图像去模糊领域的《Scale-recurrent Network for Deep Image Deblurring》论文,在本文中我从背景出发到网络结构以及论文中公式都进行了详细的解读,欢迎大家讨论。
SRN
-De
blur
Net
为了进行培训,我严格遵循原始
论文
的所有配置。
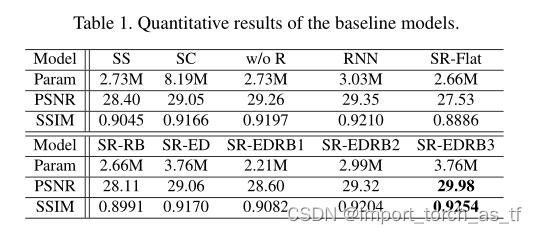
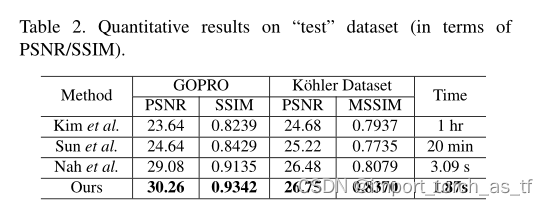
为了测试PSNR,我将GOPRO datset的测试集分为两半,一个用于验证,另一个用于测试,并获得29.58db PSNR(原始
论文
报道为30.26db )。
提供了预训练的模型。 在没有伽玛校正的情况下,可以对GOPRO的模糊
图像
进行训练。
我试图将这种模型推广到真实世界中的人脸
图像
中,但是发现它不能很好地推广。
欢迎任何讨论或更正。
1. 介绍
图像
去模糊
一直以来都是计算机视觉和
图像
处理领域内的一个重要问题。给定一张因运动或失焦而模糊(由相机摇晃、目标快速移动或对焦不准而造成)的
图像
,
去模糊
的目的是将其恢复成有清晰的边缘结构和丰富真实的细节的
图像
。
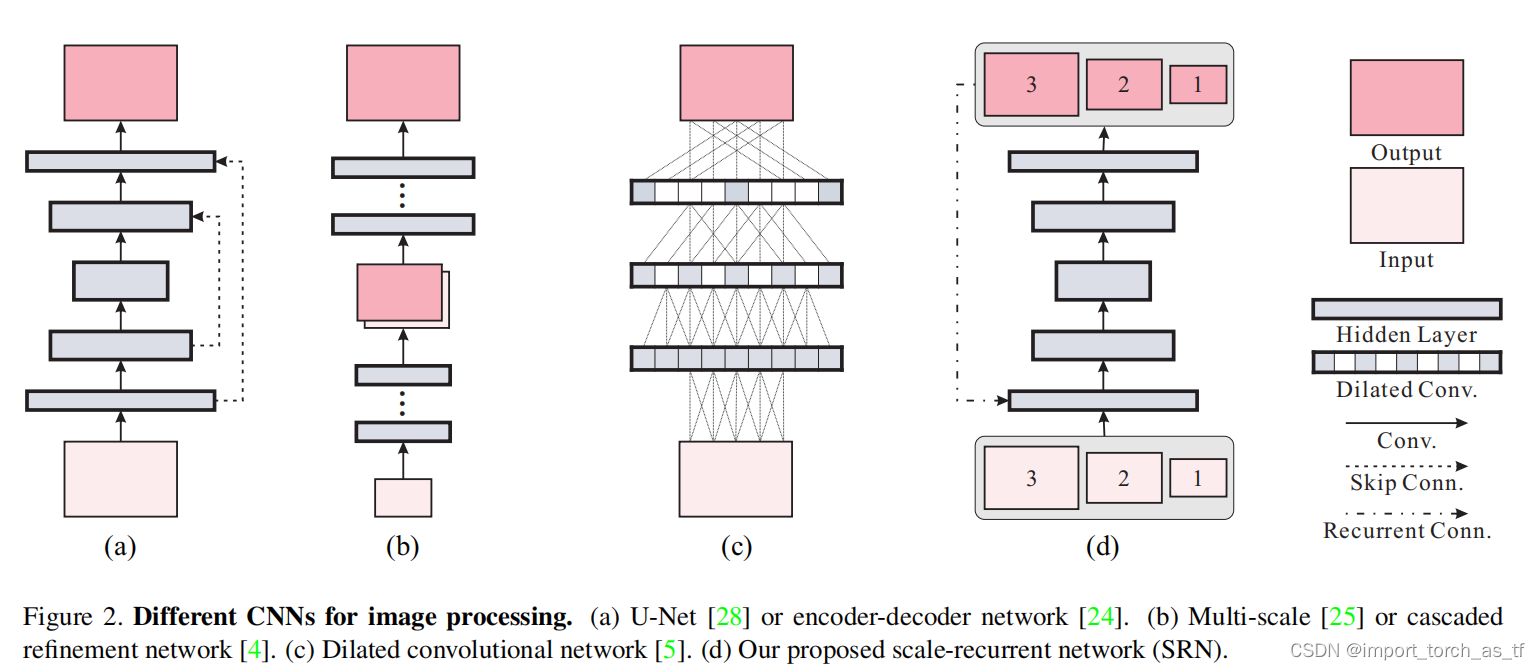
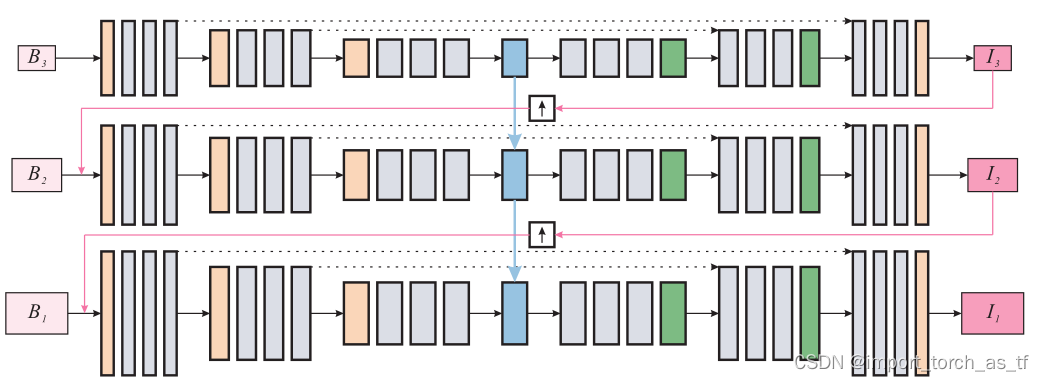
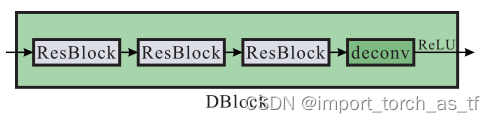
图像
去模糊
是从粗糙到精细(coarse-to-fine)的过程,在传统方法与基于深度学习的方法中,一般使用金字塔结构中不同分辨率逐渐去重建得到清晰的
图像
,这篇文章也是使用这样的方...
ICCV2021:一种基于小波变换的直线型扩张网络
图像
去模糊
方法
论文
地址:https://arxiv.org/abs/2110.05803https://arxiv.org/abs/2110.05803
