Hive 的 conf 目录下都是相关配置文件。Hive 中的配置文件是 hive-default.xml,这个文件中包含hive所有的默认配置,里面的配置贼多,不方便查看。
我们可以在 conf 目录下,vim 方式自定义一个 hive-site.xml 文件,Hive在启动时会动态的去加载 hive-site.xml 中我们自定义的配置信息。这里也涉及到配置文件加载优先级问题,类似 hadoop 中的 hdfs-default.xml 和 hdfs-site.xml 。hive-site.xml 配置会覆盖掉 hive-default.xml 中默认的配置
在 Hadoop 中,配置文件的优先级别为:hive-default.xml < 服务器中配置的 hive-site.xml < 我们编写的代码中resources目录下得 hive-site.xml < 代码中通过Configuration,直接使用conf.set(key,value)方式设置。在Hive中也是一样的。
可以进入 hive 客户端,通过 set 命令查看所有的配置信息。
hive> set;
或者通过
hive> set 配置对应的key; 来查看指定的配置信息
比如:
hive> set hive.cli.print.header; // 查看配置中,是否打印表头

由于配置文件过多,一屏无法全部显示完整,如需查看我们可以将 hive 所有的配置信息追加到一个文件中,这样更方便查看。
[hadoop@hadoop201 bin]$ touch conf.txt (创建一个文件conf.txt)
[hadoop@hadoop201 bin]$ hive -e “set” >> conf.txt (通过hive -e 方式 执行 set,将结果追加至 conf.txt 文件下,查看 conf.txt 文件即可,所有的配置就都在该文件下)
共有以下 3 种方式:
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的,Hive 的配置会覆盖 Hadoop 的配置。配置文件的设定对本机启动的所有 Hive 进程都有效。
有的配置信息,只有在当前任务执行需要此配置,如果将该配置添加至 hive-site.xml 中,那么每个任务都会使用此配置。这个显然就是不妥咯。(比如:当前任务中,有很多的小文件需要处理,此时就需要用到一个 CombinerInputFormat 临时在当前任务使用以下,其他任务也不受影响。这种情形就用到了下面的第2种方式)
启动 Hive 时,可以在命令行添加-hiveconf param=value 来设定参数。(这种方式配置,仅对当前启动的 Hive 客户端窗口有效,这种配置的优先级会比 hive-site.xml 中配置的优先级高)
[hadoop@hadoop201 hive]$ bin/hive -hiveconf mapred.reduce.tasks=10
除了以上 2 种方式外,我们还可以通过参数声明的方式来指定配置。(即:进入 Hive 客户端,通过 set hive.cli.print.header=false 方式,类似参数声明的方式来进行配置。这种方式的配置,只对声明后的语句有效)
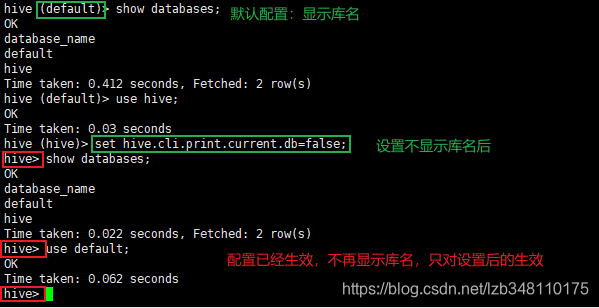
注意1: 上述三种设定方式的优先级依次递增。即 配置文件 < 命令行参数 < 参数声明。注意某些系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
注意2:凡是能通过 set 设置的属性,一定是在 hive-default.xml 配置中能够查询到的,log4j 这种就是查询不到的,所以没法设置
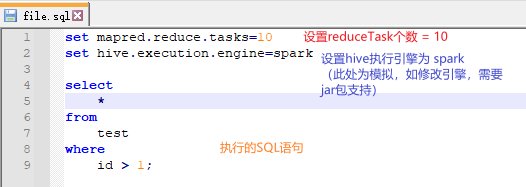
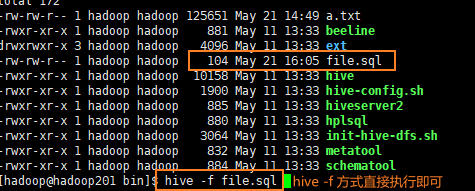
在 hive中,我们可以通过 -e 或 -f ,在不进入到 Hive 客户端中去执行SQL语句。所以:
- 我们可以把配置信息写到SQL脚本前面,只给当前这个任务的这个文件使用;通过
hive -f 文件名执行 - 只给 hive -e “set mapred.reduce.tasks=10” select * from test; 只给当前 select 这条语句使用,类似一种临时生效的方式
示例如图:
下一篇:Hive 数据类型
博主写作不易,加个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
我不能保证所写的内容都正确,但是可以保证不复制、不粘贴。保证每一句话、每一行代码都是亲手敲过的,错误也请指出,望轻喷 Thanks♪(・ω・)ノ
命令行界面(Command Line Interface,CLI)是Hive交互最常见也是最方便的方式。在命令行界面可以执行Hive支持的觉大多数功能,如查询,创建等。
hive -e
有时,并不需要一直打开命令行界面,也就是说执行完查询后立刻退出,可以用hive -e的形式,如下:
[hadoop@master ~]$ hive -e 'select count(*) from test'...
