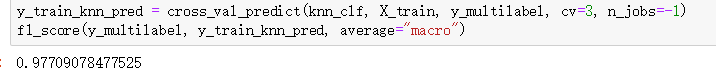我们将讨论最后一种分类任务–多输出多分类任务(简称为多输出分类)。简单而言,它是多标签分类的泛化,其标签也可以是多种类别的(比如有两个以上的值) 。
说明:构建一个去除图片中噪声的系统。给它输入一个带噪声的图片,它将(希望)输出一张干净的数字图片,跟其他MNIST图片一样,以像素强度的一个数组作为呈现方式。 需要注意的是,这个分类器的输出时多个标签(一个像素点一个标签),每一个标签有多个值(0-255)。所以这是一个多输出分类器系统的例子。
创建训练集和测试集,使用Numpy的randint 来给Mnist图片的像素强度增加噪声。目标是将图片还原为原始图片。
代码如下:
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
some_index = 5500
plt.subplot(121); plot_digit(X_test_mod[some_index])
plt.subplot(122); plot_digit(y_test_mod[some_index])
plt.show()
运行结果如下:
左边为添加噪声后的样子。
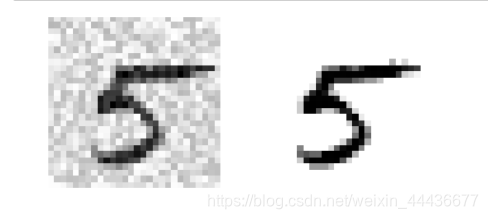
代码如下:
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[some_index]])
plot_digit(clean_digit)
运行结果如下:
可见已经消除噪声,还原为数字5了。

1.将数据进行预处理。
2.通过一对一方法将45类训练样本((0,1),(0,2),…(1,2)…(2,3))送入交叉验证法,训练算法为smo
3.得出45个模型,测试时在利用投票法判定
'''***************************************************************
* @Fun_Name : judgeStruct:
* @Function : 存放训练后的分类器参数
* @Parameter :
* @Return :
* @Creed : Talk is cheap
多项式逻辑回归是逻辑回归的扩展,它增加了对多类分类问题的支持。
默认情况下,逻辑回归仅限于两类分类问题。一些扩展,可以允许将逻辑回归用于多类分类问题,尽管它们要求首先将分类问题转换为多个二元分类问题。
相反,多项逻辑回归算法是逻辑回归模型的扩展,涉及将损失函数更改为交叉熵损失,并将概率分布预测为多项概率分布,以原生支持多类分类问题。
在本教程中,您将了解如何在 Python 中开发多项逻辑回归...
交叉验证如何用于选择调节参数、选择模型、选择特征;
对交叉验证进行升级。
1. 为什么要进行模型验证 众所周知,在机器学习与数据挖掘中进行模型验证的一个重要目的是要选出一个最合适的模型。对于有监督学习而言,我们希望模型对于未知数据具有很强的泛化能力,所以就需要模型验证这一过程来评估不同的模型
概述Holdout 交叉验证K-Fold 交叉验证Leave-P-Out 交叉验证总结概述交叉验证是在机器学习建立模型和验证模型参数时常用的办法。顾名思义,就是重复的使用数据,把得到的样...
一般的深度学习入门例子是 MNIST 的训练和测试,几乎就算是深度学习领域的 HELLO WORLD 了,但是,有一个问题是,MNIST 太简单了,初学者闭着眼镜随便构造几层网络就可以将准确率提升到 90% 以上。但是,初学者这算入门了吗?
答案是没有。
现实开发当中的例子可没有这么简单,如果让初学者直接去上手 VOC 或者是 COCO 这样的数据集,很可能自己搭建的神经网络准确率不超过 30%。...
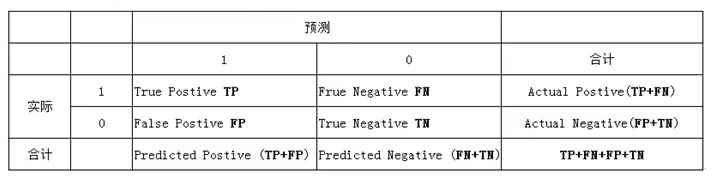
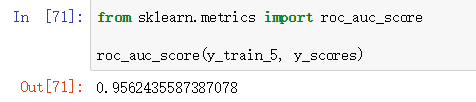
机器学习(ML), 自然语言处理(NLP), 信息检索(IR)等领域, 评估(Evaluation)是一个必要的工作, 而其评价指标往往有如下几点: 准确率(Accuracy), 精确率(Precision), 召回率(Recall) 和 F1-Measure.(注:相对来说,IR 的 ground truth 很多时候是一个 Ordered List, 而不是一个 Bool 类型的 Unorde...
from sklearn.datasets import fetch_openml
# 从 Scikit-Learn 0.24 开始,fetch_openml() 默认返回 Pandas DataFrame。
# 为了避免这种情况并保持与书中相同的代码,我们使用 as_frame=False。
# 下载失败可以多尝试几次,初次时间会稍微稍微久一点,我等了 12min7s,再次使用会优先检查缓存文件。
mnist = fetch_openml('
为了得到更为稳健可靠的模型,对模型的泛化误差进行评估,得到模型泛化误差的近似值。当有多个模型可以选择时,我们通常选择“泛化误差”最小的模型。
交叉验证的方法有许多种,但是最常用的是:留一交叉验证、k 折交叉验证。
第一种混淆矩阵
本文主要记录使用 Sklearn 做机器学习预测的代码例子,适合初学者理解和扩展。模块英文名模块中文名分类Regression回归Clustering非监督分类数据降维模型选择数据预处理。
文章目录1.前言2.非交叉验证实验3.交叉验证实验4.准确率与平方误差4.1.准确率实验
Sklearn 中的 Cross Validation (交叉验证)对于我们选择正确的 Model 和 Model 的参数是非常有帮助的, 有了它的帮助,我们能直观的看出不同 Model 或者参数对结构准确度的影响。
2.非交叉验证实验
from sklearn.datasets import lo...
交叉验证是一种用来评价一个统计分析的结果是否可以推广到一个独立的数据集上的技术。主要用于预测,即,想要估计一个预测模型的实际应用中的准确度。它是一种统计学上将数据样本切割成较小子集的实用方法。于是可以先在一个子集上做分析,
而其它子集则用来做后续对此分析的确认及验证。
交叉验证的理论是由Seymour
Geisser所开始的。 它对于防范testing
hypotheses su
交叉验证法 (cross validation)
自助法 (bootstrap)
留出法注意: 保持数据分布一致性 (例如: 分层采样) 多次重复划分 (例如: 100次随机划分) 测试集不能太大、不能太小 (例如:1/5~1/3)k-折交叉验证法自助法
sklearn
Python实战,对负债率,信用卡负债违约负债率、工龄违约信用卡负债、工龄违约,分析违约与各特征之间的关系。通过循环,基础原理实现对模型SVM,KNN,逻辑回归,决策树的调优调参,自动化得到最高得分score和accuracy,