

The Effects of Regularization and Data Augmentation are Class Dependent - QuickPeek

Abstract
使用随机裁剪的时候某些类别的准确率会下降,并且使用非信息的正则化技术比如权重衰减也会导致某些类别的准确率下降。即正则化效果会显著牺牲某些类别的性能来提升整体性能。
1 Introduction
数据增强的正则化效果是隐式正则化效果,因为其不是模型参数构成的方程,而是训练样本构成的方程。数据增强与权重衰减之间的区别在于数据增强需要更多的领域知识才能强于权重衰减。
本文主要讨论使用正则化技术比如数据增强和权重衰减时会引入显著偏差进模型中,即正则化技术会展现强类别偏好,这时模型对某个类别更加准确的代价。
熟悉统计估计结果,偏差方差权衡或者贝叶斯估计,吉洪诺夫正则化的读者都不会对于正则化会产生偏差而感到惊讶。实际上如果能减少方差,那么向估计器中引入偏差是有收益的,即最小化经验风险,这也是岭回归能成功的原因之一。但潜在风险是被正则化引入的偏差对于不同的类的效果不同,包括迁移学习。
2 Regularization Creates Class-Dependent Model Bias that can be Harmful even for Transfer Learning Tasks
正则化和其他结构风险最小化方法都是通过增加估计器中的偏差而提升泛化性能,这样估计器的方差就能减少很多。但没人能保证偏差会平等对待所有类别。
2.1 When Data-Augmentation Creates Bias
公式1中,如果变换无法移动真方程的水平集,那么模型就会学到不同的集,因此增强数据与原始数据的差异就会大于0。
