


ETL best practices with Airflow


ETL principles
在使用airflow的具体工具前,我们先来看看ETL最佳实践应该遵循的原则。
当你面对一个大数据场景时,遵循合理的原则意义重大。‘solving it quick to get going‘的方法最终会导致一大堆数据问题,及种种下游问题。
对于该如何结构化管理好ETL工作,Airflow提供了一种很好的思考方式。这种理念使Airflow能够并行化作业,根据相关性适当地安排作业,并在需要时历来重新处理数据。这种哲学植根于几个简单的原则:
- 增量加载数据: 当表或数据集较小时,可以整体加载数据。但是随着数据的增长,以固定的时间间隔增量提取数据才是ETL的常态,仅加载一个小时,一天,一周数据的需求非常普遍。Airflow可以容易地以特定的时间间隔的数据。
- 处理历史数据: 在某些情况下,您刚刚完成一个新的工作流程并且需要回溯到将新代码投入生产的日期的数据。在这种情况下,您只需使用DAG中的start_date参数以指定开始日期。然后,Airflow将回填任务到开始日期。此外,还可以使用DAG的参数来处理数周、数月或数年的数据。
- 分区提取的数据: 通过对数据的目的地进行分区,可以并行运行dag,避免对提取的数据进行锁定,并在读取相同数据时优化性能。不再相关的数据可以存档并从数据库中删除。
- 强制幂等约束 :DAG运行的结果应始终具有幂等特性。这意味着当您使用相同的参数多次运行某个流程时(即使在不同的日期),结果也将完全相同。您最终不会在您的环境中获得同一数据的多个副本或其他不良后果。显然,这仅在处理脚本尚未修改时才有效。如果业务规则在流程中发生更改,则目标数据将不同。此外,某些流程需要在一定天数后对数据进行自动处理,因为并非总是被允许永久保留客户的历史数据。
- 强制确定性 :如果对于给定的输入,所产生的输出始终完全相同,则认为该函数是确定性的。函数行为可能不确定的情况的示例:1)在函数中使用外部状态,例如全局变量,随机值,存储的磁盘数据,硬件计时器。2)以时间敏感的方式操作函数,例如多线程的不正确使用。3)依赖于输入变量的顺序而不是显式地对输入变量进行排序,而是依赖于随机的顺序。4)函数内部结构的实现问题(例如,隐式依赖于python dict中的顺序)5)异常处理不当或异常后处理不当。6)中途提交和意外情况。
- 有条件地执行 :Airflow具有一些选项,可根据之前的实例的成功来控制DAG中任务的运行方式。例如, depends_on_past 参数指定在执行一个任务之前,必须先成功执行所有任务实例,然后才能执行当前任务。如果不是最新执行,最近引入的 LatestOnlyOperator 允许您有条件地跳过DAG中的下游任务。还有一个 BranchPythonOperator ,它可以基于某些决策函数选择在DAG中进行哪个执行分支。
- 同时编码工作流和应用程序 :大多数调度程序和工作流工具都允许您创建步骤,然后在UI或XML中定义如何将步骤连接在一起。最终,总会有特定的工作受到限制,因为工作流的逻辑与工具中可以执行的操作不兼容。在Airflow中,您不仅可以对应用程序进行编码,还可以对流程本身进行编码。您可以从DAG内部动态启动新的DAG,以编程方式跳过下游任务,使用python函数有条件地执行其他代码,运行sub-dag等。
- 保持数据静止 :为了能让Airflow多线程并行,您需要考虑清楚任务步骤之间如何保存数据。Airflow的操作符通常会从一个系统读取,创建一个临时的本地文件,然后将该文件写入某个目标系统。您不应该让上游任务依赖其他下游任务中创建的临时数据(文件等)。原因是同一DAG的任务可以在不同的worker上执行,对于那些worker一些本地资源可能并不存在。当您使用Sequential或LocalExecutor时,您似乎可以摆脱它,但是如果将来需要使用分布式执行方法并且您具有这些依赖关系,则为解决这些依赖关系可能会非常痛苦。因此,最好确保从所有worker都可以访问的服务(services)中读取数据,并且在任务开始和终止时这些服务中的数据保持静止。
- 理解SLA和警报 :服务水平协议(Service Level Agreements)可用于检测长时间运行的任务实例,并让Airflow采取进一步的措施。默认情况下,Airflow将通过电子邮件发送错过的SLA,并且可以从Web服务器进一步检查。在DAG中,您可以指定一个SLA缺失时要调用的函数,方便将问题广而告之。
- 动态运行任务 :由于工作流是代码,因此可以通过该代码动态创建任务或者结束任务。在一些例子中,人们拥有一个文本文件,其中包含需要处理的指令,Airflow仅使用该文件就可以动态生成DAG和任务。
