


Flink实时数仓-02-DWD层搭建
-
- DWD层
-
- 流量域未经加工的事务事实表(※)
- 流量域独立访客事务事实表
- 流量域用户跳出事务事实表
- Join方式介绍(附)
- 交易域加购事务事实表
- 交易域订单预处理表(※)
- 交易域下单事务事实表
- 交易域取消订单事务事实表
- 交易域支付成功事务事实表
- 交易域退单事务事实表
- 交易域退款成功事务事实表
- 工具域优惠券领取事务事实表
- 工具域优惠券使用(下单)事务事实表
- 工具域优惠券使用(支付)事务事实表
- 互动域收藏商品事务事实表
- 互动域评价事务事实表
- 用户域用户注册事务事实表
数据传输过程中可能会出现部分数据丢失的情况,导致 JSON 数据结构不再完整,因此需要对脏数据进行过滤。
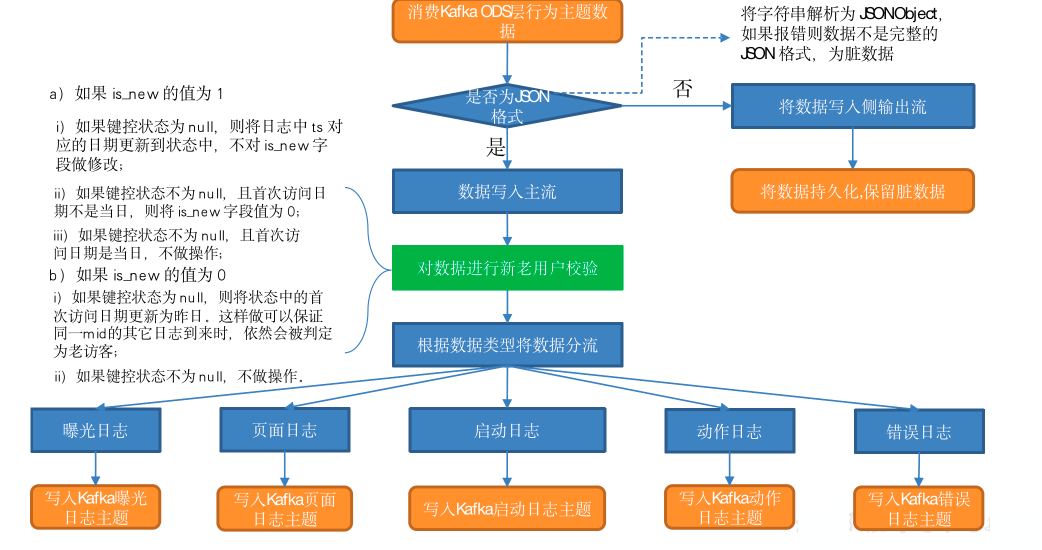
2)新老访客状态标记修复
日志数据 common 字段下的 is_new 字段是用来标记新老访客状态的,1 表示新访客,0 表示老访客。前端埋点采集到的数据可靠性无法保证,可能会出现老访客被标记为新访客的问题,因此需要对该标记进行修复。
本节将通过分流对日志数据进行拆分,生成五张事务事实表写入 Kafka:
- 流量域页面浏览事务事实表
- 流量域启动事务事实表
- 流量域动作事务事实表
- 流量域曝光事务事实表
- 流量域错误事务事实表
1)数据清洗(ETL)
对流中数据进行解析,将字符串转换为 JSONObject,如果解析报错则必然为脏数据。定义侧输出流,将脏数据发送到侧输出流,写入 Kafka 脏数据主题
2)新老访客状态标记修复
(1)前端埋点新老访客状态标记设置规则
以神策提供的第三方埋点服务中新老访客状态标记设置规则为例:
- Web 端:用户第一次访问埋入神策 SDK 页面的当天(即第一天),JS SDK 会在网页的 cookie 中设置一个首日访问的标记,并设置第一天 24 点之前,该标记为 true,即第一天触发的网页端所有事件中,is_new = 1。第一天之后,该标记则为 false,即第一天之后触发的网页端所有事件中,is_new = 0;
- 小程序端:用户第一天访问埋入神策 SDK 的页面时,小程序 SDK 会在 storage 缓存中创建一个首日为 true 的标记,并且设置第一天 24 点之前,该标记均为 true。即第一天触发的小程序端所有事件中,is_new = 1。第一天之后,该标记则为 false,即第一天之后触发的小程序端所有事件中,is_new = 0;
- APP 端:用户安装 App 后,第一次打开埋入神策 SDK 的 App 的当天,Android/iOS SDK 会在手机本地缓存内,创建一个首日为 true 的标记,并且设置第一天 24 点之前,该标记均为 true。即第一天触发的 APP 端所有事件中,is_new = 1。第一天之后,该标记则为 false,即第一天之后触发的 APP 端所有事件中,is_new = 0。
本项目模拟生成的是 APP 端日志数据。对于此类日志,如果首日之后用户清除了手机本地缓存中的标记,再次启动 APP 会重新设置一个首日为 true 的标记,导致本应为 0 的 is_new 字段被置为 1,可能会给相关指标带来误差。因此,有必要对新老访客状态标记进行修复。
(2)新老访客状态标记修复思路
运用 Flink 状态编程,为每个 mid 维护一个键控状态,记录首次访问日期。
-
如果 is_new 的值为 1:
a)如果键控状态为 null,认为本次是该访客首次访问 APP,将日志中 ts 对应的日期更新到状态中,不对 is_new 字段做修改;
b)如果键控状态不为 null,且首次访问日期不是当日,说明访问的是老访客,将 is_new 字段置为 0;
c)如果键控状态不为 null,且首次访问日期是当日,说明访问的是新访客,不做操作;
-
如果 is_new 的值为 0:
a)如果键控状态为 null,说明访问 APP 的是老访客但本次是该访客的页面日志首次进入程序。当前端新老访客状态标记丢失时,日志进入程序被判定为老访客,Flink 程序就可以纠正被误判的访客状态标记,只要将状态中的日期设置为今天之前即可。本程序选择将状态更新为昨日;
b)如果键控状态不为 null,说明程序已经维护了首次访问日期,不做操作。
3)利用侧输出流实现数据拆分
(1)埋点日志结构分析
前端埋点获取的 JSON 字符串(日志)可能存在 common、start、page、displays、actions、err、ts 七种字段。其中:
- common 对应的是公共信息,是所有日志都有的字段
- err 对应的是错误信息,所有日志都可能有的字段
- start 对应的是启动信息,启动日志才有的字段
- page 对应的是页面信息,页面日志才有的字段
- displays 对应的是曝光信息,曝光日志才有的字段,曝光日志可以归为页面日志,因此必然有 page 字段
- actions 对应的是动作信息,动作日志才有的字段,同样属于页面日志,必然有 page 字段。动作信息和曝光信息可以同时存在。
- ts 对应的是时间戳,单位:毫秒,所有日志都有的字段
综上,我们可以将前端埋点获取的日志分为两大类:启动日志和页面日志。二者都有 common 字段和 ts 字段,都可能有 err 字段。页面日志一定有 page 字段,一定没有 start 字段,可能有 displays 和 actions 字段;启动日志一定有 start 字段,一定没有 page、displays 和 actions 字段。
(2)分流日志分类
本节将按照内容,将日志分为以下五类:
- 启动日志
- 页面日志
- 曝光日志
- 动作日志
- 错误日志
(3)分流思路
- 所有日志数据都可能拥有 err 字段,所有首先获取 err 字段,如果返回值不为 null 则将整条日志数据发送到错误侧输出流。然后删掉 JSONObject 中的 err 字段及对应值;
- 判断是否有 start 字段,如果有则说明数据为启动日志,将其发送到启动侧输出流;如果没有则说明为页面日志,进行下一步;
- 页面日志必然有 page 字段、 common 字段和 ts 字段,获取它们的值,ts 封装为包装类 Long,其余两个字段的值封装为 JSONObject;
- 判断是否有 displays 字段,如果有,将其值封装为 JSONArray,遍历该数组,依次获取每个元素(记为 display),封装为JSONObject。创建一个空的 JSONObject,将 display、common、page和 ts 添加到该对象中,获得处理好的曝光数据,发送到曝光侧输出流。动作日志的处理与曝光日志相同(注意:一条页面日志可能既有曝光数据又有动作数据,二者没有任何关系,因此曝光数据不为 null 时仍要对动作数据进行处理);
- 动作日志和曝光日志处理结束后删除 displays 和 actions 字段,此时主流的 JSONObject 中只有 common 字段、 page 字段和 ts 字段,即为最终的页面日志。
处理结束后,页面日志数据位于主流,其余四种日志分别位于对应的侧输出流,将五条流的数据写入 Kafka 对应主题即可。
1)在 KafkaUtil 工具类中补充 getKafkaProducer() 方法
public static FlinkKafkaProducer<String> getFlinkKafkaProducer(String topic) { return new FlinkKafkaProducer<String>(KAFKA_SERVER, topic, new SimpleStringSchema()); public static FlinkKafkaProducer<String> getFlinkKafkaProducer(String topic, String defaultTopic) { Properties properties = new Properties(); properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_SERVER); return new FlinkKafkaProducer<String>(defaultTopic, new KafkaSerializationSchema<String>() { @Override public ProducerRecord<byte[], byte[]> serialize(String element, @Nullable Long timestamp) { if (element == null) { return new ProducerRecord<>(topic, "".getBytes()); return new ProducerRecord<>(topic, element.getBytes()); }, properties, FlinkKafkaProducer.Semantic.EXACTLY_ONCE);2)创建 DateFormatUtil 工具类用于日期格式化
public class DateFormatUtil { private static final DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd"); private static final DateTimeFormatter dtfFull = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); public static Long toTs(String dtStr, boolean isFull) { LocalDateTime localDateTime = null; if (!isFull) { dtStr = dtStr + " 00:00:00"; localDateTime = LocalDateTime.parse(dtStr, dtfFull); return localDateTime.toInstant(ZoneOffset.of("+8")).toEpochMilli(); public static Long toTs(String dtStr) { return toTs(dtStr, false); public static String toDate(Long ts) { Date dt = new Date(ts); LocalDateTime localDateTime = LocalDateTime.ofInstant(dt.toInstant(), ZoneId.systemDefault()); return dtf.format(localDateTime); public static String toYmdHms(Long ts) { Date dt = new Date(ts); LocalDateTime localDateTime = LocalDateTime.ofInstant(dt.toInstant(), ZoneId.systemDefault()); return dtfFull.format(localDateTime); public static void main( String[] args) { System.out.println(toYmdHms(System.currentTimeMillis())); // SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); // long time = sdf.parse("").getTime(); // String format = sdf.format(156456465L);3)主程序
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) public class BaseLogApp { public static void main(String[] args) throws Exception { //TODO 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //生产环境中设置为Kafka主题的分区数 //1.1 开启CheckPoint //env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE); //env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L); //env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L)); //1.2 设置状态后端 //env.setStateBackend(new HashMapStateBackend()); //env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck"); //System.setProperty("HADOOP_USER_NAME", "atguigu"); //TODO 2.消费Kafka topic_log 主题的数据创建流 String topic = "topic_log"; String groupId = "base_log_app_211126"; DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId)); //TODO 3.过滤掉非JSON格式的数据&将每行数据转换为JSON对象 OutputTag<String> dirtyTag = new OutputTag<String>("Dirty") { SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() { @Override public void processElement(String value, Context ctx, Collector<JSONObject> out) throws Exception { try { JSONObject jsonObject = JSON.parseObject(value); out.collect(jsonObject); } catch (Exception e) { ctx.output(dirtyTag, value); }); //获取侧输出流脏数据并打印 DataStream<String> dirtyDS = jsonObjDS.getSideOutput(dirtyTag); dirtyDS.print("Dirty>>>>>>>>>>>>"); //TODO 4.按照Mid分组(使用状态前必须进行一次keyBy) KeyedStream<JSONObject, String> keyedStream = jsonObjDS.keyBy(json -> json.getJSONObject("common").getString("mid")); //TODO 5.使用状态编程做新老访客标记校验 SingleOutputStreamOperator<JSONObject> jsonObjWithNewFlagDS = keyedStream.map(new RichMapFunction<JSONObject, JSONObject>() { private ValueState<String> lastVisitState; //记录首次访问时间 @Override public void open(Configuration parameters) throws Exception { lastVisitState = getRuntimeContext().getState(new ValueStateDescriptor<String>("last-visit", String.class)); @Override public JSONObject map(JSONObject value) throws Exception { //获取is_new标记 & ts 并将时间戳转换为年月日 String isNew = value.getJSONObject("common").getString("is_new"); Long ts = value.getLong("ts"); String curDate = DateFormatUtil.toDate(ts); //获取状态中的日期 String lastDate = lastVisitState.value(); //判断is_new标记是否为"1" if ("1".equals(isNew)) { if (lastDate == null) { lastVisitState.update(curDate); } else if (!lastDate.equals(curDate)) { value.getJSONObject("common").put("is_new", "0"); } else if (lastDate == null) { lastVisitState.update(DateFormatUtil.toDate(ts - 24 * 60 * 60 * 1000L)); return value; }); //TODO 6.