

2D与3D人脸识别有什么本质上的区别?
关注者
68
被浏览
50,782
8 个回答

人脸是人体最重要的生物特征之一,而人脸研究主要集中在人脸识别方面,人脸的表达模型分为2D人脸和3D人脸。2D人脸识别研究的时间相对较长,方法流程也相对成熟,在多个领域都有使用,但由于2D信息存在深度数据丢失的局限性,无法完整的表达出真实人脸,所以在实际应用中存在着一些不足,例如识别准确率不高、活体检测准确率不高等。
3D人脸模型比2D人脸模型有更强的描述能力,能更好的表达出真实人脸,所以基于3D数据的人脸识别不管识别准确率还是活体检测准确率都有很大的提高。
2D人脸识别、3D人脸识别现状如何?
2D人脸识别现状
2D人脸识别的优势是实现的算法相对比较多,有一套比较成熟的流程,图像数据获取比较简单,只需一个普通摄像头即可,所以基于2D图像数据的人脸识别是目前的主流,在安防、监控、门禁、考勤、金融身份辅助认证、娱乐等多种场景中都有应用。
2D人脸识别根据其技术发展可分为两大类:传统人脸识别、基于神经网络人脸识别:
1. 传统人脸识别
传统人脸识别主要采用数学方法, 从图像矩阵中提取对应的特征 ,该特征一般为尺度不变特征,常用的算法有SURF、SIFT、HARRIS、GFTT等。
2. 基于神经网络人脸识别
目前2D人脸识别算法在各个人脸识别挑战赛、在各种的开源数据集上测试的识别准确率已经达到了99.80%(人脸识别算法insightface在LFW数据集上的测试结果),识别准确率甚至可以跟人类相媲美,但在苛刻的金融环境仅作为一种辅助手段,人脸识别之后还需要别的验证手段,如输入手机号等。
这是为什么?
因为2D人脸识别有一定的局限性,为了弥补不足,3D人脸识别应运而生。
3D人脸识别现状
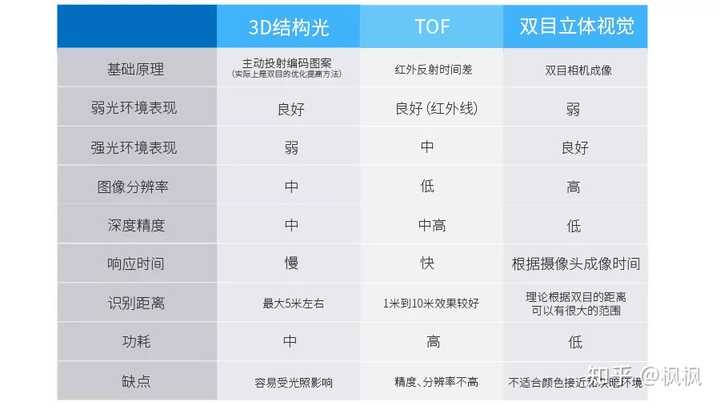
