

手把手教你打造端到端语音合成系统

参考项目(将这些项目改成中文的语音合成)
一些相关组件的参考项目(欢迎补充)
Github 项目推荐 | 一个简单的英文字形转音素的 Python 模块
自然语言处理_The CMU Pronouncing Dictionary(卡耐基梅隆大学发音词典)
1.传统语音合成技术简介
语音合成,通常又称文语转换(Text To Speech,TTS),是一种可以将任意输入文本转换成相应语音的技术,是人机语音交互中不可或缺的模块之一。如果说语音识别技术是为了让机器能够“听懂”人说话,那么语音合成技术则让机器能够跟人“说话”。无论是在地图导航、语音助手、教育、娱乐等软件应用,还是在智能音箱、家电、机器人等硬件设备中,都有语音合成技术的身影。 如图 1 所示,语音合成系统通常包含前端和后端两个模块。 前端模块主要是对输入文本进行分析,提取后端模块所需要的语言学信息。对中文合成系统来说,前端模块一般包含文本正则化、分词、词性预测、多音字消歧、韵律预测等子模块。后端模块根据前端分析结果,通过一定的方法生成语音波形。后端模块一般分为基于统计参数建模的语音合成(Statistical Parameter Speech Synthesis,SPSS,以下简称参数合成),以及基于单元挑选和波形拼接的语音合成(以下简称拼接合成)两条技术主线。
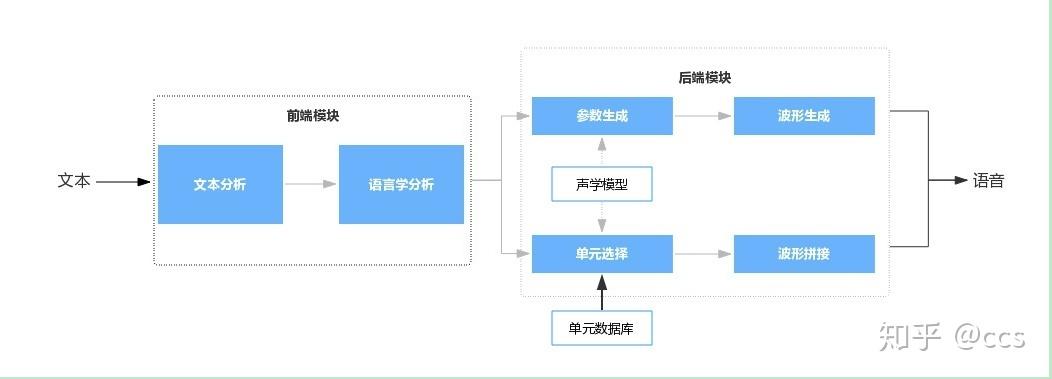
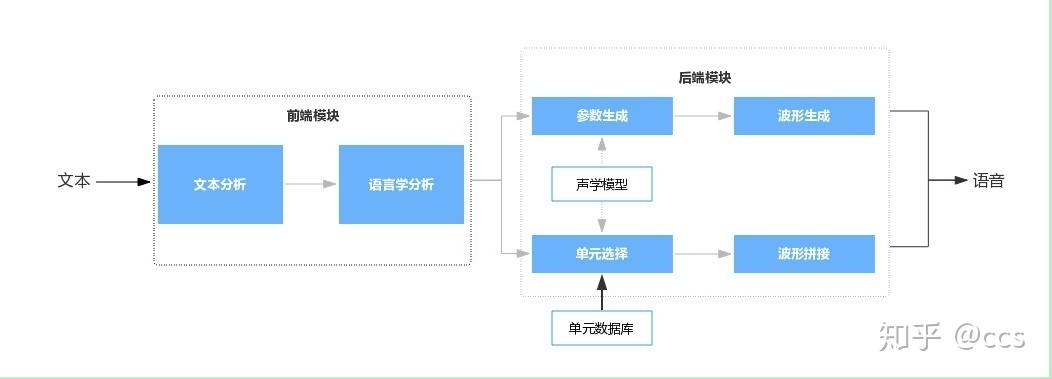
图1 语音合成系统基本框架
传统TTS是基于拼接和参数合成技术,效果上同真人语音的自然度尚有一定差距,效果已经达到上限,在实现上也依赖于复杂流水线,比如以文本分析为前端的语言模型、语音持续时间模型、声学特征预测模型、将频谱恢复成时域波形的声码器(vocoder)。这些组件都是基于大量领域专业知识,设计上很艰难,需要投入大量工程努力,对于手头资源有限的中小型玩家来说,这种“高大上”的技术似乎有些玩不起。
2.端到端语音合成的简介
为了解决传统语音合成的弊端促使了端到端语音合成的出现,研究者希望能够使合成系统能够尽量的简化,减少人工干预和对语言学相关背景知识的要求。近年来基于神经网络架构的深度学习方法崛起,使得原本在传统专业领域门槛极高的TTS应用上更接地气。端到端合成系统直接输入文本或者注音字符,系统输出音频波形。前端模块得到极大简化,甚至可以直接省略掉。端到端合成系统相比于传统语音合成,降低了对语言学知识的要求,可以方便的在不同语种上复制,批量实现几十种甚至更多语种的合成系统。借助于深度学习模型的强表达能力,端到端语音合成系统表现出令人惊艳的合成效果和强大丰富的发音风格与韵律表现力。