使用侧输出流进行分流处理 页面日志放到主流 启动、曝光、动作、错误放到侧输出流 OutputTag<String> startTag = new OutputTag<String>("start") { OutputTag<String> displayTag = new OutputTag<String>("display") { OutputTag<String> actionTag = new OutputTag<String>("action") { OutputTag<String> errorTag = new OutputTag<String>("error") { SingleOutputStreamOperator<String> pageDS = jsonObjWithNewFlagDS.process(new ProcessFunction<JSONObject, String>() { @Override public void processElement(JSONObject value, Context ctx, Collector<String> out) throws Exception { //尝试获取错误信息 String err = value.getString("err"); if (err != null) { //将数据写到error侧输出流 ctx.output(errorTag, value.toJSONString()); //移除错误信息 value.remove("err"); //尝试获取启动信息 String start = value.getString("start"); if (start != null) { //将数据写到start侧输出流 ctx.output(startTag, value.toJSONString()); } else { //获取公共信息&页面id&时间戳 String common = value.getString("common"); String pageId = value.getJSONObject("page").getString("page_id"); Long ts = value.getLong("ts"); //尝试获取曝光数据 JSONArray displays = value.getJSONArray("displays"); if (displays != null && displays.size() > 0) { //遍历曝光数据&写到display侧输出流 for (int i = 0; i < displays.size(); i++) { JSONObject display = displays.getJSONObject(i); display.put("common", common); display.put("page_id", pageId); display.put("ts", ts); ctx.output(displayTag, display.toJSONString()); //尝试获取动作数据 JSONArray actions = value.getJSONArray("actions"); if (actions != null && actions.size() > 0) { //遍历曝光数据&写到display侧输出流 for (int i = 0; i < actions.size(); i++) { JSONObject action = actions.getJSONObject(i); action.put("common", common); action.put("page_id", pageId); ctx.output(actionTag, action.toJSONString()); //移除曝光和动作数据&写到页面日志主流 value.remove("displays"); value.remove("actions"); out.collect(value.toJSONString()); }); //TODO 7.提取各个侧输出流数据 DataStream<String> startDS = pageDS.getSideOutput(startTag); DataStream<String> displayDS = pageDS.getSideOutput(displayTag); DataStream<String> actionDS = pageDS.getSideOutput(actionTag); DataStream<String> errorDS = pageDS.getSideOutput(errorTag); //TODO 8.将数据打印并写入对应的主题 pageDS.print("Page>>>>>>>>>>"); startDS.print("Start>>>>>>>>"); displayDS.print("Display>>>>"); actionDS.print("Action>>>>>>"); errorDS.print("Error>>>>>>>>"); String page_topic = "dwd_traffic_page_log"; String start_topic = "dwd_traffic_start_log"; String display_topic = "dwd_traffic_display_log"; String action_topic = "dwd_traffic_action_log"; String error_topic = "dwd_traffic_error_log"; pageDS.addSink(MyKafkaUtil.getFlinkKafkaProducer(page_topic)); startDS.addSink(MyKafkaUtil.getFlinkKafkaProducer(start_topic)); displayDS.addSink(MyKafkaUtil.getFlinkKafkaProducer(display_topic)); actionDS.addSink(MyKafkaUtil.getFlinkKafkaProducer(action_topic)); errorDS.addSink(MyKafkaUtil.getFlinkKafkaProducer(error_topic)); //TODO 9.启动任务 env.execute("BaseLogApp");流量域独立访客事务事实表
过滤页面数据中的独立访客访问记录。
1)过滤 last_page_id不为 null的数据
独立访客数据对应的页面必然是会话起始页面,last_page_id 必为 null。过滤 last_page_id != null 的数据,减小数据量,提升计算效率。
2)筛选独立访客记录
运用 Flink 状态编程,为每个 mid 维护一个键控状态,记录末次登录日期。
如果末次登录日期为 null 或者不是今日,则本次访问是该 mid 当日首次访问,保留数据,将末次登录日期更新为当日。否则不是当日首次访问,丢弃数据。
3)状态存活时间设置
如果保留状态,第二日同一 mid 再次访问时会被判定为新访客,如果清空状态,判定结果相同,所以只要时钟进入第二日状态就可以清空。
设置状态的 TTL 为 1 天,更新模式为 OnCreateAndWrite,表示在创建和更新状态时重置状态存活时间。如:2022-02-21 08:00:00 首次访问,若 2022-02-22 没有访问记录,则 2022-02-22 08:00:00 之后状态清空。
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) //程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) -> DwdTrafficUniqueVisitorDetail -> Kafka(ZK) public class DwdTrafficUniqueVisitorDetail { public static void main(String[] args) throws Exception { //TODO 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //生产环境中设置为Kafka主题的分区数 //1.1 开启CheckPoint //env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE); //env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L); //env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L)); //1.2 设置状态后端 //env.setStateBackend(new HashMapStateBackend()); //env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck"); //System.setProperty("HADOOP_USER_NAME", "atguigu"); //TODO 2.读取Kafka 页面日志主题创建流 String topic = "dwd_traffic_page_log"; String groupId = "unique_visitor_detail_211126"; DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId)); //TODO 3.过滤掉上一跳页面不为null的数据并将每行数据转换为JSON对象 SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.flatMap(new FlatMapFunction<String, JSONObject>() { @Override public void flatMap(String value, Collector<JSONObject> out) throws Exception { try { JSONObject jsonObject = JSON.parseObject(value); //获取上一跳页面ID String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id"); if (lastPageId == null) { out.collect(jsonObject); } catch (Exception e) { e.printStackTrace(); System.out.println(value); }); //TODO 4.按照Mid分组 KeyedStream<JSONObject, String> keyedStream = jsonObjDS.keyBy(json -> json.getJSONObject("common").getString("mid")); //TODO 5.使用状态编程实现按照Mid的去重 SingleOutputStreamOperator<JSONObject> uvDS = keyedStream.filter(new RichFilterFunction<JSONObject>() { private ValueState<String> lastVisitState; @Override public void open(Configuration parameters) throws Exception { ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("last-visit", String.class); //设置状态的TTL StateTtlConfig ttlConfig = new StateTtlConfig.Builder(Time.days(1)) .setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite ) .build(); stateDescriptor.enableTimeToLive(ttlConfig); lastVisitState = getRuntimeContext().getState(stateDescriptor); @Override public boolean filter(JSONObject value) throws Exception { //获取状态数据&当前数据中的时间戳并转换为日期 String lastDate = lastVisitState.value(); Long ts = value.getLong("ts"); String curDate = DateFormatUtil.toDate(ts); if (lastDate == null || !lastDate.equals(curDate)) { lastVisitState.update(curDate); return true; } else { return false; }); //TODO 6.将数据写到Kafka String targetTopic = "dwd_traffic_unique_visitor_detail"; uvDS.print(">>>>>>>>"); uvDS.map(JSONAware::toJSONString) .addSink(MyKafkaUtil.getFlinkKafkaProducer(targetTopic)); //TODO 7.启动任务 env.execute("DwdTrafficUniqueVisitorDetail");流量域用户跳出事务事实表
过滤用户跳出明细数据。
跳出说明:一次会话中只访问过一个页面。
1)筛选策略
跳出是指会话中只有一个页面的访问行为,如果能获取会话的所有页面,只要筛选页面数为 1 的会话即可获取跳出明细数据。
(1)离线数仓中我们可以获取一整天的数据,结合访问时间、page_id 和 last_page_id 字段对整体数据集做处理可以按照会话对页面日志进行划分,从而获得每个会话的页面数,只要筛选页面数为 1 的会话即可提取跳出明细数据;
(2)实时计算中无法考虑整体数据集,很难按照会话对页面访问记录进行划分。而本项目模拟生成的日志数据中没有 session_id(会话id)字段,也无法通过按照 session_id 分组的方式计算每个会话的页面数。
(3)因此,我们需要换一种解决思路。如果能判定首页日志之后没有同一会话的页面访问记录同样可以筛选跳出数据。如果日志数据完全有序,会话页面不存在交叉情况,则跳出页面的判定可以分为三种情况:
- 两条紧邻的首页日志进入算子,可以判定第一条首页日志所属会话为跳出会话;
- 第一条首页日志进入算子后,接收到的第二条日志为非首页日志,则第一条日志所属会话不是跳出会话;
- 第一条首页日志进入算子后,没有收到第二条日志,此时无法得出结论,必须继续等待。但是无休止地等待显然是不现实的。因此,人为设定超时时间,超时时间内没有第二条数据就判定为跳出行为,这是一种近似处理,存在误差,但若能结合业务场景设置合理的超时时间,误差是可以接受的。本程序为了便于测试,设置超时时间为 10s,为了更快看到效果可以设置更小的超时时间,生产环境的设置结合业务需求确定。
2)思路分析
-
思路一:会话窗口
统计窗口中的数据条数,如果为1,则输出,反之丢弃,将窗口中的所有数据按照时间排序,挨个对比。
缺点:连续两个为null就没法处理
-
思路二:状态编程
遇到last_page为null,取出状态数据
- 状态=null 定时器+将自身写入状态
- 状态!=null 输出状态+将自身写入状态
缺点:没法处理乱序问题
-
思路三:CEP(状态编程+within开窗)
3)知识储备
(1)Flink CEP
跳出行为需要考虑会话中的两条页面日志数据(第一条为首页日志且超时时间内没有接收到第二条,或两条紧邻的首页日志到来可以判定第一条为跳出数据),要筛选的是组合事件,用 filter 无法实现这样的功能,由此引出 Flink CEP。
Flink CEP(Complex Event Processing 复杂事件处理)是在Flink上层实现的复杂事件处理库,可以在无界流中检测出特定的事件模型。用户定义复杂规则(Pattern),将其应用到流上,即可从流中提取满足 Pattern 的一个或多个简单事件构成的复杂事件。
(2)Flink CEP 定义的规则之间的连续策略
- 严格连续: 期望所有匹配的事件严格的一个接一个出现,中间没有任何不匹配的事件。对应方法为 next();
- 松散连续: 忽略匹配的事件之间的不匹配的事件。对应方法为followedBy();
- 不确定的松散连续: 更进一步的松散连续,允许忽略掉一些匹配事件的附加匹配。对应方法为followedByAny()。
(3)WaterMark可以结合开窗处理乱序数据,表示小于WaterMark数据已经到齐!
