 (1)
函数: over()的作用及用法:
--
分区(
分组
)求和。
(1)
函数: over()的作用及用法:
--
分区(
分组
)求和。
sum() over( partition by column1 order by column2 )主要用来对某个字段值进行
逐步累加,连续求和
;
排名函数:
RANK ( ) OVER ( [query_partition_clause] order_by_clause ) --
DENSE_RANK ( ) OVER ( [query_partition_clause] order_by_clause )
可实现按指定的字段分组排序,对于相同分组字段的结果集进行排序,
其中PARTITION BY 为分组字段,ORDER BY 指定排序字段;
RANK()
有排名并列名次的时候会产生不连续的排名编号,
例如数据值 1,2,2,3 排名后发生的编号将是1,2,2,4;
DENSE_RANK() 有并列名次的时候会产生持续的排名编号,例如数据值 1,2,2,3 排名后发生的编号将是1,2,2,3;
over不能单独使用,要和分析函数:rank(),dense_rank(),row_number()/sum() 等一起使用。
其参数:over(partition by columnname1 order by columnname2)
含义:按columname1指定的字段进行分组排序,或者说按字段columnname1的值进行分组排序。
1.例如:employees表中,有两个部门的记录:department_id =10和20
select department_id,rank() over(partition by department_id order by salary) from employees就是指在部门10中进行薪水的排名,在部门20中进行薪水排名。如果是partition by org_id,则是在整个公司内进行排名。(org_id: 公司ID)
2.使用子分区(
分组
)查出各部门薪水连续的总和。注意按部门分区(
分组
)。注意over(...)条件的不同,
sum(sal) over (partition by deptno order by ename) 按部门“连续”求总和
sum(sal) over (partition by deptno) 按部门求总和
sum(sal) over (order by deptno,ename) 不按部门“连续”求总和
sum(sal) over () 不按部门,求所有员工总和,效果等同于sum(sal)。
SQL> break on deptno skip 1 -- 为效果更明显,把不同部门的数据隔段显示。
SQL> select deptno,ename,sal,
2 sum(sal) over (partition by deptno order by ename) 部门连续求和,--各部门的薪水"连续"求和
3 sum(sal) over (partition by deptno) 部门总和, -- 部门统计的总和,同一部门总和不变
4 sum(sal) over (order by deptno,ename) 连续求和, --所有部门的薪水"连续"求和
5 sum(sal) over () 总和, -- 此处sum(sal) over () 等同于sum(sal),所有员工的薪水总和
6 from emp ;
Result :
RANK
( )
OVER
(order by 列名 排序)
的
结果是不连续的
,如果有4个人,其中有3个是并列第1名,那么最后的排序结果结果如:1 1 1 4;
DENSE_RANK( ) OVER(order by 列名 排序)
的结果是连续的
,如果有4个人,其中有3个是并列第1名, 那么最后的排序结果如:1 1 1 2;
1. SELECT COLA ,
RANK
( )
OVER
(order by COLE ASC )
E FROM TABLE_A ;
2. SELECT COLA ,
RANK
( )
OVER
(order by COLE ASC )
E FROM TABLE_A ;
Result :
(3)
--
用row_number() over(partition by column_name1,column_name2 order by column_name3) 去除重复以partition by 所列的column的重复记录
select
*
from
(
select
ID_clo,
key_clo,
clo1,clo2 ,
date_col,
row_number()
over(partition
by ID_clo,key_clo
order
by date_col
desc)
as
desc_rk
from
my_table_name ) t
where t.desc_rk
=
1
常用函数:
1.
Round()
:
[舍入到
最接近
的
日期
],无时分秒; (day:舍入到
最接近
的
星期日
);
select sysdate S1,
round(sysdate) S2 ,
round(sysdate,'year') YEAR,
round(sysdate,'month') MONTH ,
round(sysdate,'day') DAY from dual;
2.
TRUNC()
:
(1)[截断到
最接近的日期
,单位为天] ,返回的是日期类型,无时分秒;
如:
trunc(
sysdate
,
'
month
')
--
返回当前月的1日(月初);
(2) 按照指定的精度截取一个数;
如:
SELECT
TRUNC
(11124.1888,-2) TRUNC1,TRUNC(111124.1888,2) FROM DUAL;
select sysdate S1,
trunc(sysdate) S2, --返回当前日期,无时分秒
trunc(sysdate,'year') YEAR, --返回当前年的1月1日,无时分秒(年初)
trunc(sysdate,'month') MONTH , --返回当前月的1日,无时分秒 (月初)
trunc(sysdate,'day') DAY --返回当前星期的星期天,无时分秒 (星期初,即星期的第一天)
from dual;

SELECT TRUNC(11124.1888,-2) TRUNC1,
TRUNC(111124.1888,2)
FROM DUAL;
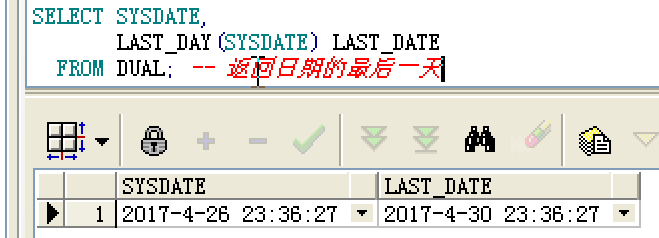
3. LAST_DAY(): 返回日期的最后一天,有时分秒;
SELECT SYSDATE,
LAST_DAY(SYSDATE) LAST_DATE
FROM DUAL; -- 返回日期的最后一天
SELECT
SYSDATE
,
TRUNC(TRUNC(SYSDATE, 'MONTH') - 1, 'MONTH') FIRST_DAY_LAST_MONTH,
TRUNC(SYSDATE, 'MONTH') - 1 / 86400 LAST_DAY_LAST_MONTH,
TRUNC(SYSDATE, 'MONTH') FIRST_DAY_CUR_MONTH,
LAST_DAY(TRUNC(SYSDATE, 'MONTH')) + 1 - 1 / 86400 LAST_DAY_CUR_MONTH,
LAST_DAY(TRUNC(SYSDATE, 'MONTH')) + 1 FIRST_DAY_NEXT_MONTH
FROM DUAL;
4. ADD_MONTHS(): 增加或减去月份
SELECT
SYSDATE,
ADD_MONTHS
(TRUNC(SYSDATE, 'MONTH'), 2),
ADD_MONTHS
(TRUNC(SYSDATE, 'MONTH'), -13)
FROM
DUAL;
5. MONTHS_BETWEEN(date1,date2) :
给出date1-date2的月份(
date1减去date2);
SELECT
SYSDATE,
MONTHS_BETWEEN
(SYSDATE,TO_DATE('20141220', 'YYYY-MM-DD')) MON_BETW1,
MONTHS_BETWEEN
(TO_DATE('20141220', 'YYYY-MM-DD'), SYSDATE) MON_BETW2,
TRUNC(
MONTHS_BETWEEN
(TO_DATE('20141220', 'YYYY-MM-DD'), SYSDATE)) MON_BETW3
FROM
DUAL;
6
.
