

Presto Connector 实现原理

前言
Presto 的一大特色是支持多源联合查询,而实现多数据源是通过 Connector 机制来实现的,Presto 内置有多种数据源,如 Hive、MySQL、MongoDB、Kafka 等十多种。不仅如此,Presto 的扩展机制允许自定义 Connector,从而实现对订制数据源的查询需求。理解 Presto 的关键之一是了解 Connector 的工作原理和实现方式。本文通过源代码解析的方式,通过 MySQL 为例,详细介绍 Connector Presto 的实现原理。
Presto 插件
在Presto中,用户自定义函数(UDF)、事件监听器(Event Listener)、支持的数据类型(Data Types和Parameter Types)、访问控制(Access Control)、资源组(Resource Group)以及本文将要介绍的Connector都是通过插件机制实现的。
插件类定义
Presto将支持的所有插件类型封装在一个统一的接口中:
public interface Plugin
default Iterable<ConnectorFactory> getConnectorFactories()
return emptyList();
default Iterable<BlockEncoding> getBlockEncodings()
return emptyList();
default Iterable<Type> getTypes()
return emptyList();
default Iterable<ParametricType> getParametricTypes()
return emptyList();
default Set<Class<?>> getFunctions()
return emptySet();
default Iterable<SystemAccessControlFactory> getSystemAccessControlFactories()
return emptyList();
default Iterable<PasswordAuthenticatorFactory> getPasswordAuthenticatorFactories()
return emptyList();
default Iterable<EventListenerFactory> getEventListenerFactories()
return emptyList();
default Iterable<ResourceGroupConfigurationManagerFactory> getResourceGroupConfigurationManagerFactories()
return emptyList();
default Iterable<SessionPropertyConfigurationManagerFactory> getSessionPropertyConfigurationManagerFactories()
return emptyList();
default Iterable<FunctionNamespaceManagerFactory> getFunctionNamespaceManagerFactories()
return emptyList();
插件加载流程
当Presto启动的时候从以下路径加载Plugin:(PluginManager.loadPlugins)
public void loadPlugins()
throws Exception{
for (File file : listFiles(installedPluginsDir)) {
if (file.isDirectory()) {
loadPlugin(file.getAbsolutePath());
for (String plugin : plugins) {
loadPlugin(plugin);
其中installedPluginsDir通过以下配置项配置:
@Config("plugin.dir")
public PluginManagerConfig setInstalledPluginsDir(File installedPluginsDir)
this.installedPluginsDir = installedPluginsDir;
return this;
plugins通过以下配置项配置:
@Config("plugin.bundles")
public PluginManagerConfig setPlugins(String plugins)
if (plugins == null) {
this.plugins = null;
else {
this.plugins = ImmutableList.copyOf(Splitter.on(',').omitEmptyStrings().trimResults().split(plugins));
return this;
plugin.bundles配置在config.properties配置文件,默认在开发环境是各个插件模块对应的pom文件路径,用于从maven仓库加载依赖的jar包。在生产环境部署时候,通常指定插件目录即可。将每种插件依赖的三方包放在$installedPluginsDir/<pluginName>目录下,将插件的配置文件放在$PrestoHome/etc/ 路径下,pluginName 为插件的名称。但是针对不同的插件类型,配置文件放置的位置略有不同,比如
- 对于Event Listerner类型的插件,其配置文件固定为$PrestoHome/etc/event-listener.properties;
- 对于UDF则不需要配置文件;
- 对于名称为mysql的connector插件,其配置文件为$PrestoHome/etc/catalog/mysql.properties。因为每种插件依赖的包位于不同的路径,根据不同的类加载器加载 就可以避免包冲突问题:
private void loadPlugin(String plugin)
throws Exception
log.info("-- Loading plugin %s --", plugin);
URLClassLoader pluginClassLoader = buildClassLoader(plugin);
try (ThreadContextClassLoader ignored = new ThreadContextClassLoader(pluginClassLoader)) {
loadPlugin(pluginClassLoader);
log.info("-- Finished loading plugin %s --", plugin);
//SPI机制加载实现了Plugin接口的类
private void loadPlugin(URLClassLoader pluginClassLoader)
ServiceLoader<Plugin> serviceLoader = ServiceLoader.load(Plugin.class, pluginClassLoader);
List<Plugin> plugins = ImmutableList.copyOf(serviceLoader);
if (plugins.isEmpty()) {
log.warn("No service providers of type %s", Plugin.class.getName());
for (Plugin plugin : plugins) {
log.info("Installing %s", plugin.getClass().getName());