set hive.exec.dynamic.partition.mode=nonstrict;
动态分区的好处是可以根据表字段自动将数据加入到指定分区,相比于写死固定分区更加便捷。以下实例基于your_table是单分区表。
原始分区示例:
hive -e "
insert overwrite tab.
hive -e “your sql” 执行sql并退出
hive -S -e “your sql” 静默模式,返回结果省去执行耗时、结果行数等信息
hive -f /xx/your_sql.hql 执行指定文件中的sql(进入hive shell模式时,可以使用source指定sql文件)
hive外部表与管理表(内部表)
管理表 —— hive控制着数据的生命周期(删除表时,数据会被删除),数据存储在默
### 回答1:
Hive 是一个基于 Hadoop 的数据仓库系统,能够处理大规模的结构化数据。在 Hive 中使用自定义函数或者存储过程时,常常需要通过加载 jar 包来实现。以下三种方式是常用的 Hive 加载 jar 包的方式。
1. 添加 Hive AUX JARS
在 hive-site.xml 或者 hive-config.sh 中,通过配置 hive.aux.jars.path=xxxx 指定 jar 包存储的路径,最终将 jar 包添加到 Hadoop 的 ClassPath 中。当 Hive 运行需要加载 jar 包的任务时,就会从 ClassPath 中加载 jar 包,避免手动指定 JAR 文件。
2. ADD JAR 命令
使用 ADD JAR 命令将 jar 包添加到 Hive 会话中,可以通过全路径、本地路径或 Hadoop HDFS 路径来指定。例如 ADD JAR hdfs:///example/hive/hive-test.jar;
3. 使用命令行参数
启动 Hive 命令时,可以通过指定 –hiveconf hive.aux.jars.path=xxxx 指定 JAR 文件的路径,启动 Hive 命令同时就会将 JAR 文件加入到 ClassPath 中。
总之,在使用 Hive时,要根据实际情况选择合适的方式加载 JAR 包,避免出现错误。
### 回答2:
在Hive中加载jar包有多种方式,以下列举其中三种:
1. 添加hive自定义类路径
在hive-site.xml文件中,将Hive的自定义类路径hive.aux.jars.path设置成需要加载的jar包所在路径,即可将jar包加入Hive的classpath中,方便调用自定义函数等操作。示例:
<property>
<name>hive.aux.jars.path</name>
<value>/path/to/jar1:/path/to/jar2</value>
</property>
2. 使用ADD JAR命令
在Hive的交互式终端或执行脚本时,使用ADD JAR命令将需要加载的jar包添加到Hive的classpath中。该命令会将jar包复制到Hive的临时文件夹中,可以通过system:java.io.tmpdir查看该路径。示例:
ADD JAR /path/to/jar1;
ADD JAR /path/to/jar2;
3. 在创建自定义函数时指定jar包路径
在创建自定义函数时,可以将需要加载的jar包路径直接指定到函数的CLASSPATH选项中。示例:
CREATE TEMPORARY FUNCTION my_func AS 'com.package.MyFunc' USING JAR '/path/to/jar1';
以上三种方式中,第一种和第二种可以将jar包持久地添加到Hive的classpath中,方便后续多个脚本或交互式终端使用;第三种方式则适用于只在当前会话使用自定义函数的情况。
### 回答3:
Hive 是一个基于 Hadoop 的数据仓库工具,它可以将结构化的数据以 SQL 的方式进行查询和分析。在 Hive 中,用户可以使用自定义的 UDF(用户定义函数),以扩展 Hive 的功能。
说到加载 Jar 包,Hive 有以下几种方式:
1. ADD JAR:通过 ADD JAR 命令将本地路径的 Jar 包加载到 Hive 中。
ADD JAR /usr/local/hive/UDF/hive-udf.jar;
2. ADD ARCHIVE:通过 ADD ARCHIVE 命令将一个包含多个 Jar 包的 tar.gz 归档文件加载到 Hive 中。
ADD ARCHIVE /usr/local/hive/UDF/hive-udf.tar.gz;
3. 在 Hive 配置文件中添加 Jar 包路径:在 Hive 的配置文件中,添加 Jar 包所在的路径,如下:
hive.aux.jars.path=file:///usr/local/hive/UDF/hive-udf.jar
4. 使用命令行选项 "-hiveconf":在启动 Hive 前,使用 -hiveconf 命令行选项指定 Jar 包路径。
$ hive -hiveconf hive.aux.jars.path=file:///usr/local/hive/UDF/hive-udf.jar
以上是 Hive 加载 Jar 包的几种方式,根据不同的需求,选择合适的方式即可。