- 本质:流当中传输的一条特殊的数据,一个时间戳
- 作用:处理乱序数据
- 作用机制:通过延迟关窗
- 传递:
- 广播方式传输,与Key无关
- 当前任务中WaterMark取决于上游最小的WaterMark值
- Watermark是单调递增的,只有Watermark比上次的大,才会向下游传输
4)实现步骤
(1)按照 mid 分组
不同访客的浏览记录互不干涉,跳出行为的分析应在相同 mid 下进行,首先按照 mid 分组。
(2)定义 CEP 匹配规则
- 规则一:跳出行为对应的页面日志必然为某一会话的首页,因此第一个规则判定 last_page_id 是否为 null,是则返回 true,否则返回 false;
- 规则二:规则二和规则一之间的策略采用严格连续,要求二者之间不能有其它事件。判断 last_page_id 是否为 null,在数据完整有序的前提下,如果不是 null 说明本条日志的页面不是首页,可以断定它与规则一匹配到的事件同属于一个会话,返回 false;如果是 null 则开启了一个新的会话,此时可以判定上一条页面日志所属会话为跳出会话,是我们需要的数据,返回 true;
- 超时时间:超时时间内规则一被满足,未等到第二条数据则会被判定为超时数据。
(3)把匹配规则(Pattern)应用到流上
根据 Pattern 定义的规则对流中数据进行筛选。
(4)提取超时流
提取超时流,超时流中满足规则一的数据即为跳出明细数据,取出。
(5)合并主流和超时流,写入 Kafka 调出明细主题
(6)结果分析
理论上 Flink 可以通过设置水位线保证数据严格有序(超时时间足够大),在此前提下,同一 mid 的会话之间不会出现交叉。若假设日志数据没有丢失,按照上述匹配规则,我们可以获得两类明细数据:
- 两个规则都被满足,满足规则一的数据为跳出明细数据。在会话之间不会交叉且日志数据没有丢失的前提下,此时获取的跳出明细数据没有误差;
- 第一条数据满足规则二,超时时间内没有接收到第二条数据,水位线达到超时时间,第一条数据被发送到超时侧输出流。即便在会话之间不交叉且日志数据不丢失的前提下,此时获取的跳出明细数据仍有误差,因为超时时间之后会话可能并未结束,如果此时访客在同一会话内跳转到了其它页面,就会导致会话页面数大于 1 的访问被判定为跳出行为,下游计算的跳出率偏大。误差大小和设置的超时时间呈负相关关系,超时时间越大,理论上误差越小。
1)添加CEP相关依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-cep_${scala.version}</artifactId> version>${flink.version}</version> </dependency>2)主程序
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) //程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) -> DwdTrafficUserJumpDetail -> Kafka(ZK) public class DwdTrafficUserJumpDetail { public static void main(String[] args) throws Exception { //TODO 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //生产环境中设置为Kafka主题的分区数 //1.1 开启CheckPoint //env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE); //env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L); //env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L)); //1.2 设置状态后端 //env.setStateBackend(new HashMapStateBackend()); //env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck"); //System.setProperty("HADOOP_USER_NAME", "atguigu"); //TODO 2.读取Kafka 页面日志主题数据创建流 String topic = "dwd_traffic_page_log"; String groupId = "user_jump_detail_1126"; DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getFlinkKafkaConsumer(topic, groupId)); //TODO 3.将每行数据转换为JSON对象 SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject); //TODO 4.提取事件时间&按照Mid分组 KeyedStream<JSONObject, String> keyedStream = jsonObjDS .assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() { @Override public long extractTimestamp(JSONObject element, long recordTimestamp) { return element.getLong("ts"); })) .keyBy(json -> json.getJSONObject("common").getString("mid")); //TODO 5.定义CEP的模式序列 Pattern<JSONObject, JSONObject> pattern = Pattern.<JSONObject> begin("start").where(new SimpleCondition<JSONObject>() { @Override public boolean filter(JSONObject value) throws Exception { return value.getJSONObject("page").getString("last_page_id") == null; }).next("next").where(new SimpleCondition<JSONObject>() { @Override public boolean filter(JSONObject value) throws Exception { return value.getJSONObject("page").getString("last_page_id") == null; }).within(Time.seconds(10)); // Pattern.<JSONObject>begin("start").where(new SimpleCondition<JSONObject>() { // @Override // public boolean filter(JSONObject value) throws Exception { // return value.getJSONObject("page").getString("last_page_id") == null; // } // }) // .times(2) //默认是宽松近邻 followedBy // .consecutive() //严格近邻 next // .within(Time.seconds(10)); //TODO 6.将模式序列作用到流上 PatternStream<JSONObject> patternStream = CEP.pattern(keyedStream, pattern); //TODO 7.提取事件(匹配上的事件以及超时事件) OutputTag<String> timeOutTag = new OutputTag<String>("timeOut") { SingleOutputStreamOperator<String> selectDS = patternStream.select(timeOutTag,new PatternTimeoutFunction<JSONObject, String>() { @Override public String timeout(Map<String, List<JSONObject>> map, long l) throws Exception { return map.get("start").get(0).toJSONString(); }, new PatternSelectFunction<JSONObject, String>() { @Override public String select(Map<String, List<JSONObject>> map) throws Exception { return map.get("start").get(0).toJSONString(); }); DataStream<String> timeOutDS = selectDS.getSideOutput(timeOutTag); //TODO 8.合并两个种事件 DataStream<String> unionDS = selectDS.union(timeOutDS); //TODO 9.将数据写出到Kafka selectDS.print("Select>>>>>>>"); timeOutDS.print("TimeOut>>>>>"); String targetTopic = "dwd_traffic_user_jump_detail"; unionDS.addSink(MyKafkaUtil.getFlinkKafkaProducer(targetTopic)); //TODO 10.启动任务 env.execute("DwdTrafficUserJumpDetail");Join方式介绍(附)
(1)DataStream方式
public class Flink04_DataStreamJoinTest { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //1001,23.6,1324 SingleOutputStreamOperator<WaterSensor> waterSensorDS1 = env.socketTextStream("hadoop102", 8888) .assignTimestampsAndWatermarks(WatermarkStrategy.<String>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<String>() { @Override public long extractTimestamp(String element, long recordTimestamp) { String[] split = element.split(","); return new Long(split[2]) * 1000L; })).map( line -> { String[] split = line.split(","); return new WaterSensor(split[0], Double.parseDouble(split[1]), Long.parseLong(split[2])); }); SingleOutputStreamOperator<WaterSensor2> waterSensorDS2 = env.socketTextStream("hadoop102", 9999) .assignTimestampsAndWatermarks(WatermarkStrategy.<String>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<String>() { @Override public long extractTimestamp(String element, long recordTimestamp) { String[] split = element.split(","); return new Long(split[2]) * 1000L; })).map(line -> { String[] split = line.split(","); return new WaterSensor2(split[0], split[1], Long.parseLong(split[2])); }); //JOIN SingleOutputStreamOperator<Tuple2<WaterSensor, WaterSensor2>> result = waterSensorDS1.keyBy(WaterSensor::getId) .intervalJoin(waterSensorDS2.keyBy(WaterSensor2::getId)) .between(Time.seconds(-5), Time.seconds(5)) .process(new ProcessJoinFunction<WaterSensor, WaterSensor2, Tuple2<WaterSensor, WaterSensor2>>() { @Override public void processElement(WaterSensor left, WaterSensor2 right, Context ctx, Collector<Tuple2<WaterSensor, WaterSensor2>> out) throws Exception { out.collect(new Tuple2<>(left, right)); }); result.print(">>>>>>>>>>>>"); env.execute();这种方式的缺点是只有inner join。
(2)SQL方式
public class Flink05_SQL_JoinTest { public static void main(String[] args) { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); System.out.println(tableEnv.getConfig().getIdleStateRetention()); tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(10)); //1001,23.6,1324 SingleOutputStreamOperator<WaterSensor> waterSensorDS1 = env.socketTextStream("hadoop102", 8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0], Double.parseDouble(split[1]), Long.parseLong(split[2])); }); SingleOutputStreamOperator<WaterSensor2> waterSensorDS2 = env.socketTextStream("hadoop102", 9999) .map(line -> { String [] split = line.split(","); return new WaterSensor2(split[0], split[1], Long.parseLong(split[2])); }); //将流转换为动态表 tableEnv.createTemporaryView("t1", waterSensorDS1); tableEnv.createTemporaryView("t2", waterSensorDS2); //FlinkSQLJOIN //inner join 左表:OnCreateAndWrite 右表:OnCreateAndWrite //tableEnv.sqlQuery("select t1.id,t1.vc,t2.id,t2.name from t1 join t2 on t1.id=t2.id") // .execute() // .print(); //left join 左表:OnReadAndWrite 右表:OnCreateAndWrite //tableEnv.sqlQuery("select t1.id,t1.vc,t2.id,t2.name from t1 left join t2 on t1.id=t2.id") // .execute() // .print(); //right join 左表:OnCreateAndWrite 右表:OnReadAndWrite //tableEnv.sqlQuery("select t1.id,t1.vc,t2.id,t2.name from t1 right join t2 on t1.id=t2.id") // .execute() // .print(); //full join 左表:OnReadAndWrite 右表:OnReadAndWrite tableEnv.sqlQuery("select t1.id,t1.vc,t2.id,t2.name from t1 full join t2 on t1.id=t2.id") .execute() .print();这种方式要记得设置空闲状态保存时间,不然会状态爆炸。
(3)LookUp Join方式
public class Flink06_LookUp_JoinTest { public static void main(String[] args) { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); //查询MySQL构建LookUp表 tableEnv.executeSql("" + "create TEMPORARY table base_dic( " + " `dic_code` String, " + " `dic_name` String, " + " `parent_code` String, " + " `create_time` String, " + " `operate_time` String " + ") WITH ( " + " 'connector' = 'jdbc', " + " 'url' = 'jdbc:mysql://hadoop102:3306/gmall-211126-flink', " + " 'table-name' = 'base_dic', " + " 'driver' = 'com.mysql.cj.jdbc.Driver', " + " 'lookup.cache.max-rows' = '10', " + //维表数据不变or会改变,但是数据的准确度要求不高 " 'lookup.cache.ttl' = '1 hour', " + " 'username' = 'root', " + " 'password' = '000000' " + ")"); //打印LookUp表 // tableEnv.sqlQuery("select * from base_dic") // .execute() // .print(); //构建事实表 SingleOutputStreamOperator<WaterSensor> waterSensorDS = env.socketTextStream("hadoop102", 8888) .map(line -> { String[] split = line.split(","); return new WaterSensor(split[0], Double.parseDouble(split[1]), Long.parseLong(split[2])); }); Table table = tableEnv.fromDataStream(waterSensorDS, $("id"), $("vc"), $("ts"), $("pt").proctime()); tableEnv.createTemporaryView("t1", table); //使用事实表关联维表并打印结果 tableEnv.sqlQuery("" + "select " + " t1.id, " + " t1.vc, " + " dic.dic_name " + "from t1 " + "join base_dic FOR SYSTEM_TIME AS OF t1.pt as dic " + "on t1.id=dic.dic_code") .execute().print();交易域加购事务事实表
提取加购操作生成加购表,并将字典表中的相关维度退化到加购表中,写出到 Kafka 对应主题。
1)维度关联(维度退化)实现策略分析
本章业务事实表的构建全部使用 FlinkSQL 实现,字典表数据存储在 MySQL 的业务数据库中,要做维度退化,就要将这些数据从 MySQL 中提取出来封装成 FlinkSQL 表,Flink 的 JDBC SQL Connector 可以实现我们的需求。
2)知识储备
(1)JDBC SQL Connector
JDBC 连接器可以让 Flink 程序从拥有 JDBC 驱动的任意关系型数据库中读取数据或将数据写入数据库。
如果在 Flink SQL 表的 DDL 语句中定义了主键,则会以 upsert 模式将流中数据写入数据库,此时流中可以存在 UPDATE/DElETE(更新/删除)类型的数据。否则,会以 append 模式将数据写出到数据库,此时流中只能有 INSERT(插入)类型的数据。
DDL 用法实例如下。
CREATE TABLE MyUserTable ( id BIGINT, name STRING, age INT, status BOOLEAN, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://localhost:3306/mydatabase', 'table-name' = 'users'JDBC SQL Connector 参数解读:
-
connector:连接器类型,此处为 jdbc
-
url:数据库 url
-
table-name:数据库中表名
-
lookup.cache.max-rows:lookup 缓存中的最大记录条数
-
lookup.cache.ttl:lookup 缓存中每条记录的最大存活时间
-
username:访问数据库的用户名
-
password:访问数据库的密码
-
driver:数据库驱动,注意:通常注册驱动可以省略,但是自动获取的驱动是 com.mysql.jdbc.Driver,Flink CDC 2.1.0 要求 mysql 驱动版本必须为 8 及以上,在 mysql-connector -8.x 中该驱动已过时,新的驱动为 com.mysql.cj.jdbc.Driver。省略该参数控制台打印的警告如下
-
connector:连接器类型,此处为 jdbc
-
url:数据库 url
-
table-name:数据库中表名
-
lookup.cache.max-rows:lookup 缓存中的最大记录条数
-
lookup.cache.ttl:lookup 缓存中每条记录的最大存活时间
-
username:访问数据库的用户名
-
password:访问数据库的密码
-
driver:数据库驱动,注意:通常注册驱动可以省略,但是自动获取的驱动是 com.mysql.jdbc.Driver,Flink CDC 2.1.0 要求 mysql 驱动版本必须为 8 及以上,在 mysql-connector -8.x 中该驱动已过时,新的驱动为 com.mysql.cj.jdbc.Driver。省略该参数控制台打印的警告如下:
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.(2)Lookup Cache
JDBC 连接器可以作为时态表关联中的查询数据源(又称维表)。目前,仅支持同步查询模式。
默认情况下,查询缓存(Lookup Cache)未被启用,需要设置 lookup.cache.max-rows 和 lookup.cache.ttl 参数来启用此功能。
Lookup 缓存是用来提升有 JDBC 连接器参与的时态关联性能的。默认情况下,缓存未启用,所有的请求会被发送到外部数据库。当缓存启用时,每个进程(即 TaskManager)维护一份缓存。收到请求时,Flink 会先查询缓存,如果缓存未命中才会向外部数据库发送请求,并用查询结果更新缓存。如果缓存中的记录条数达到了 lookup.cache.max-rows 规定的最大行数时将清除存活时间最久的记录。如果缓存中的记录存活时间超过了 lookup.cache.ttl 规定的最大存活时间,同样会被清除。
缓存中的记录未必是最新的,可以将 lookup.cache.ttl 设置为一个更小的值来获得时效性更好的数据,但这样做会增加发送到数据库的请求数量。所以需要在吞吐量和正确性之间寻求平衡。
(3)Lookup Join
Lookup Join 通常在 Flink SQL 表和外部系统查询结果关联时使用。这种关联要求一张表(主表)有处理时间字段,而另一张表(维表)由 Lookup 连接器生成。
Lookup Join 做的是维度关联,而维度数据是有时效性的,那么我们就需要一个时间字段来对数据的版本进行标识。因此,Flink 要求我们提供处理时间用作版本字段。
此处选择调用 PROCTIME() 函数获取系统时间,将其作为处理时间字段。该函数调用示例如下:
tableEnv. sqlQuery("select PROCTIME() proc_time") .execute() .print(); // 结果 +----+-------------------------+ | op | proc_time | +----+-------------------------+ | +I | 2022-04-09 15:45:50.752 | +----+-------------------------+ 1 row in set(4)Kafka Connector
