实时手形与动作跟踪方案,一直是手语识别与手势控制系统中最为核心的组成部分,同时在部分增加现实体验中也扮演着重要角色。然而,现有技术往往因为遮挡或者缺乏对比模式等问题的困扰,无法提供理想的可靠性。
面对这一现实挑战,谷歌公司的科学家们研究出一种新的计算机视觉方法,用于实现手部感知。作为幕后推手,机器学习技术为提供了强大助力。根据介绍,该方案能够在实机实验中仅凭一帧图像识别出一只手(或者多只手)上的21个3D点位。与目前市面的手势识别技术相比,谷歌的全新技术不需要依赖台式机来计算,只要在手机上就能进行实时追踪,并且还能同时追踪多只手,可识别遮挡。
研究工程师Valentin Bazarevsky和Fan Zhang在博文他们的当中写道:“感知手部形状与运动姿态的能力,有望成为改善各类技术表现及平台用户体验的重要助力。我们希望将这种手部感知功能交付至更为广泛的研究与开发社区处,利用大家的力量共同促进创新用例的出现,刺激新的应用方式并开拓出前所未有的研究途径。”
据了解,谷歌的这一技术包含三套串联工作的AI模型:一个手掌探测模型(BlazePalm)用于分析框体并返回手部动作边框;一个手部标记模型(Landmark),用于查看由手掌探测器定义的裁剪后图像区域,并返回3D位点;一个手势识别模型,用于将之前计算得出的位点归类为一组手势。
BlazePalm:手部识别绝不像听起来那么简单。GlazePalm必须能够解决手部遮挡这一现实难题。为此,谷歌团队训练出一款手掌探测器BlazePalm——注意,是手掌而不是手部。他们认为,对拳头这类物体进行边界框描绘,在难度上要比跟踪手指低得多。具体地,BlazePalm可以识别多种不同手掌大小,具备较大的缩放范围,还能识别手部遮挡,能通过识别手臂、躯干或个人特征等信息准确定位手部。除此之外,这种方式还有另一大优势,就是能够很好地兼容握手等特殊场景,利用忽略其它宽高比条件的方形边框模拟手掌,从而将所需的3D点数缩减至以往的三分之一到五分之一。据统计,经过训练之后,BlazePalm识别手掌的准确率可以达到95.7%。
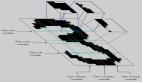
Landmark:在手掌检测之后,手部标记模型开始接管,负责在检测到的手部区域之内建立21个由手到肘的3D定位坐标。在训练当中,模型要求研究人员手动注释多达3万份真实场景下的图像,并立足多种背景对相应坐标进行渲染和映射,最终创建出高质量的合成手部模型。据统计,在经过训练后,算法的平均回归误差可降低到13.4%。
手势识别模型:流水线上的最后一步是手势识别,该模型利用关节旋转角度来确定每根手指的状态(如弯曲或伸直),并将手指状态集合与预定义的手势映射起来,进而预测基础的静态手势。Bazarevsky和Zhang介绍称,该模型能够识别来自多种文化(例如美国、欧洲与中国)的算数手势,以及握拳、“OK”、“摇滚”、“蜘蛛侠”等常见手势。
除此之外,这些模型也可以执行对应的单独任务,例如利用显卡进行图像裁剪与渲染,从而节约计算资源;并且,手掌探测模型只有在必要时才运行——因为在大多数时段内,后续视频帧内的手部位置只凭计算出的手部关键点即可推理得出,不再需要手掌探测器的参与。也就是说,只有当推理置信度低于某个阈值时,手部检测模型才会重新介入。
展望未来,Bazarevsky、Zhang及其团队还计划建立更强大且、更稳定的跟踪扩展技术,同时增加能够可靠检测出的手势数量,并考虑支持即时动态手势识别。他们总结道:“我们相信,这项技术的发布将为研究及开发者社区带来助力,帮助他们发现更多新的创意与应用方向。”