installPlugin(plugin);
//在这里通过Plugin的“分发”接口依次列举并注册所有的插件类型
public void installPlugin(Plugin plugin)
for (ConnectorFactory connectorFactory : plugin.getConnectorFactories()) {
log.info("Registering connector %s", connectorFactory.getName());
connectorManager.addConnectorFactory(connectorFactory);
for (EventListenerFactory eventListenerFactory : plugin.getEventListenerFactories()) {
log.info("Registering event listener %s", eventListenerFactory.getName());
eventListenerManager.addEventListenerFactory(eventListenerFactory);
最终处理落到方法:installPlugin(Plugin plugin),在该方法中将所有支持的插件按照类型分别存放到不同的manager的Factories,如Connector插件存放到ConnectorManager,Event Listener存放到EventListenerManager中。所谓Factories其实就是一个内存Map,比如ConnectorManager的
private final ConcurrentMap<String, ConnectorFactory> connectorFactories = new ConcurrentHashMap<>();
和EventListenerManager的
private final Map<String, EventListenerFactory> eventListenerFactories = new ConcurrentHashMap<>();
插件与SPI
上文中已经了解到这行关键的代码:
ServiceLoader<Plugin> serviceLoader = ServiceLoader.load(Plugin.class, pluginClassLoader);
它用到了Java SPI(Service Provider Interface)。所谓SPI,就是JDK内置的一种服务提供发现机制,简单说就是给定接口,动态加载接口的实现。比如我们熟知的java.sql.Driver是一个接口,在使用Driver的时候根据提供的实现动态选择mysql的Driver还是postgresql的Driver。使用SPI只需要在resources目录下创建目录META-INF/services,然后在services下创建以接口全名命名的文件即可,内容为对应接口的实现类全名,比如:文件名 META-INF/services/com.facebook.presto.spi.Plugin 对应的内容为:
com.facebook.presto.plugin.mysql.MySqlPlugin
注意:翻看mysql的connector的源代码中并不能找到META-INF/services及接口类文件声明,这是因为Presto使用了插件自动发现功能,自动创建了对应的目录和文件,比如在PluginManager中的这个方法:
private URLClassLoader buildClassLoaderFromPom(File pomFile)
throws Exception
List<Artifact> artifacts = resolver.resolvePom(pomFile);
URLClassLoader classLoader = createClassLoader(artifacts, pomFile.getPath());
Artifact artifact = artifacts.get(0);
Set<String> plugins = discoverPlugins(artifact, classLoader);
if (!plugins.isEmpty()) {
writePluginServices(plugins, artifact.getFile());
return classLoader;
该方法调用的方法discoverPlugins和writePluginServices分别实现了插件声明的发现和写入。
Catalog 加载流程
从Connector的加载流程,我们了解到所有的ConnectorFactory都被注册到ConnectorFactory的Map内存结构中。但真正能够使用该Connector还需要加载Catalog,所谓Catalog就是Presto的数据源类别,Presto通过如下三级结构来定义数据表:
catalog=>schema=>table
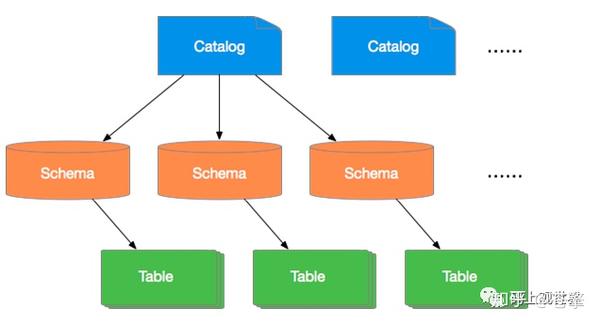
比如每个mysql实例都是一个catalog,每个mysql实例都有独立的域名、端口和登录账号等信息,schema 类比每个mysql实例的数据库。因此不同的Catalog可以使用同一个 Connector,Connector实例由ConnectorFactory来创建。所有的catalog的配置文件都位于$PrestoHome/etc/catalog路径下,加载流程从StaticCatalogStore的loadCatalogs方法开始:
public void loadCatalogs()
throws Exception{
for (File file : listFiles(catalogConfigurationDir)) {
if (file.isFile() && file.getName().endsWith(".properties")) {
loadCatalog(file);
private void loadCatalog(File file)
throws Exception{
String catalogName = Files.getNameWithoutExtension(file.getName());
if (disabledCatalogs.contains(catalogName)) {
log.info("Skipping disabled catalog %s", catalogName);
return;
log.info("-- Loading catalog %s --", file);
Map<String, String> properties = new HashMap<>(loadProperties(file));
String connectorName = properties.remove("connector.name");
checkState(connectorName != null, "Catalog configuration %s does not contain connector.name", file.getAbsoluteFile());
connectorManager.createConnection(catalogName, connectorName, ImmutableMap.copyOf(properties));
log.info("-- Added catalog %s using connector %s --", catalogName, connectorName);