本节需要从 Kafka 读取数据封装为 Flink SQL 表,并将 Flink SQL 表的数据写入 Kafka,而整个过程的数据操作类型均为 INSERT,使用 Kafka Connector 即可。
Kafka Connector 参数如下:
-
connector:指定使用的连接器,对于 Kafka,只用 ‘kafka’
-
topic:主题
-
properties.bootstrap.servers:以逗号分隔的 Kafka broker 列表。注意:可以通过
-
properties.* 的方式指定配置项,*的位置用 Kafka 官方规定的配置项的 key 替代。并不是所有的配置都可以通过这种方式配置,因为 Flink 可能会将它们覆盖,如:‘key.deserializer’ 和 ‘value.deserializer’
-
properties.group.id:消费者组 ID
-
format:指定 Kafka 消息中 value 部分的序列化的反序列化方式,‘format’ 和 ‘value.format’ 二者必有其一
-
scan.startup.mode:Kafka 消费者启动模式,有四种取值
- ‘earliest-offset’:从偏移量最早的位置开始读取数据
- ‘latest-offset’:从偏移量最新的位置开始读取数据
- ‘group-offsets’:从 Zookeeper/Kafka broker 中维护的消费者组偏移量开始读取数据
- ‘timestamp’:从用户为每个分区提供的时间戳开始读取数据
- ‘specific-offsets’:从用户为每个分区提供的偏移量开始读取数据
默认值为 group-offsets。要注意:latest-offset 与 Kafka 官方提供的配置项 latest 不同, Flink 会将偏移量置为最新位置,覆盖掉 Zookeeper 或 Kafka 中维护的偏移量。与官方提供的 latest 相对应的是此处的 group-offsets。
3)执行步骤
(1)设置表状态的 ttl。
ttl(time-to-live)即存活时间。表之间做普通关联时,底层会将两张表的数据维护到状态中,默认情况下状态永远不会清空,这样会对内存造成极大的压力。表状态的 ttl 是 Idle(空闲,即状态未被更新)状态被保留的最短时间,假设 ttl 为 10s,若状态中的数据在 10s 内未被更新,则未来的某个时间会被清除(故而 ttl 是最短存活时间)。ttl 默认值为 0,表示永远不会清空状态。
字典表是作为维度表被 Flink 程序维护的,字典表与加购表不存在业务上的滞后关系,而 look up join 是由主表触发的,即主表数据到来后去 look up 表中查询对应的维度信息,如果缓存未命中就要从外部介质中获取数据,这就要求主表数据在状态中等待一段时间,此处将 ttl 设置为 5s,主表数据会在状态中保存至少 5s。而 look up 表的 cache 是由建表时指定的相关参数决定的,与此处的 ttl 无关。
(2)读取购物车表数据。
(3)建立 Mysql-LookUp 字典表。
(4)关联购物车表和字典表,维度退化。
1)补充 Flink SQL相关依赖
要执行 Flink SQL 程序,补充相关依赖。JDBC SQL Connector 需要的依赖包含在 Flink CDC 需要的依赖中,不可重复引入。
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_${scala.version}</artifactId> <version>${flink.version}</version> </dependency>2)在 KafkaUtil 中补充 getKafkaDDL 方法和 getKafkaSinkDDL 方法
* Kafka-Source DDL 语句 * @param topic 数据源主题 * @param groupId 消费者组 * @return 拼接好的 Kafka 数据源 DDL 语句 public static String getKafkaDDL(String topic, String groupId) { return " with ('connector' = 'kafka', " + " 'topic' = '" + topic + "'," + " 'properties.bootstrap.servers' = '" + KAFKA_SERVER + "', " + " 'properties.group.id' = '" + groupId + "', " + " 'format' = 'json', " + " 'scan.startup.mode' = 'group-offsets')"; * Kafka-Sink DDL 语句 * @param topic 输出到 Kafka 的目标主题 * @return 拼接好的 Kafka-Sink DDL 语句 public static String getKafkaSinkDDL(String topic) { return " WITH ( " + " 'connector' = 'kafka', " + " 'topic' = '" + topic + "', " + " 'properties.bootstrap.servers' = '" + KAFKA_SERVER + "', " + " 'format' = 'json' " + ")";3)创建 MysqlUtil 工具类
封装 mysqlLookUpTableDDL() 方法和 getBaesDicLookUpDDL() 方法,用于将 MySQL 数据库中的字典表读取为 Flink LookUp 表,以便维度退化。
public class MysqlUtil { public static String getBaseDicLookUpDDL() { return "create table `base_dic`( " + "`dic_code` string, " + "`dic_name` string, " + "`parent_code` string, " + "`create_time` timestamp, " + "`operate_time` timestamp, " + "primary key(`dic_code`) not enforced " + ")" + MysqlUtil.mysqlLookUpTableDDL("base_dic"); public static String mysqlLookUpTableDDL(String tableName) { return " WITH ( " + "'connector' = 'jdbc', " + "'url' = 'jdbc:mysql://hadoop102:3306/gmall-211126-flink', " + "'table-name' = '" + tableName + "', " + "'lookup.cache.max-rows' = '10', " + "'lookup.cache.ttl' = '1 hour', " + "'username' = 'root', " + "'password' = '000000', " + "'driver' = 'com.mysql.cj.jdbc.Driver' " + ")";3)主程序
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeCartAdd -> Kafka(ZK) public class DwdTradeCartAdd { public static void main(String[] args) throws Exception { //TODO 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //生产环境中设置为Kafka主题的分区数 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); //1.1 开启CheckPoint //env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE); //env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L); //env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L)); //1.2 设置状态后端 //env.setStateBackend(new HashMapStateBackend()); //env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck"); //System.setProperty("HADOOP_USER_NAME", "atguigu"); //TODO 2.使用DDL方式读取 topic_db 主题的数据创建表 tableEnv.executeSql(MyKafkaUtil.getTopicDb("cart_add_211126")); //TODO 3.过滤出加购数据 Table cartAddTable = tableEnv.sqlQuery("" + "select " + " `data`['id'] id, " + " `data`['user_id'] user_id, " + " `data`['sku_id'] sku_id, " + " `data`['cart_price'] cart_price, " + " if(`type`='insert',`data`['sku_num'],cast(cast(`data`['sku_num'] as int) - cast(`old`['sku_num'] as int) as string)) sku_num, " + " `data`['sku_name'] sku_name, " + " `data`['is_checked'] is_checked, " + " `data`['create_time'] create_time, " + " `data`['operate_time'] operate_time, " + " `data`['is_ordered'] is_ordered, " + " `data`['order_time'] order_time, " + " `data`['source_type'] source_type, " + " `data`['source_id'] source_id, " + " pt " + "from topic_db " + "where `database` = 'gmall-211126-flink' " + "and `table` = 'cart_info' " + "and (`type` = 'insert' " + "or (`type` = 'update' " + " and " + " `old`['sku_num'] is not null " + " and " + " cast(`data`['sku_num'] as int) > cast(`old`['sku_num'] as int)))"); tableEnv.createTemporaryView( "cart_info_table", cartAddTable); //将加购表转换为流并打印测试 //tableEnv.toAppendStream(cartAddTable, Row.class).print(">>>>>>"); //TODO 4.读取MySQL的 base_dic 表作为LookUp表 tableEnv.executeSql(MysqlUtil.getBaseDicLookUpDDL()); //TODO 5.关联两张表 Table cartAddWithDicTable = tableEnv.sqlQuery("" + "select " + " ci.id, " + " ci.user_id, " + " ci.sku_id, " + " ci.cart_price, " + " ci.sku_num, " + " ci.sku_name, " + " ci.is_checked, " + " ci.create_time, " + " ci.operate_time, " + " ci.is_ordered, " + " ci.order_time, " + " ci.source_type source_type_id, " + " dic.dic_name source_type_name, " + " ci.source_id " + "from cart_info_table ci " + "join base_dic FOR SYSTEM_TIME AS OF ci.pt as dic " + "on ci.source_type = dic.dic_code"); tableEnv.createTemporaryView("cart_add_dic_table", cartAddWithDicTable); //TODO 6.使用DDL方式创建加购事实表 tableEnv.executeSql("" + "create table dwd_cart_add( " + " `id` STRING, " + " `user_id` STRING, " + " `sku_id` STRING, " + " `cart_price` STRING, " + " `sku_num` STRING, " + " `sku_name` STRING, " + " `is_checked` STRING, " + " `create_time` STRING, " + " `operate_time` STRING, " + " `is_ordered` STRING, " + " `order_time` STRING, " + " `source_type_id` STRING, " + " `source_type_name` STRING, " + " `source_id` STRING " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_trade_cart_add")); //TODO 7.将数据写出 //tableEnv.executeSql("insert into dwd_cart_add select * from " + cartAddWithDicTable); tableEnv.executeSql("insert into dwd_cart_add select * from cart_add_dic_table"); //.print(); //TODO 8.启动任务 env.execute("DwdTradeCartAdd");交易域订单预处理表(※)
经过分析,订单明细表和取消订单明细表的数据来源、表结构都相同,差别只在业务过程和过滤条件,为了减少重复计算,将两张表公共的关联过程提取出来,形成订单预处理表。
关联订单明细表、订单表、订单明细活动关联表、订单明细优惠券关联表四张事实业务表和字典表(维度业务表)形成订单预处理表,写入 Kafka 对应主题。
本节形成的预处理表中要保留订单表的 type 和 old 字段,用于过滤订单明细数据和取消订单明细数据。
1)知识储备
(1)left join 实现过程
假设 A 表作为主表与 B 表做等值左外联。当 A 表数据进入算子,而 B 表数据未至时会先生成一条 B 表字段均为 null 的关联数据ab1,其标记为 +I。其后,B 表数据到来,会先将之前的数据撤回,即生成一条与 ab1 内容相同,但标记为 -D 的数据,再生成一条关联后的数据,标记为 +I。这样生成的动态表对应的流称之为回撤流。
(2)Kafka SQL Connector
Kafka SQL Connector 分为 Kafka SQL Connector 和 Upsert Kafka SQL Connector
Upsert Kafka Connector支持以 upsert 方式从 Kafka topic 中读写数据
Kafka Connector支持从 Kafka topic 中读写数据
-
建表语句的主键
Kafka Connector 要求表不能有主键,如果设置了主键,报错信息如下
Caused by: org.apache.flink.table.api.ValidationException: The Kafka table 'default_catalog.default_database.normal_sink_topic' with 'json' format doesn't support defining PRIMARY KEY constraint on the table, because it can't guarantee the semantic of primary key.而 Upsert Kafka Connector 要求表必须有主键,如果没有设置主键,报错信息如下
Caused by: org.apache.flink.table.api.ValidationException: 'upsert-kafka' tables require to define a PRIMARY KEY constraint. The PRIMARY KEY specifies which columns should be read from or write to the Kafka message key. The PRIMARY KEY also defines records in the 'upsert-kafka' table should update or delete on which keys.语法: primary key(id) not enforced
注意:not enforced 表示不对来往数据做约束校验,Flink 并不是数据的主人,因此只支持 not enforced 模式
如果没有 not enforced,报错信息如下:
Exception in thread "main" org.apache.flink.table.api.ValidationException: Flink doesn't support ENFORCED mode for PRIMARY KEY constaint. ENFORCED/NOT ENFORCED controls if the constraint checks are performed on the incoming/outgoing data. Flink does not own the data therefore the only supported mode is the NOT ENFORCED mode -
对表中数据操作类型的要求
Kafka Connector 不能消费带有 Upsert/Delete 操作类型数据的表,如 left join 生成的动态表。如果对这类表进行消费,报错信息如下
Exception in thread "main" org.apache.flink.table.api.TableException: Table sink 'default_catalog.default_database.normal_sink_topic' doesn't support consuming update and delete changes which is produced by node TableSourceScan(table=[[default_catalog, default_database, Unregistered_DataStream_Source_9]], fields=[l_id, tag_left, tag_right])Upsert Kafka Connector 将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。Flink 将根据主键列的值对数据进行分区,因此同一主键的更新/删除消息将落在同一分区,从而保证同一主键的消息有序。
③ left join 结合 Upsert Kafka Connector 使用范例
说明:Kafka 并行度为 4
-
表结构
left表 id tag A left B left C left right 表 id tag A right B right C right -
查询语句
select l.id l_id, l.tag l_tag, r.tag r_tag from left l left join right r on l.id = r.id -
关联结果写入到 Upsert Kafka 表,消费 Kafka 对应主题数据结果展示
{"l_id":"A","tag_left":"left","tag_right":null} {"l_id":"A","tag_left":"left","tag_right":"right"} {"l_id":"C","tag_left":"left","tag_right":null} {"l_id":"C","tag_left":"left","tag_right":"right"} {"l_id":"B","tag_left":"left","tag_right":null} {"l_id":"B","tag_left":"left","tag_right":"right"}④ 参数解读
本节需要用到 Kafka 连接器的明细表数据来源于 topic_db 主题,于 Kafka 而言,该主题的数据的操作类型均为 INSERT,所以读取数据使用 Kafka Connector 即可。而由于 left join 的存在,流中存在修改数据,所以写出数据使用 Upsert Kafka Connector。
Upsert Kafka Connector 参数:
- connector:指定使用的连接器,对于 Upsert Kafka,使用 ‘upsert-kafka’
- topic:主题
- properties.bootstrap.servers:以逗号分隔的 Kafka broker 列表
- key.format:key 的序列化和反序列化格式
- value.format:value 的序列化和反序列化格式
2)执行步骤
预处理表与订单明细事务事实表的区别只在于前者不会对订单数据进行筛选,且在表中增加了 type 和 old 字段。二者的粒度、聚合逻辑都相同,因此按照订单明细表的思路对预处理表进行分析即可。
(1)设置 ttl;
订单明细表、订单表、订单明细优惠券管理表和订单明细活动关联表不存在业务上的滞后问题,只考虑可能的数据乱序即可,此处将 ttl 设置为 5s。
要注意:前文提到,本项目保证了同一分区、同一并行度的数据有序。此处的乱序与之并不冲突,以下单业务过程为例,用户完成下单操作时,订单表中会插入一条数据,订单明细表中会插入与之对应的多条数据,本项目业务数据是按照主键分区进入 Kafka 的,虽然同分区数据有序,但是同一张业务表的数据可能进入多个分区,会乱序。这样一来,订单表数据与对应的订单明细数据可能被属于其它订单的数据“插队”,因而导致主表或从表数据迟到,可能 join 不上,为了应对这种情况,设置乱序程度,让状态中的数据等待一段时间。
(2)从 Kafka topic_db 主题读取业务数据;
这一步要调用 PROCTIME() 函数获取系统时间作为与字典表做 Lookup Join 的处理时间字段。
(3)筛选订单明细表数据;
应尽可能保证事实表的粒度为最细粒度,在下单业务过程中,最细粒度的事件为一个订单的一个 SKU 的下单操作,订单明细表的粒度与最细粒度相同,将其作为主表。
(4)筛选订单表数据;
通过该表获取 user_id 和 province_id。保留 type 字段和 old 字段用于筛选订单明细数据和取消订单明细数据。
(5)筛选订单明细活动关联表数据;
通过该表获取活动 id 和活动规则 id。
(6)筛选订单明细优惠券关联表数据;
通过该表获取优惠券 id。
(7)建立 MySQL-Lookup 字典表;
通过字典表获取订单来源类型名称。
(8)关联上述五张表获得订单宽表,写入 Kafka 主题
事实表的粒度应为最细粒度,在下单和取消订单业务过程中,最细粒度为一个 sku 的下单或取消订单操作,与订单明细表粒度相同,将其作为主表。
① 订单明细表和订单表的所有记录在另一张表中都有对应数据,内连接即可。
② 订单明细数据未必参加了活动也未必使用了优惠券,因此要保留订单明细独有数据,所以与订单明细活动关联表和订单明细优惠券关联表的关联使用 left join。
③ 与字典表的关联是为了获取 source_type 对应的 source_type_name,订单明细数据在字典表中一定有对应,内连接即可。
1)在 KafkaUtil 中补充 getUpsertKafkaDDL 方法
* UpsertKafka-Sink DDL 语句 * @param topic 输出到 Kafka 的目标主题 * @return 拼接好的 UpsertKafka-Sink DDL 语句 public static String getUpsertKafkaDDL(String topic) { return " WITH ( " + " 'connector' = 'upsert-kafka', " + " 'topic' = '" + topic + "', " + " 'properties.bootstrap.servers' = '" + KAFKA_SERVER + "', " + " 'key.format' = 'json', " + " 'value.format' = 'json' " + ")";2)主程序