NEXT_DAY(date,day):
给出日期date和星期x之后计算接下来的最近一个星期x的
日期
。day为1-7或星期日-星期六,1表示星期日
。
next_day(sysdate,6)是从当前开始下一个星期五。后面的数字是从星期日开始算起。
SELECT
SYSDATE,
--当前日期是周四
NEXT_DAY
(SYSDATE, 2) NEXT_DAY1,
--周一对应的日期
NEXT_DAY
(SYSDATE, 7) NEXT_DAY2
--周六对应的日期
FROM
DUAL;
7. extract() : 截取出日期或间隔值的字段值;
SELECT
SYSDATE,
EXTRACT(
HOUR
FROM TIMESTAMP '2017-02-16 11:38:40') "HOUR" ,
EXTRACT(
DAY
FROM SYSDATE) "DAY",
EXTRACT(
MONTH
FROM SYSDATE) "MONTH",
EXTRACT(
YEAR
FROM SYSDATE) "YEAR"
FROM
DUAL ;
SELECT
SYSDATE,
TO_CHAR(SYSDATE, '
HH
'),
TO_CHAR(SYSDATE, '
HH24
')
FROM
DUAL;
8.
CONC
AT(‘a’,'b'): 连接a、b两个字符串;
SELECT
CONCAT
(
CONCAT
('张', '--'), '小姐') AS A,
'张' || '--' || '小姐' AS B
FROM
DUAL;
9. INITCAP():返回字符串并将字符串中每一个单词的首字母变为大写,其他字符小写。单词有空格或非字母的字符隔开;
SELECT
INITCAP
('LAKALA') AS A,
INITCAP
('lakala') AS B,
INITCAP
('la1ka?la') AS C,
INITCAP
('la ka la') AS D,
INITCAP
('la ka3la') AS E
FROM
DUAL;
(转载):
2.1.2 INSTR(C1,C2,I,J)
在一个字符串中搜索指定的字符,返回发现指定的字符的位置;
C1 被搜索的字符串
C2 希望搜索的字符串
I 搜索的开始位置,默认为1
J 出现的位置,默认为1
HR@test>select instr('lakala LAKALA','la',1,1),instr('lakala LAKALA','la',1,2) instring from dual;
INSTR('LAKALALAKALA','LA',1,1) INSTRING
------------------------------ ----------
2.1.3 LENGTH
返回字符串的长度;
SQL> select length(null),length(''),length(' '),length('lakala') from dual;
LENGTH(NULL) LENGTH('') LENGTH('') LENGTH('LAKALA')
------------ ---------- ---------- ----------------
2.1.4 LOWER
返回字符串,并将所有的字符小写
SYS@test> select lower('LaKaLa') from dual;
LOWER('LAKAL
------------
lakala
2.1.5 UPPER
返回字符串,并将所有的字符大写
SYS@test> select upper('LaKaLa') from dual;
UPPER('LAKAL
------------
LAKALA
2.1.6 RPAD和LPAD
(填充字符)RPAD 在列的右边填充字符/LPAD 在列的左边填充字符
SYS@test>select rpad('lakala',10,'#'), lpad('222.111',10,'0')from dual;
RPAD('LAKALA',10,'#' LPAD('222.111',10,'0
-------------------- --------------------
lakala#### 000222.111
2.1.7 LTRIM和RTRIM/ TRIM(s from string)
LTRIM 删除左边出现的字符串,RTRIM 删除右边出现的字符串.
LEADING 剪掉前面的字符
TRAILING 剪掉后面的字符
如果不指定,默认为空格符
SYS@test>select rtrim('#la#ka#la###','#'),ltrim('###la#ka#la#','#'),trim( '#' from '###la#ka#la###') from dual;
RTRIM('#LA#KA#LA## LTRIM('###LA#KA#LA TRIM('#'FROM'###
------------------ ------------------ ----------------
#la#ka#la la#ka#la# la#ka#la
2.1.8 SUBSTR(string,start,count)
取子字符串,从start开始,取count个
SYS@test>select substr('010-56710999',1,4),substr('010-56710999',5,8) from dual;
SUBSTR(' SUBSTR('010-5671
-------- ----------------
010- 56710999
2.1.9 REPLACE(string,s1,s2)
string 希望被替换的字符或变量
s1 被替换的字符串
s2 要替换的字符串
SYS@test>select replace('la#ka#la','#','') from dual;
REPLACE('LA#
------------
lakala
2.2 数字函数
3 ABS
返回指定值的绝对值
SYS@test>select abs(100),abs(-100) from dual;
ABS(100) ABS(-100)
---------- ----------
100 100
3.1.1 FLOOR
对给定的数字取整数
SYS@test>select floor(11.92),floor(-11.02) from dual;
FLOOR(11.92) FLOOR(-11.02)
------------ -------------
11 -12
3.1.2 MOD(n1,n2)
返回一个n1除以n2的余数
SYS@test> select mod(12,3),mod(1,3),mod(2,3) from dual;
MOD(12,3) MOD(1,3) MOD(2,3)
---------- ---------- ----------
0 1 2
3.1.3 ROUND和TRUNC
按照指定的精度进行舍入
SYS@test> select round(11.9),round(-11.4),trunc(11.9),trunc(-11.1) from dual;
ROUND(11.9) ROUND(-11.4) TRUNC(11.9) TRUNC(-11.1)
----------- ------------ ----------- ------------
12 -11 11 -11
3.1.4 SIGN
取数字n的符号,大于0返回1,小于0返回-1,等于0返回0
SYS@test>select sign(12),sign(-12),sign(0) from dual;
SIGN(12) SIGN(-12) SIGN(0)
---------- ---------- ----------
1 -1 0
3.1.5 TRUNC
按照指定的精度截取一个数
SYS@test>select trunc(11124.1888,-2) trunc1,trunc(111124.1888,2) from dual;
TRUNC1 TRUNC(111124.1888,2)
---------- --------------------
11100 111124.18
3.2 转换函数
TO_DATE格式(以时间:2007-11-02 13:45:25为例)
Year:
yy two digits 两位年 显示值:07
yyy three digits 三位年 显示值:007
yyyy four digits 四位年 显示值:2007
Month:
mm number 两位月 显示值:11
mon abbreviated 字符集表示 显示值:11月,若是英文版,显示nov
month spelled out 字符集表示 显示值:11月,若是英文版,显示november
Day:
dd number 当月第几天 显示值:02
ddd number 当年第几天 显示值:02
dy abbreviated 当周第几天简写 显示值:星期五,若是英文版,显示fri
day spelled out 当周第几天全写 显示值:星期五,若是英文版,显示friday
D Day of week (1-7). This element depends on the NLS territory of the session.