- 集中资源 :调度程序(schedulers)是无法控制脚本中资源的使用的。在Airflow中,您实际上可以创建资源池,并要求任务在执行任何工作之前都需要从该池中获取token。如果资源池已完全用完,则直到另一个任务完成释放token后,才会调度需要token的其他任务。如果要管理对共享资源(例如数据库,GPU,CPU等)的访问,这将非常有用。
- 探测任务起始时间 :许多调度程序在经过特定的日期/时间后开始执行任务,这正是cron所做的。Airflow可以实现这种简单的功能,但是通过使用任务探测器作为在dag中的第一项任务,Airflow可以感知dag中其他任务所需的前置条件。任务探测器包括:dag依赖探测器,探测由另一个dag中的任务实例结果如何,HTTP传感器可以调用URL并解析其结果,文件探测器可以探测文件是否存在,数据库探测器可以探测数据是否存在数据库中等等。这提供了很多工具来保证整个ETL管道的一致性。
- 统一登录 :Airflow在其自己的数据库中维护外部服务的登录信息。
- 统一配置 :遵循Don't repeat yourself原理,只在一个地方指定一次配置,即可避免重复配置。每个Airflow实例都有“Variables”,可以对其进行设置以指定运行任务的环境。
- 统一保存元数据 :您无需在此处做任何事情。Airflow将在一个地方管理日志,工作时间,着陆时间,从而减少了人们收集元数据以分析问题的开销。
- 开发自己的工作流框架 :将代码作为工作流,还可以根据需要重用DAG的某些部分,从而减少代码重复,并从长远来看使工作变简单。这降低了整个系统的复杂性,并为开发人员腾出时间来处理更重要和更具影响力的任务。
Airflow 抽象理解
在介绍Airflow之前,我们需要了解任务依赖的概念
任务依赖
通常,在一个运维系统,数据分析系统,或测试系统等大型系统中,我们会有各种各样的依赖需求。比如,
- 时间依赖 :任务需要等待某一个时间点触发
- 外部系统依赖 :任务依赖Mysql中的数据,HDFS中的数据等等,这些不同的外部系统需要调用接口去访问
- 机器依赖 :任务的执行只能在特定的某一台机器的环境中,可能这台机器内存比较大,也可能只有那台机器上有特殊的库文件
- 任务间依赖 :任务A需要在任务B完成后启动,两个任务互相间会产生影响
- 资源依赖 :任务消耗资源非常多,使用同一个资源的任务需要被限制,比如跑个数据转换任务要10个G,机器一共就30个G,最多只能跑两个,我希望类似的任务排个队
- 权限依赖 :某种任务只能由某个权限的用户启动
也许大家会觉得这些是在任务程序中的逻辑需要处理的部分,但是我认为,这些逻辑可以抽象为 任务控制逻辑 的部分,和实际 任务执行逻辑 解耦合
如何理解Crontab
现在让我们来看下最常用的依赖管理系统,Crontab
在各种系统中,总有些定时任务需要处理,每当在这个时候,我们第一个想到的总是crontab。
确实,crontab可以很好的处理定时执行任务的需求,但是对于crontab来说,执行任务,只是调用一个程序如此简单,而程序中的各种逻辑都不属于crontab的管辖范围(很好的遵循了KISS)
所以我们可以抽象的认为:
crontab是一种依赖管理系统,而且只管理时间上的依赖。
Airflow的处理依赖的方式
现在重点Airflow来了,看下它是怎么处理我们遇到的依赖问题。
- Airflow的核心概念,是DAG(有向无环图),DAG由一个或多个TASK组成,而这个DAG正是解决了上文所说的任务间依赖。Task A 执行完成后才能执行 Task B,多个Task之间的依赖关系可以很好的用DAG表示完善
- Airflow完整的支持crontab表达式,也支持直接使用python的datatime表述时间,还可以用datatime的delta表述时间差。这样可以解决任务的时间依赖问题。
- Airflow在CeleryExecuter下可以使用不同的用户启动Worker,不同的Worker监听不同的Queue,这样可以解决用户权限依赖问题。Worker也可以启动在多个不同的机器上,解决机器依赖的问题。
- Airflow可以为任意一个Task指定一个抽象的Pool,每个Pool可以指定一个Slot数。每当一个Task启动时,就占用一个Slot,当Slot数占满时,其余的任务就处于等待状态。这样就解决了资源依赖问题。
- Airflow中有Hook机制(其实我觉得不应该叫Hook),作用时建立一个与外部数据系统之间的连接,比如Mysql,HDFS,本地文件系统(文件系统也被认为是外部系统)等,通过拓展Hook能够接入任意的外部系统的接口进行连接,这样就解决的外部系统依赖问题。
坑:
dags_are_paused_at_creation = True
airflow pause dag_id
To Keep in Mind
- Marking task instances as failed can be done through the UI. This can be used to stop running task instances.
