泰坦尼克号数据分析python实战
(单因素分析)
数据集:kaggle上的泰坦尼克号数据集
主要字段有:
PassengerId:乘客的ID(和存活率无关)
Survived:是否存活(1为存活,0为死亡)
Pclass:船舱等级(等级较高的船舱救生设备比较齐全)
Name:乘客姓名(无关)
Sex:乘客性别
Age:乘客年龄
SibSp:兄弟姐妹(有些乘客可能带兄弟姐妹一起上船)
Parch:父母小孩(同SibSp)
Ticket:船票编号(无关)
Fare:费用(同Pclass)
Cabin:舱号(无关)
Embarked:上船的地点(可能存在一定的相关性?)
和存活率可能相关的变量:Survived,Pclass,Sex,Age,SibSp,Parch,Fare,Embarked
要分析的问题:
1,泰坦尼克号获救情况如何?
2,船舱等级Pclass对存活Survived的影响?
3,性别Sex对存活Survived的影响?
4,年龄Age对存活Survived的影响?
首先用python对数据集进行预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
df=pd.read_csv(r'train.csv')
先了解数据的概括(形状,缺失值)
df.shape
df.info()
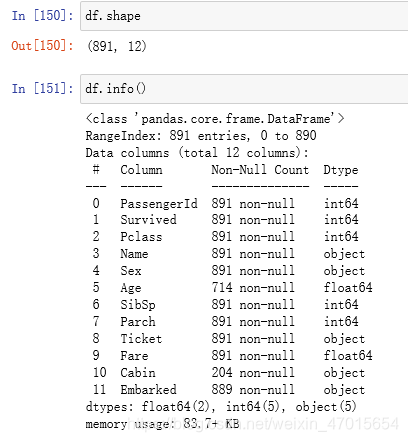
由运行结果可知:数据集中一共有12列,891行。其中,Age、Cabin、Embarked存在缺失值,对其进行缺失值处理
df.Age.fillna(df.Age.mean(),inplace=True)
df = df.drop(["Cabin" ],axis = 1)
df[df.Embarked.isnull()]
df.Embarked.value_counts()
df.Embarked.fillna('S',inplace=True)
df.Embarked.value_counts()
df.iloc[61]
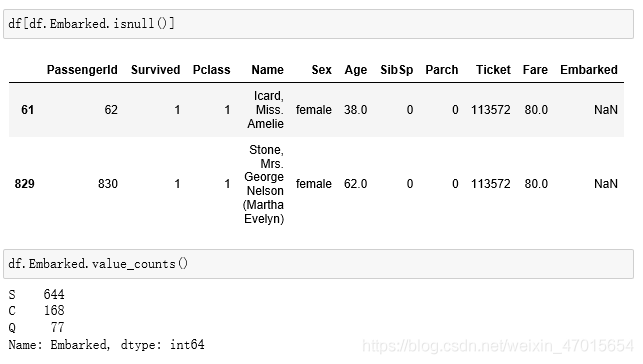
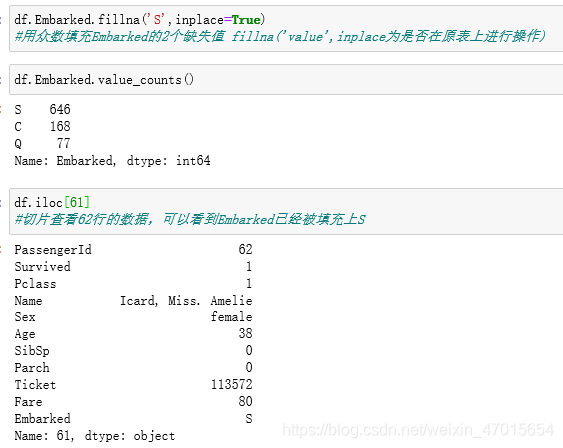
数据缺失值处理完成,接下来进行数据的描述性统计分析
df.describe()
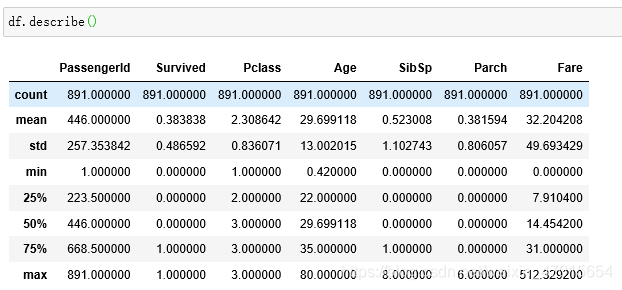
然后进行单因素分析
问题1:泰坦尼克号获救情况如何?
