

Python习题(二)

1、圆的周长和面积。 2-1.py 。输入圆的半径,求圆的周长和面积,结果四舍五入保留4位小数。
import math
r = eval(input("请输入圆的半径:"))
area=math.pi*r*r
print("圆面积为:",area)
a=area
round(a,4)
print('a')
2、直角三角形斜边上的高。 2-2.py 。输入直角三角形两直角边a,b的值,输出斜边上的高,结果四舍五入保留2位小数。
print('输入直角三角形两直角边a,b的值,')
a=eval(input('a='))
b=eval(input('b='))
h=a*b/((a*a+b*b)**0.5)
h=('{:.2f}'.format(h))
print(h)
3、字符串循环左移。 2-3.py 。给定一个字符串s,要求把s的前n个字符移动到s的尾部,如把字符串“abcdef”前面的2个字符‘a’、‘b’移动到字符串的尾部,得到新字符串“cdefab”,称作字符串循环左移n位。
输入一个字符串和一个非负整数n,要求将字符串循环左移n次。
s=str(input('请输入一个字符串:'))
n=int(input('请输入要循环左移的次数:'))
if(n>len(s)):
n-=len(s)
s=s[n:]+s[:n]
print(s)
4、输入一个由多个单词组成的字符串,单词以空格隔开。计算字符串最后一个单词的长度。
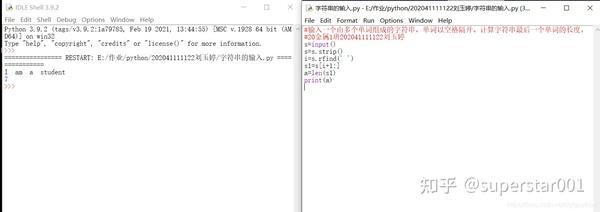
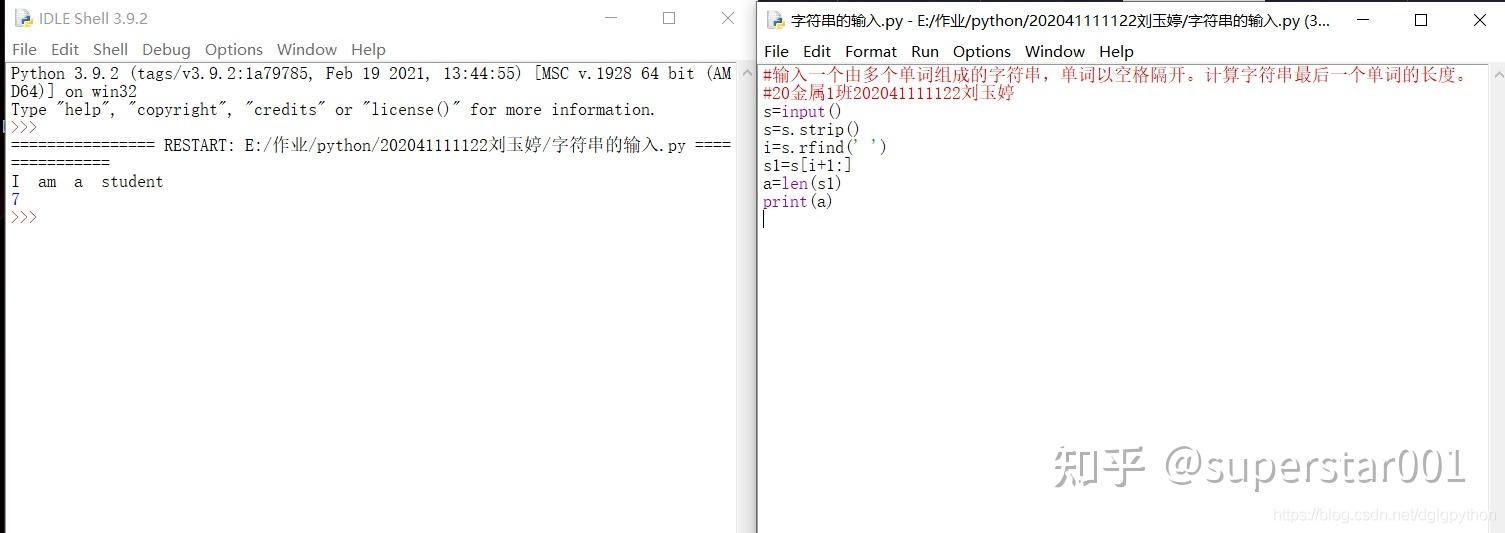
5、计算字符个数。 2-5.py 。输入一个由字母和数字组成的字符串(无空格),和一个字符,字符串和字符之间空格隔开,输出字符串中含有该字符的个数。不区分大小写。
s=input()
s=s.strip()
s=s.lower()
i=s[:-2]
a=s[-1]
b=i.count('a')