- Marking task instances as successful can be done through the UI. This is mostly to fix false negatives, or for instance, when the fix has been applied outside of Airflow.
Catchup
In the example above, if the DAG is picked up by the scheduler daemon on 2016-01-02 at 6 AM, (or from the command line), a single DAG Run will be created, with an execution_date of 2016-01-01, and the next one will be created just after midnight on the morning of 2016-01-03 with an execution date of 2016-01-02.
If the
dag.catchup
value had been
True
instead, the scheduler would have created a DAG Run for each completed interval between 2015-12-01 and 2016-01-02 (but not yet one for 2016-01-02, as that interval hasn’t completed) and the scheduler will execute them sequentially.
Catchup is also triggered when you turn off a DAG for a specified period and then re-enable it.
This behavior is great for atomic datasets that can easily be split into periods. Turning catchup off is great if your DAG performs catchup internally.
Backfill
There can be the case when you may want to run the dag for a specified historical period e.g., A data filling DAG is created with
start_date
2019-11-21
, but another user requires the output data from a month ago i.e.,
2019-10-21
. This process is known as Backfill.
You may want to backfill the data even in the cases when catchup is disabled. This can be done through CLI. Run the below command
airflow dags backfill --start-date START_DATE --end-date END_DATE dag_id
The backfill command will re-run all the instances of the dag_id for all the intervals within the start date and end date.
建议安装Airflow 1.8 ,而不是最新版的apache-airflow 1.9,主要原因是1.9版本的所有运行都是基于UTC时间的,这样导致在配置调度信息的时候不够直观,时间换算也非常头疼。
MySQL 5.6 :使用LocalExcutor模式,所有DAG信息保存在后端数据库中。
创建数据库
后端使用MySQL数据库来保存任务信息,先在数据库中建立database和user。如下
create database airflow;
grant all privileges on airflow.* to 'airflow'@'%' identified by 'airflow';
flush privileges;环境变量
Airflow在运行过程中会使用全局环境变量,所以必须先在~/.bash_profile 中增加变量如下
export AIRFLOW_HOME=/home/etl/airflow启用Web权限
默认情况下airflow的web管理台是没有用户密码的,在迁移到正式环境之前,我们需要启用权限机制。
在 airflow.cfg 中设置如下选项
[webserver]
authenticate = True
auth_backend = airflow.contrib.auth.backends.password_auth启用权限之后,在第一次登录之前必须手动通过python REPL来设置初始用户
import airflow
from airflow import models, settings
from airflow.contrib.auth.backends.password_auth import PasswordUser
user = PasswordUser(models.User())
user.username = 'airflow'
user.email = 'airflow@xxx.com'
user.password = 'airflow'
session = settings.Session()
session.add(user)
session.commit()
session.close()
exit()修改数据库连接
因为使用MySQL作为元数据库,所以还需要配置数据库的连接参数。在 airflow.cfg 中设置如下选项
[core]
executor = LocalExecutor
sql_alchemy_conn = mysql://airflow:airflow@192.168.100.57:3306/airflow?charset=utf8更改数据库连接方式之后,需要重新执行一次初始化操作。
airflow initdb默认情况下,Web界面会把样例DAG都显示出来非常混乱。除了在数据库中删除样例DAG之外,也可以通过配置不显示这部分样例。
# 不显示样例DAG
load_examples = FalseAirflow的catchup机制,会在你启动一个DAG的时候,把当前时间之前未执行的job依次执行一次。这个好处是可以把遗漏的调度任务进行补足,但是在很多时候我们并不需要这个特性。通过修改配置,可以禁止catchup,如下
[scheduler]
# 避免执行catchup,即避免把当前时间之前未执行的job都执行一次
catchup_by_default = FalseWEB界面
在默认的8080端口页面上,可以对DAG进行日常操作,包括但不限于启动,停止,查看日志等。界面如下图
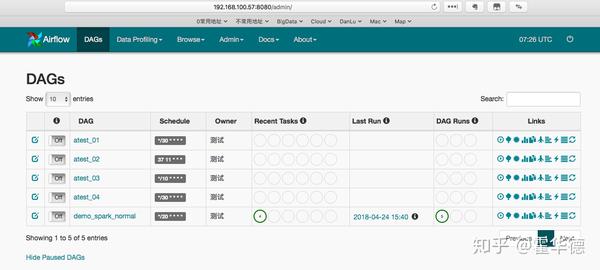
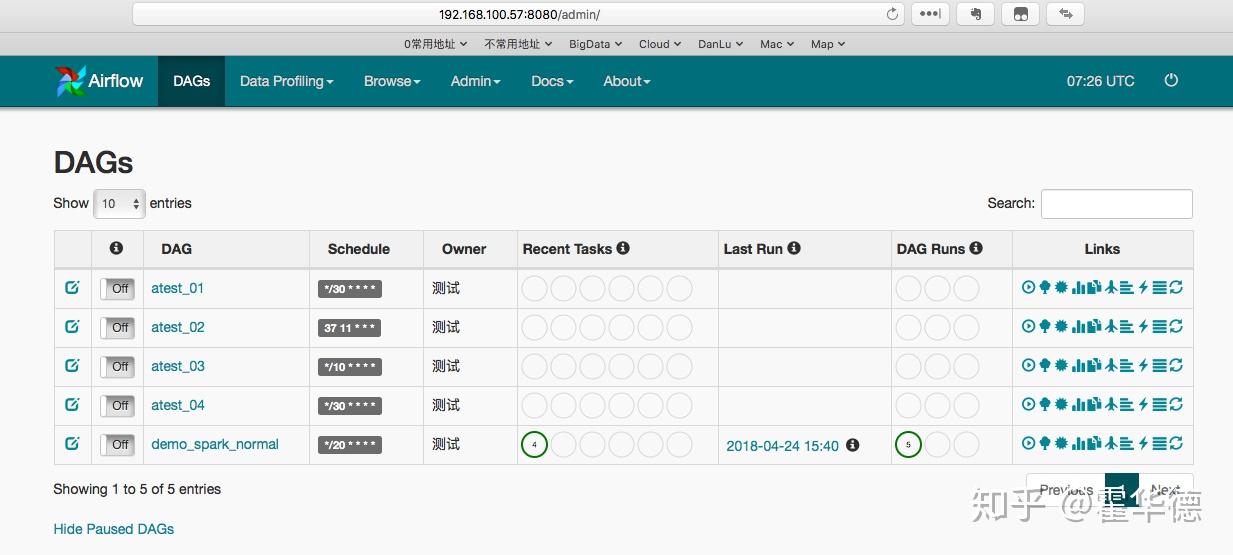
管理脚本
当前版本Airflow没有提供关闭脚本,也没有提供一个便捷的办法来彻底删除DAG。为了方便测试,我写了一个管理脚本来处理相关的任务。
脚本调用方式如下
$ ./airflow_util.py -h
usage: airflow_util.py [-h] [-k] [-s] [--clear CLEAR] [--delete DELETE]
optional arguments:
-h, --help show this help message and exit
-k, --kill 关闭Airflow
-s, --start 启动Airflow
--clear CLEAR 删除历史日志
--delete DELETE 提供需要删除的DAG ID管理脚本源代码如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import argparse
import pymysql
import subprocess
import time
#连接配置信息
config = {
'host':'127.0.0.1',
'port':3306,
'user':'airflow',
'password':'airflow',
'db':'airflow',
'charset':'utf8',
# 删除历史日志
def clear_log(num):
print("Clear logs before {0} days ...".format(num))
cmd = "find %s -maxdepth 1 -type d -mtime +%d | xargs -i rm -rf {}"
subprocess.call(cmd % ('./logs',num), shell=True)
subprocess.call(cmd % ('./logs/scheduler',num), shell=True)
# 通过杀掉后台进程来关闭Airflow
def kill_airflow():
print("Stoping Airflow ...")