public synchronized ConnectorId createConnection(String catalogName, String connectorName, Map<String, String> properties)
requireNonNull(connectorName, "connectorName is null");
ConnectorFactory connectorFactory = connectorFactories.get(connectorName);
checkArgument(connectorFactory != null, "No factory for connector %s", connectorName);
return createConnection(catalogName, connectorFactory, properties);
private synchronized ConnectorId createConnection(String catalogName, ConnectorFactory connectorFactory, Map<String, String> properties)
checkState(!stopped.get(), "ConnectorManager is stopped");
requireNonNull(catalogName, "catalogName is null");
requireNonNull(properties, "properties is null");
requireNonNull(connectorFactory, "connectorFactory is null");
checkArgument(!catalogManager.getCatalog(catalogName).isPresent(), "A catalog already exists for %s", catalogName);
ConnectorId connectorId = new ConnectorId(catalogName);
checkState(!connectors.containsKey(connectorId), "A connector %s already exists", connectorId);
addCatalogConnector(catalogName, connectorId, connectorFactory, properties);
return connectorId;
以上流程非常简单,整个流程的入参主要有两个:connectorName和catalogName,结果输出catalog对应的connectorId。connectorName从配置的Connector Plugin的connector.name配置项中获得,catalogName从catalog目录下的配置文件的文件名前缀解析获得,而创建Connector用到前面提到的ConnectorFactory。真正起作用的主要逻辑在addCatalogConnector方法中实现。
Catalog模型
在看addCatalogConnector实现逻辑之前,有必要先了解下Catalog模型:
public class Catalog
private final String catalogName;
private final ConnectorId connectorId;
private final Connector connector;
private final ConnectorId informationSchemaId;
private final Connector informationSchema;
private final ConnectorId systemTablesId;
private final Connector systemTables;
public Catalog(
String catalogName,
ConnectorId connectorId,
Connector connector,
ConnectorId informationSchemaId,
Connector informationSchema,
ConnectorId systemTablesId,
Connector systemTables)
从Catalog定义可知,每种数据源除了自身对应的Connector之外,还有另外两种:informationSchema和systemTables。其中information_schema对应了管理数据源的元数据信息,比如在mysql中,informationSchema存储了所有数据库的信息,如数据库名,数据库的表,表栏的数据类型与访问权限等,但systemTables不是每个数据源都有的。3个ConnectorId都跟catalogName关联:
public final class ConnectorId
private static final String INFORMATION_SCHEMA_CONNECTOR_PREFIX = "$info_schema@";
private static final String SYSTEM_TABLES_CONNECTOR_PREFIX = "$system@";
private final String catalogName;
@JsonCreator
public ConnectorId(String catalogName)
this.catalogName = requireNonNull(catalogName, "catalogName is null");
if (catalogName.isEmpty()) {
throw new IllegalArgumentException("catalogName is empty");
public static ConnectorId createInformationSchemaConnectorId(ConnectorId connectorId)
return new ConnectorId(INFORMATION_SCHEMA_CONNECTOR_PREFIX + connectorId.getCatalogName());
public static ConnectorId createSystemTablesConnectorId(ConnectorId connectorId)
return new ConnectorId(SYSTEM_TABLES_CONNECTOR_PREFIX + connectorId.getCatalogName());
Catalog注册过程
private synchronized void addCatalogConnector(String catalogName, ConnectorId connectorId, ConnectorFactory factory, Map<String, String> properties){
// create all connectors before adding, so a broken connector does not leave the system half updated
MaterializedConnector connector = new MaterializedConnector(connectorId, createConnector(connectorId, factory, properties));
MaterializedConnector informationSchemaConnector = new MaterializedConnector(