Hour:
hh two digits 12小时进制 显示值:01
hh24 two digits 24小时进制 显示值:13
Minute:
mi two digits 60进制 显示值:45
Second:
ss two digits 60进制 显示值:25
其它
Q digit 季度 显示值:4
WW digit 当年第几周 显示值:44
W digit 当月第几周 显示值:1
24小时格式下时间范围为: 0:00:00 - 23:59:59....
12小时格式下时间范围为: 1:00:00 - 12:59:59 ....
4 TO_CHAR(date,format)
SYS@test>select to_char(sysdate,'WW W Q ddd D'),sysdate from dual;
TO_CHAR(SYSDATE,'WWWQDDD SYSDATE
------------------------ -----------------------
11 3 1 076 2 17-MAR-2014 16:53:41
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') as nowTime from dual; //日期转化为字符串
select to_char(sysdate,'yyyy') as nowYear from dual; //获取时间的年
select to_char(sysdate,'mm') as nowMonth from dual; //获取时间的月
select to_char(sysdate,'dd') as nowDay from dual; //获取时间的日
select to_char(sysdate,'hh24') as nowHour from dual; //获取时间的时
select to_char(sysdate,'mi') as nowMinute from dual; //获取时间的分
select to_char(sysdate,'ss') as nowSecond from dual; //获取时间的秒
4.1.1 TO_DATE(string,format)
将字符串转化为ORACLE中的一个日期
4.1.2 TO_NUMBER
将给出的字符转换为数字
SYS@test>select to_number('2014') year from dual;
----------
4.2 Null函数
NVL(expr1, expr2)->expr1为NULL,返回expr2;不为NULL,返回expr1。注意两者的类型要一致.
NVL2 (expr1, expr2, expr3) ->expr1不为NULL,返回expr2;为NULL,返回expr3。expr2和expr3类型不同的话,expr3会转换为expr2的类型 .
NULLIF (expr1, expr2) ->相等返回NULL,不等返回expr1.
5
nvl(ex1,ex2):
ex1值为空则返回ex2,否则返回该值本身ex1(常用)
例:如果雇员没有佣金,将显示0,否则显示佣金
SCOTT@test>select comm,nvl(comm,0) from emp;
COMM NVL(COMM,0)
---------- -----------
300 300
500 500
1400 1400
5.1.1
nvl2(ex1,ex2,ex3) :
如果ex1不为空,显示ex2,否则显示ex3
HR@test>SELECT last_name, salary,
2 NVL2(commission_pct, salary + (salary * commission_pct), salary) income
3 FROM hr.employees
4 WHERE last_name like 'B%'
5 ORDER BY last_name;
LAST_NAME SALARY INCOME
-------------------------------------------------- ---------- ----------
Baer 10000 10000
Baida 2900 2900
Banda 6200 6820
Bates 7300 8395
Bell 4000 4000
Bernstein 9500 11875
Bissot 3300 3300
Bloom 10000 12000
Bull 4100 4100
5.1.2
nullif(ex1,ex2):
值相等返空,否则返回第一个值
HR@test>SELECT e.last_name, NULLIF(e.job_id, j.job_id) "Old Job ID"
2 FROM employees e, job_history j
3 WHERE e.employee_id = j.employee_id
4 ORDER BY last_name, "Old Job ID";
LAST_NAME Old Job ID
-------------------------------------------------- --------------------
De Haan AD_VP
Hartstein MK_MAN
Kaufling ST_MAN
Kochhar AD_VP
Kochhar AD_VP
Raphaely PU_MAN
Taylor SA_REP
Taylor
Whalen AD_ASST
Whalen
5.1.3
coalesce:
返回列表中第一个非空表达式
OE@test>SELECT product_id, list_price, min_price,
2 COALESCE(0.9*list_price, min_price, 5) "Sale"
3 FROM product_information
4 WHERE supplier_id = 102050
5 ORDER BY product_id;
PRODUCT_ID LIST_PRICE MIN_PRICE Sale
---------- ---------- ---------- ----------
1769 48 43.2
1770 73 73
2378 305 247 274.5
2382 850 731 765
3355 5
5.2 其他函数
6 Decode
[实现if ..then 逻辑] 注:第一个是表达式,最后一个是不满足任何一个条件的值
SCOTT@test>select deptno,decode(deptno,10,'1',20,'2',30,'3','??') from dept;
DEPTNO DECO
---------- ----
40 ??