# exclude current file in case the file name contains keyword 'airflow'
cmd = "ps -ef | grep -Ei 'airflow' | grep -v 'grep' | grep -v '%s' | awk '{print $2}' | xargs -i kill -9 {}" % (__file__.split('/')[-1])
subprocess.call(cmd, shell=True)
# 启动Airflow
def start_airflow():
kill_airflow()
time.sleep(3)
print("Starting Airflow Webserver ...")
subprocess.call("rm logs/webserver.log", shell=True)
subprocess.call("nohup airflow webserver >>logs/webserver.log 2>&1 &", shell=True)
print("Starting Airflow Scheduler ...")
subprocess.call("rm logs/scheduler.log", shell=True)
subprocess.call("nohup airflow scheduler >>logs/scheduler.log 2>&1 &", shell=True)
# 删除指定DAG ID在数据库中的全部信息。
# PS:因为SubDAG的命名方式为 parent_id.child_id ,所以也会把符合这种规则的SubDAG删除!
def delete_dag(dag_id):
# 创建连接
connection = pymysql.connect(**config)
cursor = connection.cursor()
sql="select dag_id from airflow.dag where (dag_id like '{}.%' and is_subdag=1) or dag_id='{}'".format(dag_id, dag_id)
cursor.execute(sql)
rs = cursor.fetchall()
dags = [r[0] for r in rs ]
for dag in dags:
for tab in ["xcom", "task_instance", "sla_miss", "log", "job", "dag_run", "dag_stats", "dag" ]:
sql="delete from airflow.{} where dag_id='{}'".format(tab, dag)
print(sql)
cursor.execute(sql)
connection.commit()
connection.close()
def main_process():
parser = argparse.ArgumentParser()
parser.add_argument("-k", "--kill", help="关闭Airflow", action='store_true')
parser.add_argument("-s", "--start", help="启动Airflow", action='store_true')
parser.add_argument("--clear", help="删除历史日志", type=int)
parser.add_argument("--delete", help="提供需要删除的DAG ID")
args = parser.parse_args()
if args.kill:
kill_airflow()
if args.start:
start_airflow()
if args.clear:
clear_log(args.clear)
if args.delete:
delete_dag(args.delete)
if __name__ == '__main__':
main_process()编写DAG
原生Airflow的工作流通过简单的python脚本来进行定义(有一些第三方扩展可以实现拖放模式的定义)。
普通DAG
对于task不是特别多的场景,把所有task都定义在同一个py文件里面即可。如下,定义了4个task

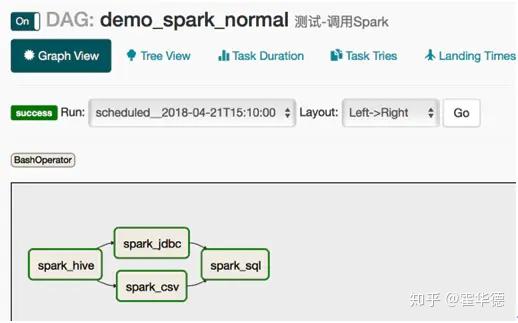
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import airflow
from airflow.models import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import timedelta, datetime
template_caller = "sh /home/etl/jupyter_home/etl_script/spark_scheduler/subdir/caller_spark.sh -m {0} -f {1} "
template_file = '/home/etl/jupyter_home/etl_script/spark_scheduler/subdir/{0}'
default_spark_master = 'spark://192.168.100.51:7077'
#-------------------------------------------------------------------------------
default_args = {
'owner': '测试',
'depends_on_past': False,
'start_date': datetime(2018,4,24,14,0,0),
'email': ['xxx@xxx.com'],
'email_on_failure': True,
#-------------------------------------------------------------------------------
dag = DAG(
'demo_spark_normal',
default_args=default_args,
description='测试-调用Spark',
schedule_interval='*/20 * * * *')
#-------------------------------------------------------------------------------
# spark operator
cmd = template_caller.format(default_spark_master, template_file.format('hive_rw.ipynb'))
t1 = BashOperator( task_id='spark_hive', bash_command=cmd , dag=dag)
cmd = template_caller.format(default_spark_master, template_file.format('jdbc_rw.ipynb'))
t2 = BashOperator( task_id='spark_jdbc', bash_command=cmd , dag=dag)
