dataframe根据另一个csv查找数据,且两个数据个数不同:
(1)目标文件:
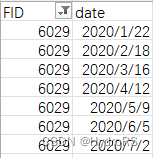
(2)查找条件:根据这个csv文件查找,如FID=6029
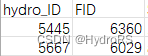
情况一:一个csv文件作为数据集,另外一个csv文件作为查找条件,假设有一个csv文件A,包含学生的姓名、id、年龄、性别等信息;另外一个csv文件B,只包含一些需要查找的id号码。我们需要从A中查找这些id对应的学生姓名,并将结果写入一个新的csv文件。
-
首先导入必要的库和数据:
```python
import pandas as pd
students = pd.read_csv("students.csv")
lookup = pd.read_csv("lookup.csv")
print(students.head())
print(lookup.head())
- 接下来,我们可以使用merge()函数将两个数据集合并,注意这里使用了’inner’模式,即只合并两个数据集中都有的id。
result = pd.merge(students, lookup, on='id', how='inner')
print(result.head())
- 我们只需要保留需要的列,即学生的姓名和id信息,并将结果写入一个新的csv文件result.csv。
result = result[['id', 'name']]
result.to_csv('result.csv', index=False)
情况二:两个csv文件的条目数不同,需要按照相同的字段进行匹配
假设有两个csv文件A和B,其中A包含学生的姓名、id、年龄、性别等信息;B包含每位学生的成绩信息,包括id和对应的成绩。但是这两个文件的条目数不同,我们需要根据id进行匹配,将两个文件中数据匹配成功的行合并在一起。
- 首先导入必要的库和数据:
import pandas as pd
students = pd.read_csv("students.csv")
scores = pd.read_csv("scores.csv")
print(students.head())
print(scores.head())
- 接下来,我们要根据id将两个数据集进行匹配,同时指定how='outer’表示保留剩余未匹配成功的数据。
result = pd.merge(students, scores, on='id', how='outer')
print(result.head())
- 由于两个数据集的条目数不同,因此可能存在一些未匹配成功的数据。我们可以使用dropna()函数将未匹配成功的数据去除,并将结果写入一个新的csv文件。
result = result.dropna()
result.to_csv('combined.csv', index=False)
情况一:一个csv文件作为数据集,另外一个csv文件作为查找条件,假设有一个csv文件A,包含学生的姓名、id、年龄、性别等信息;另外一个csv文件B,只包含一些需要查找的id号码。我们需要从A中查找这些id对应的学生姓名,并将结果写入一个新的csv文件。假设有两个csv文件A和B,其中A包含学生的姓名、id、年龄、性别等信息;但是这两个文件的条目数不同,我们需要根据id进行匹配,将两个文件中数据匹配成功的行合并在一起。情况二:两个csv文件的条目数不同,需要按照相同的字段进行匹配。
#read csv
data1 = pd.read_csv(r'tem.csv',sep=';',header='infer')
#select specific columns
data1 = pd.read_csv(r'tem.csv',sep=';',header='infer',usecols=[0,1,3])
#set column headers
data1.columns = ['y','m','numbe..
1.
dataframe遍历或迭代
list1=[['B1','2019-12-01',3], ['B2','2019-12-01',8],['A1','2019-12-02',4],['A2','2019-12-09',5]]
data=pd.
DataFrame(list1,columns=('asin','date','qty'))
(1)按行遍历iterrows()
iterrows() 按行遍历,返回(index, Series)对,通过row[name]访问元素
网上有很多类似例子,但很多在VC6.0环境下不能使用,
例子在《把脉VC++》第6章源码基础上进行修改。主要修改内容包括:vc6.0中GetCount()没有,用GetSize代替;Tokenize采用AfxExtractSubString进行代替;书中源码在VC6.0环境下不能直接使用,但是整个编程思想还是很值得借鉴。在此向原作者致敬。例子主要功能包括:
1、实现对test.csv文件的读写(例子主要是读);
2、可以辨别CSV文件中的注释行(例子以符号“;”为注释行);
3、可以剔除空行;
注:由于本人非编程专业,代码不一定简洁,非喜勿喷,有问题可联系,共同探讨。
seaborn.distplot(a=None, bins=None, hist=True, kde=True, rug=False, fit=None, hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None, color=None, vertical=False, norm_hist=False, axlabel=None, label=None, ax=None, x=None)
关键参数:norm_hist:若为True, 则直方图
利用matplotlib设置坐标轴主刻度和次刻度。
(1)只显示次刻度标签位置,没有标签文本
from matplotlib.ticker import MultipleLocator, FormatStrFormatter
xmajorLocator = MultipleLocator(a) #将x主刻度标签设置为a的倍数
xmajorFormatter = FormatStrFormatter('%1.1f') #设置x轴标签文本的格式
xminorLocator = MultipleLocat
# 创建DataFrame对象
data = [("Alice", 25), ("Bob", 30), ("Charlie", 35)]
df = spark.createDataFrame(data, ["Name", "Age"])
# 写入CSV文件
df.write.csv("path/to/output/folder")
通过执行上面的代码,会将DataFrame对象`df`写入到`path/to/output/folder`目录下,生成多个CSV文件,每个文件大小约为128MB。如果要生成单个CSV文件,可以使用`coalesce`方法将数据合并为单个分区,再调用`write`方法将其写入CSV文件,示例代码如下:
```python
# 将数据写入单个CSV文件
df.coalesce(1).write.format("csv").option("header",True).save("path/to/output/file.csv")
上述代码中,通过指定`csv`文件格式,设置`header`选项为`True`,再将数据合并为单个分区,最后将DataFrame写入CSV文件`path/to/output/file.csv`。
weixin_59825403:

