

第八章 Flink - Sink数据目标

Flink针对DataStream提供了大量的已经实现的数据目标(Sink),包括文件、Kafka、Redis、HDFS、Elasticsearch等等。
flink官网: https:// flink.apache.org/
在官网左侧,document下选择版本,目前是1.13。如果想看之前版本的文档,直接修改url中的版本号即可查看。


1) 基于HDFS的Sink( StreamingFileSink )
首先配置支持Hadoop FileSystem的连接器依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.11</artifactId>
<version>1.9.1</version>
</dependency>这个连接器提供了一个 Sink 来将分区文件写入到支持 Flink FileSystem 接口的文件系统中。
Streaming File Sink 会将数据写入到桶中。由于输入流可能是无界的,因此 每个桶中的数据被划分为多个有限大小的文件 。如何分桶是可以配置的, 默认使用基于时间的分桶策略 ,这种策略 每个小时创建一个新的桶 ,桶中包含的文件将记录所有该小时内从流中接收到的数据。
桶目录中的实际输出数据会被划分为多个部分文件(part file) ,每一个接收桶数据的 Sink Subtask , 至少包含一个部分文件(part file)。额外的部分文件(part file)将根据滚动策略创建, 滚动策略是可以配置的。默认的策略是 根据文件大小和超时时间来滚动文件 。超时时间指打开文件的最长持续时间,以及文件关闭前的最长非活动时间。
重要: 使用 StreamingFileSink 时需要启用 Checkpoint ,每次做 Checkpoint 时写入完成。如果 Checkpoint 被禁用,部分文件(part file)将永远处于 ‘in-progress’ 或 ‘pending’ 状态,下游系统无法安全地读取。
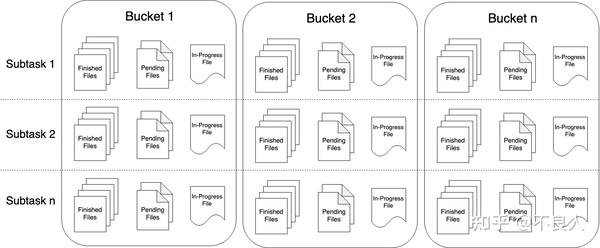
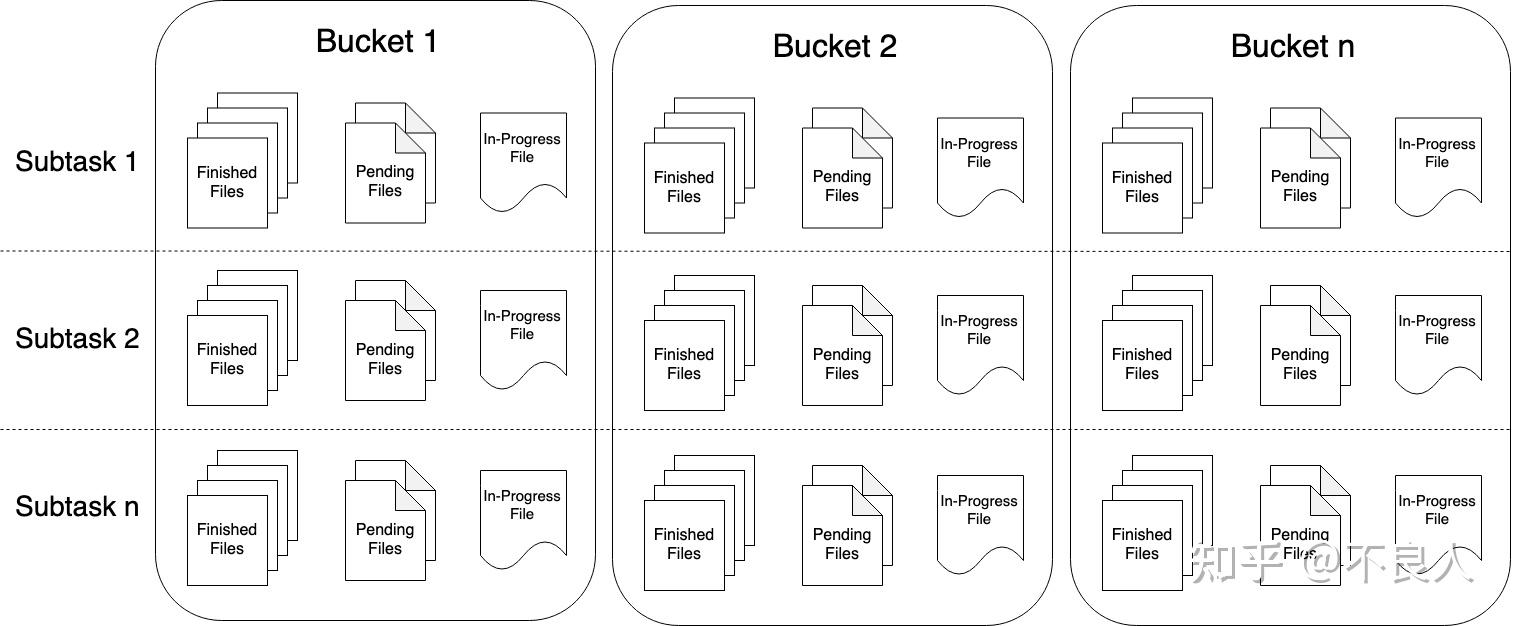
文件格式
StreamingFileSink
支持行编码格式和批量编码格式( 如
Apache Parquet
) 。
-
Row-encoded sink:
StreamingFileSink.forRowFormat(basePath, rowEncoder) -
Bulk-encoded sink:
StreamingFileSink.forBulkFormat(basePath, bulkWriterFactory)
创建行或批量编码的 Sink 时,我们需要指定存储桶的基本路径和数据的编码逻辑。
行编码格式 (Row-encoded sink)
行编码格式需要指定一个
Encoder
。Encoder 负责为每个处于 In-progress 状态文件的
OutputStream
序列化数据。
除了桶分配器之外,
RowFormatBuilder
还允许用户指定:
-
Custom
RollingPolicy:自定义滚动策略以覆盖默认的 DefaultRollingPolicy - bucketCheckInterval (默认为1分钟):毫秒间隔,用于基于时间的滚动策略。
字符串元素写入示例:
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
val input: DataStream[String] = ...
val sink: StreamingFileSink[String] = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build()