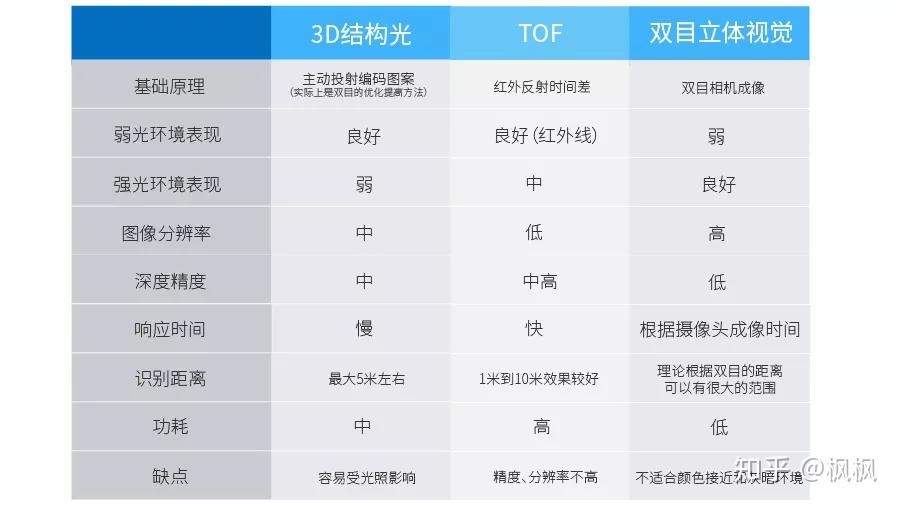
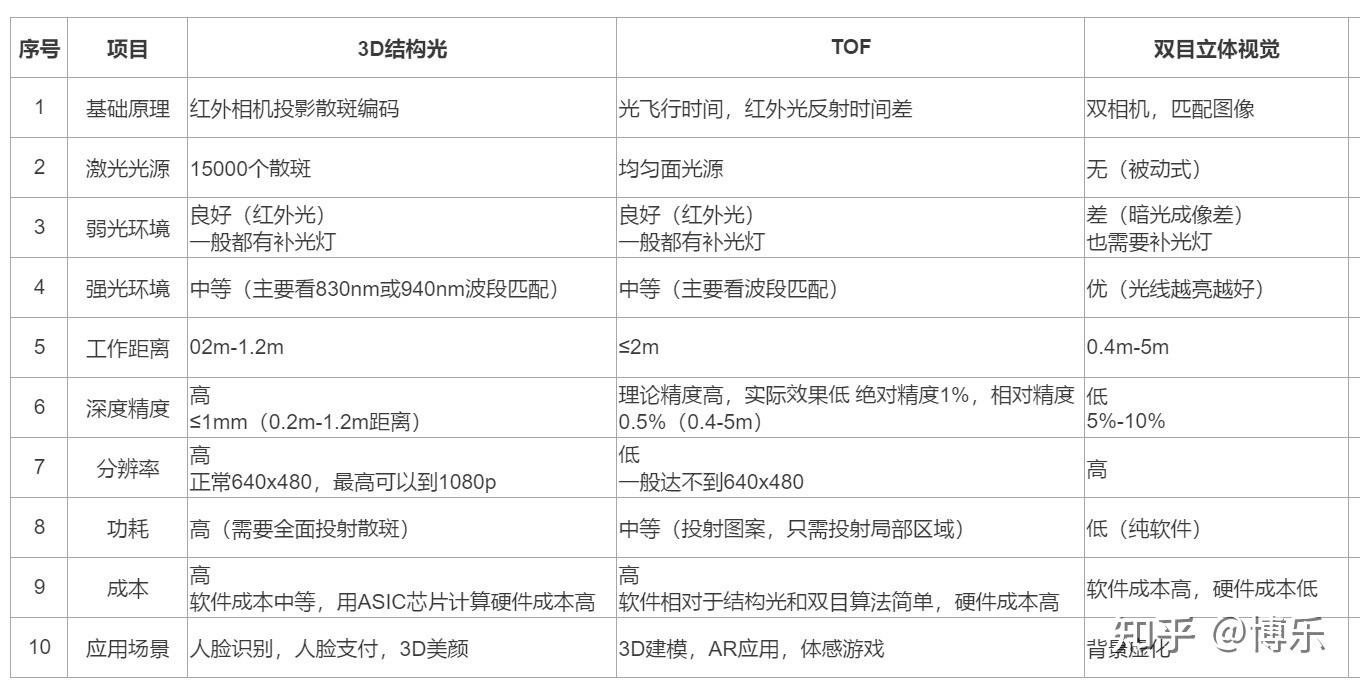
目前3D人脸识别在市场上根据使用 摄像头成像原理 主要分为:3D结构光、TOF、双目立体视觉。
3D结构光
3D结构光通过红外光投射器,将具有一定结构特征的光线投射到被拍摄物体上,再由专门的红外摄像头进行采集。主要利用三角形相似的原理进行计算,从而得出图像上每个点的深度信息,最终得到三维数据。
基于3D结构光的人脸识别已在一些智能手机上实际应用,如国外使用了 超过10亿张图像(IR和深度图像) 训练的FaceId;国内自主研发手机厂商的人脸识别。
TOF
TOF简单的说就是激光测距,照射光源一般采用方波脉冲调制,根据脉冲发射和接收的时间差来测算距离。
采用TOF的方式获取3D数据主要在Kinect上实现,Kinect在2009年推出,目的是作为跟机器的交互设备,用在游戏方面。主要获取并处理的是人体的姿态数据。
双目立体视觉
双目是基于视差原理并由多幅图像获取物体三维几何信息的方法。由双摄像机从不同角度同时获得被测物的两幅数字图像,并基于视差原理恢复出物体的三维几何信息,从而得出图像上每个点的深度信息、最终得到三维数据。
由于双目立体视觉成像原理对硬件要求比较高,特别是相机的焦距、两个摄像头的平面位置,应用范围相对3D结构光TOF少。
3D结构光、TOF、双目的区别如下
按
深度信息使用
的方法可以分为两类:3D人脸识别、2D+人脸识别。
3D人脸识别
3D人脸识别处理的是3D的数据,如点云、体素等,这些数据是完整的,立体的,能表达出物体各个角度的特征,不管一个人正脸还是侧脸,理论上都是同一个人。但是因为点云等3D数据具有数据量大、而且点云数据具有无序性、稀疏性等特点,3D人脸识别开发难度比较大。