print(b)
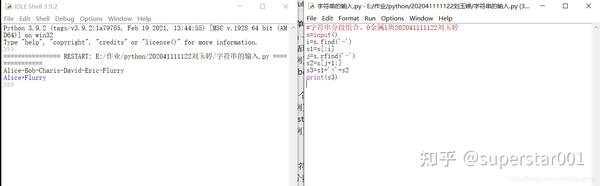
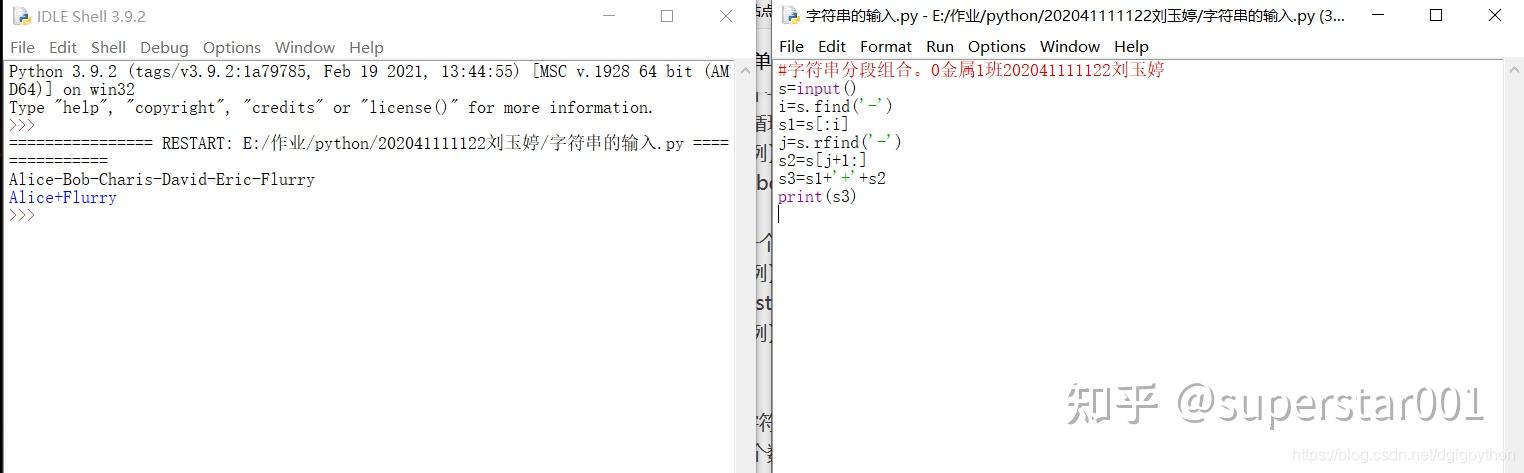
6、字符串分段组合。 2-6.py 。输入的一个字符串s,以字符减号(-)分割s,将其中首尾两段用加号(+)组合后输出。
1、货币转换。 3-1.py 。
(1)输入字符串,表示货币值,$开始表示美元,¥开始表示人民币。
(2)设人民币兑换美元的汇率是0.1456,美元兑换人民币的汇率是6.868。
(3)若输入的是美元,则转换为人民币,结果保留2位小数。若输入的是人民币,则转换为美元,结果保留2位小数。否则,则输出"输入有误"。
s=str(input('请输入货币值($开始表示美元,或¥开始表示人民币):'))
if s[0]=='$':
print('¥'+str('{:.2f}'.format(eval(s[1:])*6.868)))
elif s[0]=='¥':
print('$'+str('{:.2f}'.format(eval(s[1:])*0.1456)))
else:
print('输入有误')
2、判断一个正整数是否与7有关。
s=str(input('请输入一个正整数:'))
a=s.count('7')
b=eval(s)%7
if(a!=0 or b==0):
print(s+'是与7相关的数')
else:
print(s+'是与7无关的数')
3、出租车计费系统。 3-3.py 。当输入行程的总里程时,输出乘客应该付的车费(结果保留1位小数)。
计费标准具体为:起步价10元/3千米;超过3千米以后,每千米的费用为1.2元;超过10千米以后,每千米的费用为1.5元。
km=eval(input('请输入公里数:'))
if(km<0):
print('公里数输入错误,重新输入!')
elif(km==0):
print('您需要支付0元车费')
elif(0<km<=3):