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderPreProcess -> Kafka(ZK) public class DwdTradeOrderPreProcess { public static void main(String[] args) throws Exception { //TODO 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //生产环境中设置为Kafka主题的分区数 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); //1.1 开启CheckPoint //env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE); //env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L); //env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L)); //1.2 设置状态后端 //env.setStateBackend(new HashMapStateBackend()); //env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck"); //System.setProperty("HADOOP_USER_NAME", "atguigu"); //1.3 设置状态的TTL 生产环境设置为最大乱序程度 tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5)); //TODO 2.创建 topic_db 表 tableEnv.executeSql(MyKafkaUtil.getTopicDb("order_pre_process_211126")); //TODO 3.过滤出订单明细数据 Table orderDetailTable = tableEnv.sqlQuery("" + "select " + " data['id'] id, " + " data['order_id'] order_id, " + " data['sku_id'] sku_id, " + " data['sku_name'] sku_name, " + " data['order_price'] order_price, " + " data['sku_num'] sku_num, " + " data['create_time'] create_time, " + " data['source_type'] source_type, " + " data['source_id'] source_id, " + " data['split_total_amount'] split_total_amount, " + " data['split_activity_amount'] split_activity_amount, " + " data['split_coupon_amount'] split_coupon_amount, " + " pt " + "from topic_db " + "where `database` = 'gmall-211126-flink' " + "and `table` = 'order_detail' " + "and `type` = 'insert'"); tableEnv.createTemporaryView("order_detail_table", orderDetailTable); //转换为流并打印测试 //tableEnv.toAppendStream(orderDetailTable, Row.class).print(">>>>"); //TODO 4.过滤出订单数据 Table orderInfoTable = tableEnv.sqlQuery("" + "select " + " data['id'] id, " + " data['consignee'] consignee, " + " data['consignee_tel'] consignee_tel, " + " data['total_amount'] total_amount, " + " data['order_status'] order_status, " + " data['user_id'] user_id, " + " data['payment_way'] payment_way, " + " data['delivery_address'] delivery_address, " + " data['order_comment'] order_comment, " + " data['out_trade_no'] out_trade_no, " + " data['trade_body'] trade_body, " + " data['create_time'] create_time, " + " data['operate_time'] operate_time, " + " data['expire_time'] expire_time, " + " data['process_status'] process_status, " + " data['tracking_no'] tracking_no, " + " data['parent_order_id'] parent_order_id, " + " data['province_id'] province_id, " + " data['activity_reduce_amount'] activity_reduce_amount, " + " data['coupon_reduce_amount'] coupon_reduce_amount, " + " data['original_total_amount'] original_total_amount, " + " data['feight_fee'] feight_fee, " + " data['feight_fee_reduce'] feight_fee_reduce, " + " data['refundable_time'] refundable_time, " + " `type`, " + " `old` " + "from topic_db " + "where `database` = 'gmall-211126-flink' " + "and `table` = 'order_info' " + "and (`type` = 'insert' or `type` = 'update')"); tableEnv.createTemporaryView("order_info_table", orderInfoTable); //转换为流并打印测试 //tableEnv.toAppendStream(orderInfoTable, Row.class).print(">>>>"); //TODO 5.过滤出订单明细活动关联数据 Table orderActivityTable = tableEnv.sqlQuery("" + "select " + " data['id'] id, " + " data['order_id'] order_id, " + " data['order_detail_id'] order_detail_id, " + " data['activity_id'] activity_id, " + " data['activity_rule_id'] activity_rule_id, " + " data['sku_id'] sku_id, " + " data['create_time'] create_time " + "from topic_db " + "where `database` = 'gmall-211126-flink' " + "and `table` = 'order_detail_activity' " + "and `type` = 'insert'"); tableEnv.createTemporaryView("order_activity_table", orderActivityTable); //转换为流并打印测试 //tableEnv.toAppendStream(orderActivityTable, Row.class).print(">>>>"); //TODO 6.过滤出订单明细购物券关联数据 Table orderCouponTable = tableEnv.sqlQuery("" + "select " + " data['id'] id, " + " data['order_id'] order_id, " + " data['order_detail_id'] order_detail_id, " + " data['coupon_id'] coupon_id, " + " data['coupon_use_id'] coupon_use_id, " + " data['sku_id'] sku_id, " + " data['create_time'] create_time " + "from topic_db " + "where `database` = 'gmall-211126-flink' " + "and `table` = 'order_detail_coupon' " + "and `type` = 'insert'"); tableEnv.createTemporaryView("order_coupon_table" , orderCouponTable); //转换为流并打印测试 //tableEnv.toAppendStream(orderCouponTable, Row.class).print(">>>>"); //TODO 7.创建 base_dic LookUp表 tableEnv.executeSql(MysqlUtil.getBaseDicLookUpDDL()); //TODO 8.关联5张表 Table resultTable = tableEnv.sqlQuery("" + "select " + " od.id, " + " od.order_id, " + " od.sku_id, " + " od.sku_name, " + " od.order_price, " + " od.sku_num, " + " od.create_time, " + " od.source_type source_type_id, " + " dic.dic_name source_type_name, " + " od.source_id, " + " od.split_total_amount, " + " od.split_activity_amount, " + " od.split_coupon_amount, " + " oi.consignee, " + " oi.consignee_tel, " + " oi.total_amount, " + " oi.order_status, " + " oi.user_id, " + " oi.payment_way, " + " oi.delivery_address, " + " oi.order_comment, " + " oi.out_trade_no, " + " oi.trade_body, " + " oi.operate_time, " + " oi.expire_time, " + " oi.process_status, " + " oi.tracking_no, " + " oi.parent_order_id, " + " oi.province_id, " + " oi.activity_reduce_amount, " + " oi.coupon_reduce_amount, " + " oi.original_total_amount, " + " oi.feight_fee, " + " oi.feight_fee_reduce, " + " oi.refundable_time, " + " oa.id order_detail_activity_id, " + " oa.activity_id, " + " oa.activity_rule_id, " + " oc.id order_detail_coupon_id, " + " oc.coupon_id, " + " oc.coupon_use_id, " + " oi.`type`, " + " oi.`old`, " + " current_row_timestamp() row_op_ts "+ "from order_detail_table od " + "join order_info_table oi " + "on od.order_id = oi.id " + "left join order_activity_table oa " + "on od.id = oa.order_detail_id " + "left join order_coupon_table oc " + "on od.id = oc.order_detail_id " + "join base_dic FOR SYSTEM_TIME AS OF od.pt as dic " + "on od.source_type = dic.dic_code"); tableEnv.createTemporaryView("result_table", resultTable); //转换为流并打印测试 //tableEnv.toRetractStream(resultTable, Row.class).print(">>>>"); //TODO 9.创建 upsert-kafka 表 tableEnv.executeSql("" + "create table dwd_order_pre( " + " `id` string, " + " `order_id` string, " + " `sku_id` string, " + " `sku_name` string, " + " `order_price` string, " + " `sku_num` string, " + " `create_time` string, " + " `source_type_id` string, " + " `source_type_name` string, " + " `source_id` string, " + " `split_total_amount` string, " + " `split_activity_amount` string, " + " `split_coupon_amount` string, " + " `consignee` string, " + " `consignee_tel` string, " + " `total_amount` string, " + " `order_status` string, " + " `user_id` string, " + " `payment_way` string, " + " `delivery_address` string, " + " `order_comment` string, " + " `out_trade_no` string, " + " `trade_body` string, " + " `operate_time` string, " + " `expire_time` string, " + " `process_status` string, " + " `tracking_no` string, " + " `parent_order_id` string, " + " `province_id` string, " + " `activity_reduce_amount` string, " + " `coupon_reduce_amount` string, " + " `original_total_amount` string, " + " `feight_fee` string, " + " `feight_fee_reduce` string, " + " `refundable_time` string, " + " `order_detail_activity_id` string, " + " `activity_id` string, " + " `activity_rule_id` string, " + " `order_detail_coupon_id` string, " + " `coupon_id` string, " + " `coupon_use_id` string, " + " `type` string, " + " `old` map<string,string>, " + " row_op_ts TIMESTAMP_LTZ(3), "+ " primary key(id) not enforced " + ")" + MyKafkaUtil.getUpsertKafkaDDL("dwd_trade_order_pre_process")); //TODO 10.将数据写出 tableEnv.executeSql("insert into dwd_order_pre select * from result_table"); //TODO 11.启动任务 //env.execute("DwdTradeOrderPreProcess");交易域下单事务事实表
从 Kafka 读取订单预处理表数据,筛选下单明细数据,写入 Kafka 对应主题。
实现步骤:
(1)从 Kafka dwd_trade_order_pre_process 主题读取订单预处理数据;
(2)筛选下单明细数据:新增数据,即订单表操作类型为 insert 的数据即为订单明细数据;
(3)写入 Kafka 下单明细主题。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderPreProcess -> Kafka(ZK) -> DwdTradeOrderDetail -> Kafka(ZK) public class DwdTradeOrderDetail { public static void main(String[] args) { //TODO 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1 ); //生产环境中设置为Kafka主题的分区数 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); //1.1 开启CheckPoint //env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE); //env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L); //env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L)); //1.2 设置状态后端 //env.setStateBackend(new HashMapStateBackend()); //env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck"); //System.setProperty("HADOOP_USER_NAME", "atguigu"); //1.3 设置状态的TTL 生产环境设置为最大乱序程度 //tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5)); //TODO 2.读取Kafka订单预处理主题数据创建表 tableEnv.executeSql("" + "create table dwd_order_pre( " + " `id` string, " + " `order_id` string, " + " `sku_id` string, " + " `sku_name` string, " + " `order_price` string, " + " `sku_num` string, " + " `create_time` string, " + " `source_type_id` string, " + " `source_type_name` string, " + " `source_id` string, " + " `split_total_amount` string, " + " `split_activity_amount` string, " + " `split_coupon_amount` string, " + " `consignee` string, " + " `consignee_tel` string, " + " `total_amount` string, " + " `order_status` string, " + " `user_id` string, " + " `payment_way` string, " + " `delivery_address` string, " + " `order_comment` string, " + " `out_trade_no` string, " + " `trade_body` string, " + " `operate_time` string, " + " `expire_time` string, " + " `process_status` string, " + " `tracking_no` string, " + " `parent_order_id` string, " + " `province_id` string, " + " `activity_reduce_amount` string, " + " `coupon_reduce_amount` string, " + " `original_total_amount` string, " + " `feight_fee` string, " + " `feight_fee_reduce` string, " + " `refundable_time` string, " + " `order_detail_activity_id` string, " + " `activity_id` string, " + " `activity_rule_id` string, " + " `order_detail_coupon_id` string, " + " `coupon_id` string, " + " `coupon_use_id` string, " + " `type` string, " + " `old` map<string,string>, " + " `row_op_ts` TIMESTAMP_LTZ(3) " + ")" + MyKafkaUtil.getKafkaDDL("dwd_trade_order_pre_process", "order_detail_211126")); //TODO 3.过滤出下单数据,即新增数据 Table filteredTable = tableEnv.sqlQuery("" + "select " + "id, " + "order_id, " + "user_id, " + "sku_id, " + "sku_name, " + "sku_num, " + //+++ "order_price, " + //+++ "province_id, " + "activity_id, " + "activity_rule_id, " + "coupon_id, " + //"date_id, " + "create_time, " + "source_id, " + "source_type_id, " + //"source_type source_type_code, " + "source_type_name, " + //"sku_num, " + //"split_original_amount, " + "split_activity_amount, " + "split_coupon_amount, " + "split_total_amount, " + //删除"," //"od_ts ts, " + "row_op_ts " + "from dwd_order_pre " + "where `type`='insert'"); tableEnv.createTemporaryView("filtered_table", filteredTable); //TODO 4.创建DWD层下单数据表 tableEnv.executeSql("" + "create table dwd_trade_order_detail( " + "id string, " + "order_id string, " + "user_id string, " + "sku_id string, " + "sku_name string, " + "sku_num string, " + //+++ "order_price string, " + //+++ "province_id string, " + "activity_id string, " + "activity_rule_id string, " + "coupon_id string, " + //"date_id string, " + "create_time string, " + "source_id string, " + "source_type_id string, " + //"source_type_code string, " + "source_type_name string, " + //"sku_num string, " + //"split_original_amount string, " + "split_activity_amount string, " + "split_coupon_amount string, " + "split_total_amount string, " + //删除"," //"ts string, " + "row_op_ts timestamp_ltz(3) " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_trade_order_detail")); //TODO 5.将数据写出到Kafka tableEnv.executeSql("insert into dwd_trade_order_detail select * from filtered_table"); //TODO 6.启动任务交易域取消订单事务事实表