2D+人脸识别
由于3D人脸识别开发难度比较大,于是有2D+人脸识别,其处理方式比较简单,只是将3D的人脸数据分为2D的RGB数据+深度数据。处理的方法为先采用2D的人脸识别方法处理2D的RGB数据,然后再处理深度数据。这样的处理实现起来就相对较快,因为目前的2D人脸识别有一套比较成熟的方法,特别是CNN出现后,2D的人脸识别在各挑战赛、数据集上识别的准确率已经达到甚至超过人类的识别精度。
2D+人脸识别的方法能比较好将2D人脸识别的方法迁移过来,但是这样人为的将深度信息跟RGB信息分开处理不如3D人脸识别准确率高。2D+人脸识别相对2D人脸识别准确率提高不会很大,但是在活体检测的准确率上有一定的提高。
相对于目前的2D人脸识别,3D人脸识别处理方法上有什么不同,各有什么优缺点?
2D和3D人脸识别的差异
人脸识别2D、3D主要的区别是图像数据的获取、人脸特征的提取方式不一样。但是2D人脸识别跟3D人脸识别步骤基本上一致,都是图像数据获取-->人脸检测-->特征提取-->信息比对,大体的步骤如下表所示:
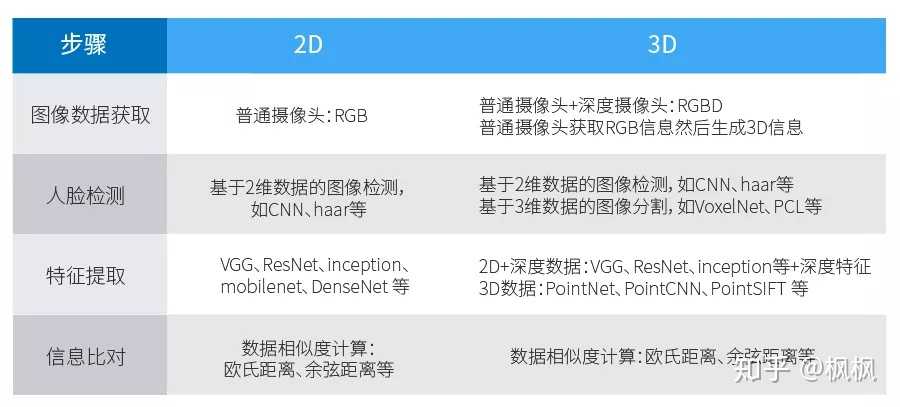
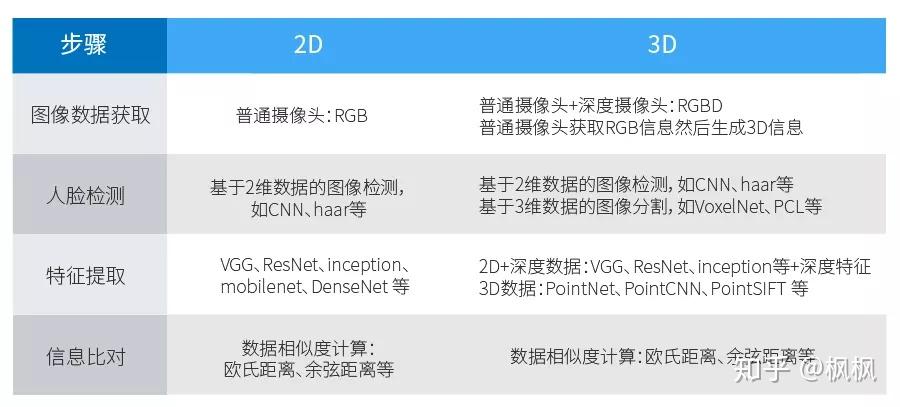
由上表可见3D人脸数据比2D人脸数据多了一维深度的信息,不管在识别准确度上还是活体检测准确度上3D人脸识别都比2D人脸识别有优势。但由于3D人脸数据比2D人脸数据多了一维深度信息,在数据处理的方法上有比较大的差异。

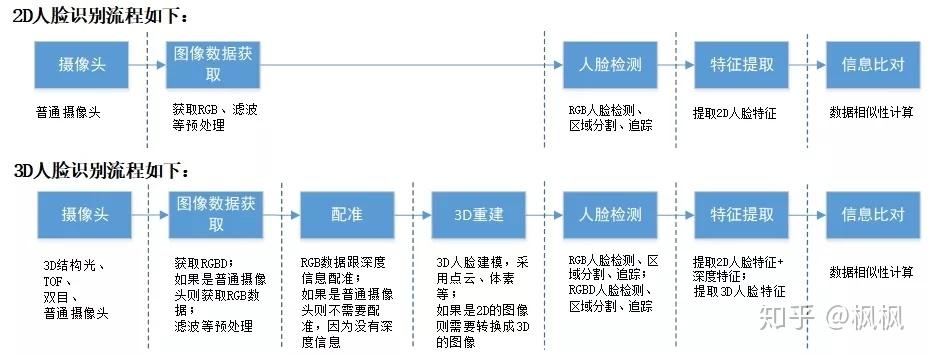
可以看出3D人脸识别细节上比2D的人脸识别复杂。下面我们展开说明。