cmd = template_caller.format(default_spark_master, template_file.format('csv_relative.py'))
t3 = BashOperator( task_id='spark_csv', bash_command=cmd , dag=dag)
cmd = template_caller.format(default_spark_master, template_file.format('pure_sql.sql'))
t4 = BashOperator( task_id='spark_sql', bash_command=cmd , dag=dag)
#-------------------------------------------------------------------------------
# dependencies
t1 >> t2 >> t4
t1 >> t3 >> t4
SubDAG
当一个工作流里面的task过多,UI显示会比较拥挤,这种场景下可以通过把task分类到不同SubDAG中的办法来实现。在具体编写上,又可以分为单一py文件和多个py文件的方案。
单一文件
这种情况下,我们把DAG和SubDAG都写在一个py文件里面。优点是只有一个文件易于编写,缺点是如果task比较多的话,文件不易管理。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from datetime import datetime, timedelta
from airflow.models import DAG
from airflow.operators.subdag_operator import SubDagOperator
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
PARENT_DAG_NAME = 'atest_04'
#CHILD_DAG_NAME = 'child_dag'
default_args = {
'owner': '测试',
'depends_on_past': False,
main_dag = DAG(
dag_id=PARENT_DAG_NAME,
default_args=default_args,
description='测试-内嵌SubDAG',
start_date=datetime(2018,4,21,16,0,0),
schedule_interval='*/30 * * * *'
# Dag is returned by a factory method
def sub_dag(parent_dag_name, child_dag_name, start_date, schedule_interval):
dag = DAG(
'%s.%s' % (parent_dag_name, child_dag_name),
schedule_interval=schedule_interval,
start_date=start_date,
t1 = BashOperator(
task_id='print_{}'.format(child_dag_name),
bash_command='echo sub key_{} `date` >> /home/etl/airflow/test.log'.format(child_dag_name),
dag=dag)
return dag
sub_dag_1 = SubDagOperator(
subdag=sub_dag(PARENT_DAG_NAME, 'child_01', main_dag.start_date, main_dag.schedule_interval),
task_id='child_01',
dag=main_dag,
sub_dag_2 = SubDagOperator(
subdag=sub_dag(PARENT_DAG_NAME, 'child_02', main_dag.start_date, main_dag.schedule_interval),
task_id='child_02',
dag=main_dag,
sub_dag_1 >> sub_dag_2
多个文件
当SubDAG比较多的场景下,把DAG文件保存在独立的py文件中是一种更好的方法。文件目录结构如下
PS :因为在airflow中调用其他文件的过程中会出现找不到model的错误,所以在主文件中增加了一句处理路径的语句。如果有更好的办法,可以对这个进行替换。
sys.path.append(os.path.abspath(os.path.dirname(__file__)))
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys, os
sys.path.append(os.path.abspath(os.path.dirname(__file__)))
from datetime import datetime, timedelta
from airflow.models import DAG
from airflow.operators.subdag_operator import SubDagOperator
from datetime import datetime
from sub.subdag import sub_dag
PARENT_DAG_NAME = 'atest_03'
CHILD_DAG_NAME = 'child_dag'
default_args = {
'owner': '测试',
'depends_on_past': False,
main_dag = DAG(
dag_id=PARENT_DAG_NAME,
default_args=default_args,
description='测试-独立SubDAG',
start_date=datetime(2018,4,14,19,0,0),
schedule_interval='*/10 * * * *',
catchup=False
sub_dag = SubDagOperator(
subdag=sub_dag(PARENT_DAG_NAME, CHILD_DAG_NAME, main_dag.start_date,
main_dag.schedule_interval),
task_id=CHILD_DAG_NAME,
dag=main_dag,
子文件如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from airflow.models import DAG
from airflow.operators.bash_operator import BashOperator
# Dag is returned by a factory method
def sub_dag(parent_dag_name, child_dag_name, start_date, schedule_interval):
dag = DAG(
'%s.%s' % (parent_dag_name, child_dag_name),
schedule_interval=schedule_interval,
start_date=start_date,
t1 = BashOperator(
task_id='print_1',