从 Kafka 读取订单预处理表数据,筛选取消订单明细数据,写入 Kafka 对应主题。
实现步骤:
(1)从 Kafka dwd_trade_order_pre_process 主题读取订单预处理数据;
(2)筛选取消订单明细数据:保留修改了 order_status 字段且修改后该字段值为 “1003” 的数据;
(3)写入 Kafka 取消订单主题。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderPreProcess -> Kafka(ZK) -> DwdTradeCancelDetail -> Kafka(ZK) public class DwdTradeCancelDetail { public static void main(String[] args) { //TODO 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env. setParallelism(1); //生产环境中设置为Kafka主题的分区数 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); //1.1 开启CheckPoint //env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE); //env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L); //env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L)); //1.2 设置状态后端 //env.setStateBackend(new HashMapStateBackend()); //env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck"); //System.setProperty("HADOOP_USER_NAME", "atguigu"); //1.3 设置状态的TTL 生产环境设置为最大乱序程度 //tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(5)); //TODO 2.读取Kafka 订单预处理表 tableEnv.executeSql("" + "create table dwd_order_pre( " + " `id` string, " + " `order_id` string, " + " `sku_id` string, " + " `sku_name` string, " + " `order_price` string, " + " `sku_num` string, " + " `create_time` string, " + " `source_type_id` string, " + " `source_type_name` string, " + " `source_id` string, " + " `split_total_amount` string, " + " `split_activity_amount` string, " + " `split_coupon_amount` string, " + " `consignee` string, " + " `consignee_tel` string, " + " `total_amount` string, " + " `order_status` string, " + " `user_id` string, " + " `payment_way` string, " + " `delivery_address` string, " + " `order_comment` string, " + " `out_trade_no` string, " + " `trade_body` string, " + " `operate_time` string, " + " `expire_time` string, " + " `process_status` string, " + " `tracking_no` string, " + " `parent_order_id` string, " + " `province_id` string, " + " `activity_reduce_amount` string, " + " `coupon_reduce_amount` string, " + " `original_total_amount` string, " + " `feight_fee` string, " + " `feight_fee_reduce` string, " + " `refundable_time` string, " + " `order_detail_activity_id` string, " + " `activity_id` string, " + " `activity_rule_id` string, " + " `order_detail_coupon_id` string, " + " `coupon_id` string, " + " `coupon_use_id` string, " + " `type` string, " + " `old` map<string,string> " + ")" + MyKafkaUtil.getKafkaDDL("dwd_trade_order_pre_process", "cancel_detail_211126")); //TODO 3.过滤出取消订单数据 Table filteredTable = tableEnv.sqlQuery("" + "select " + "id, " + "order_id, " + "user_id, " + "sku_id, " + "sku_name, " + "province_id, " + "activity_id, " + "activity_rule_id, " + "coupon_id, " + //"operate_date_id date_id, " + "operate_time cancel_time, " + "source_id, " + "source_type_id, " + //"source_type source_type_code, " + "source_type_name, " + "sku_num, " + "order_price, " + //+++ //"split_original_amount, " + "split_activity_amount, " + "split_coupon_amount, " + "split_total_amount " + //删除"," //"oi_ts ts, " + //"row_op_ts " + "from dwd_order_pre " + "where `type` = 'update' " + "and `old`['order_status'] is not null " + "and order_status = '1003'"); tableEnv.createTemporaryView("filtered_table", filteredTable); //TODO 4.创建Kafka 取消订单表 tableEnv.executeSql("create table dwd_trade_cancel_detail( " + "id string, " + "order_id string, " + "user_id string, " + "sku_id string, " + "sku_name string, " + "province_id string, " + "activity_id string, " + "activity_rule_id string, " + "coupon_id string, " + //"date_id string, " + "cancel_time string, " + "source_id string, " + "source_type_id string, " + // "source_type_code string, " + "source_type_name string, " + "sku_num string, " + "order_price string, " + //"split_original_amount string, " + "split_activity_amount string, " + "split_coupon_amount string, " + "split_total_amount string " + //删除"," //"ts string, " + //"row_op_ts timestamp_ltz(3) " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_trade_cancel_detail")); //TODO 5.将数据写出到Kafka tableEnv.executeSql("insert into dwd_trade_cancel_detail select * from filtered_table");交易域支付成功事务事实表
从 Kafka topic_db主题筛选支付成功数据、从dwd_trade_order_detail主题中读取订单事实数据、MySQL-LookUp字典表,关联三张表形成支付成功宽表,写入 Kafka 支付成功主题。
1)设置 ttl
支付成功事务事实表需要将业务数据库中的支付信息表 payment_info 数据与订单明细表关联。订单明细数据是在下单时生成的,经过一系列的处理进入订单明细主题,通常支付操作在下单后 15min 内完成即可,因此,支付明细数据可能比订单明细数据滞后 15min。考虑到可能的乱序问题,ttl 设置为 15min + 5s。
2)获取订单明细数据
用户必然要先下单才有可能支付成功,因此支付成功明细数据集必然是订单明细数据集的子集。
3)筛选支付表数据
获取支付类型、回调时间(支付成功时间)、支付成功时间戳。
生产环境下,用户支付后,业务数据库的支付表会插入一条数据,此时的回调时间和回调内容为空。通常底层会调用第三方支付接口,接口会返回回调信息,如果支付成功则回调信息不为空,此时会更新支付表,补全回调时间和回调内容字段的值,并将 payment_status 字段的值修改为支付成功对应的状态码(本项目为 1602)。支付成功之后,支付表数据不会发生变化。因此,只要操作类型为 update 且状态码为 1602 即为支付成功数据。
由上述分析可知,支付成功对应的业务数据库变化日志应满足两个条件:
(1)payment_status 字段的值为 1602;
(2)操作类型为 update。
本程序为了去除重复数据,在关联后的宽表中补充了处理时间字段,DWS 层将进行详细介绍。支付成功表是由支付成功数据与订单明细做内连接,而后与字典表做 LookUp Join 得来。这个过程中不会出现回撤数据,关联后表的重复数据来源于订单明细表,所以应按照订单明细表的处理时间字段去重,故支付成功明细表的 row_op_ts 取自订单明细表。
3)构建 MySQL-LookUp 字典表
4)关联上述三张表形成支付成功宽表,写入 Katka 支付成功主题
支付成功业务过程的最细粒度为一个 sku 的支付成功记录,payment_info 表的粒度与最细粒度相同,将其作为主表。
(1) payment_info 表在订单明细表中必然存在对应数据,主表不存在独有数据,因此通过内连接与订单明细表关联;
(2) 与字典表的关联是为了获取 payment_type 对应的支付类型名称,主表不存在独有数据,通过内连接与字典表关联。下文与字典表的关联同理,不再赘述。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderPreProcess -> Kafka(ZK) -> DwdTradeOrderDetail -> Kafka(ZK) -> DwdTradePayDetailSuc -> Kafka(ZK) public class DwdTradePayDetailSuc { public static void main(String[] args) throws Exception { //TODO 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //生产环境中设置为Kafka主题的分区数 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); //1.1 开启CheckPoint //env.enableCheckpointing(5 * 60000L, CheckpointingMode.EXACTLY_ONCE); //env.getCheckpointConfig().setCheckpointTimeout(10 * 60000L); //env.getCheckpointConfig().setMaxConcurrentCheckpoints(2); //env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L)); //1.2 设置状态后端 //env.setStateBackend(new HashMapStateBackend()); //env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/211126/ck"); //System.setProperty("HADOOP_USER_NAME", "atguigu"); //1.3 设置状态的TTL 生产环境设置为最大乱序程度 tableEnv.getConfig().setIdleStateRetention(Duration.ofSeconds(905)); //TODO 2.读取TopicDB数据并过滤出支付成功数据 tableEnv.executeSql(MyKafkaUtil.getTopicDb("pay_detail_suc_211126")); Table paymentInfo = tableEnv.sqlQuery("select " + "data['user_id'] user_id, " + "data['order_id'] order_id, " + "data['payment_type'] payment_type, " + "data['callback_time'] callback_time, " + "`pt` " + // "from topic_db " + "where `table` = 'payment_info' " + "and `type` = 'update' " + "and data['payment_status']='1602'"); tableEnv.createTemporaryView("payment_info", paymentInfo); //打印测试 //tableEnv.toAppendStream(paymentInfo, Row.class).print(); //TODO 3.消费下单主题数据 tableEnv.executeSql("" + "create table dwd_trade_order_detail( " + "id string, " + "order_id string, " + "user_id string, " + "sku_id string, " + "sku_name string, " + "sku_num string, " + //+++ "order_price string, " + //+++ "province_id string, " + "activity_id string, " + "activity_rule_id string, " + "coupon_id string, " + //"date_id string, " + "create_time string, " + "source_id string, " + "source_type_id string, " + //"source_type_code string, " + "source_type_name string, " + //"sku_num string, " + //"split_original_amount string, " + "split_activity_amount string, " + "split_coupon_amount string, " + "split_total_amount string, " + //删除"," //"ts string, " + "row_op_ts timestamp_ltz(3) " + ")" + MyKafkaUtil.getKafkaDDL("dwd_trade_order_detail","pay_detail_suc_order_211126")); //TODO 4.读取MySQL Base_Dic表 tableEnv.executeSql(MysqlUtil.getBaseDicLookUpDDL()); //TODO 5.三表关联 Table resultTable = tableEnv.sqlQuery("" + "select " + "od.id order_detail_id, " + "od.order_id, " + "od.user_id, " + "od.sku_id, " + "od.sku_name, " + "od.province_id, " + "od.activity_id, " + "od.activity_rule_id, " + "od.coupon_id, " + "pi.payment_type payment_type_code, " + "dic.dic_name payment_type_name, " + "pi.callback_time, " + "od.source_id, " + "od.source_type_id, " + //"od.source_type_code, " + "od.source_type_name, " + "od.sku_num, " + "od.order_price, " + //+++ //"od.split_original_amount, " + "od.split_activity_amount, " + "od.split_coupon_amount, " + "od.split_total_amount split_payment_amount, " + //删除"," //"pi.ts, " + "od.row_op_ts row_op_ts " + "from payment_info pi " + "join dwd_trade_order_detail od " + "on pi.order_id = od.order_id " + "join `base_dic` for system_time as of pi.pt as dic " + //proc_time -> pt "on pi.payment_type = dic.dic_code"); tableEnv.createTemporaryView("result_table", resultTable); //TODO 6.创建Kafka支付成功表 tableEnv.executeSql("" + "create table dwd_trade_pay_detail_suc( " + "order_detail_id string, " + "order_id string, " + "user_id string, " + "sku_id string, " + "sku_name string, " + "province_id string, " + "activity_id string, " + "activity_rule_id string, " + "coupon_id string, " + "payment_type_code string, " + "payment_type_name string, " + "callback_time string, " + "source_id string, " + "source_type_id string, " + //"source_type_code string, " + "source_type_name string, " + "sku_num string, " + "order_price string, " + //+++ //"split_original_amount string, " + "split_activity_amount string, " + "split_coupon_amount string, " + "split_payment_amount string, " + //"ts string, " + "row_op_ts timestamp_ltz(3), " + "primary key(order_detail_id) not enforced " + ")" + MyKafkaUtil.getUpsertKafkaDDL("dwd_trade_pay_detail_suc")); //TODO 7.将数据写出 tableEnv.executeSql("" + "insert into dwd_trade_pay_detail_suc select * from result_table"); //TODO 8.启动任务 //env.execute("DwdTradePayDetailSuc");交易域退单事务事实表
从 Kafka 读取业务数据,筛选退单表数据,筛选满足条件的订单表数据,建立 MySQL-Lookup 字典表,关联三张表获得退单明细宽表。
1)设置 ttl
用户执行一次退单操作时,order_refund_info 会插入多条数据,同时 order_info 表的****一****条对应数据会发生修改,所以两张表不存在业务上的时间滞后问题,因此仅考虑可能的乱序即可,ttl 设置为 5s。
2)筛选退单表数据
退单业务过程最细粒度的操作为一个订单中一个 SKU 的退单操作,退单表粒度与最细粒度相同,将其作为主表。
3)筛选订单表数据并转化为流
获取 province_id。退单操作发生时,订单表的 order_status 字段值会由1002(已支付)更新为 1005(退款中)。订单表中的数据要满足三个条件:
(1)order_status 为 1005(退款中);
(2)操作类型为 update;
(3)更新的字段为 order_status。
该字段发生变化时,变更数据中 old 字段下 order_status 的值不为 null(为 1002)。
4) 建立 MySQL-Lookup 字典表
获取退款类型名称和退款原因类型名称。
5)关联这几张表获得退单明细宽表,写入 Kafka 退单明细主题
退单信息表 order_refund_info 的粒度为退单业务过程的最细粒度,将其作为主表。
(1)对单信息表与订单表的退单数据完全对应,不存在独有数据,通过内连接关联。
(2)与字典表通过内连接关联。