首先大体回顾2D人脸识别现有的经典模型及实现方式。
2D人脸识别实现
2D的人脸识别因为研究的时间较长,挑战赛、开源数据集等比较多,因此诞生了一批准确率较高的识别人脸识别算法,如deepface、facenet、arcface等,这些算法的流程基本都可以按照前面说的四个大步骤(图像数据采集 -->人脸检测 -->特征提取 -->信息比对)进行,下面对这些2D人脸识别的实现步骤进行分析。
1. 图像数据采集
图像采集主要是获取目标(这里主要是人脸)的RGB彩色图像,2D图像的获取相对简单,只需要获取到RGB的图像信息,不需要深度信息。获取图像数据的方式只需要一个普通摄像头模组即可,简单方便。
图像采集完毕之后需要对图像进行预处理,如滤波、亮度调整、去噪等,保证输出图片的质量达到要求,减少干扰。预处理是比较重要的一个环节,预处理做好了能提高后面识别步骤的准确度。常用的预处理算法有均值滤波、高斯滤波等线性滤波;中值滤波、双边滤波等非线性滤波;腐蚀、膨胀、开运算、闭运算等形态学滤波;还有伽马矫正、亮度调整、基于直方图统计的图像增强等。
2.人脸检测
人脸检测的目的是找到人脸的区域,并且将人脸的区域输出给后面的特征提取模块,完成人脸的特征提取。人脸检测步骤是一个很关键的步骤,获取人脸的boundingbox不仅只能包含人脸部分而且还要包含全部的人脸区域。如果boundingbox的大小或者坐标不准,就会使后面的特征提取步骤提取的特征不准,最后导致识别准确率下降,出现误识别。
2D人脸检测研究的时间比较长,所以更成熟,检测方法有传统的haar方法、还有神经网络实现的方式,而且速度可以很快,如目前mtcnn能做到在I7-7700 CPU@3.6GHz的CPU上达到1562 FPS的帧率。下面对使用比较多的几种算法进行分析:
/1/
基于haar特征
