本文21年上旬发表于CVPR的关于无监督语义分割的文章。我个人不是专门做语义分割领域的,感觉无监督语义分割还是一块待开垦的沃土,做语义分割的小伙伴们可以尝试这个方向。首先本文针对之前无监督语义分割存在的两个问题:
1、分割时不同class的object像素点数量的不平衡问题
语义分割是像素级的分类问题,以往的无监督语义分割使用互信息的方式进行优化,然而由于不同class的object所包含的像素点个数不同(有时甚至差距很大),因此使用互信息会发生严重的样本不平和现象,由此导致的结果就是分割大大的偏向如天空,草地等占比大的objec( leads to noisy representation as major classes)。
2、以往的无监督语义分割有一个重要的假设,即语义连贯性,然而在许多场景中,这种假设并不好,这会导致小object被忽略。
受到深度聚类方法(DeepCluster)的启发,本文提出了一种
两阶段迭代
的无监督语义分割方法:
①
首先通过特征提取网络
c
(
.
)
的参数是固定的。
到这里,回到最开始的两个问题,第一个问题我们就可以给出解决方案了:在聚类结束后,统计每个类对应的像素点的数量,之后将其当做特征提取网络计算交叉熵时的权重,来抵消不同class样本不平衡带来的问题。
那么第二个问题是如何解决的呢,作者在本文提出了一种新的优化准则,即
照片变换( photometric transformations
的不变性和几何变换的等变性。简单来说
照片变换
就是对输入图像做类似于颜色变换、明亮变换、高斯模糊等不改变像素点的语义信息(不改变得到的pseudo-label;几何变换则类似于随机翻转,随机剪切等。对图像做几何变换后再进行特征提取,等于对图像进行特征提取再做同样的几何变换。可以将以上两条准则归为以下监督损失:
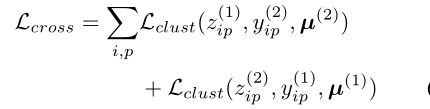
其中
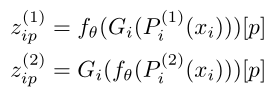
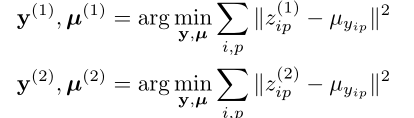
其中
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering 论文解读和感想
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering 论文解读和感想背景和动机本文21年上旬发表于CVPR的关于无监督语义分割的文章。我个人不是专门做语义分割领域的,感觉无监督语义分割还是一块待开垦的沃土,做语义分割的小伙伴们可以尝试这个方向。首先本文针对之前无监督语义分割存在的两个问题:1、分割时不同class的object像素点数量的不平衡问题语义分割是像素级的分类问题,
一种无监督语义分割算法:Un
super
vis
ed
Sem
ant
ic
Segmentat
ion
using
In
variance
and
Equi
variance
in
Clustering
将文章分割成具有语义相关性的片段,能够增强文章的可读性
同时也促进了文本摘要((Angheluta et al., 2002; Dias et al., 2007)、文章检索(Huang et al., 2003; Dias et al., 2007)、文本索引(text indexing)等相关任务的开展
话题分割的两类任务
线性地检测分割点
IC
CV原文地址
在无监督设置下,学习密集语义表征(dense
sem
ant
ic
representat
ion
s)是一个非常重要的问题,这引导网络学习像素级的语义表征/嵌入,这对无监督语义分割非常重要。如果解决了这个问题,那么后续直接使用K-Means聚类将每个像素聚集到对应的
sem
at
ic
groups就可以执行语义分割。
目前采用的无监督表征学习(自监督学习)通常学习到的是图像级的表征【比如进行实例判别的对比学习】,无法表征其具有像素判别性。而一个好的像素
在这个
Vis
ion
Transformer睥睨天下的时代,CNN一时式微,作为
计算机视觉
领域的前任霸主,少不得被拿来对比。相信大家在看
论文
的时候,会发现引言里面常常会阐述ViT与CNN各自的优势,对于ViT来说,那自然是全局关系的建模,而对于CNN来说,归纳偏差、平移不变性亦是常见的字眼。看的多了,不禁多想了一分,CNN的平移不变性究竟为何?于是乎在下收集了一些资料结合自己的理解总结,特此记录以便回顾。
图片文字来自
论文
: https://arxiv.org/abs/2201.10728
Learning a Discriminative Feature Network for
Sem
ant
ic
Segmentat
ion
- CVPR2018 - Face++ [Paper]
Vortex Pooling: Improving Context Representat
ion
in
Sem
ant
ic
Segmentat
ion
- 2018...