SELECT product_id,
DECODE (warehouse_id, 1, 'Southlake',
2, 'San Francisco',
3, 'New Jersey',
4, 'Seattle',
'Non domestic') "Location"
FROM oe.inventories
WHERE product_id < 1775
ORDER BY product_id, "Location";
PRODUCT_ID Location
---------- --------------------------
1729 New Jersey
1729 Non domestic
1729 Non domestic
1729 Non domestic
1729 Non domestic
1729 Non domestic
1733 New Jersey
1733 Non domestic
1733 Non domestic
1733 Non domestic
1733 Non domestic
1733 Non domestic
1733 San Francisco
1733 Seattle
1733 Southlake
1734 New Jersey
6.1.1 Case
[实现switch ..case 逻辑]注:CASE语句在处理类似问题就显得非常灵活。当只是需要匹配少量数值时,用Decode更为简洁。
OE@test>SELECT cust_last_name,
2 CASE credit_limit WHEN 100 THEN 'Low'
3 WHEN 5000 THEN 'High'
4 ELSE 'Medium' END AS credit
5 FROM customers
6 ORDER BY cust_last_name, credit;
CUST_LAST_NAME CREDIT
---------------------------------------- ------------
Adjani Medium
Adjani Medium
Alexander Medium
Alexander Medium
Altman High
Altman Medium
Altman Medium
Andrews Medium
Andrews Medium
Ashby High
Ashby High
Aykroyd Medium
Baldwin Medium
7 聚合函数
8
Rollup/cube
rollup 按分组的第一个列进行统计和最后的小计
cube 按分组的所有列的进行统计和最后的小计
SCOTT@test>select deptno,job ,sum(sal) from emp group by deptno,job;
DEPTNO JOB SUM(SAL)
---------- ------------------ ----------
20 CLERK 1900
30 SALESMAN 5600
20 MANAGER 2975
30 CLERK 950
10 PRESIDENT 1000
30 MANAGER 2850
10 CLERK 1000
10 MANAGER 1000
20 ANALYST 6000
SCOTT@test>select deptno,job ,sum(sal) from emp group by rollup(deptno,job);
DEPTNO JOB SUM(SAL)
---------- ------------------ ----------
10 CLERK 1000
10 MANAGER 1000
10 PRESIDENT 1000
10 3000
20 CLERK 1900
20 ANALYST 6000
20 MANAGER 2975
20 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
30 9400
23275
SCOTT@test>select deptno,job ,sum(sal) from emp group by rollup(job,deptno);
DEPTNO JOB SUM(SAL)
---------- ------------------ ----------
10 CLERK 1000
20 CLERK 1900
30 CLERK 950
CLERK 3850
20 ANALYST 6000
ANALYST 6000
10 MANAGER 1000
20 MANAGER 2975
30 MANAGER 2850
MANAGER 6825
30 SALESMAN 5600
SALESMAN 5600
10 PRESIDENT 1000
PRESIDENT 1000
23275
cube 产生组内所有列的统计和最后的小计
SCOTT@test>select deptno,job ,sum(sal) from emp group by cube(deptno,job);
DEPTNO JOB SUM(SAL)
---------- ------------------ ----------
23275
CLERK 3850
ANALYST 6000
MANAGER 6825
SALESMAN 5600
PRESIDENT 1000
10 3000
10 CLERK 1000
10 MANAGER 1000
10 PRESIDENT 1000
20 10875
20 CLERK 1900
20 ANALYST 6000
20 MANAGER 2975
30 9400
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
8.1.1 AVG(DISTINCT|ALL)
all表示对所有的值求平均值,distinct只对不同的值求平均值
HR@test>SELECT AVG(salary) "Average"
2 FROM employees;
Average
----------
6461.83178
8.1.2 MAX(DISTINCT|ALL)
求最大值,ALL表示对所有的值求最大值,DISTINCT表示对不同的值求最大值,相同的只取一次
HR@test>SELECT MAX(salary) "Maximum"
2 FROM employees;
Maximum
----------
24000
8.1.3 MIN(DISTINCT|ALL)
求最小值,ALL表示对所有的值求最小值,DISTINCT表示对不同的值求最小值,相同的只取一次
HR@test>SELECT MIN(hire_date) "Earliest"
2 FROM employees;
Earliest
-----------------------
13-JAN-2001 00:00:00
8.1.4 COUNT
功能描述:对一组内发生的事情进行累积计数,如果指定*或一些非空常数,count将对所有行计数,如果指定一个表达式,count返回表达式非空赋值的计数,当有相同值出现时,这些相等的值都会被纳入被计算的值;可以使用DISTINCT来记录去掉一组中完全相同的数据后出现的行数。.
整个结果集是一个组
1) 求部门30 的最高工资,最低工资,平均工资,总人数,有工作的人数,工种数量及工资总和
SCOTT@test> select max(ename),max(sal),
2 min(ename),min(sal),
3 avg(sal),
4 count(*) ,count(job),count(distinct(job)) ,
5 sum(sal) from emp where deptno=30;
MAX(ENAME) MAX(SAL) MIN(ENAME) MIN(SAL) AVG(SAL) COUNT(*) COUNT(JOB) COUNT(DISTINCT(JOB)) SUM(SAL)
-------------------- ---------- -------------------- ---------- ---------- ---------- ---------- -------------------- ----------
WARD 2850 ALLEN 950 1566.66667 6 6 3 9400
9 分析函数
9.1 分析函数语法:
analytic_function
([ arguments ])
OVER
([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
例:
sum(sal) over (partition by deptno order by ename) new_alias
sum就是函数名,(sal)是分析函数的参数,每个函数有0~3个参数,参数可以是表达式,例如:sum(sal+comm),over 是一个关键字,
用于标识分析函数
,否则查询分析器不能区别sum()聚集函数和sum()分析函数,partition
by deptno 是可选的分区子句,如果不存在任何分区子句,则全部的结果集可看作一个单一的大区。order by ename
是可选的order by
子句,有些函数需要它,有些则不需要.依靠已排序数据的那些函数,如:用于访问结果集中前一行和后一行的LAG和LEAD,必须使用,其它函数,如AVG,则不需要.在使用了任何排序的开窗函数时,该子句是强制性的,它指定了在计算分析函数时一组内的数据是如何排序的.