createInformationSchemaConnectorId(connectorId),
new InformationSchemaConnector(catalogName, nodeManager, metadataManager, accessControlManager, connector.getSessionProperties()));
ConnectorId systemId = createSystemTablesConnectorId(connectorId);
SystemTablesProvider systemTablesProvider;
if (nodeManager.getCurrentNode().isCoordinator()) {
systemTablesProvider = new DelegatingSystemTablesProvider(
new StaticSystemTablesProvider(connector.getSystemTables()),
new MetadataBasedSystemTablesProvider(metadataManager, catalogName));
else {
systemTablesProvider = new StaticSystemTablesProvider(connector.getSystemTables());
MaterializedConnector systemConnector = new MaterializedConnector(systemId, new SystemConnector(
systemId,
nodeManager,
systemTablesProvider,
transactionId -> transactionManager.getConnectorTransaction(transactionId, connectorId),
connector.getSessionProperties()));
Catalog catalog = new Catalog(
catalogName,
connector.getConnectorId(),
connector.getConnector(),
informationSchemaConnector.getConnectorId(),
informationSchemaConnector.getConnector(),
systemConnector.getConnectorId(),
systemConnector.getConnector());
addConnectorInternal(connector);
addConnectorInternal(informationSchemaConnector);
addConnectorInternal(systemConnector);
catalogManager.registerCatalog(catalog);
其中MaterializedConnector的定义为:
private static class MaterializedConnector
private final ConnectorId connectorId;
private final Connector connector;
private final ConnectorSplitManager splitManager;
private final Set<SystemTable> systemTables;
private final Set<Procedure> procedures;
private final ConnectorPageSourceProvider pageSourceProvider;
private final Optional<ConnectorPageSinkProvider> pageSinkProvider;
private final Optional<ConnectorIndexProvider> indexProvider;
private final Optional<ConnectorNodePartitioningProvider> partitioningProvider;
private final Optional<ConnectorPlanOptimizerProvider> planOptimizerProvider;
private final Optional<ConnectorAccessControl> accessControl;
private final List<PropertyMetadata<?>> sessionProperties;
private final List<PropertyMetadata<?>> tableProperties;
private final List<PropertyMetadata<?>> schemaProperties;
private final List<PropertyMetadata<?>> columnProperties;
private final List<PropertyMetadata<?>> analyzeProperties;
MaterializedConnector包装了Connector所有需要的信息,如进行数据读取的分片管理器ConnectorSplitManager、用于索引读取的ConnectorIndexProvider、用于分页读取的ConnectorPageSourceProvider、用于分页写入的ConnectorPageSinkProvider以及各种属性元数据PropertyMetadata等,而addConnectorInternal方法则将MaterializedConnector包装的各属性注册到对应的Manager:如ConnectorSplitManager注册到SplitManager,ConnectorIndexProvider注册到IndexManager,ConnectorPageSourceProvider注册到PageSourceManager,ConnectorPageSinkProvider注册到PageSinkManager,各种属性注册到MetadataManager等,addConnectorInternal实现逻辑如下:
private synchronized void addConnectorInternal(MaterializedConnector connector)
checkState(!stopped.get(), "ConnectorManager is stopped");
ConnectorId connectorId = connector.getConnectorId();
checkState(!connectors.containsKey(connectorId), "A connector %s already exists", connectorId);
connectors.put(connectorId, connector);
splitManager.addConnectorSplitManager(connectorId, connector.getSplitManager());
pageSourceManager.addConnectorPageSourceProvider(connectorId, connector.getPageSourceProvider());
connector.getPageSinkProvider()
.ifPresent(pageSinkProvider -> pageSinkManager.addConnectorPageSinkProvider(connectorId, pageSinkProvider));