print('您需要支付10元车费')
elif(3<km<=10):
print('您需要支付'+str('{:.1f}'.format((km-3)*1.2+10))+'元车费')
else:
print('您需要支付'+str('{:.1f}'.format((km-10)*1.5+18.4))+'元车费')
1、数字形式转换。 4-1.py 。
输入一个正整数,输出改数字对应的中文字符表示。
0到9对应的中文字符分别是:零一二三四五六七八九
n=input()
s="零一二三四五六七八九"
for i in n:
print(s[eval(i)], end="")
2.输入猴子吃完桃子的天数,输出猴子第一天共摘了桃子的个数。
猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个。第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半零一个。到第n天(<1<n<11)早上想再吃时,见只剩下一个桃子了。
n=eval(input('请输入猴子吃完桃子的天数:'))
sum=1
for i in range(n-1):
sum=(sum+1) * 2
print('猴子第一天共摘了'+str(sum)+'个桃子' )
3、输入两个正整数num1和num2(不超过500),求它们的最小公倍数并输出。
num1=eval(input('请输入第一个正整数:'))
num2=eval(input('请输入第二个正整数:'))
import math
a=num1*num2/math.gcd(num1,num2)
print(str(num1)+'和'+str(num2)+'的最小公倍数是'+'{:.0f}'.format(a))
4、无穷级数4/1 - 4/3 + 4/5 - 4/7 + ……的和是圆周率π,求圆周率π误差小于10的(-7)次方的时候停止计算,输出求得的圆周率π值是多少?