10 FUNCTION子句
ORACLE提供了26个分析函数,按功能分5类
分析函数分类
等级(ranking)
函数
:用于寻找前N种查询
开窗(windowing)
函数
:用于计算不同的累计,如
SUM,COUNT,AVG,MIN,MAX
等,作用于数据的一个窗口上
例:
sum(t.sal) over (order by t.deptno,t.ename) running_total,
sum(t.sal) over (partition by t.deptno order by t.ename) department_total
制表(reporting)
函数
:与开窗函数同名,作用于
一个分区或一组上的所有列
例:
sum(t.sal) over () running_total2,
sum(t.sal) over (partition by t.deptno ) department_total2
制表函数与开窗函数的关键不同之处在于OVER
语句上缺少一个ORDER BY
子句!
LAG,LEAD
函数
:这类函数允许在结果集中向前或向后检索值,为了避免数据的自连接,它们是非常用用的.
VAR_POP,VAR_SAMP,STDEV_POPE
及线性的衰减函数
:计算任何未排序分区的统计值
Oracle 11g的分析函数
AVG *
CORR *
COUNT *
COVAR_POP *
COVAR_SAMP *
CUME_DIST
DENSE_RANK
FIRST
FIRST_VALUE *
LAST_VALUE *
LISTAGG
MAX *
MIN *
NTH_VALUE *
NTILE
PERCENT_RANK
PERCENTILE_CONT
PERCENTILE_DISC
RATIO_TO_REPORT
REGR_ (Linear Regression) Functions *
ROW_NUMBER
STDDEV *
STDDEV_POP *
STDDEV_SAMP *
SUM *
VAR_POP *
VAR_SAMP *
VARIANCE *
10.1.1 PARTITION子句
按照表达式分区(就是
分组
),如果省略了分区子句,则全部的结果集被看作是一个单一的组
10.1.2 ORDER BY子句
分析函数中ORDER BY的存在将添加一个
默认的开窗子句
,这意味着计算中所使用的行的集合是当前分区中当前行和前面所有行,
没有
ORDER BY
时
,
默认的窗口是全部的分区
在Order by 子句后可以添加
nulls last
,如:order by comm desc nulls last 表示排序时忽略comm列为空的行.
10.1.3 WINDOWING子句
用于定义分析函数将在其上操作的行的集合
Windowing子句给出了一个
定义变化或固定的数据窗口
的方法,分析函数将对这些数据进行操作.默认的窗口是一个固定的窗口,仅仅在一组的第一行开始,一直继续到当前行,要使用窗口,必须使用ORDER BY子句.根据2个标准可以建立窗口:
数据值的范围
(RANGES)或与当前行的
行偏移量
.
5)Rang
窗口
RANGE窗口仅对NUMBERS和DATES起作用,因为不可能从VARCHAR2中增加或减去N个单元
另外的限制是ORDER BY中只能有一列,因而范围实际上是一维的,不能在N维空间中
6)Row
窗口
利用ROW分区,就没有RANGE分区那样的限制了,数据可以是任何类型,且ORDER BY 可以包括很多列
7)Specifying
窗口
UNBOUNDED PRECEDING:这个窗口从当前分区的每一行开始,并结束于正在处理的当前行
CURRENT ROW:该窗口从当前行开始(并结束)
Numeric Expression PRECEDING:对该窗口从当前行之前的数字表达式(Numeric Expression)的行开始,对RANGE来说,从行序值小于数字表达式的当前行的值开始.
Numeric Expression FOLLOWING:该窗口在当前行Numeric Expression行之后的行终止(或开始),且从行序值大于当前行Numeric Expression行的范围开始(或终止)
rows between 100 preceding and 100 following:当前行100前,当前后100后
over(order by salary) 按照salary排序进行累计,order by是个默认的开窗函数
over(partition by deptno)按照部门分区
over(order by salary
range
between 50 preceding and 150 following)
每行对应的数据窗口是之前行幅度值不超过50,之后行幅度值不超过150 范围[
current_value-50, current_value+150]
over(order by salary
rows
between 50 preceding and 150 following)
每行对应的数据窗口是之前50行,之后150行
over(order by salary rows between unbounded preceding and unbounded following)
每行对应的数据窗口是从第一行到最后一行,等效:
over(order by salary range between unbounded preceding and unbounded following)
注意
:
分析函数允许你对一个数据集进排序和筛选
,
这是
SQL
从来不能实现的
.
除了最后的
Order by
子句之外
,
分析函数是在查询中执行的最后的操作集
,
这样的话
,
就不能直接在谓词中使用分析函数
,
即不能在上面使用
where
或
having
子句
!!!
10.2 排名
Oracle从8i开始就提供了3个排名函数:rand,dense_rank,row_number
Rank,Dense_rank,Row_number函数为每条记录产生一个从1开始至N的自然数,N的值可能小于等于记录的总数。这3个函数的唯一区别在于当碰到相同数据时的排名策略。
①
ROW_NUMBER
:
Row_number函数返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
②
DENSE_RANK
:
Dense_rank函数返回一个唯一的值,除非当碰到相同数据时,此时所有相同数据的排名都是一样的。
③
RANK
:
Rank函数返回一个唯一的值,除非遇到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
SELECT department_id, last_name, salary,
RANK() OVER (PARTITION BY department_id ORDER BY salary) RANK,
DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary) DENSE_RANK,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary) ROW_NUMBER
FROM employees WHERE department_id = 50
ORDER BY RANK, last_name;
DEPARTMENT_ID LAST_NAME SALARY
RANK
DENSE_RANK
ROW_NUMBER
------------- --------------- ---------- ---------- ---------- ----------
50 Olson 2100 1 1 1
50 Markle 2200 2 2 2
50 Philtanker 2200 2 2 3
50 Gee 2400 4 3 4
50 Landry 2400 4 3 5
50 Marlow 2500 6 4 6
50 Vargas 2500 6 4 7
50 Sullivan 2500 6 4 8
50 Perkins 2500 6 4 9
50 Patel 2500 6 4 10
50 OConnell 2600 11 5 11
50 Grant 2600 11 5 12
50 Matos 2600 11 5 13
50 Seo 2700 14 6 14
50 Mikkilineni 2700 14 6 15
50 Geoni 2800 16 7 16
50 Atkinson 2800 16 7 17
50 Jones 2800 16 7 18
请注意上面的绿色高亮部分,这里生动的演示了3种不同的排名策略:
Dense_rank
Row_number
不同值排名
1,2,3,4,…..
1,2,3,4,…..
