报错信息,是什么原因?
当MaxCompute客户端上传参数有
--scan
时,续跑模式的参数传递存在问题,将
--scan=true
去掉重试即可。
使用Tunnel Upload命令上传数据时,共分为50个Block,开始一切正常,但是在第22个Block时,出现Upload Fail,重试直接跳过开始上传第23个Block,如何解决?
一个Block对应一个HTTP Request,多个Block的上传可以并发且是原子的,一次同步请求要么成功要么失败,不会影响其他的Block。
重传Retry有次数的限制,当重传的次数超过了这个限制,就会继续上传下一个Block。上传完成后,可以通过
select count(*) from table;
语句,检查是否有数据丢失。
本地服务器每天采集的网站日志有10 GB,需要上传至MaxCompute,在使用Tunnel Upload命令上传时速度约为300 KB/S,如何提升上传速度?
Tunnel Upload命令上传是不设速度限制的。上传速度的瓶颈在于网络带宽、客户端性能以及服务器性能。为了提升性能,可以考虑在上传时分区分表,或通过多台ECS上传数据。
上传数据时,每个Session的生命周期是一天,因源表数据太大,导致Session超时任务失败,如何解决?
建议将源表拆分为2个任务执行。
上传Session太多导致上传速度慢,如何解决?
应合理设置Block大小。Block ID最大为20000,Session的时间根据具体业务需求设置,Session提交以后数据才可见。建议您创建Session的频率不要太高,最多5分钟一个Session,Session里的Block值应该设置的较大一些,建议每个Block超过64 MB。
导入数据的最后一列为什么会多出\r符号?
Windows的换行符是
\r\n
,macOS和Linux的换行符是
\n
,Tunnel命令使用系统换行符作为默认列分隔符,所以从macOS或Linux上传Windows编辑保存的文件后,会把
\r
作为数据内容导入表。
使用Tunnel Upload命令上传数据时,默认用逗号进行列分割,但是数据中有逗号,这种情况如何分割?
如果数据描述字段内本身有逗号,可以考虑转换数据的分隔符为其他符号,再通过
-fd
指定为其他分隔符进行上传。
使用Tunnel Upload命令上传数据时,如果数据使用空格作为列分隔符,或需要对数据做正则表达式过滤时,如何解决?
Tunnel Upload命令不支持正则表达式。如果数据使用空格作为列分隔符,或需要对数据做正则表达式过滤时可借助MaxCompute的UDF功能。
假设原始数据如下,列分割符为空格,行分隔符为回车,并且需要取的部分数据在引号内,部分数据例如”-“需要被过滤。这种复杂的需求可通过正则表达式实现。
10.21.17.2 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73477.html" 200 0 81615 81615 "-" "iphone" - HIT - - 0_0_0 001 - - - -
10.17.5.23 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73478.html" 206 0 49369 49369 "-" "huawei" - HIT - - 0_0_0 002 - - - -
10.24.7.16 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73479.html" 206 0 83821 83821 "-" "vivo" - HIT - - 0_0_0 003 - - - -实现方式如下:
-
将数据以单列形式上传,首先在MaxCompute项目内创建一个单列的表格用于接收数据。命令示例如下。
create table userlog1(data string); -
使用一个不存在的列分隔符
\u0000上传数据,从而达到不分割列的效果。命令示例如下。tunnel upload C:\userlog.txt userlog1 -s false -fd "\u0000" -rd "\n"; -
完成原始数据上传后,使用MaxCompute Studio编写一个Python UDF(您也可以使用Java UDF)并注册函数。编写并注册UDF操作,请参见 开发Java UDF 或 开发Python UDF 。
UDF代码示例如下。假设注册的函数名称为ParseAccessLog。
from odps.udf import annotate from odps.udf import BaseUDTF import re #此处引入正则函数 regex = '([(\d\.)]+) \[(.*?)\] - "(.*?)" (\d+) (\d+) (\d+) (\d+) "-" "(.*?)" - (.*?) - - (.*?) (.*?) - - - -' #使用的正则表达式 # line -> ip,date,request,code,c1,c2,c3,ua,q1,q2,q3 @annotate('string -> string,string,string,string,string,string,string,string,string,string,string') #请注意string数量和真实数据保持一致,本例中有11列。 class ParseAccessLog(BaseUDTF): def process(self, line): t = re.match(regex, line).groups() self.forward(t[0], t[1], t[2], t[3], t[4], t[5], t[6], t[7], t[8], t[9], t[10]) except: pass -