input.addSink(sink)这个例子创建了一个简单的 Sink ,将记录分配给默认的一小时时间桶。它还指定了一个滚动策略,该策略在以下三种情况下滚动处于 In-progress 状态的部分文件(part file):
- 它至少包含 15 分钟的数据
- 最近 5 分钟没有收到新的记录
- 文件大小达到 1GB (写入最后一条记录后)
批量编码格式 (Bulk-encoded sink)
批量编码 Sink 的创建与行编码 Sink 相似,不过在这里我们不是指定编码器
Encoder
而是指定 BulkWriter.
Factory
。
BulkWriter
定义了如何添加、刷新元素,以及如何批量编码。
Flink 有四个内置的 BulkWriter Factory :
-
ParquetWriterFactory -
AvroWriterFactory -
SequenceFileWriterFactory -
CompressWriterFactory -
OrcBulkWriterFactory
重要: 批量编码模式仅支持 OnCheckpointRollingPolicy 策略, 在每次 checkpoint 的时候切割文件。
Parquet 格式
Flink 包含为不同 Avro 类型,创建 ParquetWriterFactory 的便捷方法,更多信息请参考
ParquetAvroWriters
。
要编写其他 Parquet 兼容的数据格式,用户需要创建 ParquetWriterFactory 并实现
ParquetBuilder
接口。
在应用中使用 Parquet 批量编码器,你需要添加以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.11</artifactId>
<version>1.13.2</version>
</dependency>这个例子使用 StreamingFileSink 将 Avro 数据写入 Parquet 格式:
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.formats.parquet.avro.ParquetAvroWriters
import org.apache.avro.Schema
val schema: Schema = ...
val input: DataStream[GenericRecord] = ...
val sink: StreamingFileSink[GenericRecord] = StreamingFileSink
.forBulkFormat(outputBasePath, ParquetAvroWriters.forGenericRecord(schema))
.build()
input.addSink(sink)除了上述schema的方式,还可以通过反射的方式创建parquet格式。例如:
DataStream<GenericRecord> stream = ...;
final StreamingFileSink<GenericRecord> sink = StreamingFileSink
.forBulkFormat(outputBasePath,ParquetAvroWriters.forReflectRecord(MyBean.class))
.build();
input.addSink(sink);类似的,将 Protobuf 数据写入到 Parquet 格式可以通过:
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.formats.parquet.protobuf.ParquetProtoWriters
// ProtoRecord is a generated protobuf Message class.
val input: DataStream[ProtoRecord] = ...