1,2,3,4,…..
有相同值排名
1,2,2,4,4,…..
1,2,2,3,3,…..
1,2,3,4,5…..
比较上面3种不同的策略,我们在选择的时候就要根据客户的需求来定夺了:
①假如只需要指定数目的记录,那么采用row_number是最简单的,但有漏掉的记录的危险
②假如需要所有达到排名水平的记录,那么采用rank或dense_rank是不错的选择。至于选择哪一种则看客户的需要,选择dense_rank或得到最大的记录
10.3 First/Last
功能描述:从DENSE_RANK返回的集合中取出排在最前面的一个值的行(可能多行,因为值可能相等),因此完整的语法需要在开始处加上一个集合函数以从中取出记录
SAMPLE:下面例子中DENSE_RANK按部门分区,再按佣金commission_pct排序,FIRST取出佣金最低的对应的所有行,然后前面的MIN函数从这个集合中取出薪水最低的值;LAST取出佣金最高的对应的所有行,然后前面的MAX函数从这个集合中取出薪水最高的值
SELECT last_name, department_id, salary,
MIN(
salary) KEEP (DENSE_RANK FIRST ORDER BY commission_pct)
OVER (PARTITION BY department_id) "Worst",
MAX(salary) KEEP (DENSE_RANK LAST ORDER BY commission_pct)
OVER (PARTITION BY department_id) "Best"
FROM employees
ORDER BY department_id, salary, last_name;
LAST_NAME DEPARTMENT_ID SALARY Worst Best
--------------- ------------- ---------- ---------- ----------
Whalen 10 4400 4400 4400
Fay 20 6000 6000 13000
Hartstein 20 13000 6000 13000
Colmenares 30 2500 2500 11000
Himuro 30 2600 2500 11000
Tobias 30 2800 2500 11000
Baida 30 2900 2500 11000
Khoo 30 3100 2500 11000
Raphaely 30 11000 2500 11000
Mavris 40 6500 6500 6500
Olson 50 2100 2100 8200
Markle 50 2200 2100 8200
Philtanker 50 2200 2100 8200
10.4 ntile
将列值分为几个等级。
HR@test>SELECT last_name, salary, NTILE(4) OVER (ORDER BY salary DESC) AS quartile
2 FROM employees
3 WHERE department_id = 100
4 ORDER BY quartile;
LAST_NAME SALARY QUARTILE
--------------- ---------- ----------
Greenberg 12008 1
Faviet 9000 1
Chen 8200 2
Urman 7800 2
Sciarra 7700 3
Popp 6900 4
10.5 first_value/last_value:
功能描述:返回组中数据窗口的第一个值。
SAMPLE:下面例子计算80部门分区按薪水排序的数据窗口的第一个值对应的名字,如果薪水的第一个值有多个,则从多个对应的名字中取缺省排序的第一个名字
SELECT department_id, last_name, salary,
FIRST_VALUE(last_name) OVER (ORDER BY salary ROWS UNBOUNDED
PRECEDING) AS lowest_sal,last_VALUE(last_name) OVER (ORDER BY salary
range between unbounded preceding and unbounded following) AS great_sal
FROM (SELECT * FROM employees
WHERE department_id = 80
ORDER BY employee_id)
ORDER BY salary;
DEPARTMENT_ID LAST_NAME SALARY LOWEST_SAL GREAT_SAL
------------- --------------- ----------
--------------------------------------------------
--------------------------------------------------
80 Kumar 6100 Kumar Russell
80 Banda 6200 Kumar Russell
80 Johnson 6200 Kumar Russell
80 Ande 6400 Kumar Russell
80 Lee 6800 Kumar Russell
80 Russell 14000 Kumar Russell
10.6 lag、lead
功能描述:可以访问结果集中的其它行而不用进行自连接。它允许去处理游标,就好像游标是一个数组一样。在给定组中可参考当前行之前的行,这样就可以从组中与当前行一起选择以前的行。Offset是一个正整数,其默认值为1,若索引超出窗口的范围,就返回默认值(默认返回的是组中第一行),其相反的函数是LEAD
HR@test>select first_name,last_name,hire_date,
lag(hire_date,1,'1987-01-01') over(order by hire_date) as
prev_hire_date,hire_date-lag(hire_date,1,'1987-01-01') over(order by
hire_date) as days_between_hires from hr.employees order by hire_date;
FIRST_NAME LAST_NAME HIRE_DATE PREV_HIRE_ DAYS_BETWEEN_HIRES
---------------------------------------- --------------- ---------- ---------- ------------------
Lex De Haan 2001-01-13 1987-01-01 5126
Susan Mavris 2002-06-07 2001-01-13 510
Hermann Baer 2002-06-07 2002-06-07 0
Shelley Higgins 2002-06-07 2002-06-07 0
William Gietz 2002-06-07 2002-06-07 0
Daniel Faviet 2002-08-16 2002-06-07 70
Nancy Greenberg 2002-08-17 2002-08-16 1
Den Raphaely 2002-12-07 2002-08-17 112
Payam Kaufling 2003-05-01 2002-12-07 145
Alexander Khoo 2003-05-18 2003-05-01 17
Steven King 2003-06-17 2003-05-18 30
Renske Ladwig 2003-07-14 2003-06-17 27
Jennifer Whalen 2003-09-17 2003-07-14 65
10.7 RATIO_TO_REPORT
HR@test>HR@test>SELECT last_name, salary, RATIO_TO_REPORT(salary) OVER () AS rr
2 FROM employees
3 WHERE job_id = 'PU_CLERK'
4 ORDER BY last_name, salary, rr;
LAST_NAME SALARY RR
--------------- ---------- ----------
Baida 2900 .208633094
Colmenares 2500 .179856115
Himuro 2600 .18705036
Khoo 3100 .223021583
Tobias 2800 .201438849
10.8 AVG /count/sum
功能描述:用于计算一个组和数据窗口内表达式的平均值。
SAMPLE:下面的例子中列c_mavg计算员工表中每个员工的平均薪水报告,该平均值由当前员工和与之具有相同经理的前一个和后一个三者的平均数得来;
OE@test>OE@test>SELECT manager_id, last_name, hire_date, salary,
2 AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date
3 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS c_mavg
4 FROM employees;
MANAGER_ID LAST_NAME HIRE_DATE SALARY C_MAVG
---------- --------------- ----------------------- ---------- ----------
100 De Haan 13-JAN-2001 00:00:00 17000 14000
100 Raphaely 07-DEC-2002 00:00:00 11000 11966.6667
100 Kaufling 01-MAY-2003 00:00:00 7900 10633.3333
100 Hartstein 17-FEB-2004 00:00:00 13000 9633.33333
100 Weiss 18-JUL-2004 00:00:00 8000 11666.6667
100 Russell 01-OCT-2004 00:00:00 14000 11833.3333
100 Partners 05-JAN-2005 00:00:00 13500 13166.6667
100 Errazuriz 10-MAR-2005 00:00:00 12000 11233.3333
100 Fripp 10-APR-2005 00:00:00 8200 12400
100 Kochhar 21-SEP-2005 00:00:00 17000 10566.6667
100 Vollman 10-OCT-2005 00:00:00 6500 11500
100 Cambrault 15-OCT-2007 00:00:00 11000 7766.66667
100 Mourgos 16-NOV-2007 00:00:00 5800 9100
100 Zlotkey 29-JAN-2008 00:00:00 10500 8150
101 Baer 07-JUN-2002 00:00:00 10000 11004
101 Higgins 07-JUN-2002 00:00:00 12008 9502.66667
SAMPLE:下面例子中计算每个员工在按薪水排序中当前行附近薪水在[n-50,n+150]之间的行数,n表示当前行的薪水
例如,Philtanker的薪水2200,排在他之前的行中薪水大于等于2200-50的有1行,排在他之后的行中薪水小于等于2200+150的行没有,所以count计数值cnt3为2(包括自己当前行);cnt2值相当于小于等于当前行的SALARY值的所有行数
OE@test>SELECT last_name, salary, COUNT(*) OVER () AS
cnt1,COUNT(*) OVER (ORDER BY salary) AS cnt2,COUNT(*) OVER (ORDER BY
salary RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING) AS cnt3 FROM
employees;
LAST_NAME SALARY CNT1 CNT2 CNT3
--------------- ---------- ---------- ---------- ----------
Olson 2100 107 1 3
Philtanker 2200 107 3 2
Markle 2200 107 3 2
Landry 2400 107 5 8
Gee 2400 107 5 8
Perkins 2500 107 11 10
Colmenares 2500 107 11 10
Patel 2500 107 11 10
Vargas 2500 107 11 10
Sullivan 2500 107 11 10
Marlow 2500 107 11 10
OConnell 2600 107 15 6
Grant 2600 107 15 6
Himuro 2600 107 15 6
Matos 2600 107 15 6
Mikkilineni 2700 107 17 6
Seo 2700 107 17 6
Tobias 2800 107 21 7
Geoni 2800 107 21 7
Atkinson 2800 107 21 7
Jones 2800 107 21 7
Baida 2900 107 24 5
11 其它问题
12 null排序的处理
SCOTT@test>select empno,ename,mgr,sal,comm from emp order by comm desc nulls last;
EMPNO ENAME MGR SAL COMM
---------- -------------------- ---------- ---------- ----------
7654 MARTIN 7698 1250 1400
7521 WARD 7698 1250 500
7499 ALLEN 7698 1600 300
7844 TURNER 7698 1500 0
7788 SCOTT 7566 3000
7839 KING 1000
7876 ADAMS 7788 1100
7900 JAMES 7698 950
7902 FORD 7566 3000
7934 MILLER 7782 1000
7698 BLAKE 7839 2850
7566 JONES 7839 2975
7369 SMITH 7902 800
7782 CLARK 7839 1000
SCOTT@test>select empno,ename,mgr,sal,comm from emp order by comm; ---默认
EMPNO ENAME MGR SAL COMM
---------- -------------------- ---------- ---------- ----------
7844 TURNER 7698 1500 0
7499 ALLEN 7698 1600 300
7521 WARD 7698 1250 500
7654 MARTIN 7698 1250 1400
7788 SCOTT 7566 3000
7839 KING 1000
7876 ADAMS 7788 1100
7900 JAMES 7698 950
7902 FORD 7566 3000
7934 MILLER 7782 1000
7698 BLAKE 7839 2850
7566 JONES 7839 2975
7369 SMITH 7902 800
7782 CLARK 7839 1000
12.1.1 count中null 的处理
count(*)null值在内所有行
count(comssion_pct) 不包括null值
OE@test>select
count(*),count(commission_pct),avg(commission_pct),sum(commission_pct)/count(commission_pct)
from hr.employees;
COUNT(*) COUNT(COMMISSION_PCT) AVG(COMMISSION_PCT) SUM(COMMISSION_PCT)/COUNT(COMMISSION_PCT)
---------- --------------------- ------------------- -----------------------------------------
107 35 .222857143 .222857143
13 LISTAGG
LISTAGG
(
measure_expr [, 'delimiter'])
WITHIN GROUP
(order_by_clause) [
OVER
query_partition_clause]
按照order by 的排序,顺序连接measure_expr列的值,delimiter 缺省为null
HR@test>SELECT LISTAGG(last_name, '; ')
2 WITHIN GROUP (ORDER BY hire_date, last_name) "Emp_list",
3 MIN(hire_date) "Earliest"
4 FROM employees
5 WHERE department_id = 30;
Emp_list Earliest
--------------------------------------------------------------------------------------- -----------------------
Raphaely; Khoo; Tobias; Baida; Himuro; Colmenares 07-DEC-2002 00:00:00
HR@test>SELECT hire_date, last_name
2 FROM employees
3 WHERE department_id = 30 order by hire_date, last_name;
HIRE_DATE LAST_NAME
----------------------- --------------------------------------------------
07-DEC-2002 00:00:00 Raphaely
18-MAY-2003 00:00:00 Khoo
24-JUL-2005 00:00:00 Tobias
24-DEC-2005 00:00:00 Baida
15-NOV-2006 00:00:00 Himuro
10-AUG-2007 00:00:00 Colmenares
HR@test>SELECT department_id "Dept.",
2 LISTAGG(last_name, '; ') WITHIN GROUP (ORDER BY hire_date) "Employees"
3 FROM employees
4 GROUP BY department_id
5 ORDER BY department_id;
Dept. Employees
---------- --------------------------------------------------
10 Whalen
20 Hartstein; Fay
30 Raphaely; Khoo; Tobias; Baida; Himuro; Colmenares
40 Mavris
50 Kaufling; Ladwig; Rajs; Sarchand; Bell; Mallin; We
iss; Davies; Marlow; Bull; Everett; Fripp; Chung;
Nayer; Dilly; Bissot; Vollman; Stiles; Atkinson; T
aylor; Seo; Fleaur; Matos; Patel; Walsh; Feeney; D
ellinger; McCain; Vargas; Gates; Rogers; Mikkiline
ni; Landry; Cabrio; Jones; Olson; OConnell; Sulliv
an; Mourgos; Gee; Perkins; Grant; Geoni; Philtanke
r; Markle
60 Austin; Hunold; Pataballa; Lorentz; Ernst
70 Baer
80 King; Sully; Abel; McEwen; Russell; Partners; Tuck
er; Errazuriz; Smith; Ozer; Hutton; Bernstein; Hal
l; Vishney; Doran; Fox; Bloom; Taylor; Olsen; Livi
ngston; Sewall; Cambrault; SMITH; Greene; Bates; C
ambrault; Tuvault; Johnson; Marvins; Zlotkey; Lee;
Ande; Banda; Kumar
90 De Haan; King; Kochhar
100 Faviet; Greenberg; Chen; Sciarra; Urman; Popp
110 Gietz; Higgins
Grant
SELECT department_id "Dept", hire_date "Date", last_name "Name",
LISTAGG(last_name, '; ') WITHIN GROUP (ORDER BY hire_date, last_name)
OVER (PARTITION BY department_id) as "Emp_list"
FROM employees
ORDER BY "Dept", "Date", "Name";
Dept Date Name Emp_list
---------- ----------------------- -------------------- --------------------------------------------------
10 17-SEP-2003 00:00:00 Whalen Whalen
20 17-FEB-2004 00:00:00 Hartstein Hartstein; Fay
20 17-AUG-2005 00:00:00 Fay Hartstein; Fay
30 07-DEC-2002 00:00:00 Raphaely Raphaely; Khoo; Tobias; Baida; Himuro; Colmenares
30 18-MAY-2003 00:00:00 Khoo Raphaely; Khoo; Tobias; Baida; Himuro; Colmenares
30 24-JUL-2005 00:00:00 Tobias Raphaely; Khoo; Tobias; Baida; Himuro; Colmenares
30 24-DEC-2005 00:00:00 Baida Raphaely; Khoo; Tobias; Baida; Himuro; Colmenares
30 15-NOV-2006 00:00:00 Himuro Raphaely; Khoo; Tobias; Baida; Himuro; Colmenares
30 10-AUG-2007 00:00:00 Colmenares Raphaely; Khoo; Tobias; Baida; Himuro; Colmenares
40 07-JUN-2002 00:00:00 Mavris Mavris
14 行列转换:
Pivot
行转列
OE@test>select customer_id,product_id,quantity from orders join
order_items using(order_id) where product_id in (3170 ,3176 ,3182,3163
,3165 ) ; ---五个产品的销售情况
CUSTOMER_ID PRODUCT_ID QUANTITY
----------- ---------- ----------
101 3163 142
101 3163 66
104 3182 77
104 3176 72
104 3170 70
104 3165 64
104 3163 61
106 3176 62
106 3163 55
107 3165 76
108 3163 45
108 3165 31
109 3182 115
109 3165 112
116 3165 10
116 3163 5
116 3176 24
116 3170 24
116 3170 24
117 3165 67
117 3163 63
118 3170 42
119 3170 36
求这五个产品中每个客户购买情况。
with order_item_query as (select customer_id,product_id,quantity from
orders join order_items using(order_id)) select * from
oe.order_item_query
pivot
( sum(quantity) as sum_qty for (product_id)
in(3170 as P3170,3176 as P3176,3182 as P3182,3163 as P3163,3165 as
P3165)) order by customer_id;
CUSTOMER_ID P3170_SUM_QTY P3176_SUM_QTY P3182_SUM_QTY P3163_SUM_QTY P3165_SUM_QTY
----------- ------------- ------------- ------------- ------------- -------------
101 208
104 70 72 77 61 64
106 62 55
107 76
108 45 31
109 115 112
116 48 24 5 10
117 63 67
14.2 Unpivot :
列转行
OE@test>select * from email_signup;
USER_ACCOUNT SIGNUP_DATE USER_EMAIL FRIEND1_EMAIL FRIEND2_EMAIL FRIEND3_EMAIL
-------------------- ----------------------- --------------- --------------- --------------- ---------------
lakala 18-MAR-2014 00:00:00 123@lakala.com 1@lakala.com 2@lakala.com 3@lakala.com
lkl 17-MAR-2014 00:00:00 p123@lakala.com p1@lakala.com p2@lakala.com p3@lakala.com
OE@test>select user_account, signup_date, src_col_name, friend_email
2 from email_signup
3
unpivot
(
4 (friend_email) for src_col_name
5 in (user_email, friend1_email, friend2_email, friend3_email)
USER_ACCOUNT SIGNUP_DATE SRC_COL_NAME FRIEND_EMAIL
-------------------- ----------------------- -------------------------- --------------------
lakala 18-MAR-2014 00:00:00 USER_EMAIL 123@lakala.com
lakala 18-MAR-2014 00:00:00 FRIEND1_EMAIL 1@lakala.com
lakala 18-MAR-2014 00:00:00 FRIEND2_EMAIL 2@lakala.com
lakala 18-MAR-2014 00:00:00 FRIEND3_EMAIL 3@lakala.com
lkl 17-MAR-2014 00:00:00 USER_EMAIL p123@lakala.com
lkl 17-MAR-2014 00:00:00 FRIEND1_EMAIL p1@lakala.com
lkl 17-MAR-2014 00:00:00 FRIEND2_EMAIL p2@lakala.com
lkl 17-MAR-2014 00:00:00 FRIEND3_EMAIL p3@lakala.com

