

一种结合数据增强的电力系统短期电压稳定评估深度学习智能系统



Abstrct
如何使基于深度学习的短期电压稳定性评估(STVSA)模型在小型训练数据集上运行良好是一个具有挑战性和紧迫性的问题。
本文提出了一种新型的用于电力系统STVSA的深度学习智能系统。首先,由于没有可靠的量化标准来判断特定电力系统的稳定状态,利用半监督聚类学习在原始小数据集中获得标记样本。其次,为了使深度学习适用于小数据集,引入了基于条件最小二乘生成对抗网络(LSGAN)的数据扩充,通过人工生成额外的有效样本来扩展原始数据集。第三,为了从系统的扰动后动态轨迹中提取时间依赖关系,建立了基于注意机制的双向门控循环单元评估模型,双向学习重要的时间依赖关系并自动分配注意权重。
测试结果表明,所提出的方法能够通过原始小数据集实现更好的准确性和更快的响应时间。
Ⅰ Introduction
短期电压稳定性评估(STVSA)一直被视为保障电力系统安全稳定运行的关键任务。电力系统的短期电压稳定性(STVS)是指母线电压在受到较大扰动后迅速恢复到可接受水平的能力。由于输电能力接近于极限,并且可再生能源固有的可变性和不确定性,这都对电压稳定性提出了新的挑战。因此,如何准确的、及时的检测电力系统的STVS转态已经成为了一个具有挑战性和紧迫的问题。
在这项工作中,具有注意机制的双向门控循环单元(BiGRU-Attention)被用于捕获 STVSA 的后扰动系统动力学中的时间依赖性。众所周知,与传统的浅层机器学习方法相比,获取大量训练数据是确保深度学习算法作为大数据智能的核心,能够有效地学习复杂数据分布特征的关键前提。由于缺乏统一可靠的标准,获取具有准确标注的大规模、平衡的数据难度大、代价高,加上数据标注、训练数据收集本身在实际应用中昂贵且费力,这构成了开发高性能的基于深度学习的STVSA模型在实际应用中的重要障碍。鉴于此,训练一个深度学习模型,使其能够很好地处理STVSA领域的小数据,具有重要的意义。不幸的是,据作者所知,到目前为止还没有专门解决这个问题的研究。
对于STVSA而言,有两种不同的方法来收集大量的训练数据:事故模拟和数据增强。虽然可以通过事故模拟直接产生足够大的数据集,但数据扩充是一个优越且不可替代的命题。与繁琐、复杂和低效的事故模拟相比,数据扩充提供了一种低成本和高效的方法。本文提出了一种基于LSGAN的深度对抗性数据增强技术,使得基于BiGRU注意力的STVSA模型能够适用于较小的训练数据集。
本文最重要的贡献可突出如下:
1、提出了一种基于LSGAN的数据扩充和基于BiGRU的注意力评估模型相结合的深度学习智能系统,称为深度LSGAN-BiGRU-Attention Network(DLBAN)。
2、通过利用数据扩充,所提出的基于深度学习的评估模型能够很好地处理小训练数据集,这是电力系统稳定分析领域的一种新方法。
3、为了充分捕捉电力系统输入扰动后动态轨迹的时态相关性,利用BiGRU-Attention从正向和反向提取潜在信息,其中注意机制通过根据输入信息的重要性自动分配注意力来提高特征学习能力。
4、由于STVSA领域没有可靠的定量标准,采用半监督模糊c均值(SFCM)来确定不能根据领域知识直观区分稳定状态的样本标签。
5、这项工作使用 AUC、MCC 和 F1-score 等统计指标进行了广泛的统计测试,以全面检查所提出方法的性能。
Ⅱ Semi-Supervised Cluster Learning(半监督集群学习)
在这项研究中,半监督集群学习的目的是标记不同的样本。遗憾的是,到目前为止,还没有统一可靠的标准来确定给定电力系统的STVS,如何有效地标记所有训练数据成为一个瓶颈,这阻碍了数据驱动的STVSA方法在实际电力系统中的应用。
A、Semi-Supervised Fuzzy C-Means Algorithm(半监督模糊C-均值算法)
在这项研究中,SFCM被用来获得所有样本的确切类别标签。对于一个m维的数据 X = { x_j }, 1 ≤ j ≤N ,他被分为c个簇。并且对于每个样本 x_j = ( x_j1 , x_j2 , .... , x_jm )通过模糊隶属度(fuzzy membership)将其划分为S_i, 1≤ i ≤ c。
在半监督学习中,具有精确标签的样本被作为迭代优化过程中的先验知识。SFCM的目标函数如下:
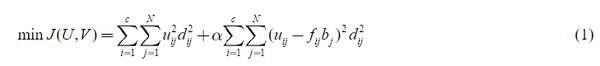