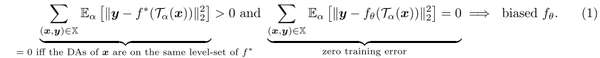
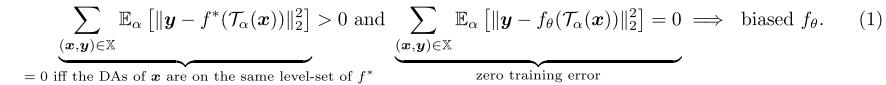
如果标签没有随着增强数据而修改,那么任何非label-preserving的数据增强都会引入偏差。
我们的目标是在2.2节中展示随机裁剪、颜色抖动、CutOut等数据增强只在一些值的情况下为label-preserving类型,并且这些值还随着不同类别而变化。
2.2 The Same Data-Augmentation can be Label-Preserving or Not Between Different Classes
我们希望展示数据增强随着类别变为label-preserving和非label-preserving,因此当同样的数据增强应用在所有类别上时,增强数据集会偏爱最label-preserving的类别。
我们选择了6个流行的架构,然后用不同的数据增强技术来评估性能。我们观察到如果把数据集作为整体来看作α的函数,其内包含的信息平均上来看不足够预测正确的标签。但是从类别角度观察,对于一些类别,无论什么程度的数据增强,即啥α值,都能取得优化效果,而其他类别会变得无法预测。
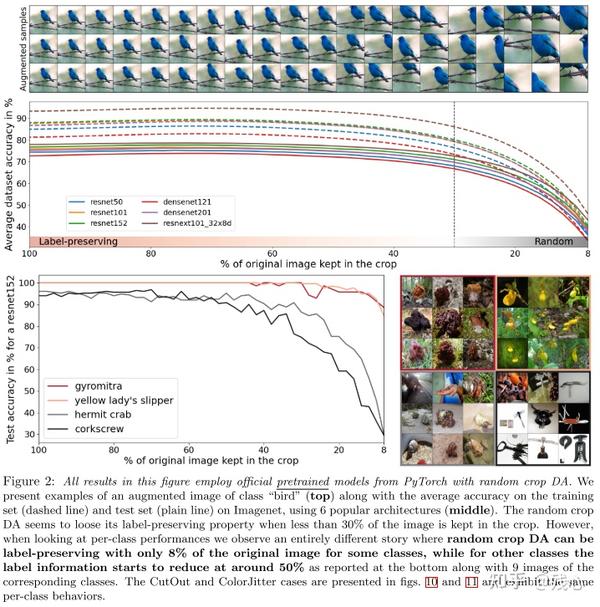
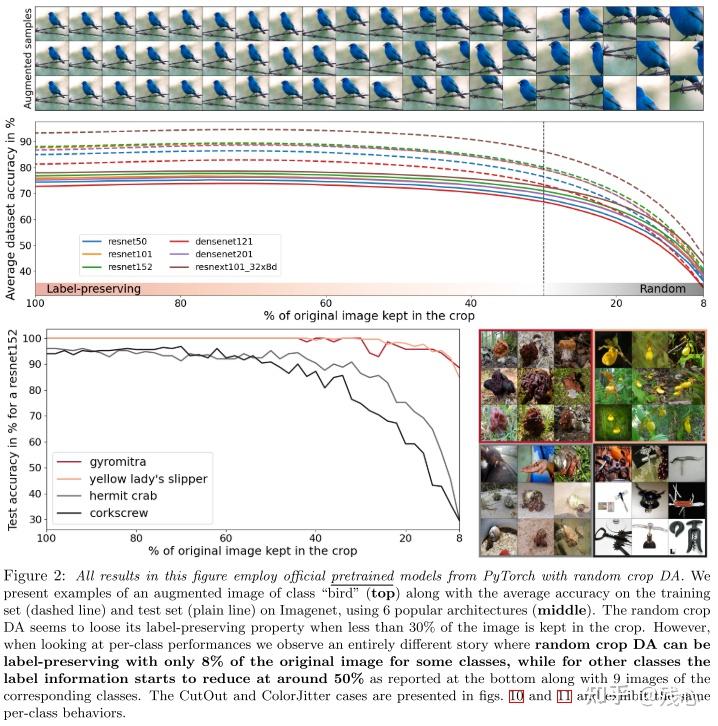
Fig3中展示了不同模型的类别准确率,全都显示出了相同的趋势,我们因此确认了当给所有类别使用同样的数据增强策略时,不同类别的样本中包含的信息会极度不均衡,就算原始数据集中的信息是均衡的。
