


不用自备显卡,在线免费体验八个开源大语言模型!


我在本地部署过Stable Diffusion的Webui,用 Lora训练过一个Stable Diffusion上用的模型 ,部署过 清华开源的ChatGLM ,也一键安装过LLaMA 7B的对话模型(Alpaca Electron-解压即可使用)。


除了最后一个没用到显卡,其它几个在部署的时候总是因为显存不够而难受。那就得买24GB显存的显卡了吗?
除了真正的研究开发人员,普通人千万不要因为想在本地电脑部署大语言模型而冲动买显卡。
因为,体验了很多项目之后再跟ChatGPT一对比,体验差距过于大,很容易失望。
除非非常不差钱,我劝你不要买RTX 3090或者RTX 4090这种级别的24GB显卡,更不要轻易尝试P40、K40之类的加速卡。
因为前者起码还能用来玩游戏,后者等你热情过了就只能吃灰了。
为了帮大家快速简单了解常见的开源大语言模型在现阶段的基本表现,有人做了这么一个网站,网站托管了8个开源的大语言模型。
Vicuna


一款类似ChatGPT的聊天助手,基于用户分享的跟LLaMA的对话数据做微调而得来,训练成本约为300美元。
评估结果显示,Vicuna-13B在超过90%的情况下,都比LLaMA和斯坦福羊驼(Stanford Alpaca)表现要好。另外,其质量水平达到了OpenAI ChatGPT和Google Bard九成以上的水准。
Koala(考拉)


也是类似ChatGPT的聊天助手,由用户分享的与LLaMA的对话数据和开源数据集上微调得来。
与ChatGPT和斯坦福的Alpaca进行了比较,Koala能够有效地回应各种用户的问题,做出的回应经常比Alpaca更好,在50%以上的概率中与ChatGPT表现不相上下。
Koala(考拉)的出现表明,如果在精心收集的数据上进行训练,那些小到可以在本地运行的模型也可获得比肩同类大模型的表现。
换句话说,如果投入更多精力来策划高质量的数据集,可能比单纯增加系统规模更有助于训练处更安全、更真实和更强的模型。
值得注意的是,Koala(考拉)是一项研究的原型,它在内容、安全性和可靠性方面仍有很大的缺陷,不建议用在研究以外的场景。
Open Assistant

这是一个面向所有人的对话式 AI,其目标是成为像Stable Diffusion一样有影响力的开源模型,因此,它也是免费可用的,其目标是在消费级硬件上运行。
Open Assistant 是由 LAION 和全球贡献者组织的项目。官网介绍中提到,Open Assistant处于研发的初期阶段, 正在研究将RLHF应用于 LLM。
除了像用ChatGPT一样用它,用户也可以对模型生成的数据进行评价,公户贡献的这些反馈有助于提高模型的公正客观,少一点偏见。
Dolly
由Databricks开源的指令优化的大语言模型。
Dolly 2.0是一个基于EleutherAI pythia模型系列的12B参数的语言模型,特意在一个新的、高质量的人类生成的指令跟随数据集上进行微调得来。
Dolly目前有两个版本,Dolly1.0用了OpenAI的数据所以没法开源。最新的Dolly 2.0开源的很彻底,可供研究和商业使用。
目前,Databricks开放了Dolly 2.0的全部内容,包括训练代码、数据集和模型权重,所有这些都可免费商用,无需付费。
ChatGLM


清华团队开源的中英双语对话语言模型——ChatGLM-6B,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
经过约 1T 标识符的中英双语训练,辅以监督微调、 反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了用户部署的门槛,并且已经能生成相当符合人类偏好的回答。
StableLM


Stability的大语言模型,Stability此前的项目就是大名鼎鼎的Stable Diffusion(文章头图就是我用它生成的,感兴趣的可以私信,我分享给你我自己训练的LoRa)。
StableLM将包含6个不同大小的模型,目前开放下载的只有30亿和70亿参数规模两种,150亿、300亿以及650亿的还在开发当中,1750亿参数的还在计划当中。
StableLM-Alpha是从The Pile数据集基础上训练而来的,将原始的Pile数据集放大了三倍,用1.5万亿个文本做训练。
Stability还用斯坦福大学的Alpaca对模型进行了微调,微调使用的数据集来自与几个AI模型的对话,包括斯坦福大学的Alpaca、Nomic-AI的gpt4all、RyokoAI的ShareGPT52K、Databricks labs的Dolly和Anthropic的HH。
Alpaca