其中 U = [u_ij] 是隶属矩阵,V = (v_1, v_2, ... ,v_c) 是集群中心, d_ij^2 是 x_j 与 v_i的欧氏距离; F = [f_ij] ∈ R c×N 代表监理信息, f_ij 是 u_ij 的先验知识; 公式1的第一项是FCM的目标函数,第二项反映了监督聚类; α > 0 是一个缩放因子,用来衡量给定分类信息的重要性; b = [b_j]' 代表样本x_j是否有已知的类标签, b_j 的条件为:


具体来说,隶属度矩阵表示为 u_ij, 聚类的中心 v_i 如下所示:
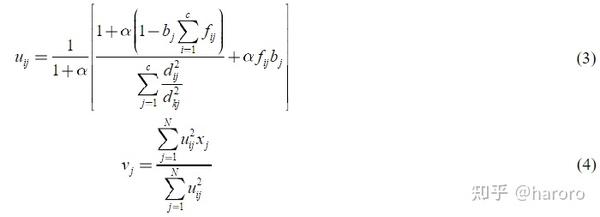

公式3-4由拉格朗日乘子法得到
B、Silhouette Coefficient(轮廓系数)
本文采用轮廓系数(SC)来评价半监督聚类学习算法的性能。SC值越大,聚类性能越好,这意味着同一簇的点更紧凑,不同簇之间的点更分离。SC被定义为:


其中 a_j 表示簇内的紧凑程度, b_j 表示簇间的分离程度。对于数据集 X = { x_j }, 1<j<N,被分为c个簇,记作{S_1, S_2, .... , S_c}, 其中 a_j 代表 x_j 与簇内其他点的平均距离, b_j 代表 x_j 到其他簇的最小平均距离。
Ⅲ DLBAN Framework
针对STVSA,提出了一种结合LSGAN和BiGRU-Attention的深度学习智能系统DLBAN。
A、Least Squares Generative Adversarial Network(最小二乘生成对抗性网络)
与原始GAN相比,LSGAN采用最小二乘损失函数代替Sigmoid交叉熵损失函数作为鉴别器。这样,远离决策边界的样本被惩罚并向边界移动,从而有效地解决了梯度消失的问题。LSGAN的成本函数可表示为:
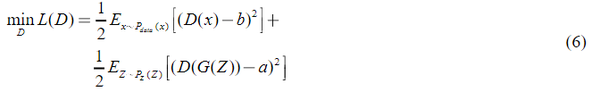

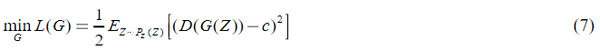

其中 D 是判别器,P_data(x)表示真实的概率分布,G是发生器。
在本文中,使用了一个条件版本的LSGAN,其中类标签通过使用一热编码进行二值化。
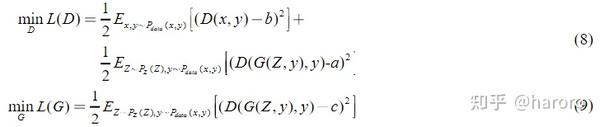