2.3 Measuring the Average Treatment Effect of Data-Augmentation on Models’ Class-Dependent Bias
我们提出了Fig4的实验,即敏感度分析,通过不同的数据增强策略训练同样的模型,比如改变随机裁剪的值α,就能改变图片中保留的信息。我们观察到增强数据增强的强度,会使得所有类别的平均准确率增加,减少某些类别的测试准确率。
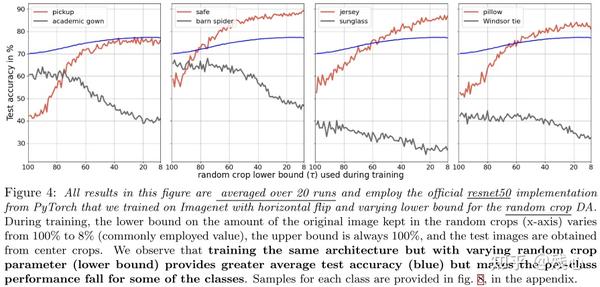
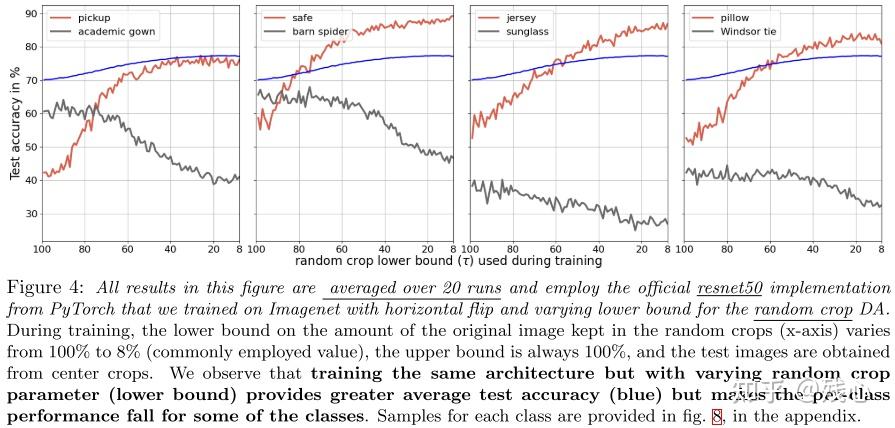
……,因此有足够的证据证明对1000个ImageNet类别来说,当使用数据增强时,有4.4%的类别准确率没有增加。
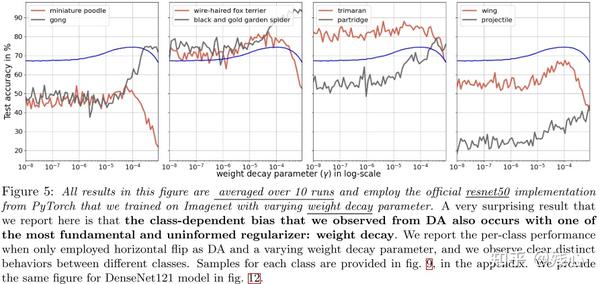
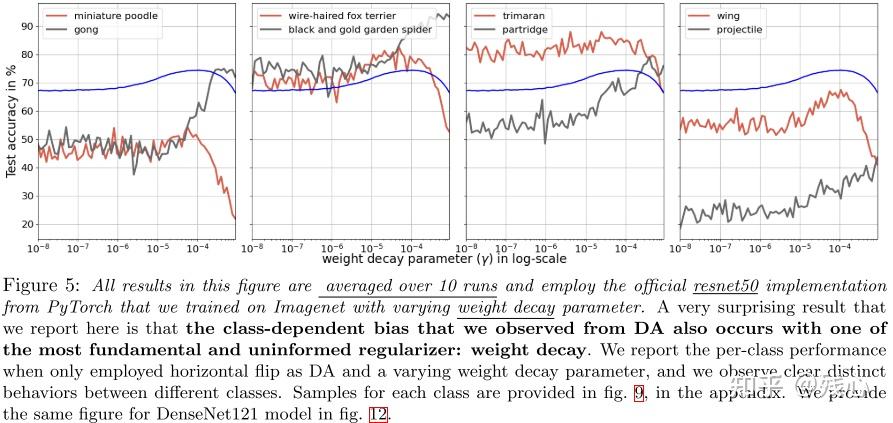
2.4 Uninformed Weight Decay Also Creates Class-Dependent Model Bias
我们在Fig5中展示了使用不同因子的权重衰减训练ResNet50的每个类别的性能。我们证明了就算非信息的正则化技术比如权重衰减,也会有类别偏差被引入,某些类别的性能还是会减少。
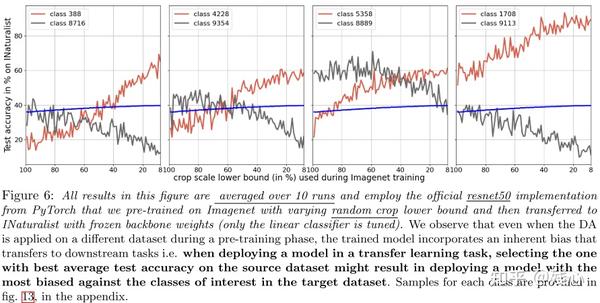
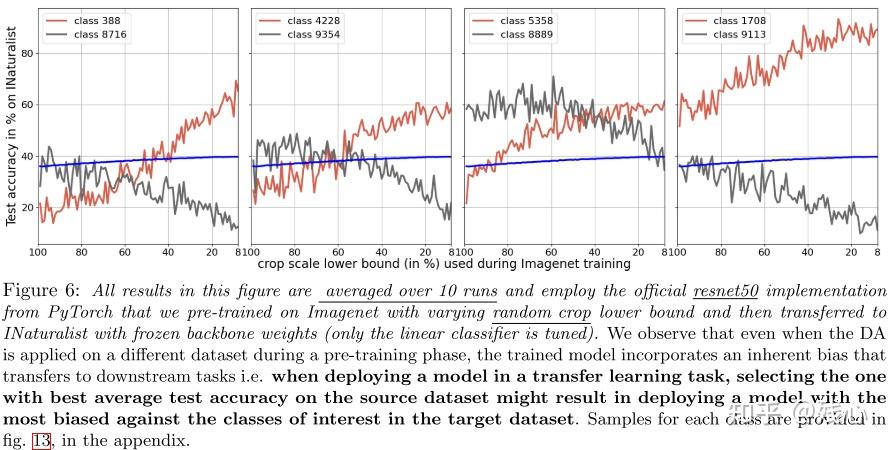
2.5 The Class-Dependent Bias Transfers to Other Downstream Tasks
Fig6展示了迁移学习使用不同数据增强的性能,同样出现了某些类别的性能下降,而整体性能上升的现象。
3 Conclusion
