我们训练完一个分类模型后,会在测试(验证)集检验模型的性能,涉及到一些模型的评估指标。如:准确率(Accuracy)、混淆矩阵(confusion matrix)、F1-score、ROC曲线、PR曲线等。
我以Softmax回归二分类模型为例,展示一下如何展示模型性能的评估指标,并稍作解读。
需要使用到pandas、scikit-learn、matplotlib库。
分类器的输出结果长什么样子(Softmax为例)
一般我们用测试集的特征数据传给训练好的模型net:
pred_y = net(valid_features_X).detach()
pred_y会长这个样子:
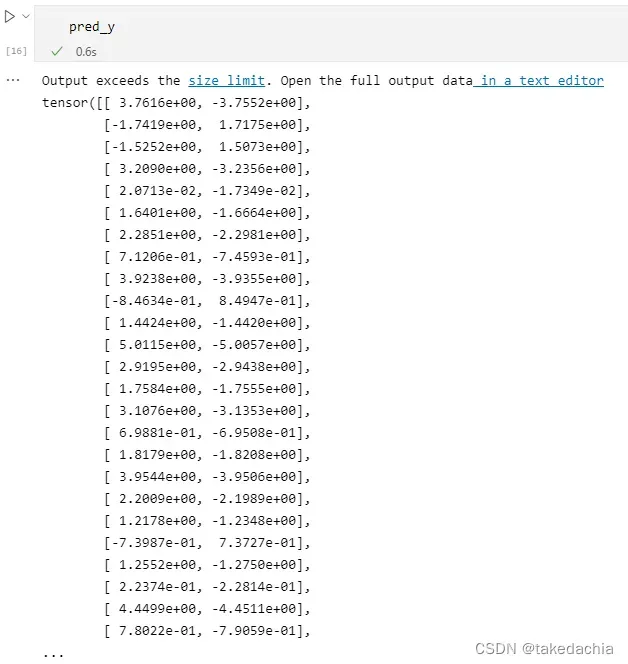
这是个二分类数据,输出的二维向量分别对应了线性层的输出值,代表了两个类别的输出,注意这个输出值
 并没有对其求softmax。
并没有对其求softmax。
因为softmax函数的单调性不变,这个时候对输出
 比较大小就可以判断出应分为哪一类。
比较大小就可以判断出应分为哪一类。
softmax忘了怎么回事的可以复习一下下面这张图:
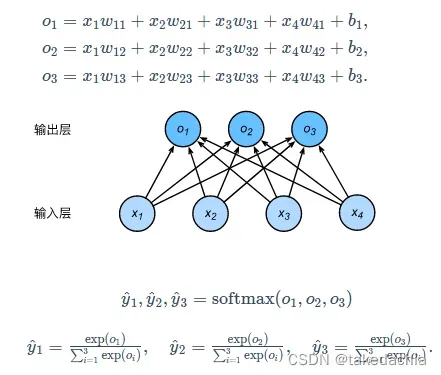
上图中,输出的
 便是对
求softmax后得到的预测概率。
便是对
求softmax后得到的预测概率。
但是如果我们仅作分类预测,比较
 三个值的大小就行了,不用特地求softmax,因为softmax不改变单调性。
三个值的大小就行了,不用特地求softmax,因为softmax不改变单调性。
1 混淆矩阵
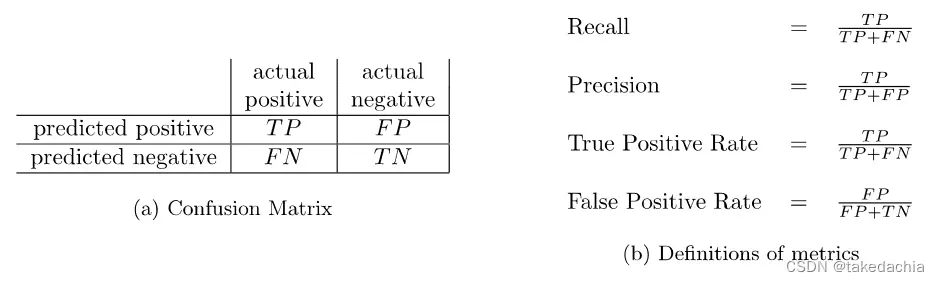
混淆矩阵包含了模型对一个数据集预测结果的综合信息,包含了 真阳TP、假阳FP、假阴FN、真阴TN 4个值,4个值可组合成各种常见的评估指标。
混淆矩阵与常见指标 例图:
准备数据
要画混淆矩阵,需要的数据为 正确的结果 和 预测的结果。
预测的结果:
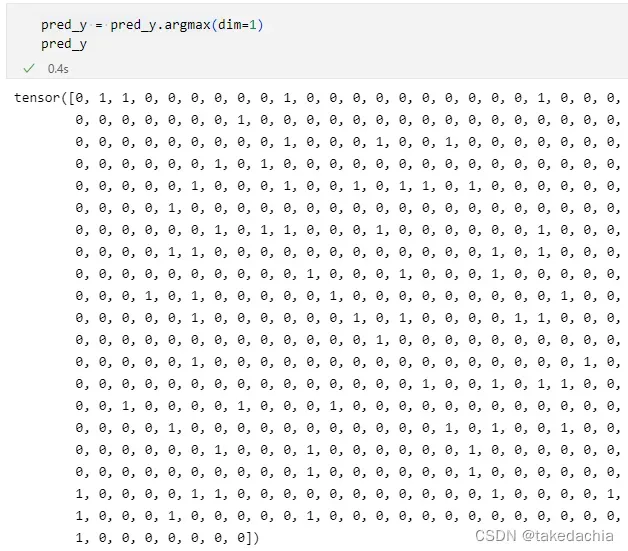
我们先对pred_y求argmax即可获得y的类别(设0为负类,1为正类)
pred_y = pred_y.argmax(dim=1)
绘制
使用pandas的crosstab方法即可绘制,直接把两个tensor传进去:
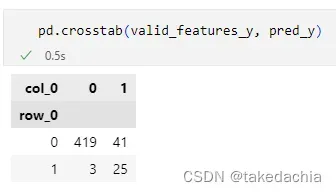
我们可以将pandas的DataFrame的列传进去,这样分类就比较清晰:
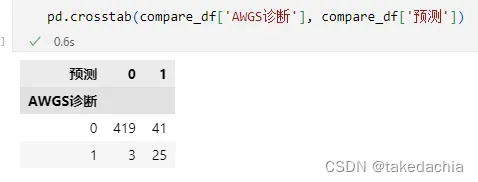
2 F1-score
F1-scores是
precision
(查准率)和
recall
(查全率、敏感性)的调和平均数,可反映小类(少数类)的预测性能,常用于类别不平衡样本的模型预测性能的评估。
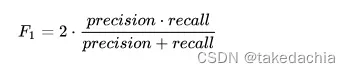
代码:
from sklearn.metrics import f1_score
# 计算 F1 score
report = f1_score(valid_features_y, pred_y)
print(report)
>>> 0.5319148936170213
3 统计综合分类指标(precision、recall等)
我们还可以统计一下分类器的综合指标。
统计的时候,classification_report函数还需要指定一下标签的0、1代表阴性和阳性。
from sklearn.metrics import classification_report
# 统计该模型各个指标
report = classification_report(valid_features_y, pred_y, labels=[0, 1], target_names=['阴性', '阳性'])
print(report)
precision recall f1-score support
阴性 0.99 0.91 0.95 460
阳性 0.38 0.89 0.53 28
accuracy 0.91 488
macro avg 0.69 0.90 0.74 488
weighted avg 0.96 0.91 0.93 488
解读一下:
因为precision(查准率)和recall(查全率)是对于一个指定类别来说的,所以严格来讲阴性和阳性都会有一个precision、recall和对应的f1-score。但由于这是一个类别不平衡数据,阴性占比很大,所以阴性的数据没有多大研究意义。
我们一般研究小类的分类性能,所以就看阳性这一行的precision、recall、f1-score就行了。
maro avg和weighted avg是上面两个类别的数据对应求平均值。
macro avg是算术平均值,weighted avg是权重平均值(两个值各自乘以自身类别数量的占比,再相加)。
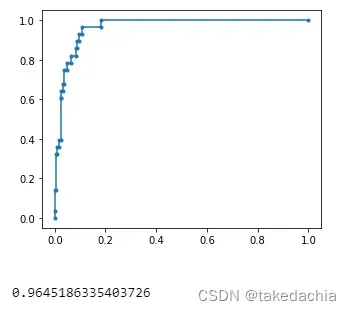
4 ROC曲线
ROC曲线表示了模型的综合分类性能,包括正类和负类。
我们也常用曲线下面积(AUC-ROC)来衡量ROC曲线的质量。
准备数据
但是绘制ROC曲线就需要传入输出类别的预测概率了。
获得0、1两类的预测概率就需要对输出求softmax,得到的就是两个类别各自的概率。
我们只需要正类的概率。代码就是
pred_y_softmax = torch.softmax(pred_y_output, dim=1).numpy()[:,1]
绘制
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
# 给出正类的概率
pred_y_output = net(valid_features_X).detach()
pred_y_softmax = torch.softmax(pred_y_output, dim=1).numpy()[:,1]
# 绘制ROC曲线,计算AUC
fpr, tpr, thresholds_roc = roc_curve(valid_features_y, pred_y_softmax, pos_label=1)
plt.plot(fpr,tpr,marker = '.')
plt.show()
AUC = auc(fpr, tpr)
print(AUC)
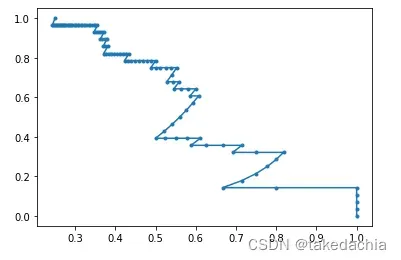
5 PR曲线
PR曲线和 F1-score 一样,是对类别不平衡数据的少数类的分类性能的评估指标。
和ROC曲线一样,需要传入预测概率。
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds_pr = precision_recall_curve(valid_features_y, pred_y_softmax)
plt.plot(precision, recall, marker = '.')
plt.show()
本节代码
可参考我的
Github
。