第二步是否从订单表中筛选退单数据并不影响查询结果,提前对数据进行过滤是为了减少数据量,减少性能消耗。下文同理,不再赘述。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeOrderRefund -> Kafka(ZK) public class DwdTradeOrderRefund { public static void main(String[] args) throws Exception { // TODO 1. 环境准备 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 获取配置对象 Configuration configuration = tableEnv.getConfig().getConfiguration(); // 为表关联时状态中存储的数据设置过期时间 configuration.setString("table.exec.state.ttl", "5 s"); // TODO 2. 状态后端设置 // env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE); // env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L); // env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); // env.getCheckpointConfig().enableExternalizedCheckpoints( // CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION // ); // env.setRestartStrategy(RestartStrategies.failureRateRestart( // 3, Time.days(1), Time.minutes(1) // )); // env.setStateBackend(new HashMapStateBackend()); // env.getCheckpointConfig().setCheckpointStorage( // "hdfs://hadoop102:8020/ck" // ); // System.setProperty("HADOOP_USER_NAME", "atguigu"); // TODO 3. 从 Kafka 读取 topic_db 数据,封装为 Flink SQL 表 tableEnv.executeSql("create table topic_db(" + "`database` string, " + "`table` string, " + "`type` string, " + "`data` map<string, string>, " + "`old` map<string, string>, " + "`proc_time` as PROCTIME(), " + "`ts` string " + ")" + MyKafkaUtil.getKafkaDDL("topic_db", "order_refund_211126")); // TODO 4. 读取退单表数据 Table orderRefundInfo = tableEnv.sqlQuery("select " + "data['id'] id, " + "data['user_id'] user_id, " + "data['order_id'] order_id, " + "data['sku_id'] sku_id, " + "data['refund_type'] refund_type, " + "data['refund_num'] refund_num, " + "data['refund_amount'] refund_amount, " + "data['refund_reason_type'] refund_reason_type, " + "data['refund_reason_txt'] refund_reason_txt, " + "data['create_time'] create_time, " + "proc_time, " + "ts " + "from topic_db " + "where `table` = 'order_refund_info' " + "and `type` = 'insert' "); tableEnv.createTemporaryView("order_refund_info", orderRefundInfo); // TODO 5. 读取订单表数据,筛选退单数据 Table orderInfoRefund = tableEnv.sqlQuery("select " + "data['id'] id, " + "data['province_id'] province_id, " + "`old` " + "from topic_db " + "where `table` = 'order_info' " + "and `type` = 'update' " + "and data['order_status']='1005' " + "and `old`['order_status'] is not null"); tableEnv.createTemporaryView("order_info_refund", orderInfoRefund); // TODO 6. 建立 MySQL-LookUp 字典表 tableEnv.executeSql(MysqlUtil.getBaseDicLookUpDDL()); // TODO 7. 关联三张表获得退单宽表 Table resultTable = tableEnv.sqlQuery("select " + "ri.id, " + "ri.user_id, " + "ri.order_id, " + "ri.sku_id, " + "oi.province_id, " + "date_format(ri.create_time,'yyyy-MM-dd') date_id, " + "ri.create_time, " + "ri.refund_type, " + "type_dic.dic_name, " + "ri.refund_reason_type, " + "reason_dic.dic_name, " + "ri.refund_reason_txt, " + "ri.refund_num, " + "ri.refund_amount, " + "ri.ts, " + "current_row_timestamp() row_op_ts " + "from order_refund_info ri " + "join " + "order_info_refund oi " + "on ri.order_id = oi.id " + "join " + "base_dic for system_time as of ri.proc_time as type_dic " + "on ri.refund_type = type_dic.dic_code " + "join " + "base_dic for system_time as of ri.proc_time as reason_dic " + "on ri.refund_reason_type=reason_dic.dic_code"); tableEnv.createTemporaryView("result_table", resultTable); // TODO 8. 建立 Kafka-Connector dwd_trade_order_refund 表 tableEnv.executeSql("create table dwd_trade_order_refund( " + "id string, " + "user_id string, " + "order_id string, " + "sku_id string, " + "province_id string, " + "date_id string, " + "create_time string, " + "refund_type_code string, " + "refund_type_name string, " + "refund_reason_type_code string, " + "refund_reason_type_name string, " + "refund_reason_txt string, " + "refund_num string, " + "refund_amount string, " + "ts string, " + "row_op_ts timestamp_ltz(3) " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_trade_order_refund")); // TODO 9. 将关联结果写入 Kafka-Connector 表 tableEnv.executeSql("" + "insert into dwd_trade_order_refund select * from result_table");交易域退款成功事务事实表
1)从退款表中提取退款成功数据,并将字典表的 dic_name维度退化到表中
2)从订单表中提取退款成功订单数据
3)从退单表中提取退款成功的明细数据
1)设置 ttl
一次退款支付操作成功时,refund_payment 表会新增记录,订单表 order_info 和退单表order_refund_info 的对应数据会发生修改,几张表之间不存在业务上的时间滞后。与字典表的关联分析同上,不再赘述。因而,仅考虑可能的数据乱序即可。将 ttl 设置为 5s。
2)建立 MySQL-Lookup 字典表
获取支付类型名称。
2)读取退款表数据,筛选退款成功数据
退款表 refund_payment 的粒度为一个订单中一个 SKU 的退款记录,与退款业务过程的最细粒度相同,将其作为主表。
退款操作发生时,业务数据库的退款表会先插入一条数据,此时 refund_status 状态码应为 0701(商家审核中),callback_time 为 null,而后经历一系列业务过程:商家审核、买家发货、退单完成。退单完成时会将状态码由 0701 更新为 0705(退单完成),同时将
callback_time 更新为退款支付成功的回调时间。
由上述分析可知,退款成功记录应满足三个条件:(1)数据操作类型为 update;(2)refund_status 为 0705;(3)修改的字段包含 refund_status。
3)读取订单表数据,过滤退款成功订单数据
用于获取 user_id 和 province_id。退款操作完后时,订单表的 order_status 字段会更新为 1006(退款完成),因此退单成功对应的订单数据应满足三个条件:
(1)操作类型为 update;
(2)order_status 为 1006;
(3)修改了 order_status 字段。
order_status 值更改为 1006 之后对应的订单表数据就不会再发生变化,所以只要满足前两个条件,第三个条件必定满足。
4)筛选退款成功的退单明细数据
用于获取退单件数 refund_num。退单成功时 order_refund_info 表中的 refund_status 字段会修改为0705(退款成功状态码)。因此筛选条件有三:(1)操作类型为 update;(2)refund_status 为 0705;(3)修改了 refund_status 字段。筛选方式同上。
5)关联四张表并写出到 Katka 退款成功主题
退款支付表的粒度为退款支付业务过程的最细粒度,即一个 sku 的退款操作,将其作为主表。
(1)退款支付表数据与订单表中的退款变更数据完全对应,不存在独有数据,内连接关联。
(2)退款支付数据与退单表退款变更数据完全对应,不存在独有数据,内连接关联。
(3)与字典表通过内连接关联。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdTradeRefundPaySuc -> Kafka(ZK) public class DwdTradeRefundPaySuc { public static void main(String[] args) throws Exception { // TODO 1. 环境准备 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 获取配置对象 Configuration configuration = tableEnv.getConfig().getConfiguration(); // 为表关联时状态中存储的数据设置过期时间 configuration.setString("table.exec.state.ttl", "5 s"); // TODO 2. 状态后端设置 // env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE); // env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); // env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L); // env.getCheckpointConfig().enableExternalizedCheckpoints( // CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION // ); // env.setRestartStrategy(RestartStrategies.failureRateRestart( // 3, Time.days(1), Time.minutes(1) // )); // env.setStateBackend(new HashMapStateBackend()); // env.getCheckpointConfig().setCheckpointStorage( // "hdfs://hadoop102:8020/ck" // ); // System.setProperty("HADOOP_USER_NAME", "atguigu"); // TODO 3. 从 Kafka 读取 topic_db 数据,封装为 Flink SQL 表 tableEnv.executeSql("create table topic_db(" + "`database` string, " + "`table` string, " + "`type` string, " + "`data` map<string, string>, " + "`old` map<string, string>, " + "`proc_time` as PROCTIME(), " + "`ts` string " + ")" + MyKafkaUtil.getKafkaDDL("topic_db", "refund_pay_suc_211126")); // TODO 4. 建立 MySQL-LookUp 字典表 tableEnv.executeSql(MysqlUtil.getBaseDicLookUpDDL()); // TODO 5. 读取退款表数据,并筛选退款成功数据 Table refundPayment = tableEnv.sqlQuery("select " + "data['id'] id, " + "data['order_id'] order_id, " + "data['sku_id'] sku_id, " + "data['payment_type'] payment_type, " + "data['callback_time'] callback_time, " + "data['total_amount'] total_amount, " + "proc_time, " + "ts " + "from topic_db " + "where `table` = 'refund_payment' " // + // "and `type` = 'update' " + // "and data['refund_status'] = '0702' " + // "and `old`['refund_status'] is not null" tableEnv.createTemporaryView("refund_payment", refundPayment); // TODO 6. 读取订单表数据并过滤退款成功订单数据 Table orderInfo = tableEnv.sqlQuery("select " + "data['id'] id, " + "data['user_id'] user_id, " + "data['province_id'] province_id, " + "`old` " + "from topic_db " + "where `table` = 'order_info' " + "and `type` = 'update' " "and data['order_status']='1006' " + "and `old`['order_status'] is not null" tableEnv.createTemporaryView("order_info", orderInfo); // TODO 7. 读取退单表数据并过滤退款成功数据 Table orderRefundInfo = tableEnv.sqlQuery("select " + "data['order_id'] order_id, " + "data['sku_id'] sku_id, " + "data['refund_num'] refund_num, " + "`old` " + "from topic_db " + "where `table` = 'order_refund_info' " // + // "and `type` = 'update' " + // "and data['refund_status']='0705' " + // "and `old`['refund_status'] is not null" // order_refund_info 表的 refund_status 字段值均为 null tableEnv.createTemporaryView("order_refund_info", orderRefundInfo); // TODO 8. 关联四张表获得退款成功表 Table resultTable = tableEnv.sqlQuery("select " + "rp.id, " + "oi.user_id, " + "rp.order_id, " + "rp.sku_id, " + "oi.province_id, " + "rp.payment_type, " + "dic.dic_name payment_type_name, " + "date_format(rp.callback_time,'yyyy-MM-dd') date_id, " + "rp.callback_time, " + "ri.refund_num, " + "rp.total_amount, " + "rp.ts, " + "current_row_timestamp() row_op_ts " + "from refund_payment rp " + "join " + "order_info oi " + "on rp.order_id = oi.id " + "join " + "order_refund_info ri " + "on rp.order_id = ri.order_id " + "and rp.sku_id = ri.sku_id " + "join " + "base_dic for system_time as of rp.proc_time as dic " + "on rp.payment_type = dic.dic_code "); tableEnv.createTemporaryView("result_table", resultTable); // TODO 9. 创建 Kafka-Connector dwd_trade_refund_pay_suc 表 tableEnv.executeSql("create table dwd_trade_refund_pay_suc( " + "id string, " + "user_id string, " + "order_id string, " + "sku_id string, " + "province_id string, " + "payment_type_code string, " + "payment_type_name string, " + "date_id string, " + "callback_time string, " + "refund_num string, " + "refund_amount string, " + "ts string, " + "row_op_ts timestamp_ltz(3) " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_trade_refund_pay_suc")); // TODO 10. 将关联结果写入 Kafka-Connector 表 tableEnv.executeSql("" + "insert into dwd_trade_refund_pay_suc select * from result_table");工具域优惠券领取事务事实表
读取优惠券领用数据,写入 Kafka 优惠券领用主题
用户领取优惠券后,业务数据库的优惠券领用表会新增一条数据,因此操作类型为 insert 的数据即为优惠券领取数据。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdToolCouponGet -> Kafka(ZK) public class DwdToolCouponGet { public static void main(String[] args) throws Exception { // TODO 1. 环境准备 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // TODO 2. 状态后端设置 // env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE); // env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L); // env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); // env.getCheckpointConfig().enableExternalizedCheckpoints( // CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION // ); // env.setRestartStrategy(RestartStrategies.failureRateRestart( // 3, Time.days(1), Time.minutes(1) // )); // env.setStateBackend(new HashMapStateBackend()); // env.getCheckpointConfig().setCheckpointStorage( // "hdfs://hadoop102:8020/ck" // ); // System.setProperty("HADOOP_USER_NAME", "atguigu"); // TODO 3. 从 Kafka 读取业务数据,封装为 Flink SQL 表 tableEnv.executeSql("create table `topic_db`( " + "`database` string, " + "`table` string, " + "`data` map<string, string>, " + "`type` string, " + "`ts` string " + ")" + MyKafkaUtil.getKafkaDDL("topic_db", "dwd_tool_coupon_get_211126")); // TODO 4. 读取优惠券领用数据,封装为表 Table resultTable = tableEnv.sqlQuery("select " + "data['id'], " + "data['coupon_id'], " + "data['user_id'], " + "date_format(data['get_time'],'yyyy-MM-dd') date_id, " + "data['get_time'], " + "ts " + "from topic_db " + "where `table` = 'coupon_use' " + "and `type` = 'insert' "); tableEnv.createTemporaryView("result_table", resultTable); // TODO 5. 建立 Kafka-Connector dwd_tool_coupon_get 表 tableEnv.executeSql("create table dwd_tool_coupon_get ( " + "id string, " + "coupon_id string, " + "user_id string, " + "date_id string, " + "get_time string, " + "ts string " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_tool_coupon_get")); // TODO 6. 将数据写入 Kafka-Connector 表 tableEnv.executeSql("" + "insert into dwd_tool_coupon_get select * from result_table");工具域优惠券使用(下单)事务事实表
读取优惠券领用表数据,筛选优惠券下单数据,写入 Kafka 优惠券下单主题。
用户使用优惠券下单时,优惠券领用表的 using_time 字段会更新为下单时间,同时 coupon_status 字段会由 1401 更改为 1402,因此优惠券下单数据应满足三个条件:① 操作类型为 update;② 当前 coupon_status 字段的值为 1402;③ 修改了 coupon_status 字段。
执行步骤:
(1)通过三个条件筛选优惠券使用(下单)数据。
(2)建立 Upsert-Kafka 表,将优惠券使用(下单)数据写入 Kafka 优惠券使用(下单)事实主题。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdToolCouponOrder -> Kafka(ZK) public class DwdToolCouponOrder { public static void main(String[] args) throws Exception { // TODO 1. 环境准备 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // TODO 2. 状态后端设置 // env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE); // env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L); // env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); // env.getCheckpointConfig().enableExternalizedCheckpoints( // CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION // ); // env.setRestartStrategy(RestartStrategies.failureRateRestart( // 3, Time.days(1), Time.minutes(1) // )); // env.setStateBackend(new HashMapStateBackend()); // env.getCheckpointConfig().setCheckpointStorage( // "hdfs://hadoop102:8020/ck" // ); // System.setProperty("HADOOP_USER_NAME", "atguigu"); // TODO 3. 从 Kafka 读取业务数据,封装为 Flink SQL 表 tableEnv.executeSql("create table `topic_db` ( " + "`database` string, " + "`table` string, " + "`data` map<string, string>, " + "`type` string, " + "`old` map<string, string>, " + "`ts` string " + ")" + MyKafkaUtil.getKafkaDDL("topic_db", "dwd_tool_coupon_order_211126")); // TODO 4. 读取优惠券领用表数据,筛选满足条件的优惠券下单数据 Table couponUseOrder = tableEnv.sqlQuery("select " + "data['id'] id, " + "data['coupon_id'] coupon_id, " + "data['user_id'] user_id, " + "data['order_id'] order_id, " + "date_format(data['using_time'],'yyyy-MM-dd') date_id, " + "data['using_time'] using_time, " + "ts " + "from topic_db " + "where `table` = 'coupon_use' " + "and `type` = 'update' " + "and data['coupon_status'] = '1402' " + "and `old`['coupon_status'] = '1401'"); tableEnv.createTemporaryView("result_table", couponUseOrder); // TODO 5. 建立 Kafka-Connector dwd_tool_coupon_order 表 tableEnv.executeSql("create table dwd_tool_coupon_order( " + "id string, " + "coupon_id string, " + "user_id string, " + "order_id string, " + "date_id string, " + "order_time string, " + "ts string " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_tool_coupon_order")); // TODO 6. 将数据写入 Kafka-Connector 表 tableEnv.executeSql("" + "insert into dwd_tool_coupon_order select " + "id, " + "coupon_id, " + "user_id, " + "order_id, " + "date_id, " + "using_time order_time, " + "ts from result_table");工具域优惠券使用(支付)事务事实表
读取优惠券领用表数据,筛选优惠券支付数据,写入 Kafka 优惠券支付主题。
用户使用优惠券支付时,优惠券领用表的 used_time 字段会更新为支付时间,因此优惠券支付数据应满足两个条件:(1)操作类型为 update;(2)修改了 used_time 字段。使用优惠券支付后,优惠券领用表数据就不会再发生变化,所以在操作类型为 update 的前提下,只要 used_time 不为 null,就可以断定本次操作修改的是 used_time 字段。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdToolCouponPay -> Kafka(ZK) public class DwdToolCouponPay { public static void main(String[] args) throws Exception { // TODO 1. 环境准备 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // TODO 2. 状态后端设置 // env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE); // env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L); // env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); // env.getCheckpointConfig().enableExternalizedCheckpoints( // CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION // ); // env.setRestartStrategy(RestartStrategies.failureRateRestart( // 3, Time.days(1), Time.minutes(1) // )); // env.setStateBackend(new HashMapStateBackend()); // env.getCheckpointConfig().setCheckpointStorage( // "hdfs://hadoop102:8020/ck" // ); // System.setProperty("HADOOP_USER_NAME", "atguigu"); // TODO 3. 从 Kafka 读取业务数据,封装为 Flink SQL 表 tableEnv.executeSql("create table `topic_db` ( " + "`database` string, " + "`table` string, " + "`data` map<string, string>, " + "`type` string, " + "`old` string, " + "`ts` string " + ")" + MyKafkaUtil.getKafkaDDL("topic_db", "dwd_tool_coupon_pay_211126")); // TODO 4. 读取优惠券领用表数据,筛选优惠券使用(支付)数据 Table couponUsePay = tableEnv.sqlQuery("select " + "data['id'] id, " + "data['coupon_id'] coupon_id, " + "data['user_id'] user_id, " + "data['order_id'] order_id, " + "date_format(data['used_time'],'yyyy-MM-dd') date_id, " + "data['used_time'] used_time, " + "`old`, " + "ts " + "from topic_db " + "where `table` = 'coupon_use' " + "and `type` = 'update' " + "and data['used_time'] is not null"); tableEnv.createTemporaryView("coupon_use_pay", couponUsePay); // TODO 5. 建立 Kafka-Connector dwd_tool_coupon_order 表 tableEnv.executeSql("create table dwd_tool_coupon_pay( " + "id string, " + "coupon_id string, " + "user_id string, " + "order_id string, " + "date_id string, " + "payment_time string, " + "ts string " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_tool_coupon_pay")); // TODO 6. 将数据写入 Kafka-Connector 表 tableEnv.executeSql("" + "insert into dwd_tool_coupon_pay select " + "id, " + "coupon_id, " + "user_id, " + "order_id, " + "date_id, " + "used_time payment_time, " + "ts from coupon_use_pay");互动域收藏商品事务事实表
读取收藏数据,写入 Kafka 收藏主题
用户收藏商品时业务数据库的收藏表会插入一条数据,因此筛选操作类型为 insert 的数据即可。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdInteractionFavorAdd -> Kafka(ZK) public class DwdInteractionFavorAdd { public static void main(String[] args) throws Exception { // TODO 1. 环境准备 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // TODO 2. 状态后端设置 // env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE); // env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L); // env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); // env.getCheckpointConfig().enableExternalizedCheckpoints( // CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION // ); // env.setRestartStrategy(RestartStrategies.failureRateRestart( // 3, Time.days(1), Time.minutes(1) // )); // env.setStateBackend(new HashMapStateBackend()); // env.getCheckpointConfig().setCheckpointStorage( // "hdfs://hadoop102:8020/ck" // ); // System.setProperty("HADOOP_USER_NAME", "atguigu"); // TODO 3. 从 Kafka 读取业务数据,封装为 Flink SQL 表 tableEnv.executeSql("create table topic_db(" + "`database` string, " + "`table` string, " + "`type` string, " + "`data` map<string, string>, " + "`ts` string " + ")" + MyKafkaUtil.getKafkaDDL("topic_db", "dwd_interaction_favor_add_211126")); // TODO 4. 读取收藏表数据 Table favorInfo = tableEnv.sqlQuery("select " + "data['id'] id, " + "data['user_id'] user_id, " + "data['sku_id'] sku_id, " + "date_format(data['create_time'],'yyyy-MM-dd') date_id, " + "data['create_time'] create_time, " + "ts " + "from topic_db " + "where `table` = 'favor_info' " + "and (`type` = 'insert' or (`type` = 'update' and data['is_cancel'] = '0'))" + ""); tableEnv.createTemporaryView("favor_info", favorInfo); // TODO 5. 创建 Kafka-Connector dwd_interaction_favor_add 表 tableEnv.executeSql("create table dwd_interaction_favor_add ( " + "id string, " + "user_id string, " + "sku_id string, " + "date_id string, " + "create_time string, " + "ts string " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_interaction_favor_add")); // TODO 6. 将数据写入 Kafka-Connector 表 tableEnv.executeSql("" + "insert into dwd_interaction_favor_add select * from favor_info");互动域评价事务事实表
建立 MySQL-Lookup 字典表,读取评论表数据,关联字典表以获取评价(好评、中评、差评、自动),将结果写入 Kafka 评价主题
1)设置 ttl
前文提到,与字典表关联时 ttl 的设置主要是考虑到从外部介质查询维度数据的时间,此处设置为 5s。
2)筛选评论数据
用户提交评论时评价表会插入一条数据,筛选操作类型为 insert 的数据即可。
3)建立 Mysql-Lookup 字典表
4)关联两张表
5)写入 Katka 互动域评论事实主题
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdInteractionComment -> Kafka(ZK) public class DwdInteractionComment { public static void main(String[] args) throws Exception { // TODO 1. 环境准备 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 获取配置对象 Configuration configuration = tableEnv.getConfig().getConfiguration(); // 为表关联时状态中存储的数据设置过期时间 configuration.setString("table.exec.state.ttl", "5 s"); // TODO 2. 状态后端设置 // env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE); // env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L); // env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); // env.getCheckpointConfig().enableExternalizedCheckpoints( // CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION // ); // env.setRestartStrategy(RestartStrategies.failureRateRestart( // 3, Time.days(1), Time.minutes(1) // )); // env.setStateBackend(new HashMapStateBackend()); // env.getCheckpointConfig().setCheckpointStorage( // "hdfs://hadoop102:8020/ck" // ); // System.setProperty("HADOOP_USER_NAME", "atguigu"); // TODO 3. 从 Kafka 读取业务数据,封装为 Flink SQL 表 tableEnv.executeSql("create table topic_db(" + "`database` string, " + "`table` string, " + "`type` string, " + "`data` map<string, string>, " + "`proc_time` as PROCTIME(), " + "`ts` string " + ")" + MyKafkaUtil.getKafkaDDL("topic_db", "dwd_interaction_comment_211126")); // TODO 4. 读取评论表数据 Table commentInfo = tableEnv.sqlQuery("select " + "data['id'] id, " + "data['user_id'] user_id, " + "data['sku_id'] sku_id, " + "data['order_id'] order_id, " + "data['create_time'] create_time, " + "data['appraise'] appraise, " + "proc_time, " + "ts " + "from topic_db " + "where `table` = 'comment_info' " + "and `type` = 'insert' "); tableEnv.createTemporaryView("comment_info", commentInfo); // TODO 5. 建立 MySQL-LookUp 字典表 tableEnv.executeSql(MysqlUtil.getBaseDicLookUpDDL()); // TODO 6. 关联两张表 Table resultTable = tableEnv.sqlQuery("select " + "ci.id, " + "ci.user_id, " + "ci.sku_id, " + "ci.order_id, " + "date_format(ci.create_time,'yyyy-MM-dd') date_id, " + "ci.create_time, " + "ci.appraise, " + "dic.dic_name, " + "ts " + "from comment_info ci " + "join " + "base_dic for system_time as of ci.proc_time as dic " + "on ci.appraise = dic.dic_code"); tableEnv.createTemporaryView("result_table", resultTable); // TODO 7. 建立 Kafka-Connector dwd_interaction_comment 表 tableEnv.executeSql("create table dwd_interaction_comment( " + "id string, " + "user_id string, " + "sku_id string, " + "order_id string, " + "date_id string, " + "create_time string, " + "appraise_code string, " + "appraise_name string, " + "ts string " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_interaction_comment")); // TODO 8. 将关联结果写入 Kafka-Connector 表 tableEnv.executeSql("" + "insert into dwd_interaction_comment select * from result_table");用户域用户注册事务事实表
读取用户表数据,获取注册时间,将用户注册信息写入 Kafka 用户注册主题。
用户注册时会在用户表中插入一条数据,筛选操作类型为 insert 的数据即可。
//数据流:Web/app -> nginx -> 业务服务器(Mysql) -> Maxwell -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) //程 序:Mock -> Mysql -> Maxwell -> Kafka(ZK) -> DwdUserRegister -> Kafka(ZK) public class DwdUserRegister { public static void main(String[] args) throws Exception { // TODO 1. 环境准备 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); tableEnv.getConfig().setLocalTimeZone(ZoneId.of("GMT+8")); // TODO 2. 启用状态后端 // env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE); // env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L); // env.getCheckpointConfig().enableExternalizedCheckpoints( // CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION // ); // env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L); // env.setRestartStrategy( // RestartStrategies.failureRateRestart(3, Time.days(1L), Time.minutes(3L)) // ); // env.setStateBackend(new HashMapStateBackend()); // env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/ck"); // System.setProperty("HADOOP_USER_NAME", "atguigu"); // TODO 3. 从 Kafka 读取业务数据,封装为 Flink SQL 表 tableEnv.executeSql("create table topic_db(" + "`database` string, " + "`table` string, " + "`type` string, " + "`data` map<string, string>, " + "`ts` string " + ")" + MyKafkaUtil.getKafkaDDL("topic_db", "dwd_trade_order_detail_211126")); // TODO 4. 读取用户表数据 Table userInfo = tableEnv.sqlQuery("select " + "data['id'] user_id, " + "data['create_time'] create_time, " + "ts " + "from topic_db " + "where `table` = 'user_info' " + "and `type` = 'insert' "); tableEnv.createTemporaryView("user_info", userInfo); // TODO 5. 创建 Kafka-Connector dwd_user_register 表 tableEnv.executeSql("create table `dwd_user_register`( " + "`user_id` string, " + "`date_id` string, " + "`create_time` string, " + "`ts` string " + ")" + MyKafkaUtil.getKafkaSinkDDL("dwd_user_register")); // TODO 6. 将输入写入 Kafka-Connector 表 tableEnv.executeSql("insert into dwd_user_register " + "select " + "user_id, " + "date_format(create_time, 'yyyy-MM-dd') date_id, " + "create_time, " + "ts " + "from user_info"); # 大数据 # 数据仓库 # flink # kafka
-