val sink: StreamingFileSink[ProtoRecord] = StreamingFileSink
.forBulkFormat(outputBasePath, ParquetProtoWriters.forType(classOf[ProtoRecord]))
.build()
input.addSink(sink)Bucket Assignment:(分桶策略)
桶分配逻辑定义了如何将数据结构化为基本输出目录中的子目录
行格式和批量格式都使用
DateTimeBucketAssigner
作为默认的分配器。 默认情况下,DateTimeBucketAssigner 基于系统默认时区每小时创建一个桶,格式如下:
yyyy-MM-dd--HH
。日期格式(即桶的大小)和时区都可以手动配置。
我们可以在格式构建器上调用
.withBucketAssigner(assigner)
来自定义
BucketAssigner
。
Flink 有两个内置的 BucketAssigners :
-
DateTimeBucketAssigner:默认基于时间的分配器 -
BasePathBucketAssigner:将所有部分文件(part file)存储在基本路径中的分配器(单个全局桶)
除此之外,还可以实现BucketAssigner接口,自定义分桶策略。
滚动策略
滚动策略
RollingPolicy
定义了指定的文件在何时关闭(closed)并将其变为 Pending 状态,随后变为 Finished 状态。处于 Pending 状态的文件会在下一次 Checkpoint 时变为 Finished 状态,通过设置 Checkpoint 间隔时间,可以控制部分文件(part file)对下游读取者可用的速度、大小和数量。
Flink 有两个内置的滚动策略:
-
DefaultRollingPolicy: 当超过文件大小(默认为 128 MB),或超过了滚动周期(默认为 60 秒),或未写入数据处于不活跃状态超时(默认为 60 秒)的时候,滚动文件; -
OnCheckpointRollingPolicy: 当 checkpoint 的时候,滚动文件。
部分文件(part file) 生命周期
为了在下游系统中使用 StreamingFileSink 的输出,我们需要了解输出文件的命名规则和生命周期。
部分文件(part file)可以处于以下三种状态之一:
- In-progress :当前文件正在写入中
- Pending :当处于 In-progress 状态的文件关闭(closed)了,就变为 Pending 状态
- Finished :在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态
处于 Finished 状态的文件不会再被修改,可以被下游系统安全地读取。
重要: 部分文件的索引在每个 subtask 内部是严格递增的(按文件创建顺序)。但是索引并不总是连续的。当 Job 重启后,所有部分文件的索引从 `max part index + 1` 开始, 这里的 `max part index` 是所有 subtask 中索引的最大值。
对于每个活动的桶,Writer 在任何时候都只有一个处于 In-progress 状态的部分文件(part file),但是可能有几个 Penging 和 Finished 状态的部分文件(part file)。
部分文件(part file)例子
为了更好地理解这些文件的生命周期,让我们来看一个包含 2 个 Sink Subtask 的简单例子:


当部分文件
part-1-0
被滚动(假设它变得太大了)时,它将成为 Pending 状态,但是它还没有被重命名。然后 Sink 会创建一个新的部分文件:
part-1-1
:
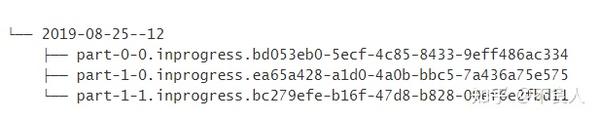
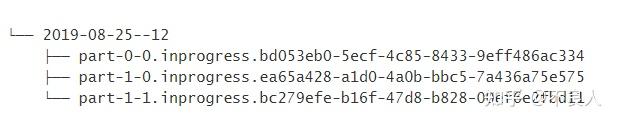
part-1-0
现在处于 Pending 状态等待完成,在下一次成功的 Checkpoint 后,它会变成 Finished 状态:


根据分桶策略创建新的桶,但是这并不会影响当前处于 In-progress 状态的文件:
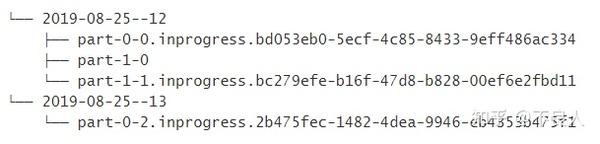
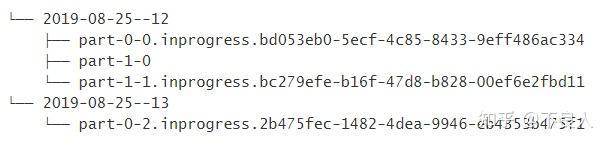
因为分桶策略基于每条记录进行评估,所以旧桶仍然可以接受新的记录。
部分文件的配置项
可以通过命名,将Finished的文件与in-progress的文件区分开。默认:
- In-progress / Pending:part-<subtaskIndex>-<partFileIndex>.inprogress.uid
- Finished:part-<subtaskIndex>-<partFileIndex>
Flink 允许用户通过
OutputFileConfig
指定部分文件名的前缀和后缀。 举例来说,前缀设置为 “prefix” 以及后缀设置为 “.ext” 之后,Sink 创建的文件名如下所示:
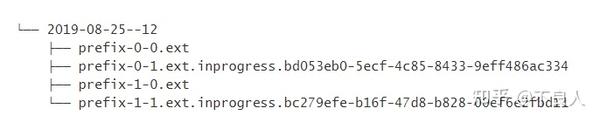
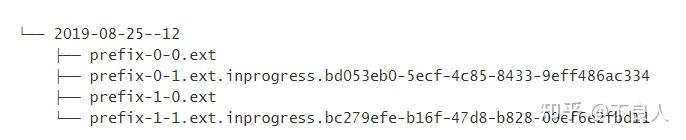
用户可以通过如下方式设置
OutputFileConfig
:
val config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".ext")
.build()
val sink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withBucketAssigner(new KeyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(config)
.build()2) 基于Kafka的Sink
由于前面已经讲过Flink的Kafka连接器,所以还是一样需要配置Kafka连接器的依赖配置,接下我们还是把WordCout的结果写入Kafka:
package com.jht.flink.sink
import java.lang
import java.util.Properties
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaProducer, KafkaSerializationSchema}
import org.apache.flink.streaming.util.serialization.KeyedSerializationSchema
import org.apache.kafka.clients.producer.ProducerRecord
object KafkaSink1 {
//从netcat中读取数据,统计单词的数量,写入Kafka
def main(args: Array[String]): Unit = {
//初始化Flink流计算环境
val streamEvn: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//设置默认的分区
//读取流数据
val ds: DataStream[String] = streamEvn.socketTextStream("hadoop101",9999)
//转换计算
val result: DataStream[(String, Int)] = ds.flatMap(_.split(" ")).filter(_.nonEmpty)
.map((_, 1))
.keyBy(0)//分组:必须指定根据哪个字段分组,参数代表当前要分组的字段的下标。
.sum(1) //1代表下标
//写数据Kafka
//创建Kafka的连接参数
val props = new Properties()
props.setProperty("bootstrap.servers","hadoop101:9092,hadoop102:9092,hadoop103:9092")
result.addSink(new FlinkKafkaProducer[(String, Int)]("t_topic",new MySerializer2,props, FlinkKafkaProducer.Semantic.EXACTLY_ONCE))
streamEvn.execute()
class MySerializer2 extends KafkaSerializationSchema[(String,Int)] {
override def serialize(t: (String, Int), aLong: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord("t_topic",t._1.getBytes(),t._2.toString.getBytes())
3) 自定义的Sink
当然你可以自己定义Sink,有两种实现方式:1、实现SinkFunction接口。2、实现RichSinkFunction类。后者增加了生命周期的管理功能。比如需要在Sink初始化的时候创建连接对象,则最好使用第二种。案例需求:把StationLog对象写入Mysql数据库中。
package com.jht.flink.sink
import java.sql.DriverManager
import java.sql.{Connection, PreparedStatement}
import com.jht.flink.source.{MyCustomerSource, StationLog}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object DiySink {
//自定义一个Sink写入Mysql
class MyCustomSink extends RichSinkFunction[StationLog]{
var conn:Connection = _
var pst :PreparedStatement =_
//生命周期管理,在Sink初始化的时候调用
override def open(parameters: Configuration): Unit = {
conn=DriverManager.getConnection("jdbc:mysql://192.21.19.200:3306/test","kk","kk")
pst=conn.prepareStatement("insert into t_station_log (sid,call_out,call_in,call_type,call_time,duration) values (?,?,?,?,?,?)")
//把StationLog 写入到表t_station_log,每写入一条执行一次
override def invoke(value: StationLog, context: SinkFunction.Context[_]): Unit = {
pst.setString(1,value.sid)
pst.setString(2,value.callOut)
pst.setString(3,value.callIn)
pst.setString(4,value.callType)
pst.setLong(5,value.callTime)
pst.setLong(6,value.duration)
pst.executeUpdate()
override def close(): Unit = {
pst.close()
conn.close()
def main(args: Array[String]): Unit = {
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1)
//导入隐式转换,建议写在这里,可以防止IDEA代码提示出错的问题
import org.apache.flink.streaming.api.scala._
val data: DataStream[StationLog] = streamEnv.addSource(new MyCustomerSource)