我的代码逻辑如下
-
首先使用pipeline组装实现多项式逻辑回归算法PolynomialLogisticRegression
-
使用GridSearch对PolynomialLogisticRegression进行网格搜索
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
def PolynomialLogisticRegression(degree=2, C=1.0):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std', StandardScaler()),
('log_reg', LogisticRegression(C=C))
from sklearn.model_selection import GridSearchCV
param_grid = {
'degree': [i for i in range(1, 21)],
'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]
grid_search = GridSearchCV(PolynomialLogisticRegression(), param_grid)
grid_search.fit(X_train, y_train)
报以下错误 Invalid parameter C for estimator Pipeline…
ValueError: Invalid parameter C for estimator Pipeline(memory=None,
steps=[('poly',
PolynomialFeatures(degree=2, include_bias=True,
interaction_only=False, order='C')),
('std',
StandardScaler(copy=True, with_mean=True, with_std=True)),
('log_reg',
LogisticRegression(C=1.0, class_weight=None, dual=False,
fit_intercept=True, intercept_scaling=1,
l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None,
penalty='l2', random_state=None,
solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False))],
verbose=False). Check the list of available parameters with `estimator.get_params().keys()`.
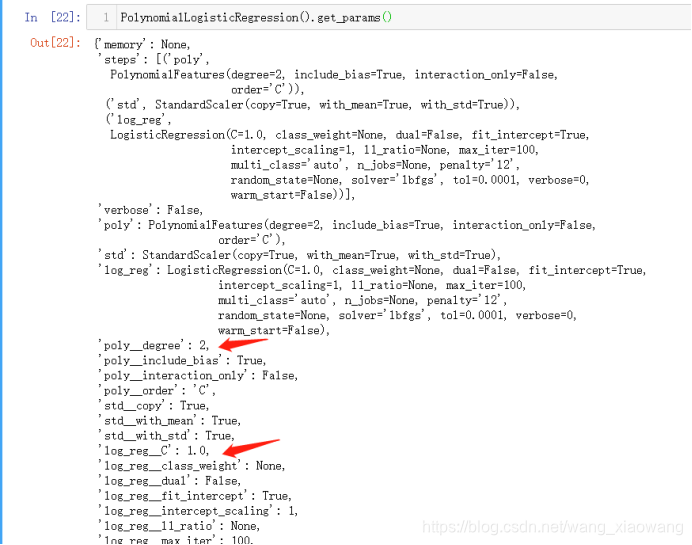
发现是网格搜索的参数存在问题,由pipeline组装成的PolynomialLogisticRegression中不存在此参数
通过PolynomialLogisticRegression().get_params()发现参数名前方拼接了pipeline中每个步骤起的别名(类似命名空间),如degree参数在pipeline中定义为(‘poly’, PolynomialFeatures(degree=degree)),所以应该传poly__degree
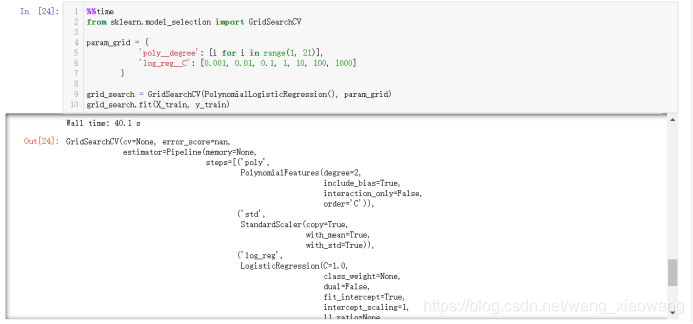
修改后的GridSearch
%%time
from sklearn.model_selection import GridSearchCV
param_grid = {
'poly__degree': [i for i in range(1, 21)],
'log_reg__C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]
grid_search = GridSearchCV(PolynomialLogisticRegression(), param_grid)
grid_search.fit(X_train, y_train)
运行结果如下
我的代码逻辑如下首先使用pipeline组装实现多项式逻辑回归算法PolynomialLogisticRegression使用GridSearch对PolynomialLogisticRegression进行网格搜索from sklearn.preprocessing import StandardScaler, PolynomialFeaturesfrom sklearn.pipeline import Pipelinefrom sklearn.linear_model import Log
复制代码 代码如下:
totalCount = ‘100’ totalPage = int(totalCount)/20
ValueError: invalid literal for int() with base 10的错误
网上同样的错误有人建议用round(float(“1.0″)),但是解决不了我这个问题,round(float(“1.0″))是用于解决浮点数转换为整形数的,
而我这个则是因为原字符串转换为整形后做除法,虽然一段时间内可能不报错,但时间久了就会提示(其实就是一个warning,但是会强制终止你的程序),正确
ratio = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7]
C = [3, 3, 3, 2, 2, 2, 2]
gamma = [.02, .009, .009, .005, .0008, .0009, .0007]
# 设管道
estimators = [('smt', SVMSM
from sklearn.model_selection import GridSearchCV
param_grid =[
{'n_eatimatiors':[3,10,30],'max_features':[2,4,6,8]},
{'bootstrap':[False],'n_estimators':[3,10],'max_features':[2,3,4]},
forest_reg=RandomForestRegressor(random_state=42)
from sklearn.model_selection import GridSearchCV
X, y = make_blobs(n_samples=100, centers=2,
random_state=0, cluster_std=0.8)
param_grid = {'svc__C': ...
简单模型网格调参
from xgboost import XGBClassifier
from sklearn.multiclass import OneVsRestClassifier
from sklearn.model_selection import train_test_split,GridSearchCV
param_test1 = {'max_depth':range(3,10,2),'min_child_weight':range(1,6,2)}
model = XGBClassifier
一、交叉验证
什么是交叉验证?
将拿到的训练数据分为训练和验证集。例如将训练数据分成4份,其中一份作为验证集。然后经过4组的测试,每次都更换不同的验证集,即得到4组模型的结果,取平均值作为最终结果,并称为4折交叉验证。
训练集:训练集+验证集
测试集:测试集
为什么需要交叉验证?
为了让被评估的模型更加准确可信
二、超参数搜索-网格搜索(Grid Search)
什么是参数搜索?
通常情况下,有很多参数是需要手动指定的(如KNN中的K值),这种叫做超参数。但是手中过程繁杂,所以需要对模型预设几种超参数