total_survived=df.Survived.value_counts()
total_survived.index=total_survived.index.astype('str')
_x=total_survived.index
_y=total_survived.values
plt.figure(figsize=(10,5),dpi=80)
ax1=plt.subplot(1,2,1)
plt.title('Survived Count')
plt.bar(_x[0],_y[0],color='#39cc6A',align='center',label='survived')
plt.bar(_x[1],_y[1],color='#ff9361',align='center',label='not survived')
label=['survived','not survived']
plt.xlabel('survived or not',fontsize=10)
plt.ylabel('count',fontsize=10)
plt.ylim(0,600)
ax2=plt.subplot(1,2,2)
plt.title('Survived Rate')
plt.pie(total_survived,labels=['not survived','survived'],colors=['#ff9361','#39cc64'], autopct='%3.0f%%', startangle=230)
plt.axis('equal')
plt.show()
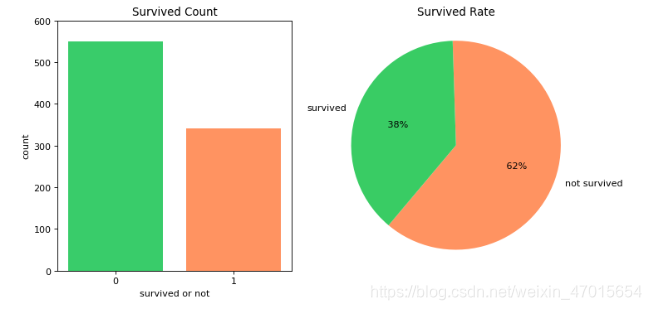
结论1:由图形可以看出,这891名乘客中,获救的占38%,没获救的占比62,死亡率很高。
这里遇到一个问题:绘制直方图,X轴的标签赋值label设置无效。但是饼图中的label有效。希望有大佬可以解答一下,谢谢。
问题2:船舱等级Pclass对存活Survived的影响?
df['Pclass']=df['Pclass'].astype('str')
df_survived=df['Pclass'][df['Survived']==1]
df_not_survived=df['Pclass'][df['Survived']==0]
plt.figure(figsize=(10,5),dpi=80)
plt.hist([df_survived,df_not_survived],stacked=True,color=['#39cc6a','#ff9361'],label=['Survived','Not Survived'])
plt.xticks(['1','2','3'],['Upper','Middle','Lower'])
plt.legend()
plt.xlabel('Pclass',fontsize=10)
plt.ylabel('Count',fontsize=10)
plt.title('Pclass_Survived')
plt.ylim(0,600)
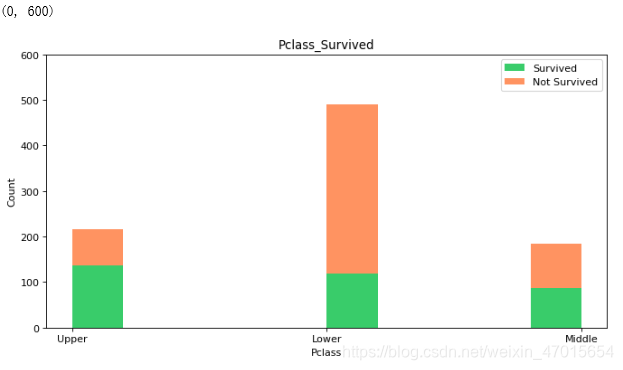
结论2:第3层的船舱人数越多,获救率反而最小,船舱等级越高,获救率越大
问题3:性别Sex对存活Survived的影响?
df['Sex']=df['Sex'].astype('str')
df_sex1=df['Sex'][df['Survived']==1]
df_sex0=df['Sex'][df['Survived']==0]
plt.figure(figsize=(5,5),dpi=80)
plt.hist([df_sex1,df_sex0],stacked=True,color=['#39cc6a','#ff9361'],label=['Survived','Not Survived'])
plt.xticks([-1,0,1,2],[-1,'F','M',2])
plt.legend()
plt.xlabel('Sex',fontsize=10)
plt.ylabel('count',fontsize=10)
plt.ylim(0,600)
plt.title('Sex_Survived')
plt.show()
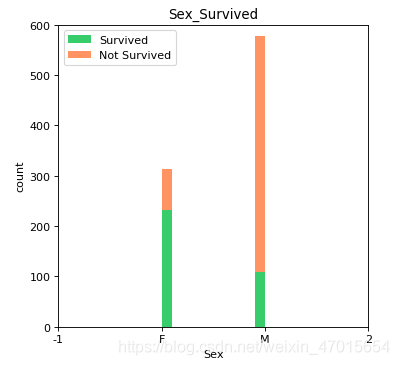
结论3:船上男性的人数比女性多,但女性的获救率远大于男性
问题4:年龄Age对存活Survived的影响?
def age_level(age):
if age <= 9:
return str('1')
elif age <=24:
return str('2')
elif age <=59:
return str('3')
else:
return str('4')
df['Age']=df['Age'].apply(lambda x: age_level(x))
df_age1=df['Age'][df['Survived']==1]
df_age0=df['Age'][df['Survived']==0]
plt.figure(figsize=(10,5),dpi=80)
plt.hist([df_age1,df_age0],stacked=True,color=['#39CC6A','#FF9361'],label=['Survived','Not Survived'])
plt.xticks(['1','2','3','4'],['kids','youth','middle','old'])
plt.legend()
plt.xlabel('Age_level',fontsize=10)
plt.ylabel('count',fontsize=10)
plt.title('Age_Survived')
plt.ylim(0,700)
plt.show()
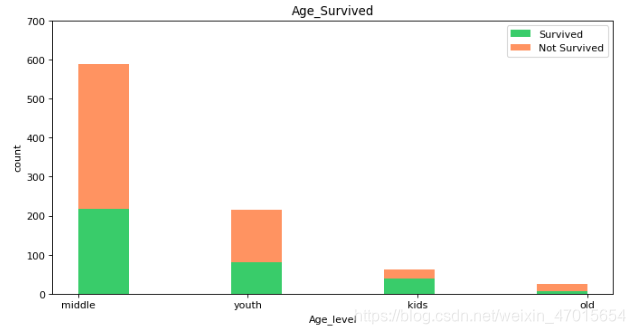
结论4:中年人(24-59岁)的人数最多,获救人数也最多,儿童(0-9岁)的获救率最高。
参考文章:https://blog.csdn.net/jessie0615/article/details/90173259
主要分析有数据接:https://pan.baidu.com/s/1jn88GiOr7uWA8BDQocFXxg 密码: s0e0不同舱位等级中幸存者和遇难者的乘客比例不同性别的幸存比例幸存和遇难旅客的票价分布幸存和遇难乘客的年龄分布不同上船港口的乘客仓位等级分布幸存和遇难乘客堂兄弟姐妹的数量分布幸存和遇难旅客父母子女的数量分布单独乘船与否和幸存之间有没有联系是否成年男性和幸存之间有没有联系
数据接:https://pan.baidu.com/s/1jn88GiOr7uWA8BDQocFXxg 密码: s0e0
首先做准备(导入库,读入数据集)
import matplotlib.pypl
3.2 查看数据基本信息
3.3 绘制年龄分布图,通过seaborn的distplot函数查看乘客的年龄分布
3.4 从上图可以看出年龄呈现正态分布-- 对年龄缺失值进行填充,再次可视化
3.5 根据性别 绘制年龄分布图
3.6 登船地点分布情况(用countplot
Python数据分析实战视频教程,主要以泰坦尼克号之灾结合机器学习算法为案例展开教学,该课程涉及的课程内容1. 泰坦尼克号船员数据与特征2. 数据分析中缺失值,字符值处理(使用pandas库)3. 机器学习经典算法-逻辑回归与决策树4. 使用scikit-learn库建立模型5. 评估和特征分析
20世纪初,由英国白星航运公司制造的一艘巨大豪华客轮。是当时世界上最大的豪华客轮,被称为是“永不沉没的”或是“梦幻客轮”。
泰坦尼克号是人类的美好梦想达到顶峰时的产物,反映了人类掌握世界的强大自信心。她的沉没,向人类展示了大自然的神秘力量,以及命运的不可预测。到泰坦尼克号沉没那天为止,西方世界的人们已经享受了10...
2.特征(features)和标签(labels):
特征:数据的属性,通过这些特征可以代表数据的特点,例如Excel的字段列名,也叫做解释变量或自变量。标签:对数据的预测结果,也叫做因变量。
3.训练数据(train)和测试数据(tset):
训练数据:用于机器学习算法,之后形成我们的机器学...
RMS泰坦尼克号的沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在首次航行期间,泰坦尼克号撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难。这场轰动的悲剧震撼了国际社会,并导致了更好的船舶安全条例。
海难导致生命损失的原因之一是没有足够的救生艇给乘客和机组人员。虽然幸存下来的运气有一些因素,但一些人比其他人更有可能生存,比如妇女,儿童和
数据集中共有12个字段,PassengerId:乘客编号,Survived:乘客是否存活,Pclass:乘客所在的船舱等级;Name:乘客姓名,Sex:乘客性别,Age:乘客年龄,SibSp:乘客的兄弟姐妹和配偶数量,Parch:乘客的父母与子女数量,Ticket:票的编号,Fare:票价,Cabin:座位号,Embarked:乘客登船码头,共有891位乘客的数据信息。其中277位乘客的年龄数据缺...
12.章节12 -结论和步骤7:优化和战略如何使用本教程:请阅读本内核中提供的解释和相关链接。我们的目标不只是知道“是什么”,还要知道“为什么”。如果您不理解代码中的某些内容,那么print()函数是您最好的朋友。在编码中,尝试、失败、再尝试都是必要的过程。如果你遇到了问题,谷歌是你的第二个好朋友,因为99.99%的情况下,其他人都有相同的问题,并且已经向编码社区询问过了。如果您已经尝试了所有资源...
决策树二分类之泰坦尼号克生存预测一、项目简介1.1 项目背景1.2 目标问题1.3 字段描述二、训练集(train)建模2.1 导入相关库2.2 自定义函数2.3 特征工程2.3.1 数据导入2.3.2 数据初探(1)特征信息(2)特征缺失值比例统计(3)数值特征描述统计2.3.3 单特征可视化分析与处理(1)Survived 是否存活(2)Pclass 乘客等级(3)Name 乘客姓名(4)Sex 性别(5)Age 年龄(6)SibSp 堂兄弟妹个数(7)Parch 父母与小孩的个数(8)Ticket 船
这是kaggle上面比较入门的一个比赛。今天让我们来看看怎么做吧。kaggle传送门。首先报名,下载数据集。
数据载入及概述
首先导入从Kaggle上面下载的数据集,在导入的过程中就需要先导入一些必备的包了。
import numpy as np
import pandas as pd
# 接着导入我们的训练数据
filename = 'titanic/train.csv' # 这是我存放的文件路径,这边换成你们自己的
train = pd.read_csv(filename)
from sklearn.tree import DecisionTreeClassifier as DTC #决策树
from sklearn.model_selection import GridSearchCV # 超参数自动搜索模块
from skle
相信很多人都看过泰坦尼克号这部电影,影片以1912年泰坦尼克号邮轮在其处女启航时触礁冰山而沉没的事件为背景,描述了处于不同阶层的两个人——穷画家杰克和贵族女露丝抛弃世俗的偏见坠入爱河,最终杰克把生命的机会让给了露丝的感人故事。
1912年4月10日,号称 “世界工业史上的奇迹”的豪华客轮泰坦尼克号开始了自己的处女航,从英国的南安普顿出发驶往美国纽约。
泰坦尼克号是一艘奥林匹克级邮轮,于1912年4月首航时撞上冰山后沉没。泰坦尼克号由位于北爱尔兰贝尔法斯特的哈兰·沃尔夫船厂兴建,是当时最大的客运轮船,由于其规模相当一艘现代航空母舰,因而号称“上帝也沉没不了的巨型邮轮”。在泰坦尼克号的首航中,从英国南安普敦出发,途经法国瑟堡-奥克特维尔以及爱尔兰昆士敦,计划横渡大西洋前往美国纽约市。但因为人为错误,于1912年4月14日船上时间夜里11点40分撞上...
泰坦尼克号数据集,是kaggle(Titanic: Machine Learning from Disaster)上入门机器学习(ML)的一个好的可选数据集,当然,也是不错的练习数据分析的数据集。对 python ,在数据分析方面,作为一柄利器,涵盖了「数据获取→数据处理→数据分析→数据可视化」这个流程中每个环节, 这风骚的操作,也是没谁了。
这个项目做下来,除了没有涉及到数据抓取(python爬...