import math
PI=0
i=1
while abs(PI*4-math.pi)>=1e-7:
PI=PI+(-1)**(i+1)*(1/(2*i-1))
i+=1
print('PI=',PI*4)
5、输入一个正整数n(1<n<10),输出n行数字金字塔。
n=int(input('请输入金字塔的行数:'))
for i in range(1,n+1):
print(' '*(n-i)+(str(i)+' ')*i)
6、给定一个正整数max(>1),求[1,max]之间的所有与7无关的正整数的平方和。 4-6.py 。
与7相关的数:如果一个正整数,它是7的倍数,或者他的十进制表示法中某个位数上的数字为7,则称之为与7相关的数。
max=int(input('请输入一个正整数:'))
list=[]
for i in range(1,max+1):
if i % 7 != 0 and ("7"not in str(i)):
list.append(i)
sum=0
for j in list:
sum+= j*j
print(sum)
7、输入一个正整数max(>1),求[1,max]之间的所有完数,以空格分隔,并统计个数。
完数是指一个正整数的因子和(不包括它本身)等于它本身。
max = int(input('请输入一个正整数:'))
print('1~{}之间的完数有:'.format(max))
count=0
for i in range(1,max+1):
sum = 0
for j in range(1,i):
if i%j == 0:
sum += j
if sum == i:
count+=1
print(i,end=" ")
print('\n个数:%d'%count)
8、输入一个正整数max(>1),求[2,max]之间的所有素数,以空格分隔,并统计个数。
素数又称质数。一个大于1的自然数,除了1和它自身外,不能被其它整数整除的数叫做素数;否则称为合数。
max = int(input('请输入一个正整数:'))
print('1~{}之间的素数有:'.format(max))
count=0
for i in range(2,max):
for j in range(2,i):
if i%j == 0:
break
else:
print('{}'.format(i),end=" ")
count+=1
print('\n个数:{}'.format(count))
9、输入一个正整数max(>=100),求[100,max]之间的所有水仙花数,以空格分隔,并统计个数水仙花数是指一个n位数 (n≥3),它的每个位上的数字的n次幂之和等于它本身。
例如:153是一个“水仙花数”,因为:1的3次方+5的3次方+3的3次方=153
1634是一个“水仙花数”,因为:1的4次方+6的4次方+3的4次方+4的4次方=1634
max=int(input('请输入一个正整数:'))
print('100~{}之间的水仙花数有:'.format(max))
count=0
for i in range(100,max+1):
length=len(str(i))
sm=0
temp=i
for j in range(length):
sm+=(temp%10)**length
temp//=10
if sm==i:
print(i,end=" ")
count+=1
print('\n个数:{}'.format(count))
10、输入一个正整数n,输出斐波那契数列的前n项。每项占10位,左对齐,每行5个输出。斐波那契数列(Fibonacci sequence),指的是这样一个数列:1、1、2、3、5、8、13、21、34、……。这个数列从第3项开始,每一项都等于前两项之和。
n=int(input("请输入斐波那契数列的项数:"))
def fibonacci(n):
f1=1
f2=1
for i in range(1,n+1):
if i==1 or i==2:
yield i,1
continue
f1,f2=f2,f1+f2
yield i,f2
for i,x in fibonacci(n):
print(x,end=' '*(10-int(len(str(x)))))
1.请按照5-1-效果图.jpg所示,输入程序,输出多个正多边形。 5-1.py 。
2、参照第1题,进行改写。画笔颜色和填充颜色不同。 5-2.py 。输出如5-2-效果图.jpg所示。
3、请编写程序,实现输出不同颜色的圆及内切正多边形。 5-3.py 。输出如5-3-效果图.jpg所示。
【提示】circle(r,angle):绘制半径为r,弧度为angle的圆。
circle(r,360,n):绘制半径为r,弧度为360的圆形的内切正n边形。
4、请编写程序,实现输出不同颜色的多角星(五角星,七角星,九角星,十一角星,十三角星,十五角星)。 5-4.py 。输出如5-4-效果图.jpg所示。
5、正方形螺旋线的绘制。 5-5.py 。输出如5-5-效果图.jpg所示。
文件部分
一.创建“hamlet_词频.txt”文件。
#课本153-154页,例7-3。创建“hamlet_词频.txt”文件。 9-1.py 。
#20金属班202041111122刘玉婷
#编写函数对待分析文本进行预处理
def getText(text):
text = text.lower()
for ch in ",.;?-:\'":
text = text.replace(ch," ")
return text
#编写函数统计单词出现频率
#text为侍统计文本,topn表示取频率最高的单词个粉
def wordFreq(text,topn):
words = text.split() #将文本分词
counts ={}
for word in words:
counts[word] = counts.get(word,0) + 1