代码:GitHub - FlyEgle/SDWNet: An Straight Dilated Network with Wavelet for image De
blur
ring
现有的方法大多采用重复的上采样和下采样结构来增大感受野,导致采样过程中纹理信息丢失,其中一些设计多阶段从..
SRGAN和
SRN
-de
blur
是两种不同的深度学习模型,它们的应用场景和目标也有所不同。
SRGAN主要用于超分辨率
图像
重建,即将低分辨率
图像
转换为高分辨率
图像
。它使用了生成对抗网络(GAN)的结构,并引入了残差学习,从而能够生成更加真实、清晰的高分辨率
图像
。SRGAN已经在
图像
超分辨率增强、医学
图像
处理等领域取得了较好的效果。
SRN
-de
blur
主要用于
图像
去模糊
,即将模糊的
图像
还原为清晰的
图像
。它使用了深度卷积神经网络(DCNN)和残差网络(ResNet)的结构,通过对大量的模糊和清晰
图像
进行训练,使网络能够自动学习
图像
的模糊性质,并能够自动去除
图像
的模糊效果。
SRN
-de
blur
已经在
图像
去模糊
、视频去抖动等领域取得了较好的效果。
因此,虽然SRGAN和
SRN
-de
blur
都是基于深度学习的
图像
处理技术,但它们的应用场景和目标是不同的。
ImportError: cannot import name ‘SummaryWriter‘ from partially initialized module ‘torch.utils.tenso
ImportError: cannot import name ‘SummaryWriter‘ from partially initialized module ‘torch.utils.tenso
m0_74886235:
【超分辨率】VDSR论文笔记
小鱼扭咕噜: