第1关:带 WHERE 子句的多表查询
任务描述
本关任务:使用带 WHERE 子句的多表查询方法,检索数据表中的指定内容。
相关知识
为了完成本关任务,你需要掌握:如何使用带 WHERE 子句的方法查询多表数据。
理解连接
SQL 最强大的功能之一,就是能使用数据检索语句来连接多张数据表。 连接 (Join) 是使用数据库时最重要的操作,所以理解什么情况下,能连接和如何连接是学习 SQL 中极其重要的部分。
在你使用连接查询之前,一定要搞清楚数据表之间的关系。那怎么理解数据表之间是有关系的呢?
举个例子
假设现在你有一张商品的列表,这张列表里包含了每个商品的名称、信息以及价格。现在的问题是,如果这些产品有一部分来自相同的生产厂家,你打算在哪里存储这些厂家的信息(比如厂家地址、信息及联系方式)?
有两种选择,一种是把厂家的信息和产品信息存储在一张数据表里,另一种是建立新的数据表来存储厂家的信息。
不知道你会选哪一种存储方式?
我们推荐选第二种,因为:
有很多商品来自同一厂家,在存储的时候,就势必会造成大量的重复信息涌入商品数据表,这样既浪费时间,又浪费空间;
如果厂家更换了信息(比如地址或者电话),你将要更新每一个出现在商品数据表中的厂家信息,这太费劲儿了!
当信息内容大量重复时,你没有办法保证写入的每一条信息都和其他的一模一样,很有可能会在字符上有些许差异,数据不一致将来很难进行操作。
Tips:
一张数据表里出现多条相同的数据并不是一件好事,这个原则也同样适用于关系数据库的设计。我们推荐把不同种类的信息放在不同的数据表中,但是有关系的两张表,可以被同一种数据所关联。
用WHERE子句创造一个连接
两张数据表是如何被关联起来的呢?
你只需要列出所有被关联到的表,并写出他们是怎样的关系就可以了。抽象吗?
举个例子
我们现在有两张数据表,student 表中存储了学生信息,class 表中存储了班级信息。但是很显然,student 数据表里并没有存储学生的班级,而是学生班级的 id。我们只有将两张表关联起来,才能查询到学生所属的班级,但是,如何将两张数据表关联起来呢?


输入:
SELECT *
FROM student, class
WHERE student.class_id = class.class_id
该例中,我们在 WHERE 关键字后使用student.class_id = class.class_id 语句用来关联这两张表。我们可以理解为,当 student 表与 class 表中的 class_id 字段内容相同时,我们可以将两张表中 class_id 字段对应的内容行拼接成一张表。
输出:

注意到,class 表中的 class_id = 308 的内容行,并没有出现在我们的关联后的新表中。因为 student 表中的 class_id 并没有出现过内容 308 。现在我们可以大大方方的说,我们关联后的表是取了表 student 和表 class 的交集,如下图所示:

检索过程:

有的同学可能会注意到,这里出现了重复的显示项 class_id ,我们将在下一关里介绍如何去掉它。
编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。你只需在右侧 Begin-End 区域内补充代码,用 WHERE 子句关联表 Products 和表 Vendors 。
表 Products 和表 Vendors 的内容如下图所示:


测试说明
测试过程:
本关涉及到的测试文件是 step1_test.sh ,平台将运行用户补全的 step1.sql 文件,得到数据;
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:

参考代码:
USE Mall
SET NOCOUNT ON
--********** Begin **********--
SELECT *
FROM Products, Vendors
WHERE Products.vend_id = Vendors.vend_id
--********** End **********--
第2关:内连接查询
任务描述
本关任务:使用自然连接多表查询方法,检索数据表中的指定内容。
相关知识
为了完成本关任务,你需要掌握:
如何使用等值查询的方法查询多表数据;
如何使用自然查询的方法查询多表数据。
我们之前学到的 WHERE 连接也称为等同连接,这种类型的连接我们一般称它为内连接(Inner Joins),包含关系如下图所示:
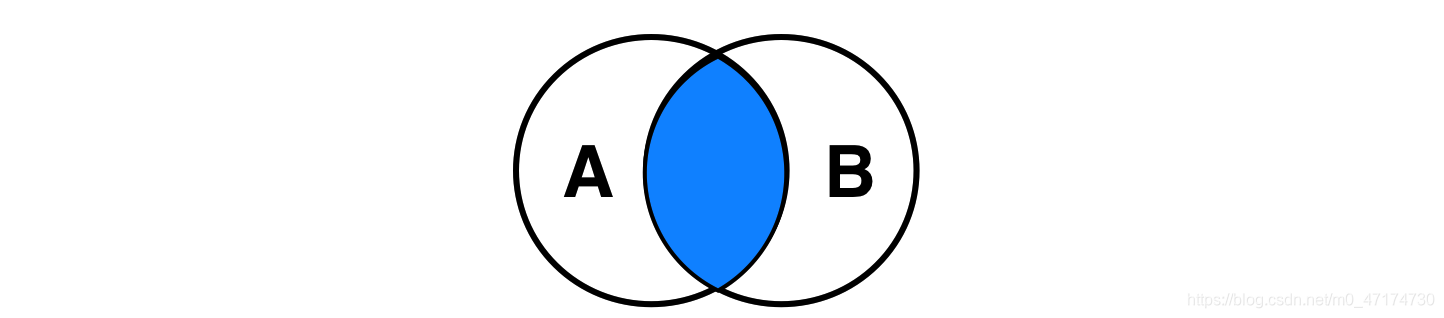
事实上,我们可以使用另一种专门的语法,来表示这种类型的连接。以后你将会学到其他类似的语法,来表示其他类型的连接。
等值连接
等值连接使用 = 来进行比较运算。
举个例子
还记得上一关我们用到的例子吗?在上一关中,为了查询每个学生所对应的班级,我们用 WHERE 语句将表 student 和表 class 关联了起来。


代码如下:
SELECT *
FROM student, class
WHERE student.class_id = class.class_id
现在,我们用内连接查询语法进行查询,你将看见,它返回的结果与上一关一模一样。
输入:
SELECT *
FROM student inner join class
ON student.class_id = class.class_id
在该语法中,我们将两张需要关联的表放在了 join 的两端,并用 ON 代替之前的 WHERE 关键字。
输出:

检索过程:
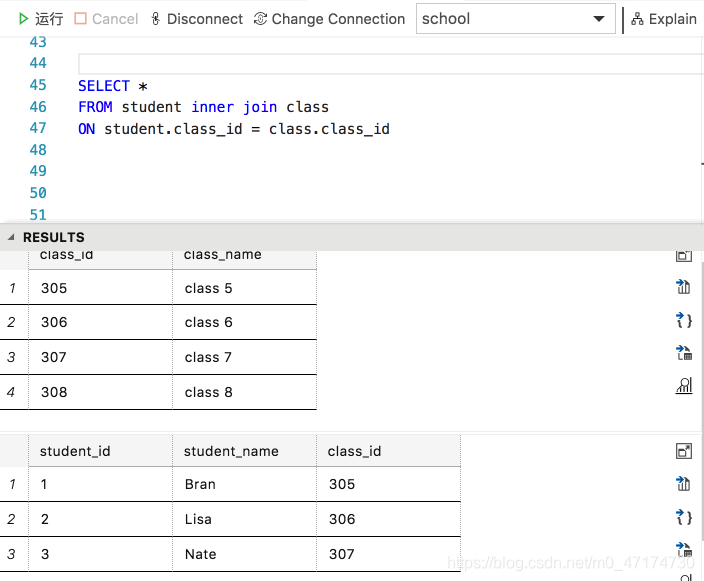
结论:
若要连接表 t1 和表 t2 ,比较条件为 t1.a = t2.a,那么数据库会用 t1 中 a 列的所有元素逐个和 t2 中的 a 列进行比较,如果相等,则输出该行。
不等值连接
在内连接中,如果不使用 = 作为比较运算符,我们就叫它不等值连接。
举个例子
在查询每个学生所对应班级的这个例子中,若使用不等值连接,将会返回: student 表和 class 表中, class_id 字段不相等的所有组合。
输入:
SELECT *
FROM student inner join class
ON student.class_id <> class.class_id
输出:
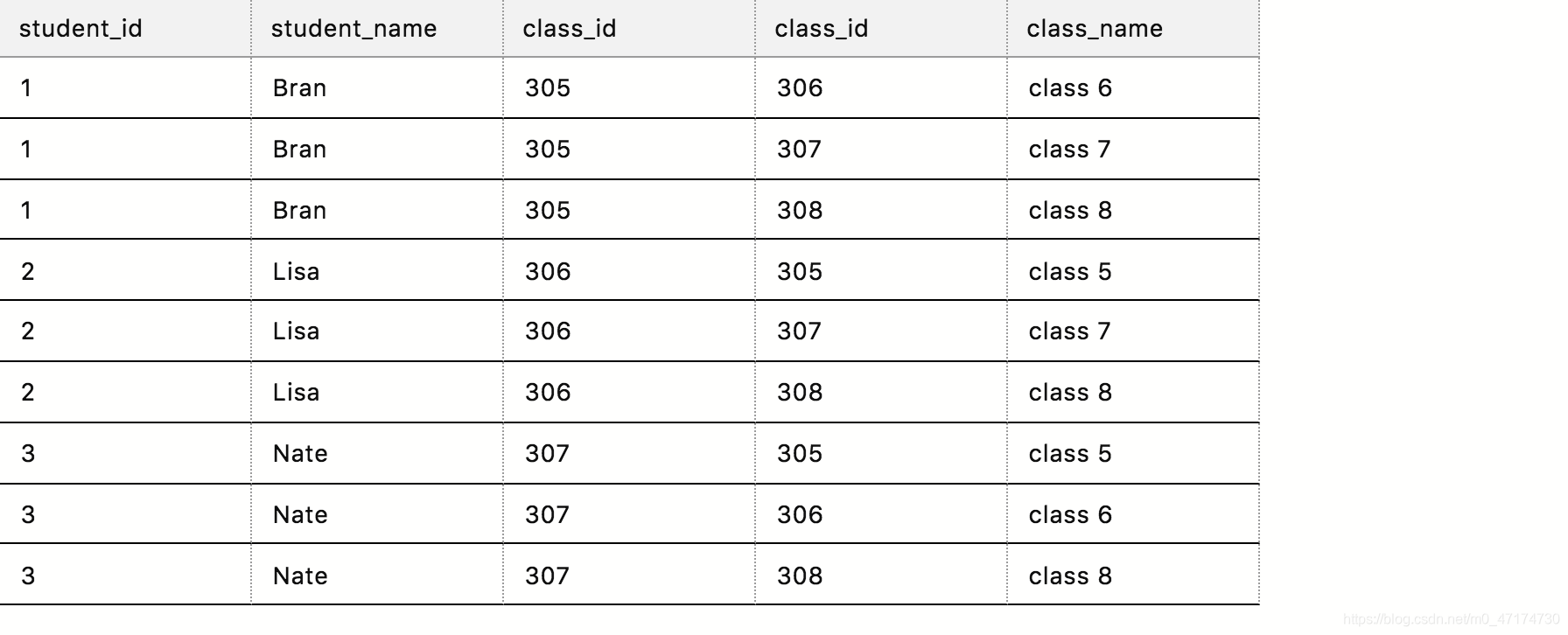
检索过程:
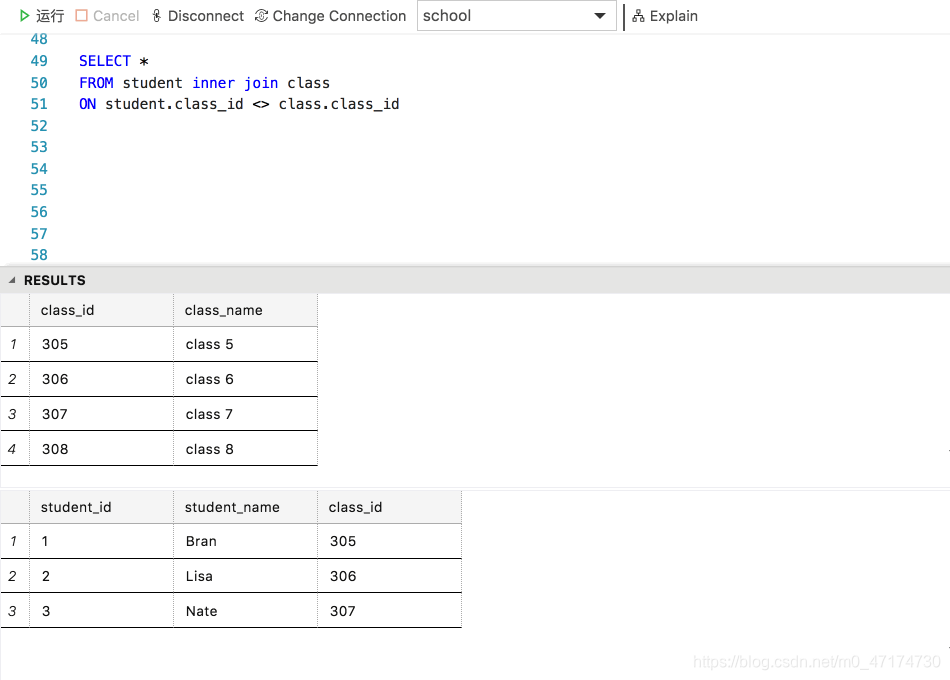
结论:
若要连接表 t1 和 t2 ,比较条件为 t1.a <> t2.a,那么数据库会用 t1 中 a 列的所有元素逐个和 t2 中的 a 列进行比较,如果不相等,则输出该行。
自然连接
自然连接是一种特殊的等值连接,但与等值连接及其类似。大家可能已经注意到,我们之前的连接查询结果,都会出现两列重复的 class_id ,但在自然连接查询结果中,我们将只能看见一列 class_id。
怎么做到的呢?自然连接,相当于在等值连接的基础上,加了显示的限定条件,从而实现了列去重。
它还和等值查询有一个明显的区别:
自然连接要求比较的两个列属性必须相同,等值连接则不需要。
举个例子
查询每个学生所对应的班级:
输入:
SELECT student.*, class.class_name
FROM student inner join class
ON student.class_id = class.class_id
输出:

检索过程:
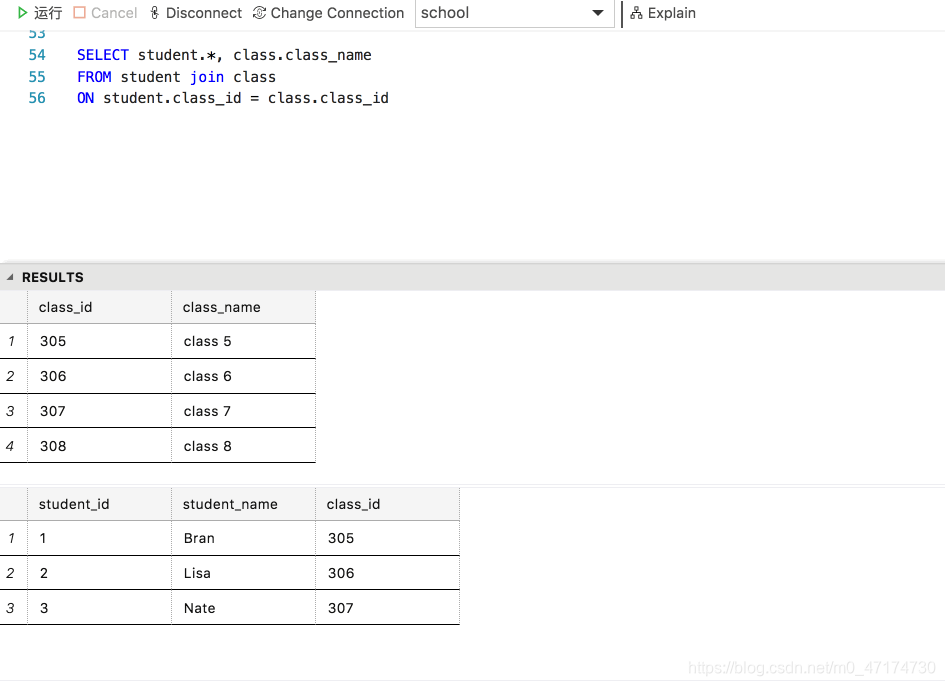
编程要求
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。你只需在右侧 Begin-End 区域内补充代码,用自然连接关联表 Products 和表 Vendors 。
表 Products 和表 Vendors 的内容如下图所示:
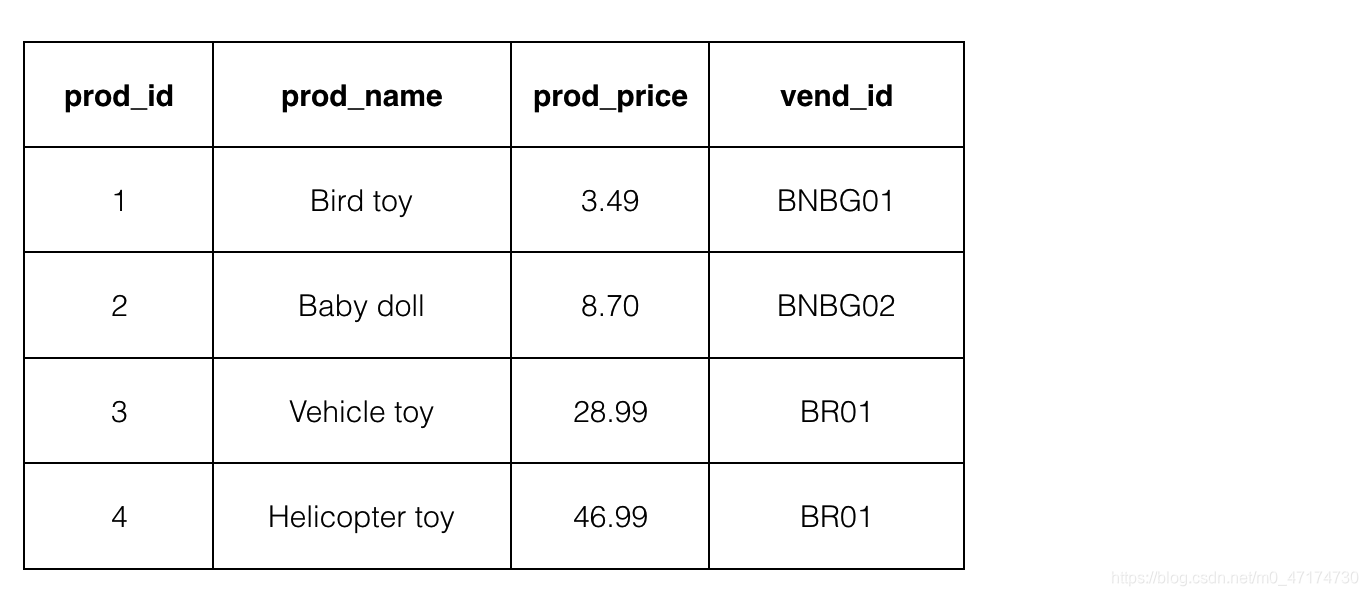
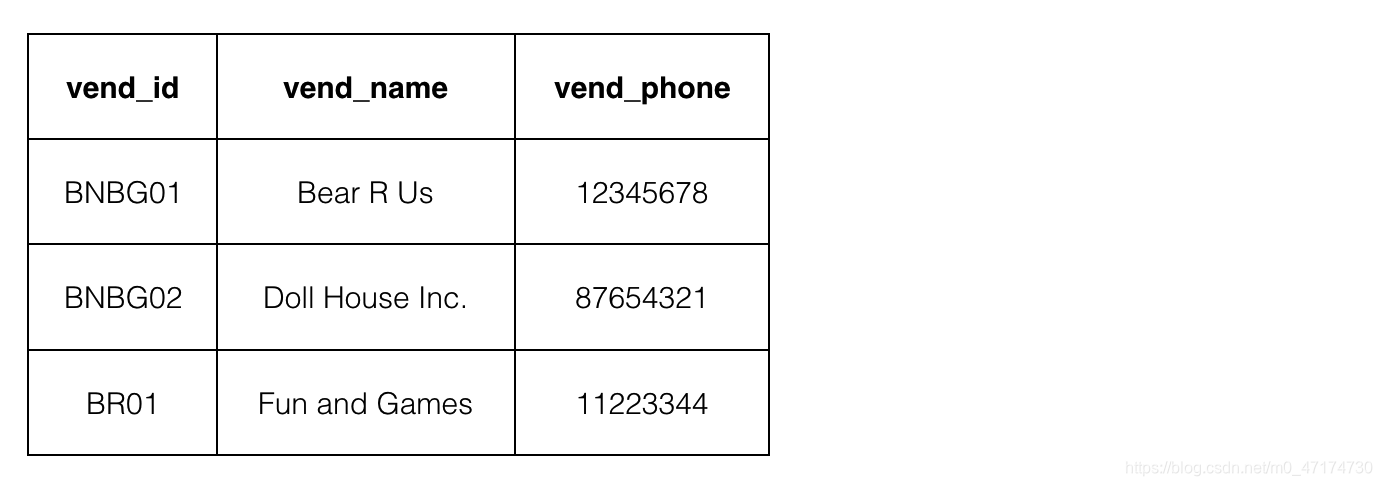
测试说明
本关涉及到的测试文件是 step2_test.sh ,平台将运行用户补全的 step2.sql 文件,得到数据;
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:

参考代码:
USE Mall
SET NOCOUNT ON
--********** Begin **********--
SELECT Products.*,Vendors.vend_name,Vendors.vend_phone
FROM Products inner join Vendors
ON Products.vend_id = Vendors.vend_id
--********** End **********--
第3关:外连接查询
任务描述
本关任务:使用左连接和右连接多表查询方法,检索数据表中的指定内容。
相关知识
为了完成本关任务,你需要掌握:
如何使用左连接查询的方法查询多表数据;
如何使用右连接查询的方法查询多表数据。
有的时候,我们不仅想知道在两张表中,什么内容是可以匹配查询到的。还想知道那些没有被关联到的内容是什么?比如在百货公司里,我们不仅想知道哪些商品被顾客买走了,还想知道那些没有买走的东西是什么,以调整将来的供货策略。
左连接
左连接以左表为基础,显示左表中的所有记录:
显示的记录条数 = 左表中记录的条数
再用左表中的指定列,来和右表中的指定列比较。满足,则输出值;不满足,则输出 NULL。
举个例子
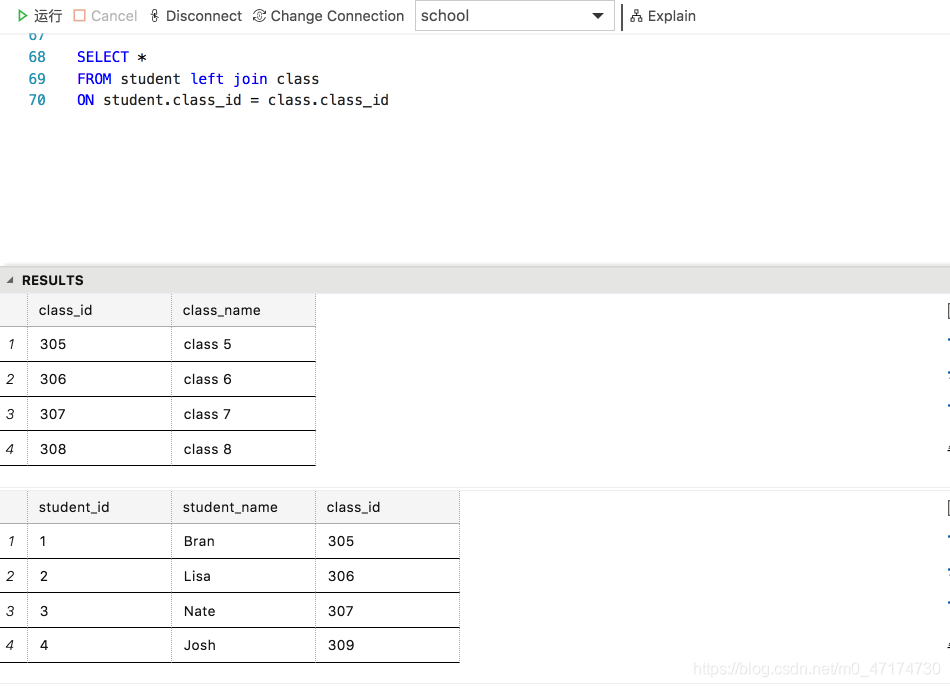
如果你有两张表,分别为表 student 和表 class ,要查出每个学生所对应的班级名称,用左连接应该怎么做?