connector.getIndexProvider()
.ifPresent(indexProvider -> indexManager.addIndexProvider(connectorId, indexProvider));
connector.getPartitioningProvider()
.ifPresent(partitioningProvider -> partitioningProviderManager.addPartitioningProvider(connectorId, partitioningProvider));
if (nodeManager.getCurrentNode().isCoordinator()) {
connector.getPlanOptimizerProvider()
.ifPresent(planOptimizerProvider -> connectorPlanOptimizerManager.addPlanOptimizerProvider(connectorId, planOptimizerProvider));
metadataManager.getProcedureRegistry().addProcedures(connectorId, connector.getProcedures());
connector.getAccessControl()
.ifPresent(accessControl -> accessControlManager.addCatalogAccessControl(connectorId, accessControl));
metadataManager.getTablePropertyManager().addProperties(connectorId, connector.getTableProperties());
metadataManager.getColumnPropertyManager().addProperties(connectorId, connector.getColumnProperties());
metadataManager.getSchemaPropertyManager().addProperties(connectorId, connector.getSchemaProperties());
metadataManager.getAnalyzePropertyManager().addProperties(connectorId, connector.getAnalyzeProperties());
metadataManager.getSessionPropertyManager().addConnectorSessionProperties(connectorId, connector.getSessionProperties());
只有完成这一步catalog的注册,catalog才可以真正对外提供服务:如查看当前catalog的所有schema等元信息,查看当前catalog支持的函数,从catalog读取或者写入数据等。
Connector模型
再次回到Plugin接口定义来看看关于Connector接口方法的定义:
public interface Plugin
default Iterable<ConnectorFactory> getConnectorFactories()
return emptyList();
方法返回一个ConnectorFactory迭代器,用于创建具体的Connector,为了进一步了解ConnectorFactory的实现,我们以Mysql为例来详细探索。从Mysql Plugin插件实现声明直达JdbcPlugin:
@Override
public Iterable<ConnectorFactory> getConnectorFactories()
return ImmutableList.of(new JdbcConnectorFactory(name, module, getClassLoader()));
public interface ConnectorFactory
String getName();
ConnectorHandleResolver getHandleResolver();
Connector create(String catalogName, Map<String, String> config, ConnectorContext context);
实现ConnectorFactory接口需要需要实现以上3个方法,后面2个方法是重点也是难点。其中getHandleResolver返回一个ConnectorHandleResolver接口,用于对数据源的解析处理,各接口方法定义如下:
public interface ConnectorHandleResolver
Class<? extends ConnectorTableHandle> getTableHandleClass();
Class<? extends ConnectorTableLayoutHandle> getTableLayoutHandleClass();
Class<? extends ColumnHandle> getColumnHandleClass();
Class<? extends ConnectorSplit> getSplitClass();
default Class<? extends ConnectorIndexHandle> getIndexHandleClass()
throw new UnsupportedOperationException();
default Class<? extends ConnectorOutputTableHandle> getOutputTableHandleClass()
throw new UnsupportedOperationException();
default Class<? extends ConnectorInsertTableHandle> getInsertTableHandleClass()
throw new UnsupportedOperationException();
default Class<? extends ConnectorPartitioningHandle> getPartitioningHandleClass()
throw new UnsupportedOperationException();
default Class<? extends ConnectorTransactionHandle> getTransactionHandleClass()
throw new UnsupportedOperationException();
Mysql的ConnectorHandleResolver由类JdbcHandleResolver来实现。ConnectorFactory的另一个重要方法是create,用于创建Connector,Connector也是一个接口,其定义为:
public interface Connector
ConnectorTransactionHandle beginTransaction(IsolationLevel isolationLevel, boolean readOnly);
* Guaranteed to be called at most once per transaction. The returned metadata will only be accessed
* in a single threaded context.