excludes={'the','and','to','of','a','be','it','is','not','but'}
for word in excludes:
del(counts[word])
items = list(counts.items())
return items[:topn]
#编写主程序,调用函数
try:
with open(r"D:\作业\Python\202041111103陈坤\第九次作业\9-1\hamlet.txt",'r',encoding='utf-8') as file:
text = file.read ()
text = getText(text)
freqs = wordFreq(text,10)
except IOError:
print("文件不存在,请确认!\n")
else:
try:
with open(r"D:\作业\Python\202041111103陈坤\第九次作业\9-1\hamlet_词频.txt",'w',encoding='utf-8') as fileFreq:
items = [ word + '\t' + str(freq) + '\n' for word,freq in freqs]
fileFreq.writelines(items)
except IOError:
print("写入文件出错")
for word,freq in freqs:
print("{:<10}{:>}".format(word, freq))
二.【提示】(1)请将文件“儿童谜语集.csv”放在自己的文件夹下,并在程序中指定文件位置。
(2)文件“儿童谜语集.csv”的编码请设置为:encoding='utf-8-sig'。
#课本154-156页,例7-4。 9-2.py 。20金属班202041111122刘玉婷
import os
import csv
import random
#定义函数打开文件,将谜语集读成字典
def getDic(fileName):
dic={}
with open(fileName,'r',encoding='utf-8-sig') as file:
reader=csv.reader(file)
next(reader) #跳过文件中的表头
for row in reader:
dic[row[0]]=row[1] #谜面作为key,谜底作为value
return dic
#定义函数根据dic生成长度为n的试卷列表,每一个元素为一套试卷列表
def creatPapers(dic,n):
tests=[]
items=list(dic.keys())
for i in range(n):
random.shuffle(items) #打乱列表顺序取前10题
ls=items[:10]
tests.append(ls)
return tests
#定义函数根据lsPapers和lsAnswers生成n个试卷文件和n个答卷文件
def createFiles(lsPapers,lsAnswers,n):
for i in range (n):
fpn="paper"+ str(i+1) + ".txt"
with open(fpn,'w',encoding='utf-8-sig') as filep:
filep.writelines([item + '\n' for item in lsPapers[i]])
fan="answer" + str(i+1) + ".txt"
with open(fan,'w',encoding='utf-8-sig') as filea:
filea.writelines([item + '\n' for item in lsAnswers[i]])
#主程序,生成n套试卷和答卷
os.chdir("D:\\作业\\Python\\202041111103陈坤\\第九次作业\\9-2")
fn="儿童谜语集.csv"
n=5
riddles=getDic(fn)
papers=creatPapers(riddles,n)
answers=[] #根据谜面列表papers生成对应的答案列表
for paper in papers:
ans=[riddles[item] for item in paper]
answers.append(ans)
createFiles(papers,answers,n)
三.【提示】(1)将字典的内容以列表的形式存储,用writer.writerows(lst)写入文件。
(2)文件“通信录.csv”的编码请设置为:encoding='utf-8-sig'。
#课本157页,课后习题第1题。创建“通信录.csv”文件。 9-3.py 。
#20金属班202041111122刘玉婷
import csv
dictTXL={"小新":{"手机":"13913000001","QQ":"18191220001","微信":"xx9907"},
"小亮":{"手机":"13913000002","QQ":"13913000002","微信":"13913000002"},
"小刚":{"手机":"13913000003","QQ":"18191220003","微信":"gang1004"},
"大刘":{"手机":"13914000001","QQ":"18191230001","微信":"liu666"},
"大王":{"手机":"13914000002","QQ":"18191230002","微信":"jack_w"},
"大张":{"手机":"13914000003","QQ":"18191230003","微信":"13914000003"}}
lst1=["姓名","手机","QQ","微信"]
lst2=[]
for k,v in dictTXL.items():
lst=[]
lst.append(k)
for i in v.values():
lst.append(i)
lst2.append(lst)
lst3=[lst1]+lst2
print(lst3)
print("\n姓名:大王")
print("手机号:{}".format(dictTXL["大王"]["手机"]))
print("QQ号:{}".format(dictTXL["大王"]["QQ"]))
print("微信号:{}".format(dictTXL["大王"]["微信"]))
with open("通讯录.csv",'w',encoding='utf-8-sig',newline='') as f:
writer=csv.writer(f)
writer.writerows(lst3)
四.将文件“ 实验9-4调查问卷.py ”的代码补充完整。
程序结果如图:实验9-4-运行示例.jpg。
生成的文件如图:实验9-4-文件示例.jpg。
# 调查问卷随机产生,写入文件。统计各评语出现的次数,生成字典。把统计结果再写入文件。
#20金属班202041111122刘玉婷
import random
def Qnaire(lst,n): # 从lst中,随机产生n份调查问卷,存于字符串并返回
result=random.sample(lst,1)
while len(result)<n:
result=result+random.sample(lst,1)
return result
def Qnairewrite(filename,text): # 将字符串text写入文件filename中
with open(filename,'w',encoding='utf-8') as f:
f.write(','.join(text))
f.write('\n')
def Qnaireread(filename): # 将文件内容读出,放于字符串中,并返回
with open(filename,'r',encoding='utf-8') as f:
return result
def cntComments(text): # 对字符串text,统计各评语出现的次数,生成字典,并返回
dic={}
for x in comments:
n=result.count(x)
dic[x]=n
dic["满意"]=dic["满意"]-dic["不满意"]-dic["很满意"]
return dic
def dictappend(filename,dicCnts): # 往将调查问卷的结果dicCnts,追加到文件中filename
with open(filename,'a',encoding='utf-8') as f:
f.write('\n\n根据统计,对伙食感觉:\n')
for k,v in dicCnts.items():
f.write("{}的学生:{}人\n".format(k,v))
for k,v in dicCnts.items():
if v==max(dicCnts.values()):
f.write("调查结果中,出现次数最多的评语是:{}".format(k))
pathfile="TXT\\result1.txt"
comments=['不满意','一般','满意','很满意']
result=Qnaire(comments,90) # 产生90份随机调查问卷结果,放于result中
Qnairewrite(pathfile,result) # 将调查问卷结果result,写入文件pathfile
result=Qnaireread(pathfile) # 将文件pathfile中内容读出,放于result中
print("\n{} 调查问卷(随机产生):\n\n{}".format(pathfile,result))
dicCnts=cntComments(result) # 将调查结果result,统计各评语出现的次数,生成字典,放于dicCnts中
print("\n调查问卷中各评语的统计结果:\n{}".format(dicCnts))
dictappend(pathfile,dicCnts) # 将各评语出现的次数dicCnts,追加写入文件pathfile中
result=Qnaireread(pathfile) # 将文件pathfile中内容读出,放于result中
print("\n{} 调查问卷及各评语的统计结果:\n\n{}".format(pathfile,result))
5、用两种方法求文件“latex.log”的文件总行数、除了空行以外的文件行数、除了空行以外的不重复的文件行数。 9-5.py 。
【运行结果】
方法一:文件一行一行访问
TXT\latex.log 文件总行数:5310
TXT\latex.log 除了空行以外的文件行数:4951
TXT\latex.log 除了空行以外的不重复的文件行数:410
方法二:文件读出到列表中
TXT\latex.log 文件总行数:5310
TXT\latex.log 除了空行以外的文件行数:4951
TXT\latex.log 除了空行以外的不重复的文件行数:410
#用两种方法求文件“latex.log”的文件总行数、除了空行以外的文件行数、除了空行以外的不重复的文件行数。 9-5.py
#20金属班202041111122刘玉婷
def filelines1(filename):
with open(filename,'r',encoding='utf-8') as f:
cnt1=0
cnt2=0
lst=[]
for line in f:
cnt1=cnt1+1
if line!='\n':
cnt2=cnt2+1
if line not in lst:
lst.append(line)
cnt3=len(lst)
return (cnt1,cnt2,cnt3)
def fileline2(filename):
with open(filename,'r',encoding='utf-8') as f:
lst=f.readlines()
cnt1=len(lst)
lst1=[]
for i in lst:
if i!='\n':
lst1.append(i)
cnt2=len(lst1)
lst=list(set(lst1))
cnt3=len(lst)
return (cnt1,cnt2,cnt3)
filepath1="latex.log"
cnt1,cnt2,cnt3=filelines1(filepath1)
print("方法一:文件一行一行访问")
print("{}文件总行数:{}".format(filepath1,cnt1))
print("{}除了空行以外的文件行数:{}".format(filepath1,cnt2))
print("{}除了空行以外的不重复的文件行数:{}".format(filepath1,cnt3))
print("\n")
cnt1,cnt2,cnt3=fileline2(filepath1)
print("方法二:文件读出到列表中")
print("{}文件总行数:{}".format(filepath1,cnt1))
print("{}除了空行以外的文件行数:{}".format(filepath1,cnt2))
print("{}除了空行以外的不重复的文件行数:{}".format(filepath1,cnt3))
6、请将文件data1.csv的每行的空格去掉并按照列逆序排列,数据之间用分号隔开,将结果存放在data3.csv文件并输出。
#请将文件data1.csv的每行的空格去掉并按照列逆序排列, 数据之间用分号隔开9-6.py 。
#20金属班202041111122刘玉婷
import csv
def readfile(filename):
with open(filename,'r',encoding='utf-8-sig') as f:
text=f.read ()
return text
def filereverse(filename1,filename2):
with open(filename1,'r',encoding='utf-8-sig') as f:
lst=f.readlines()
with open(filename2,'w',encoding='utf-8-sig') as f:
for line in lst:
line=line.replace("\n","")
line=line.replace(" ","")
ls=line.split(",")
ls=ls[::-1]
line=";".join(ls)
line=line+'\n'
f.write(line)
filepath1="data1.csv"
filepath2="data3.csv"
text=readfile(filepath1)
print("{}文件:\n{}".format(filepath1,text))
filereverse(filepath1,filepath2)
text=readfile(filepath2)
print("{}文件:\n{}".format(filepath2,text))
10.1生成词云resultcloud.png。
#生成词云resultcloud.png。 10-1.py 。20金属班202041111122刘玉婷
import wordcloud
import random
import string #导入string库
# string.ascii_uppercase可以获取所有的大写字母
lstChar = [x for x in string.ascii_uppercase]
#使用randint获取26个随机整数
lstfreq = [random.randint(1,100) for i in range(26)]
#使用字典生成式,产生形式如{'A': 80, 'B': 11, 'C': 38……]的字典
freq = {x[0]:x[1] for x in zip(lstChar,lstfreq)}
print(freq)
wcloud = wordcloud.WordCloud(
background_color = "white",width=1000,
max_words = 50,
height = 860, margin = 1).fit_words(freq) #利用字典freq生成词云
wcloud.to_file("resultcloud.png") #将生成的词云图片保存
print('结束')
10.2、根据“红楼梦.txt”,并统计出场次数最多的20个人物,生成词频文件“红楼梦_词频.txt”。 10-2.py 。
【提示】参照课本167-171页,使用停用词表“stop_words.txt”,并对同一人物的不同称谓进行处理。生成文件内容参照课本171页图8-11。
# 10-2.py 。20金属班202041111122刘玉婷
import jieba
def getText(filepath):
f=open(filepath, 'r',encoding='utf-8')
text=f.read ()
f.close()
return text
def stopwordslist(filepath):
stopwords = [line.strip() for line in open (filepath, 'r',encoding='utf-8').readlines()]
return stopwords
def wordFreg(filepath,text,topn):
words = jieba.lcut(text.strip())
counts= {}
stopwords = stopwordslist('stop_words.txt')
for word in words:
if len(word) == 1:
continue
elif word not in stopwords:
if word == "凤姐儿":
word="凤姐"
elif word=="林黛玉" or word== "林妹妹" or word=="黛玉笑":
word="黛玉"
elif word == "宝二爷":
word="宝玉"
elif word == "袭人道":
word="袭人"
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
f=open(filepath[:-4]+'_词频.txt','w')
for i in range(topn):
word,count=items[i]
f.write("{}\t{}\n".format(word,count))
f.close()
filepath="红楼梦.txt"
text=getText(filepath)
topn=20
wordFreg(filepath,text,topn)
10.3、使用第2题生成的“红楼梦_词频.txt”,制作词云。要求使用图片不是五角星。 10-3.py 。
【提示】参照课本172页,图片上网找不同于五角星的图片。
# 10-3.py 。20金属班202041111122刘玉婷
import matplotlib.pyplot as plt
import wordcloud
import PIL .Image as image
import numpy as np
f = open("红楼梦_词频.txt",'r')
text = f.read ()
f.close()
mask=np.array( image.open ("str.jpg"))
wcloud=wordcloud.WordCloud(font_path=r'C:\Windows\Fonts\simhei.ttf',
background_color = "white",width=1000,
max_words = 500,
mask=mask,
height = 860,margin = 2).generate(text)
wcloud.to_file("红楼梦cloud_star.png") #保存图片
#显示词云图片
plt.imshow(wcloud)
plt.axis('off')
plt.show ()
4、根据“红楼梦.txt”,分析每一回里,“笑”和“喜”、“哭”与“悲”分别出现的次数,制作折线图,生成“红楼梦悲喜变化图.png”。 10-4.py 。
【提示】(1)先对“红楼梦.txt”进行章节拆分。参照课本173-174页。
(2)制作折线图,生成“红楼梦悲喜变化图.png”。生成图片参照课本176页图8-16。
#生成“红楼梦悲喜变化图.png”。 10-4.py 。20金属班202041111122刘玉婷
f = open('红楼梦.txt','r',encoding='utf-8')
s = f.read () #读取《红楼梦》文本
import re
lst_chapter = []
chapter = re.findall("第[\u4E00-\u9FA5]+回",s)#"第([\u4E00-\u9FA5]+)回"返回第和回中间的内容"
for x in chapter:
if x not in lst_chapter and len(x)<=5:
lst_chapter.append(x)
print(lst_chapter)
lst_start_chapterindex = []
for x in chapter:
lst_start_chapterindex.append(s.index(x)) #存放每一回起始索引
print(lst_start_chapterindex)
lst_end_chapterindex = lst_start_chapterindex[1:]+[len(s)] #存放每一回结束索引
lst_chapterindex=list(zip(lst_start_chapterindex,lst_end_chapterindex))
#将每一回的起始索引和结束索引通过zip合并,存放在lst_chapterindex中
print(lst_chapterindex)
cnt_laugh = []
cnt_cry = []
for ii in range(120):
start = lst_chapterindex[ii][0]
end =lst_chapterindex[ii][1]
cnt_laugh.append(s[start:end].count("笑")+s[start:end].count("喜"))
cnt_cry.append(s[start:end].count("哭")+s[start:end].count("悲"))
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.figure(figsize =(18,4))
plt.plot(cnt_laugh,label="笑和喜")
plt.plot(cnt_cry,label="哭和悲")
plt.xlabel("章节数",Fontproperties='SimHei')
plt.ylabel("出现次数",Fontproperties='SimHei')
plt.legend()
plt.title("《红楼梦》120回悲喜变化图",Fontproperties='SimHei')
plt.show ()
————————————————
版权声明:本文为CSDN博主「东莞喵喵python」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
