(base) PS L:\Download\error> aapt dump badging .\58ͬ_com.wuba.apk | findstr 'application-label:'
application-label:'58???'
总结下就是findstr只能在gbk编码下查找中文,我们修改为utf-8编码的格式之后就不能使用了
怎么办,最后找了半天,脚本中使用正则表达式吧:
match_packgame = re.compile("package: name='(\S+)'").match(output.decode())
match_name = re.compile("application-label:'(.+)'").search(output.decode())
先说结论,用数组传每一个单独的参数,带有空格的命令仍然是一个参数,放在一起传进去即可。

然后记录一下寻找过程:
最后这个问题困扰我最久,一开始发现文件路径中带有中文,简单的使用单引号框起来路径,因为在命令行中这样就可以了,所以没有多想,最后一直报错才发现不对劲,开始寻找答案。
找啊找,找到了这个链接https://blog.csdn.net/ya6543/article/details/107774269,和我完全一样的问题,然后说再使用双引号括起来就能成功。
但我试了一下报错了:
python The filename, directory name, or volume label syntax is incorrect
可能是我没括对格式,但是我不想再试了,上面的链接说是从 StackOverflow上看到的解决方案,顺着点进链接https://stackoverflow.com/questions/49594738/not-able-to-parse-windows-path-with-space-in-python?newreg=6f5ff42a554343debcd90b7a291151ea
一大堆讨论不想看,但是拖到最后发现,结尾有人有一个方案:
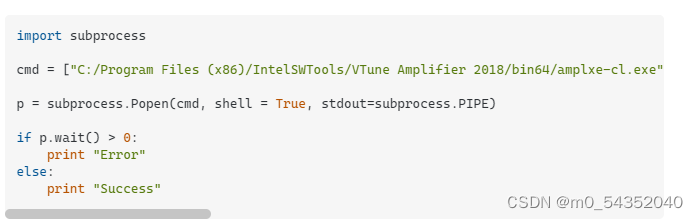
试了一下,完美,成功了。
最近在采集windows上中间件的时候,遇到了文件路径有空格的问题。
例如:Aapche的安装路径为D:\Program Files\Apache Software Foundation\Apache2.2。
采集apache要读取配置文件D:\Program Files\Apache Software Foundation\Apache2.2\conf\httpd.conf
执行一些D:\Program Files\Apache Software Foundation\Apache2.2\bin\httpd.exe -v 这种命令。
读取配置文件是没有问题的,因为用的是python代码,打开
哈喽,大家好,我是木头左!在编程实践中,常常需要通过Python执行系统命令,这包括调用外部程序、脚本或是其他命令行工具。然而,一个看似简单却常被忽视的细节——文件路径中的空格,可能会导致程序意外崩溃或行为异常。本篇文章将深入探讨当路径中包含空格时,如何在Python中正确执行命令,以及提供一些实用的解决方案和最佳实践指导。
python字符串查找函数的使用打开Python开发工具IDLE,新建"findstr.py'文件,并写代码如下:s ='/ab/bx,.s'print (s.find('/x'))注意find是匹配子字符串,而不是匹配第一个字符F5运行程序,打印出-1,代表没有找到"/x'子字符串修改代码如下,查找"/b'子字符串s ='/ab/bx,.s'print (s.fin...
最近在采集windows上中间件的时候,遇到了文件路径有空格的问题。
例如:Aapche的安装路径为D:\Program Files\Apache Software Foundation\Apache2.2。
采集apache要读取配置文件D:\Program Files\Apache Software Foundation\Apache2.2\conf\httpd.conf
执行一些D:\Pro...
import sys import getopt def usage(): print ("sys.argv[0]: '-a aa -b bb -c cc'") print ("sys.argv[0]: ' -h'") def db_get_args(): try: opts,args = getopt.getopt(sys.argv[1:], "ha:b:c:") except getopt.G...
python字符串查找函数的使用打开Python开发工具IDLE,新建‘findstr.py'文件,并写代码如下:s ='/ab/bx,.s'print (s.find('/x'))注意find是匹配子字符串,而不是匹配第一个字符F5运行程序,打印出-1,代表没有找到‘/x'子字符串修改代码如下,查找‘/b'子字符串s ='/ab/bx,.s'print (s.find('/b'))F5运行程序,...
在文件中寻找字符串。
FINDSTR [/B] [/E] [/L] [/R] [/S] [/I] [/X] [/V] [/N] [/M] [/O] [/F:file]
[/C:string] [/G:file] [/D:dir list] [/A:color attributes] [/OFF[LINE]]
strings [[drive:][path]filename[ ...]]
if sys.platform == "win32":
import codecs
from ctypes import WINFUNCTYPE, windll, POINTER, byre
在使用的使用decode一下,windows下为gbk编码(不同平台的编码可能不同)。如:
option = raw_input(hint.encode('gbk'))
原因Windows 下的 cmd 和 powershell 默认是 GBK 编码显示输出内容, 这导致使用 UTF-8 的 Python 程序中的中文内容(包括注释、文档、和字符串字面量)会以不正确的解码方式输出成乱码内容。解决办法Windows 内置了一个叫 “chcp” 的命令,它可以修改要显示的字符集编码的编号。UTF-8 的编号是 65001,所以启动 cmd 或者 powershell ...