2017年初,Google 提出了一种新的端到端的语音合成系统——Tacotron。Tacotron是一种端到端的TTS生成模型。所谓“端到端”就是直接从字符文本合成语音,打破了各个传统组件之间的壁垒,使得我们可以从<文本,声谱>配对的数据集上,完全随机从头开始训练。从Tacotron的论文中我们可以看到,Tacotron模型的合成效果是优于要传统方法的,如图2。
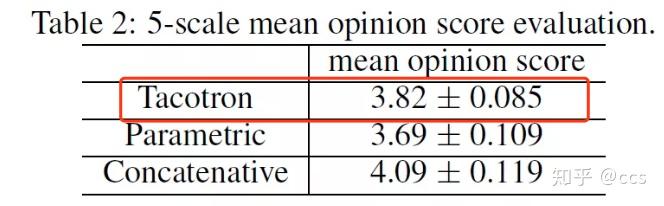
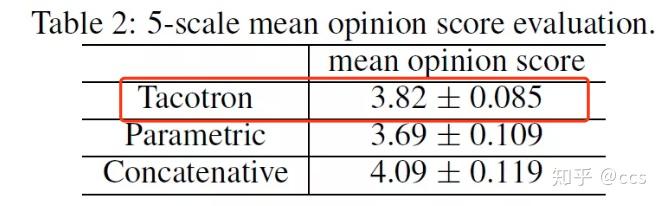
图2 平均意见得分(MOS)测试结果
论文地址: Tacotron: Towards End-to-End Speech Synthesis
注明:Tacotron和Tacotron2师出同门,总体思路是一样的,以后再具体讲解它们的结构,这里不展开
端到端的语音合成系统整体技术架构选型如图3所示,红色为今天所使用的技术栈。
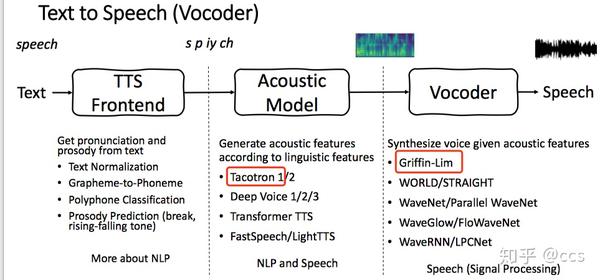
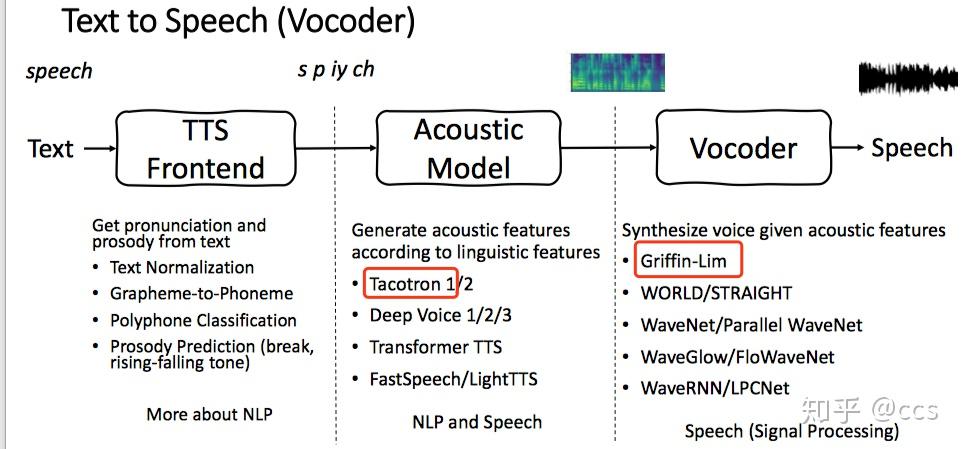
图3 端到端的语音合成系统技术栈
3.基于Tacotron普通话语音合成的实践
3.1 项目运行所需的软硬件环境
- 包括NVIDIA GTX系列显卡及其驱动
- 使用python3以及安装好Tensorflow模块


- 下载训练普通话语料库
- THCHS-30 上下载6.4G大小的THCHS-30,这是由清华大学开放的汉语普通话语料,许可证为Apache License v2.0。
- 其他普通话训练语料库
- Aishell-1
- 标贝数据集
-
几个最新免费开源的中文语音数据集
- git clone Tacotron的源代码.
- 普通话Tacotron的源代码
3.2 开始实践
- 先clone源代码到本地~/tacotron,然后解压THCHS-30数据集到根目录下,如下所示:


# 1.创建名为tacotron的python3.6虚拟环境(建议)
> conda create -n tacotron python=3.6
# 2.clone源代码
> git clone https://github.com/X-CCS/mandarin_tacotron_GL
# 3.解压THCHS-30数据集到根目录下
> tar zxvf data_thchs30.tgz -C ~/tacotron