Alpaca 7B是一个从LLaMA 7B模型中微调出来的关于52K指令跟随演示的模型。
评估显示,Alpaca的表现与OpenAI的text-davinci-003在质量上相似,同时模型本身又出奇的小,可以以很低的成本复制。
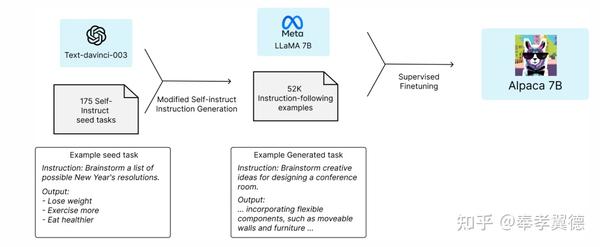
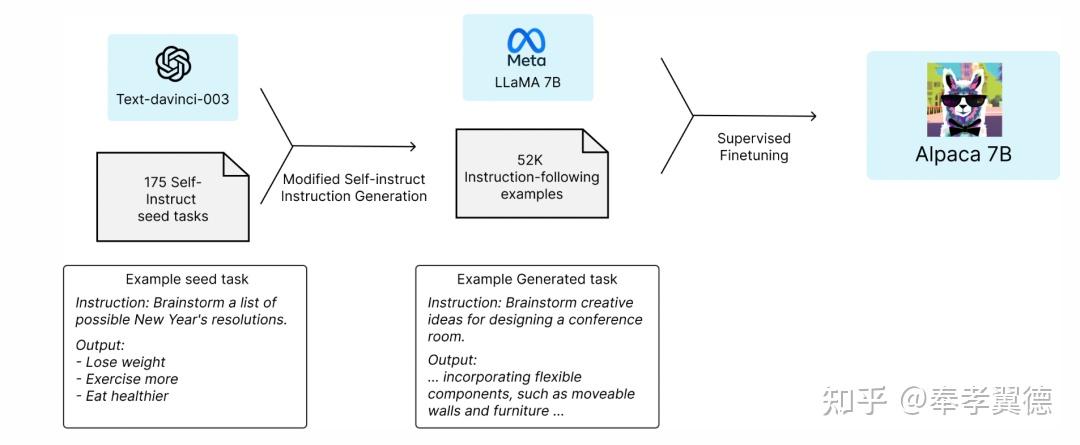
Alpaca是斯坦福大学关于指令跟随语言模型的研究结果,目前,Alpaca只用于学术研究,禁止任何商业使用。
LLaMA


这是一个开放和高效的基础语言模型,具有从70亿到650亿多种规模参数。
LLaMA在数以万亿计的标记上训练而来模型,它的出现证明了,即使是完全使用公开的数据集也能训练出最先进的模型,而不必求助于专有数据集。
实测数据显示,LLaMA-13B在大多数基准测试上都超过了GPT-3,而LLaMA-65B与最好的模型Chinchilla-70B和PaLM-540B相比也有竞争力。
网站目前知道的人不多,资源相对充裕,等候的时间不需要太长,感兴趣的朋友可以自己试试。
访问地址:
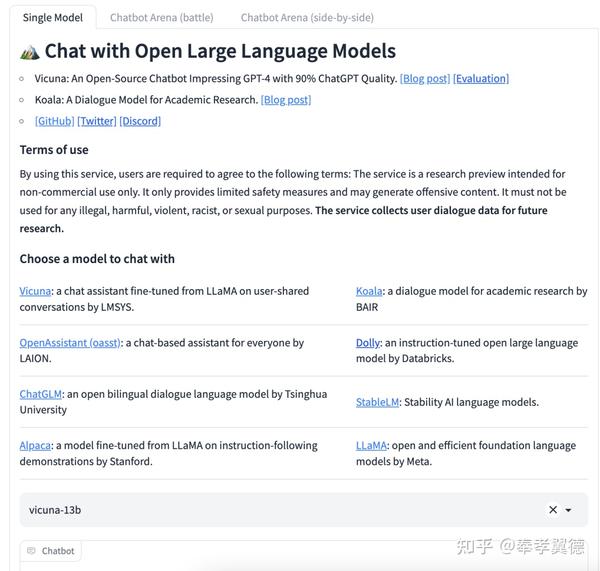
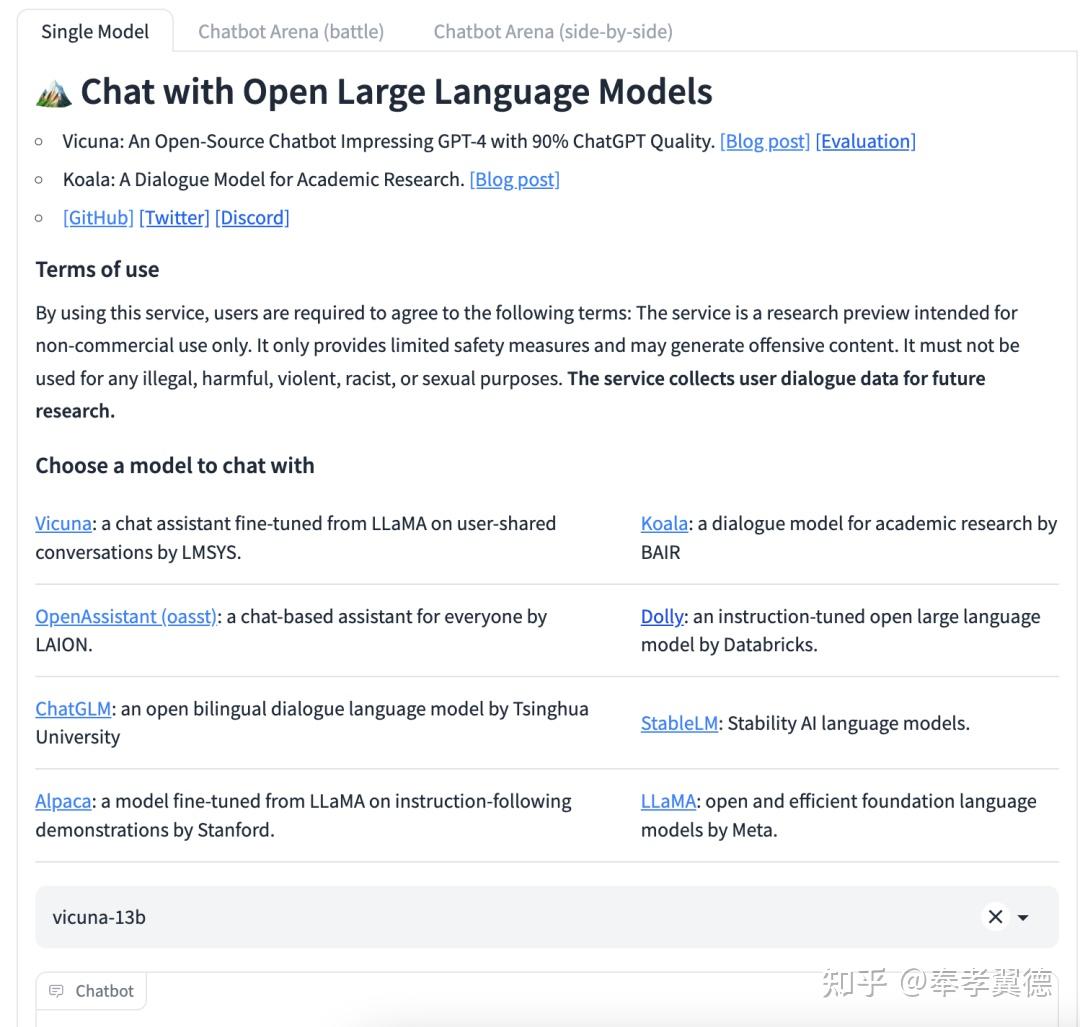
除了单独体验某一个具体的模型,还可以进入对比模式,看看两个模型哪个表现更好。
用户可以做出反馈评价,这可能也有助于模型的优化和迭代。
截止发稿前后,该网站又改版了,将模型PK的模式分成了两种(Battle模式和side-by-side模式):
第一种,Battle模式下,用户事先不知道用的是什么模型,单纯凭模型输出来做评价,评价完之后会显示具体用的是什么模型。
另外一个,side-by-side模式,用户可以自行指定要用的模型,然后对模型进行评价。
前者可以防止特别喜欢或者厌恶某模型的人给出有偏见的评价。