完成函数注册后,就可以使用UDF函数处理上传到表格userlog1的原始数据了,注意不要写错列的名称,本例中为data。您可以使用正常的SQL语法,新建一个表格userlog2用于存放处理后的数据。命令示例如下。
create table userlog2 as select ParseAccessLog(data) as (ip,date,request,code,c1,c2,c3,ua,q1,q2,q3) from userlog1;完成处理后,可以查询userlog2的表数据,数据成功分列。
select * from userlog2; --返回结果如下。 +----+------+---------+------+----+----+----+----+----+----+----+ | ip | date | request | code | c1 | c2 | c3 | ua | q1 | q2 | q3 | +----+------+---------+------+----+----+----+----+----+----+----+ | 10.21.17.2 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73477.html | 200 | 0 | 81615 | 81615 | iphone | HIT | 0_0_0 | 001 | | 10.17.5.23 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73478.html | 206 | 0 | 4936 | 4936 | huawei | HIT | 0_0_0 | 002 | | 10.24.7.16 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73479.html | 206 | 0 | 83821 | 83821 | vivo | HIT | 0_0_0 | 003 | +----+------+---------+------+----+----+----+----+----+----+----+
Tunnel Upload完成后,存在脏数据,如何解决?
建议一张单表(没有分区的表)或一个分区尽量一次性写入数据,不要多次写同一个分区,否则容易出现脏数据。您可以在MaxCompute客户端执行
tunnel show bad <sessionid>;
命令查看脏数据。一旦出现脏数据,可以通过如下方法进行删除:
-
执行
drop table ...;命令删除整张表或执行alter table ... drop partition;命令删除目标分区后,重新上传数据。 -
如果脏数据可以通过WHERE条件过滤出来,也可以通过INSERT+WHERE条件,把需要的数据导入到另一张新表或就地更新(源和目的分区/表名相同)。
geometry类型数据如何同步至MaxCompute?
MaxCompute不支持geometry类型数据,需要将geometry类型数据转换为STRING类型数据才能同步至MaxCompute。
geometry类型是一种特殊的数据类型,不同于SQL标准中的标准数据类型,因此在JDBC的通用框架并不支持,所以导致geometry类型的导入导出需要进行特殊的处理。
Tunnel Download导出格式有哪些?
使用Tunnel Download导出的数据文件格式为TXT或CSV。
在同一地域内使用Tunnel Download命令下载数据,为什么会产生费用?
同一地域内使用Tunnel下载数据,必须配置经典网络或VPC类型的Tunnel Endpoint,否则数据可能路由到其他地域,从外网下载数据从而产生费用。
使用Tunnel Download命令下载数据时,总是提示超时,如何解决?
通常是Tunnel Endpoint错误,请检查Tunnel Endpoint配置是否正确。简单的判断方法是通过Telnet等方法检测网络连通性。
使用Tunnel Download命令下载数据时,报错You have NO privilege,如何解决?
-
问题现象
使用Tunnel Download命令下载数据时,返回报错信息如下。
You have NO privilege ‘odps:Select‘ on {acs:odps:*:projects/XXX/tables/XXX}. project ‘XXX‘ is protected. -
产生原因
项目开启了数据保护功能。
-
解决措施
如果您需要把一个项目中的数据导出至另一个项目,需要该项目所有者进行操作。
如何使用Tunnel下载部分指定数据?
Tunnel不支持数据的计算或者过滤。如果需要实现此功能,您可以考虑以下两种方法:
-
先运行SQL任务,将需要下载的数据保存成一张临时表,下载结束后再删除此临时表。
-
如果您所需要的数据量比较小,可以使用SQL命令直接查询需要的数据,无需下载。
Tunnel中的history命令信息会保存多久?