B、BiGRU-Attention
BiGRU可以完全从输入信息中获取前后方向的时间依赖性。为了提高BiGRU的性能,采用了一种注意力机制,对关键隐藏信息进行关注。
1、BiGRU
对于 STVSA,之前和之后的状态都对当前状态下的输出有贡献。因此,在本研究中,BiGRU 通过将前向和后向 GRU 连接在一起,以充分利用前后状态的信息。
2、 Attention Mechanism
注意机制将足够的注意力分配给关键信息并突出重要信息的影响,从而提高准确性。考虑到不同采样时间的系统动态信息对STVSA的贡献程度不同,采用注意力机制更好地衡量提取的隐藏层特征的重要性,并自动为其分配相应的权重。
计算注意力机制的归一化权重的公式可以表述如下:


C、Structure of DLBAN Framework
本文提出的DLBAN框架由2个深度学习算法LSGAN和BiGRU-Attention组成。 DLBAN框架结构如图2所示。
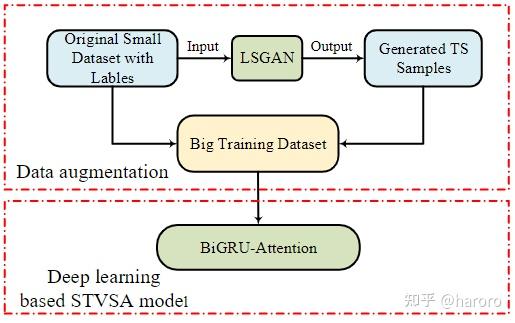

在DLBAN框架中,LSGAN首先在原始小数据集的基础上生成大规模、可靠、平衡且标签准确的数据,不仅增加了训练数据量,而且提高了训练数据的质量。然后,得到一个由生成的样本和原始的小数据集组成的大训练数据集,实现了低成本、高效的数据增强。最后,基于得到的大训练数据集,训练出需要海量训练数据才能有效学习的基于BiGRU-Attention的深度学习模型。通过这种方式,所提出的 DLBAN 框架使得所提出的基于深度学习的 STVSA 模型能够充分发挥其在深度特征挖掘中的强大优势,即使在小数据集的情况下也是如此。
Ⅳ Proposed STVSA Intelligent System
所提出的基于 DLBAN 的 STVSA 智能系统如图 3 所示。
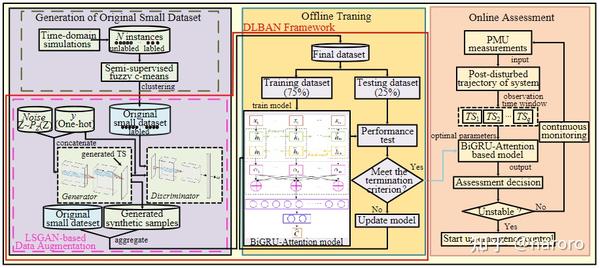

Step1:使用时域模拟(TDS)和 SFCM 生成原始小数据集;
Step2:通过聚合原始小数据集和来自 LSGAN 的人为膨胀的训练集来执行数据增强;
Step3:为离线训练建立 BiGRU-Attention 评估模型;
Step4:BiGRU-Attention评估模型用于在线 STVSA。
A、Generation of Original Small Dataset
在本文中,N 个实例由 TDS 生成,可以表示为:
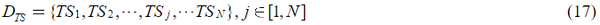

在这个公式中,N 是所有实例的数量。
根据领域知识,图 4 所示的电压轨迹可以直接分为稳定或不稳定。这里,在基于 SFCM 的半监督聚类学习过程中,根据领域知识获得的一部分具有已知标签的样本作为数据标注的先验信息。
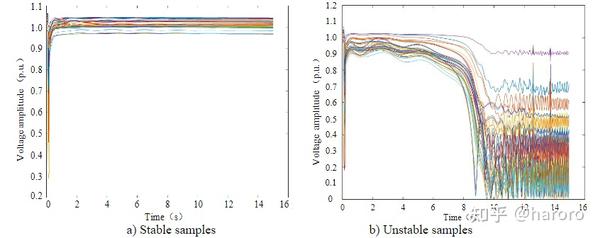