留个笔记自用
xMUDA: Cross-Modal Un
super
vis
ed
Domain Adaptat
ion
for 3D
Sem
ant
ic
Segmentat
ion
Instance
segmentat
ion
实例分割
目标检测( Object detect
ion
)不仅需要提供图像中物体的类别,还需要提供物体的位置(bounding box)。语义分割(
Sem
ant
ic
segmentat
ion
)需要预测出输入图像的每一个像素点属于哪一类的标签。实例分割( instance segmenta
Abstract
目的,利用经典信号采样理论,消除下采样(max-pooling, strid
ed
-convolut
ion
, and averagepooling)引起的信号混叠(锯齿)效应。方法抗锯齿(
ant
i-aliasing),达到平移不变形。
1. Introduct
ion
早期的网络确实采用了模糊下采样的形式–平均池,但经验说明最大池表现更好,但2018有人发现因为maxpool没有抗锯...
Un
super
vis
ed
Intra-domain Adaptat
ion
for
Sem
ant
ic
Segmentat
ion
through Self-
Super
vis
ion
原文链接 :点击下载
文章目录Un
super
vis
ed
Intra-domain Adaptat
ion
for
Sem
ant
ic
Segmentat
ion
through Self-
Super
vis
ion
摘要框架域间自适应阶段熵排序过程域内自适应阶段Experiments
通过自监督用于语义分割的无监督域内自适应
CVPR 2020.
在
深度学习
领域中,研究人员发现,有监督学习存在标注难度高的问题,尤其是在内容业务端的风控过程中数据“大爆发”。因此,自监督学习的相关研究在近年蓬勃发展起来,达到并超越了有监督学习。
通过借助无标签数据与无监督训练任务,自监督学习可有效改善传统有监督算法中“泛化性能不足”、“模型过拟合”、“严重依赖数据标注质量”等问题。
那么,如何开展自监督学习?文章对自监督学习的方法做了超详细的
解读
,展示了SimCLR、Moco、BYOL三个方向,并介绍了各自的优势和应用场景。快来学习与分享吧。...
在欧几里得几何中,平移是一种几何变换,表示把一幅图像或一个空间中的每一个点在相同方向移动相同距离。比如对图像分类任务来说,图像中的目标不管被移动到图片的哪个位置,得到的结果(标签)应该是相同的,这就是卷积神经网络中的平移不变性。
平移不变性意味着系统产生完全相同的响应(输出),不管它的输入是如何平移的 。平移同变性(translat
ion
equi
variance
)意味着系统在不同位置的工作原理相...
Geoffery Hinton教授的Neuron Networks for Machine Learning的第五讲主要介绍物体识别问题的难点及克服这些难点的方法,重点介绍了数字识别和物体识别中使用的卷积网络。Why object recognit
ion
is diff
ic
ult我们知道识别真实场景中的物体是很困难的,这一小节我们来介绍造成这些困难的一些东西。
Segmentat
ion
: 在一个图像
转载自:https://www.aiuai.cn/aifarm62.html
CCNet: Criss-Cross Attent
ion
for
Sem
ant
ic
Segmentat
ion
- 2018 <Paper> <Code-PyTorch>
A PyTorch
Sem
ant
ic
Segmentat
ion
Toolbox...
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering 论文解读和感想