与时间无关,默认保存500条。
Tunnel上传数据的流程是什么?
Tunnel上传数据的流程如下:
-
准备源数据,例如源文件或数据表。
-
设计表结构和分区定义,进行数据类型转换,然后在MaxCompute上创建表。
-
在MaxCompute表上添加分区,没有分区时忽略此步骤。
-
把数据上传到指定分区或表上。
Tunnel目录名支持中文吗?
支持中文。
Tunnel使用分隔符时,需要注意什么?
Tunnel使用分隔符时,需要注意:
-
行分隔符为
rd,列分隔符为fd。 -
列分隔符
fd不能包含行分隔符rd。 -
Tunnel的默认分隔符为
\r\n(Windows)和\n(Linux)。 -
上传开始的时候,屏显会打印提示信息,告知本次上传所使用的行分隔符(0.21.0版本及以后)供用户查看和确认。
Tunnel文件路径是否可以有空格?
可以有空格,参数需要用双引号("")括起来。
Tunnel是否支持.dbf后缀非加密数据库文件?
Tunnel仅支持文本文件,不支持二进制文件。
Tunnel上传下载正常速度范围是多少?
Tunnel上传下载受网络因素影响较大,正常网络情况下速度范围为1 MB/s~20 MB/s。
Tunnel域名如何获取?
Tunnel域名即 外网Tunnel Endpoint ,不同地域、不同网络对应不同的Tunnel域名,请参见 Endpoint对照表 获取 外网Tunnel Endpoint 。
Tunnel无法上传下载,如何处理?
在MaxCompute客户端安装目录
..\odpscmd_public\conf
下的odps_config.ini文件中获取Tunnel域名,在系统命令行窗口执行
curl -i 域名
(例如
curl -i http://dt.odps.aliyun.com
)命令测试网络是否连通,若无法连通请检查设备网络或更换为正确的Tunnel域名。
Tunnel命令报错Java heap space FAILED,如何解决?
-
问题现象
使用Tunnel命令上传或下载数据时,返回报错如下。
Java heap space FAILED: error occurred while running tunnel command -
产生原因
-
原因一:上传数据时,单行数据太大导致报错。
-
原因二:下载数据量太大,客户端程序内存不足。
-
-
解决措施
-
原因一的解决措施:
-
首先确认是否是分隔符错误,导致所有数据都进入同一行记录,导致单行数据太大。
-
如果分隔符正确,文件中的单行数据的确很大,则为客户端程序的内存不够用,需要调整客户端进程的启动参数。编辑客户端安装目录
bin下的odpscmd脚本,适当增加Java进程启动选项中的内存值。即将java -Xms64m -Xmx512m -classpath "${clt_dir}/lib/*:${clt_dir}/conf/"com.aliyun.openservices.odps.console.ODPSConsole "$@"中-Xms64m -Xmx512m的值增大即可。
-
-
原因二的解决措施:编辑客户端安装目录
bin下的odpscmd脚本,适当增加Java进程启动选项中的内存值。即将java -Xms64m -Xmx512m -classpath "${clt_dir}/lib/*:${clt_dir}/conf/"com.aliyun.openservices.odps.console.ODPSConsole "$@"中-Xms64m -Xmx512m的值增大即可。
-
Session是否存在生命周期,超过生命周期后如何处理?
每个Session在服务端的生命周期为24小时,创建后24小时内均可使用。Session超时后就失效了,此时您不能做任何操作,需要重新创建Session重写数据。
Session是否可以共享使用?
Session在可以跨进程、线程共享使用,但是必须保证同一个BlockId没有重复使用。
Tunnel路由功能是什么?
如果您未配置Tunnel Endpoint,Tunnel会自动路由到MaxCompute服务所在网络对应的Tunnel Endpoint。如果您配置了Tunnel Endpoint,则以配置为准,不进行自动路由。
Tunnel是否支持多并发?
支持,命令示例如下。
tunnel upload E:/1.txt tmp_table_0713 --threads 5;