仿真实验


得到一个原始的小数据集,其中所有样本都有类标签。在原始小数据集中,N 个实例的输入 TS 由与 STVS 状态密切相关的 3 个电量组成。本文中,3个量分别为母线电压幅值、有功功率和无功功率(简称U/P/Q),记为:
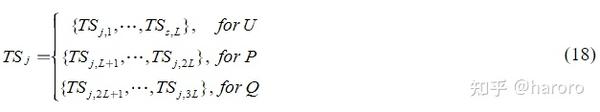

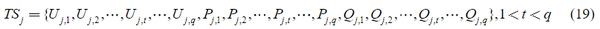

其中 TS_j 是第j个 DTS 样本的 TS_j 集合;L是总线总数; TS_j 的维数为 3L ;这里,每个 TS 的长度是相同的。在 (19) 中,每个 TS 的长度都是相同的,T 是观察时间窗口 (OTW) 的大小,t 表示采样时间, 在本文中 OTW 的长度为 0.03 s 。
B、Data Augmentation
在这项工作中,LSGAN 用于数据增强,在所提出的智能系统中,它作为小数据集和深度学习技术之间的链接起着重要作用。具体而言,数据增强以 TDSs 和 SFCM 获得的原始小数据集为输入,输出海量的高质量标注数据,为训练深度学习分类模型提供必要的数据资源。通过数据增强获得的大训练数据集作为基于 BiGRU-Attention 的评估模型的输入。通过这种方式,数据增强步骤支持本研究中的 STVS 稳定性评估。


C、Offline Training
离线训练阶段基于 BiGRU-Attention 的评估模型的架构如图 6 所示。
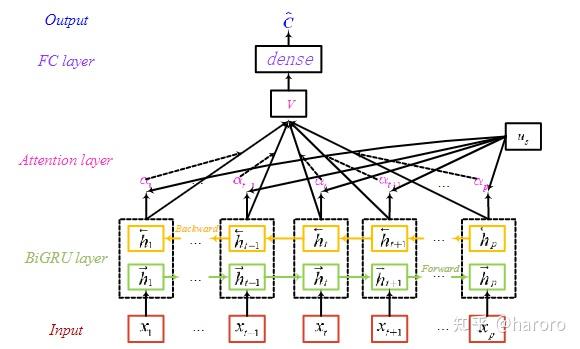

本文使用的BiGRU-Attention模型主要包括5层,分别是输入层、BiGRU层、注意力层、FC层、输出层。
对于每个样本,BiGRU-Attention 模型的输入是由输入特征构成的所有BUS的 TS,在每个采样时刻,它是一个 m 维特征向量,本文采用 Adam 优化器来寻找这些参数的最优值,并使用具有 L2 范数的欧几里德距离作为损失函数。
D、Online Application
在在线应用阶段,实时测量由相位测量单元 (PMU) 收集。一旦获得测量值,它将被输入到评估模型中,该模型通过离线训练获得其最佳参数。然后,可以立即确定系统的 STVS 结果。请注意,在线应用阶段,训练后的模型可以定期更新,以提高所提出的智能系统在各种运行条件下对意外情况的适应性。
E、Evaluation Indicators
为了正确评估基于 LSGAN 的数据增强获得的生成样本的质量和基于 BiGRU-Attention 的评估模型的性能,本文引入了以下评估指标。
1、 Evaluation indicators of data augmentation(数据增强评价指标)
WD、MMD、FID
2、 Evaluation indicators of STVSA model
Accuracy、AUC、MCC、F1-score
Ⅴ Case Study
为了验证所提出方法的有效性和优越性,通过对广泛应用于 STVSA 领域的 新英格兰 39 总线系统 的一系列综合测试进行了检验。
请注意,PMU 数据是使用商业电力系统模拟软件 PSD-BPA 通过详细的 TDS 模拟的。
A、Generation of Original Small Dataset
在这项研究中,使用详细的 TDS 来生成原始的小数据集。为了涵盖不同的突发事件和运行条件,在 TDS 中考虑了各种不同的运行条件,包括故障位置、故障类型、故障清除时间和动态负载的比例。
1、总负荷需求分别设定为基准水平的80%、100%、120%;
2、所有负载均采用由静态ZIP负载和电机负载并联组成的复合负载模型,其中电机负载的比例分别设置为60%、70%、80%和90%;
3、作为本研究采用的故障类型,对每条输电线路施加三相短路故障;
4、短路故障分别设置在某条输电线路的0%、20%、40%、60%、80%;
5、当短路故障发生在 0.1 秒时,故障清除时间在 [0.15 秒,0.2 秒] 范围内变化。
基于上述设置,TDSs得到包含1200个样本的原始小数据集,采样时间为 0.01 s 。通过将数据增强产生的案例添加到原始的小数据集中,得到最终的数据集,总共有 10640 个样本,用于后续分析。本研究将原始小数据集按照3:1的比例随机分为训练数据集和测试数据集。
B、Performance Test of SFCM(SFCM被用来获得所有样本的确切类别标签)
为了检验 SFCM 的有效性,将其与常用的约束分区 k-means (COP-k-means)进行比较。根据轮廓系数,这些半监督聚类学习算法的计算结果如表四所示。
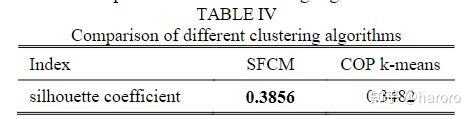

从表IV可以看出,SFCM的SC值高于COP-k-Means的SC值,这表明SFCM可以更好地挖掘数据集中包含的隐藏规则,并可以获得一组更可靠的类别标签。
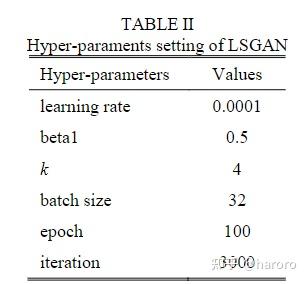
C、Performance Test of LSGAN
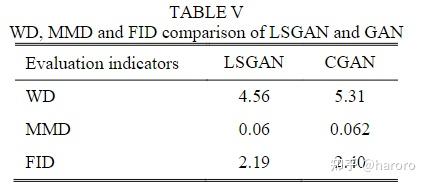
在这一部分中,使用WD、MMD和FID来检验所提出的深度对抗性数据增强在亲和力和多样性方面的性能。此外,为了验证本文所使用的LSGAN的有效性,我们在相同条件下将其与条件GAN(CGAN)进行了比较。此外,为了进行可靠的评估,所有实验都用不同的随机种子进行了3次,平均数如表V所示。

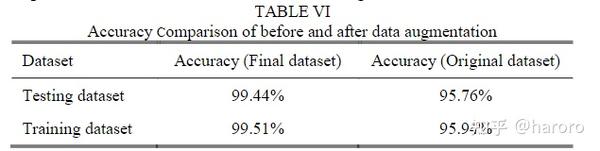

从表VI可以发现,通过基于LSGAN的数据增强,训练和测试的准确率得到了显著提高。这一事实表明,数据增强是一种有效的工具,使所提出的基于深度学习的评估模型能够很好地处理小数据集。
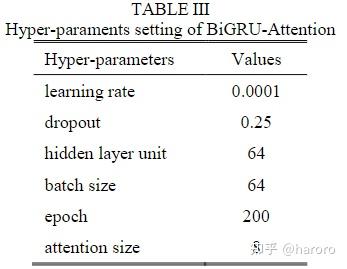
D、Performance Test of BiGRU-Attention Based Model
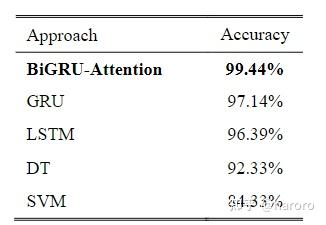
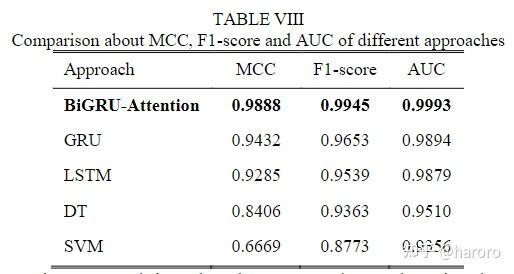
从表7可以看出,BiGRU-注意的准确率最高,GRU和LSTM的准确率也高于DT和支持向量机。这表明,从量化的TS的时间相关性中学习有助于获得高精度。 此外,在本研究中,BiGRU-注意通过双向信息传递和注意机制优于GRU和LSTM。(本文并未做消融实验)