ConnectorMetadata getMetadata(ConnectorTransactionHandle transactionHandle);
ConnectorSplitManager getSplitManager();
* @throws UnsupportedOperationException if this connector does not support reading tables page at a time
default ConnectorPageSourceProvider getPageSourceProvider()
throw new UnsupportedOperationException();
* @throws UnsupportedOperationException if this connector does not support reading tables record at a time
default ConnectorRecordSetProvider getRecordSetProvider()
throw new UnsupportedOperationException();
* @throws UnsupportedOperationException if this connector does not support writing tables page at a time
default ConnectorPageSinkProvider getPageSinkProvider()
throw new UnsupportedOperationException();
* @throws UnsupportedOperationException if this connector does not support indexes
default ConnectorIndexProvider getIndexProvider()
throw new UnsupportedOperationException();
* @throws UnsupportedOperationException if this connector does not support partitioned table layouts
default ConnectorNodePartitioningProvider getNodePartitioningProvider()
throw new UnsupportedOperationException();
* @throws UnsupportedOperationException if this connector does not need to optimize query plans
default ConnectorPlanOptimizerProvider getConnectorPlanOptimizerProvider()
throw new UnsupportedOperationException();
* @return the set of system tables provided by this connector
default Set<SystemTable> getSystemTables()
return emptySet();
* @return the set of procedures provided by this connector
default Set<Procedure> getProcedures()
return emptySet();
* @return the system properties for this connector
default List<PropertyMetadata<?>> getSessionProperties()
return emptyList();
* @return the schema properties for this connector
default List<PropertyMetadata<?>> getSchemaProperties()
return emptyList();
* @return the analyze properties for this connector
default List<PropertyMetadata<?>> getAnalyzeProperties()
return emptyList();
* @return the table properties for this connector
default List<PropertyMetadata<?>> getTableProperties()
return emptyList();
* @return the column properties for this connector
default List<PropertyMetadata<?>> getColumnProperties()
return emptyList();
* @throws UnsupportedOperationException if this connector does not have an access control
default ConnectorAccessControl getAccessControl()
throw new UnsupportedOperationException();
* Commit the transaction. Will be called at most once and will not be called if
* {@link #rollback(ConnectorTransactionHandle)} is called.
default void commit(ConnectorTransactionHandle transactionHandle)
* Rollback the transaction. Will be called at most once and will not be called if
* {@link #commit(ConnectorTransactionHandle)} is called.
* Note: calls to this method may race with calls to the ConnectorMetadata.
default void rollback(ConnectorTransactionHandle transactionHandle)
* True if the connector only supports write statements in independent transactions.
default boolean isSingleStatementWritesOnly()
return false;
* Shutdown the connector by releasing any held resources such as
* threads, sockets, etc. This method will only be called when no
* queries are using the connector. After this method is called,
* no methods will be called on the connector or any objects that
* have been returned from the connector.
default void shutdown() {}
default Set<ConnectorCapabilities> getCapabilities()
return emptySet();
接口方法比较多,总体来看都是跟对数据源的读写操作紧密相关。
@Override
public Connector create(String catalogName, Map<String, String> requiredConfig, ConnectorContext context)
requireNonNull(requiredConfig, "requiredConfig is null");
try (ThreadContextClassLoader ignored = new ThreadContextClassLoader(classLoader)) {
Bootstrap app = new Bootstrap(
binder -> {
binder.bind(FunctionMetadataManager.class).toInstance(context.getFunctionMetadataManager());
binder.bind(StandardFunctionResolution.class).toInstance(context.getStandardFunctionResolution());
binder.bind(RowExpressionService.class).toInstance(context.getRowExpressionService());
new JdbcModule(catalogName),
module);
Injector injector = app
.strictConfig()
.doNotInitializeLogging()
.setRequiredConfigurationProperties(requiredConfig)
.initialize();
return injector.getInstance(JdbcConnector.class);