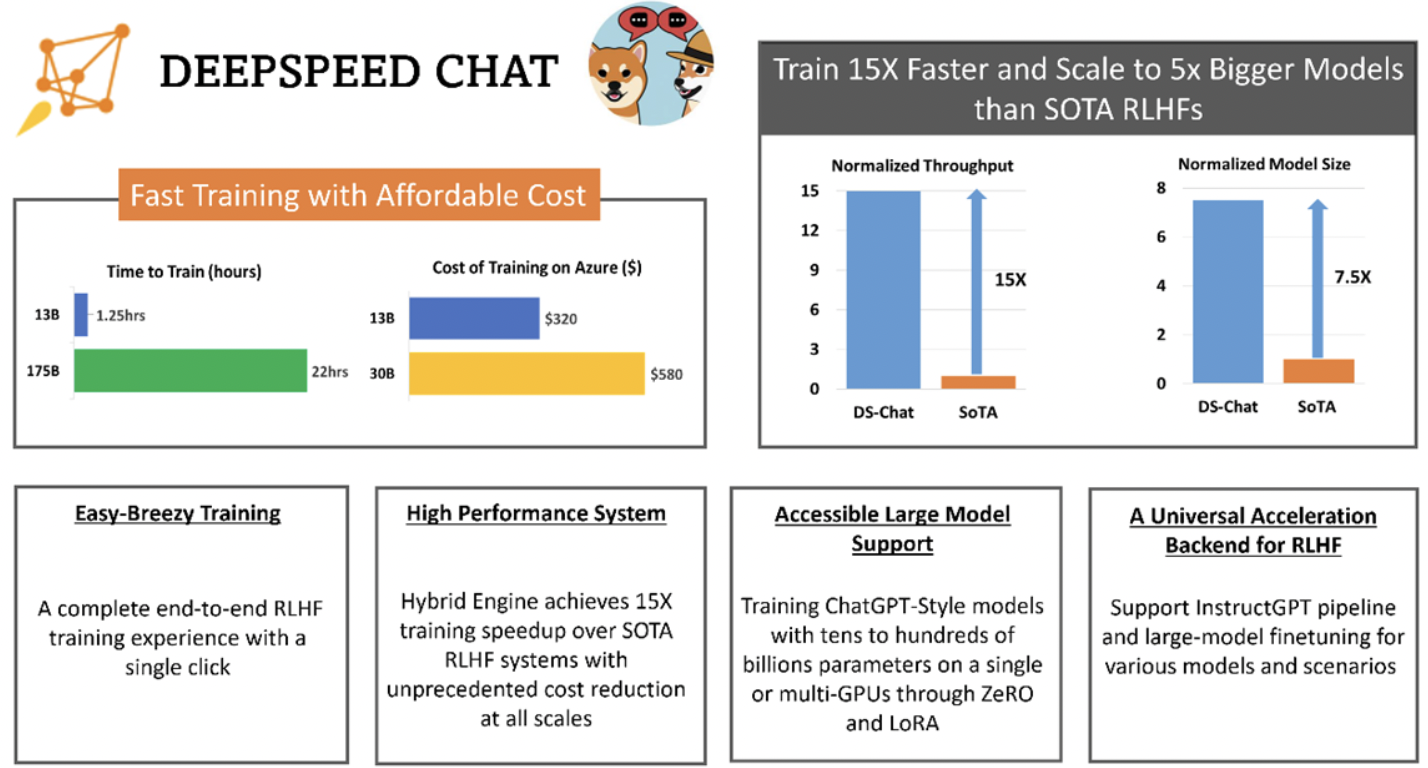
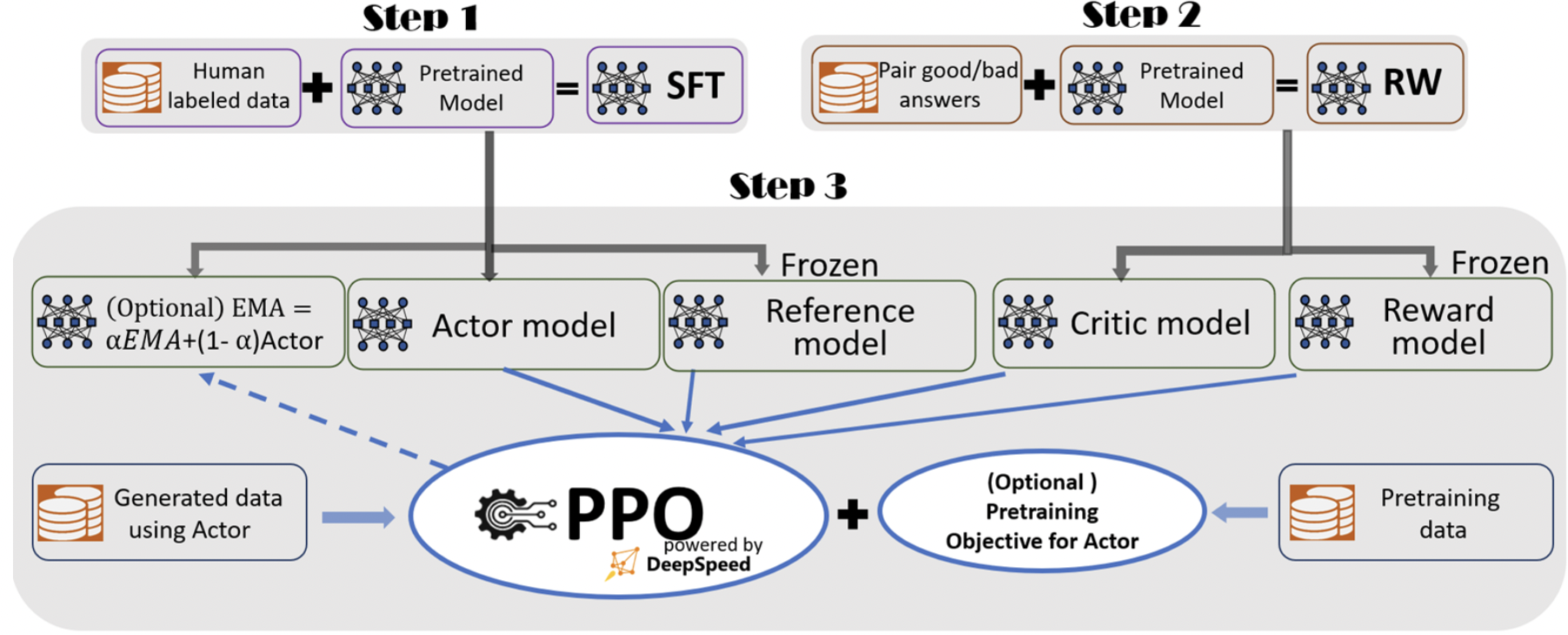
link之家
链接快照平台
- 输入网页链接,自动生成快照
- 标签化管理网页链接
相关文章推荐

|
瘦瘦的烈马 · 动漫《圣斗士星矢》中的白银圣斗士的战斗力天花 ...· 1 年前 · |
|
|
拉风的绿豆 · 日本漫画家井上雄彦:《灌篮高手》 ...· 1 年前 · |
|
|
耍酷的黑框眼镜 · 天越亮越早,宝宝也越醒越早,怎么办?六步解决!· 1 年前 · |
|
|
帅气的松球 · 恶女的惩罚游戏漫画第二季什么时候出,恶女的惩 ...· 1 年前 · |

推荐文章
|
|
耍酷的黑框眼镜 · 天越亮越早,宝宝也越醒越早,怎么办?六步解决! 1 年前 |