输入:
SELECT *
FROM student left join class
ON student.class_id = class.class_id
输出:
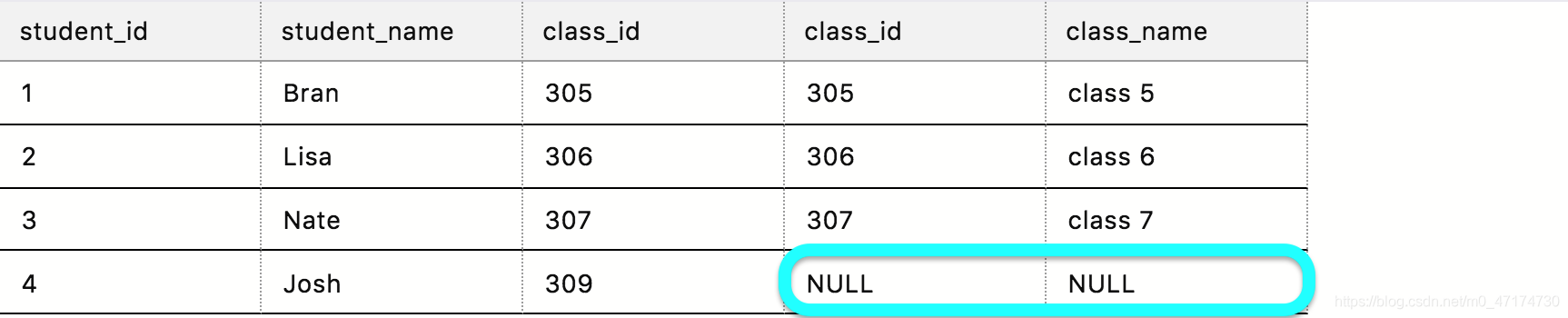
在这里,左表的第 4 条记录并没有匹配到右表的任何内容,所以右表的相应内容显示为 NULL 。
检索过程:
右连接
右连接与左连接正好相反,右连接以右表为基础,显示右表中的所有记录:
显示的记录条数 = 右表中记录的条数
再用右表中的指定列,来和左表中的指定列比较。满足,则输出值;不满足,则输出 NULL。
举个例子
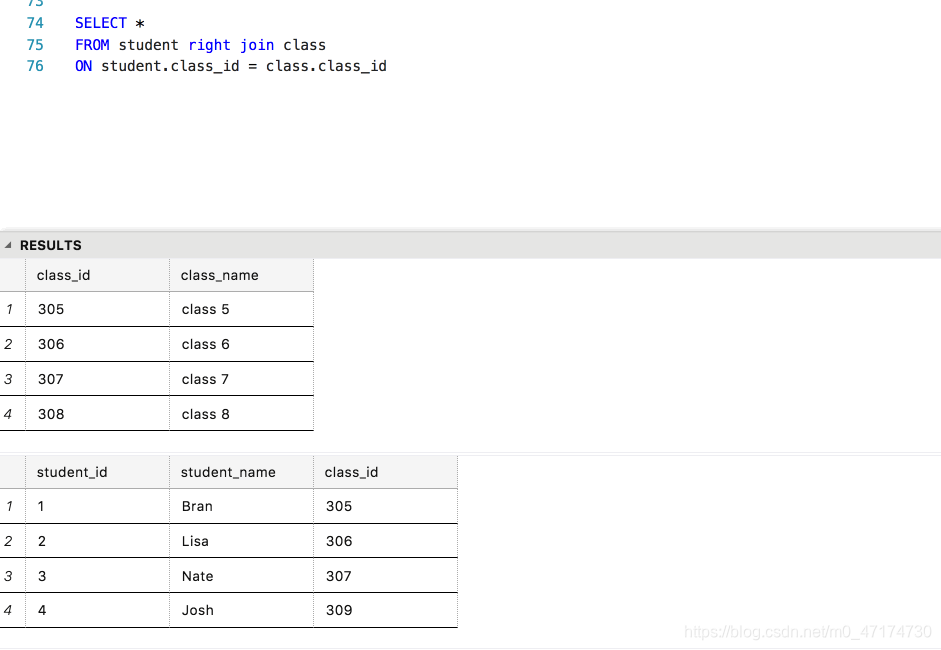
如果你想连接表 student 和表 class 查询每个学生所对应的班级名称,用右连接应该怎么做?会与左连接查询有多大的区别呢?