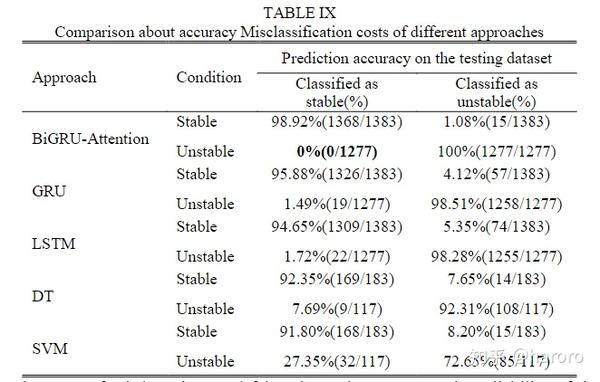

考虑到误检测和误报警的成本,表九验证了所提出方法的可靠性。特别是,该方法的误检率为0%,优于其他方法。
FN:False Negative,被判定为负样本,但事实上是正样本。
FP:False Positive,被判定为正样本,但事实上是负样本。
TN:True Negative,被判定为负样本,事实上也是负样本。
TP:True Positive,被判定为正样本,事实上也是证样本。
E、Computational Efficiency Analysis
考虑到STVS问题是几秒量级的快速现象,快速检测稳定性结果至关重要。此外,考虑到需要在短时间内启动可靠的补救控制,适当的OTW对分类性能具有至关重要的影响。较小的窗口大小将导致快速但不准确的评估;而较大的窗口大小将导致准确但不及时的评估。通过进行灵敏度分析,测试了BiGRU-注意力模型在不同长度的OTWs下的性能,如图7所示。
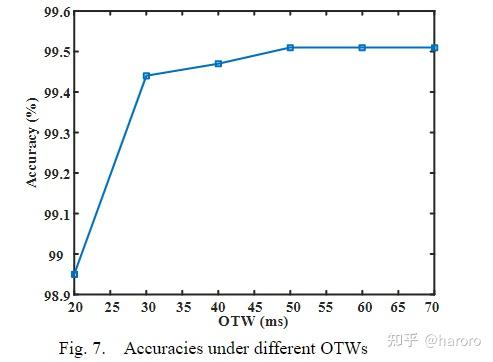

从图7可以观察到,当OTW的长度超过30ms时,基于BiGRU注意的STVSA模型的精度仅略有上升。因此,为了达到评估精度和快速性之间的平衡,OTW长度被选择为30ms,这比现有的其他最先进的方法性能更好,响应时间更短,而不牺牲精度。
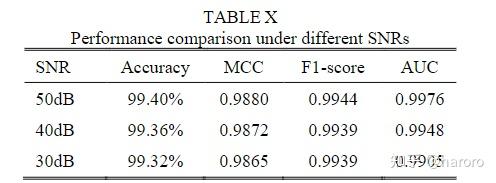
F、Robustness Test under Noisy Environments
由于PMU数据的采集和传输过程中不可避免地存在噪声,因此对该方法在噪声环境下的鲁棒性进行了测试。这里,具有不同信噪比(SNR)的高斯白噪声被添加到PMU数据中,其中SNR越小表示噪声水平越高。

Ⅵ Conclusion
1、如何使基于深度学习的STVSA模型在小训练数据集上运行是一个具有挑战性和迫在眉睫的问题。
2、虽然可以通过事故模拟直接生成足够大的数据集,但通过低成本、高效率地对具有代表性的多样化训练数据集进行人为膨胀,数据扩充是一个优越且不可替代的命题。
有鉴于此,本文提出了一种针对STVSA的深度学习智能系统,并在IEEE 39节点系统上进行了仿真。