输入:
SELECT *
FROM student right join class
ON student.class_id = class.class_id
输出:
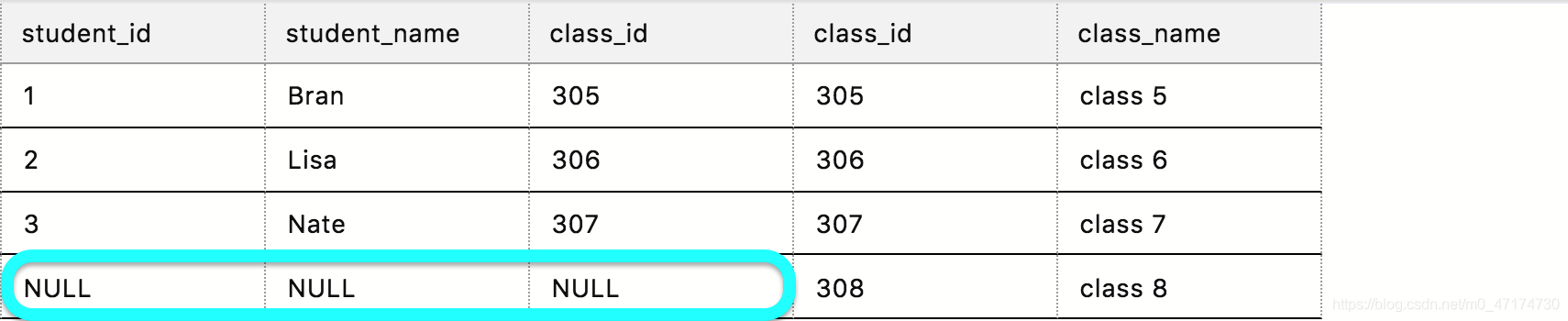
在这里,右表的第 4 条记录并没有匹配到左表的任何内容,所以左表的相应内容显示为 NULL 。
检索过程:
全连接
全连接类似于左连接和右连接的综合:
显示记录的条数 = 指定比较字段在两个表中的不同种类数
对于空余字段,则显示 NULL 。也就是说,它能返回两个表中所有的关联信息,以及所有没有被关联到的信息。
举个例子
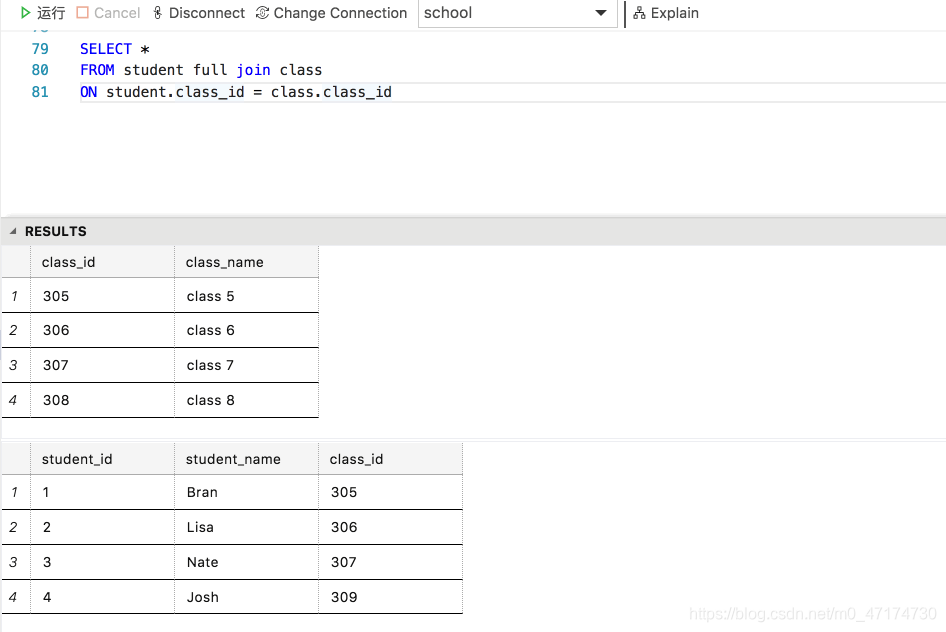
我们现在用全连接查询方法,连接表 student 和表 class,查询每个学生所对应的班级名称:


输入:
SELECT *
FROM student full join class
ON student.class_id = class.class_id
输出:
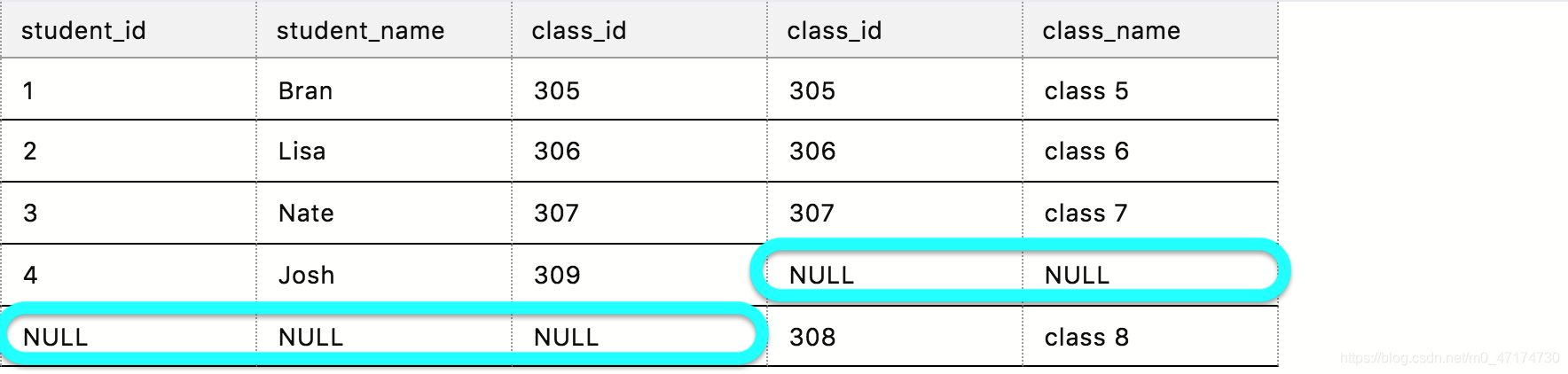
检索过程:
编程要求
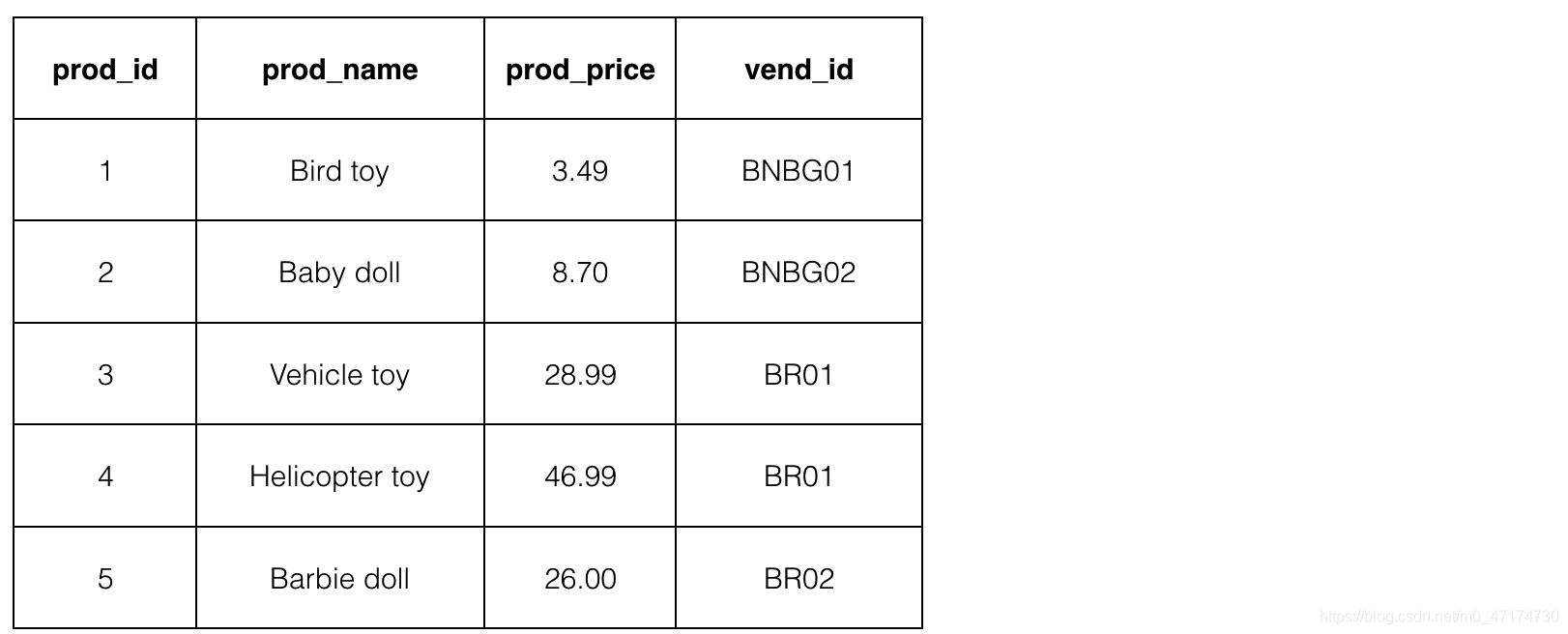
我们已经为你建好了数据库与数据表,并添加了相应的数据内容。你只需根据提示,在右侧 Begin-End 区域内补充代码,分别用左连接和右连接关联表 Products 和表 Vendors。
表 Products 和表 Vendors 的内容如下图所示:

测试说明
本关涉及到的测试文件是 step3_test.sh,平台将运行用户补全的 step3.sql 文件,得到数据;
将得到的数据与答案比较,判断代码是否正确。
如果操作正确,你将得到如下的结果:

参考代码:
USE Mall
SET NOCOUNT ON
--********** 左连接 **********--
--********** Begin **********--
SELECT *
FROM Products left join Vendors
ON Products.vend_id = Vendors.vend_id
--********** End **********--
--********** 右连接 **********--
--********** Begin **********--
SELECT *
FROM Products right join Vendors
ON Products.vend_id = Vendors.vend_id
--********** End **********--
第1关:带 WHERE 子句的多表查询任务描述本关任务:使用带 WHERE 子句的多表查询方法,检索数据表中的指定内容。相关知识为了完成本关任务,你需要掌握:如何使用带 WHERE 子句的方法查询多表数据。理解连接SQL 最强大的功能之一,就是能使用数据检索语句来连接多张数据表。 连接 (Join) 是使用数据库时最重要的操作,所以理解什么情况下,能连接和如何连接是学习 SQL 中极其重要的部分。在你使用连接查询之前,一定要搞清楚数据表之间的关系。那怎么理解数据表之间是有关系的呢?举个例子
再用PD建表完成后导成SQL脚本然后在SQL Server中运行后生成数据库后,就想到,可不可以将直接将数据库的内容生成PD文档?经过上网查,当然可以的。
要将SQL Server中的数据库导入到PD中,首先需要建立一个数据库的链接,然后进行逆向工程的操作。下面开始操作。
第一步:打开数据库菜单,选择“Configure Connections”
第二步:创建新的ODBC链接
第三步:选择系统数据源
第四步:选择需要的数据库
第五步:“完成”
第六步:命名数据源,并选择服务器
第七步:选择登陆方式,并数据登录名和密码
SET NOCOUNT ON
---------- retrieving multiple column ----------
-- ********** Begin ********** --
select prod_name,prod_price from Products
-- ********** End ********** --
---------- retrieving all column ----------
为了完成本关任务,你需要掌握:1. AVG() 函数的含义,2. AVG() 函数的用法。
返回某一字段的平均值
AVG() 函数通过计算某字段(列)内容(行)的个数和它们的数值之和来返回某一字段的平均值。
语法规则为:
SELECT AVG(column_name)
FROM table_name
我们想从表 Customers 中,检索到所有消费者消费金额的平均值。
表 Cust
完整表格见博文:https://blog.csdn.net/weixin_44410704/article/details/118252624
一、实验目的
1、掌握Select语句的基本语法;
2、掌握连接查询的表示和使用方法;
3、掌握子查询的表示和使用方法。
二、实验准备
1、理解Select语句的基本语法格式和执行方法;
2、理解连接查询的表示;
3、理解子查询的表示方法。
三、实验内容
基于Student_DB 数据库中的三个表Student,Course,SC,进行如下的查询:
(给出查询语句及
1.掌握SQL Server 2005的安装。
2.掌握SQL Server Management Studio的启动和使用。
3.掌握SQL Server 2005服务器的配置和注册。
4.掌握SQL Server 2005查询的基本使用。
5.掌握应用SQL Server Management Studio创建数据库的方法。
6.掌握应用SQL Server Management Studio修改和查看数据库的方法。
7.掌握应用SQL Server Management Studio删除数据库的方法。
8.掌握应用Transact-SQL语句创建数据库的方法。
9.掌握应用Transact-SQL修改和查看数据库的方法。
10.掌握通过Transact-SQL删除数据库的方法。
11.掌握SQL Server 2005数据库和操作系统物理文件的关系。
12.掌握数据库的分离和附加方法。
二、实验内容
1.完成SQL Server 2005开发版的安装。
提示:若计算机系统中已经安装有SQL Server 2005系统,则在安装时需要选择安装命名实例。安装过程中身份验证模式选择“混合模式”并设置sa账户的密码。
2.利用SQL Server配置管理器启动、停止SQL Server服务(包括默认实例和命名实例),配置SQL Server服务为自动启动。
3.利用SQL Server配置管理器配置进行SQL Server 2005网络配置,启用默认实例和命名实例的TCP/IP协议。
4.利用SQL Server外围配置器配置数据库引擎的服务及远程连接,设置为“本地连接和远程连接”,选择“同时使用TCP/IP和named pipes”。
5.利用SQL Server Management Studio注册安装的命名实例。
6.利用SQL Server Management Studio注册远程服务器。
提示:注册远程服务器时需要使用混合验证模式,利用sa账户和密码登录远程服务器。
7.启动SQL Server Management Studio,连接到服务器。新建一个查询,在其中输入如下代码:
DECLARE @position int, @string char(5)
SET @position = 1
SET @string = 'China'
WHILE @position <= DATALENGTH(@string)
BEGIN
SELECT SUBSTRING(@string, @position, 1) 字符,
ASCII(SUBSTRING(@string, @position, 1)) ASCII码
SET @position = @position + 1
15.3.2 使用create procedure创建存储过程 309
15.3.3 使用execute语句调用存储过程 310
15.3.4 使用create function创建函数 312
15.3.5 使用enterprise manager创建存储过程和函数 315
15.3.6 修改和删除存储过程和函数 317
15.4 oracle中的流控制语句 319
15.4.1 条件语句 319
15.4.2 循环语句 320
15.4.3 标号和goto 322
15.5 oracle数据库中的存储过程 322
15.5.1 存储过程的创建与调用 322
15.5.2 oracle中存储过程和函数的管理 324
第16章 sql触发器 325
16.1 触发器的基本概念 325
16.1.1 触发器简介 325
16.1.2 触发器执行环境 325
16.2 sql server中的触发器 326
16.2.1 sql server触发器的种类 326
16.2.2 使用create trigger命令创建触发器 326
16.2.3 insert触发器 328
16.2.4 delete触发器 329
16.2.5 update触发器 330
16.2.6 instead of触发器 332
16.2.7 嵌套触发器 334
16.2.8 递归触发器 336
16.2.9 sql server中触发器的管理 338
16.3 oracle数据库中触发器的操作 340
16.3.1 oracle触发器类型 340
16.3.2 触发器的创建 341
16.3.3 创建系统触发器 342
16.3.4 触发器的触发次序和触发谓词的使用 343
16.3.5 oracle触发器的管理 346
第17章 sql中游标的使用 349
17.1 sql游标的基本概念 349
17.1.1 游标的概念 349
17.1.2 游标的作用及其应用 350
17.2 sql游标的使用 351
17.2.1 使用declare cursor语句创建游标 351
17.2.2 使用open/close语句打开/关闭游标 352
17.2.3 使用fetch语句检索数据 352
17.2.4 基于游标的定位delete语句 354
17.2.5 基于游标的定位update语句 356
17.3 sql server中游标的扩展 357
17.3.1 transact_sql扩展declare cursor语法 357
17.3.2 @@cursor_rows全局变量确定游标的行数 359
17.3.3 @@fetch_status全局变量检测fetch操作的状态 360
17.3.4 游标的关闭与释放 361
17.3.5 游标变量 362
17.3.6 使用系统过程管理游标 363
17.4 oracle中游标的使用 365
17.4.1 显式游标与隐式游标 365
17.4.2 游标的属性 366
17.4.3 %type、%rowtype定义记录变量 367
17.4.4 参数化游标 368
17.4.5 游标中的循环 369
17.4.6 游标变量 371
17.5 小结 372
第18章 事务控制与并发处理 373
18.1 sql事务控制 373
18.1.1 事务控制的引入 373
18.1.2 事务的特性 373
18.1.3 sql中与事务有关的语句 374
18.2 事务控制的具体实现 376
18.2.1 开始事务 376
18.2.2 set constraints语句设置约束的延期执行 377
18.2.3 终止事务 378
18.3 并发控制 380
18.3.1 并发操作的问题 381
18.3.2 事务隔离级别 382
18.3.3 set transaction设置事务属性 383
18.4 sql server中的并发事务控制 384
18.4.1 锁的分类 384
18.4.2 sql server中表级锁的使用 385
18.4.3 设置隔离级别实现并发控制 387
18.4.4 死锁及其预防 391
18.5 oracle中的并发事务控制 393
18.5.1 通过加锁避免写数据丢失 393
18.5.2 设置只读事务(read only) 394
18.5.3 oracle中的隔离级别 395
第19章 嵌入式sql 397
19.1 sql的调用 397
19.1.1 直接调用sql 397
19.1.2 嵌入式sql 398
19.1.3 sql调用层接口(cli) 399
19.2 嵌入式sql的使用 401
19.2.1 创建嵌入式sql语句 401
19.2.2 sql通信区 402
19.2.3 主变量 404
19.2.4 嵌入式sql中使用游标 406
19.3 检索、操作sql数据 407
19.3.1 不需要游标的sql dml操作 407
19.3.2 使用游标的sql dml操作 410
19.3.3 动态sql技术 412
19.4 sql server中嵌入式sql的编译运行 413
19.4.1 嵌入式sql代码 413
19.4.2 预编译文件 415
19.4.3 设置visual c++ 6.0连接 417
19.4.4 编译运行程序 419
19.5 oracle中嵌入式sql的编译运行 420
19.5.1 嵌入式sql代码 420
19.5.2 预编译文件 421
19.5.3 设置visual c++ 6.0编译环境 423
19.5.4 编译运行程序 424
附录a sql保留字 427
附录b 常用的sql命令 431
附录c 关于运行环境的说明 435
c.1 sql server 2000 435
c.1.1 直接访问 435
c.1.2 从企业管理器访问 436
c.2 oracle系统 436