该算法灵感来源与haar小波变换,捕抓图像中的边缘、变化等信息,从而检测出人脸的位置。其检测速度及精度都达到了不错的水平,基本图片中的正脸都能检测出来,但是对侧脸检测的精度没有mtcnn高,该算法已经在opencv中实现,使用方便。
/2/
Face R-CNN
基于Faster R-CNN框架针对人脸检测做了专门的优化。引入了更好的center loss使得类内的差异性更小,提高了负样本在特征空间的差异性从而提高了算法的性能。
/3/
MTCNN
多任务的人脸检测方法,将人脸区域的检测跟人脸的关键点检测放到一起,基于cascade框架,总体上分为PNet、RNet、ONet三部分。MTCNN的准确度很高,侧脸、正脸、模糊的脸基本都能检测的比较准,运算速度都比较快,能在手机端跑到30FPS,在PC端只有CPU I7-7700的情况下能跑到1562FPS的帧率。
除了上面这些还有Faceness-Net、SSH、HR、Pyramidbox等。
3.特征提取
特征提取阶段是人脸识别最重要的阶段,这个阶段设计的网络模型的好坏直接决定了人脸识别准确率的高低。2D的人脸数据只有RGB,2D人脸特征提取的方法就很多了,传统算法有SURF、SIFT等,基于神经网络的有Inception、VGG、ResNet、Inception-ResNet等。
基于CNN神经网络的特征提取模型是目前的主流。CNN神经网络特征提取的实现分为四个步骤:神经网络设计、损失函数设计、训练、推理。
神经网络设计
特征提取的神经网络模型基本上以在imagenet的表现为参考进行选择,当然可以自己设计神经网络架构,目前这些CNN网络模型在imagenet上的识别准确率及参数量为下表所示:
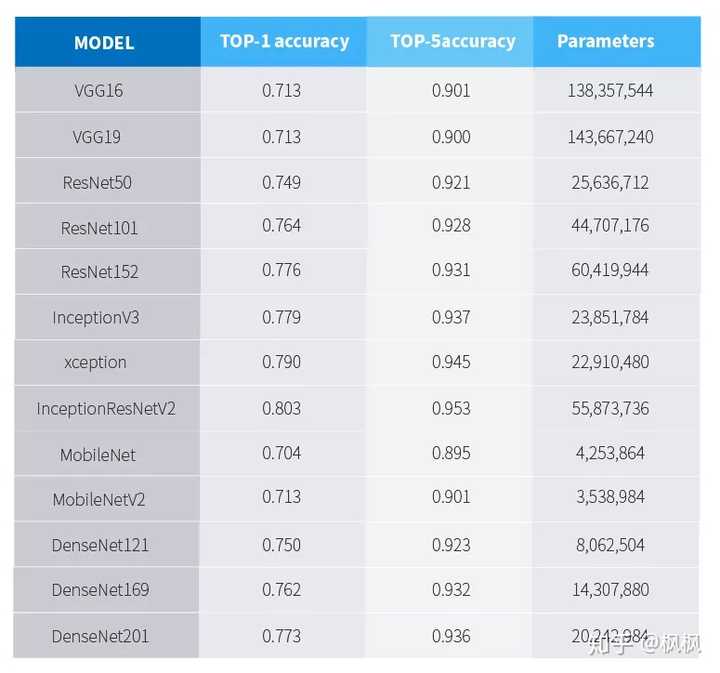
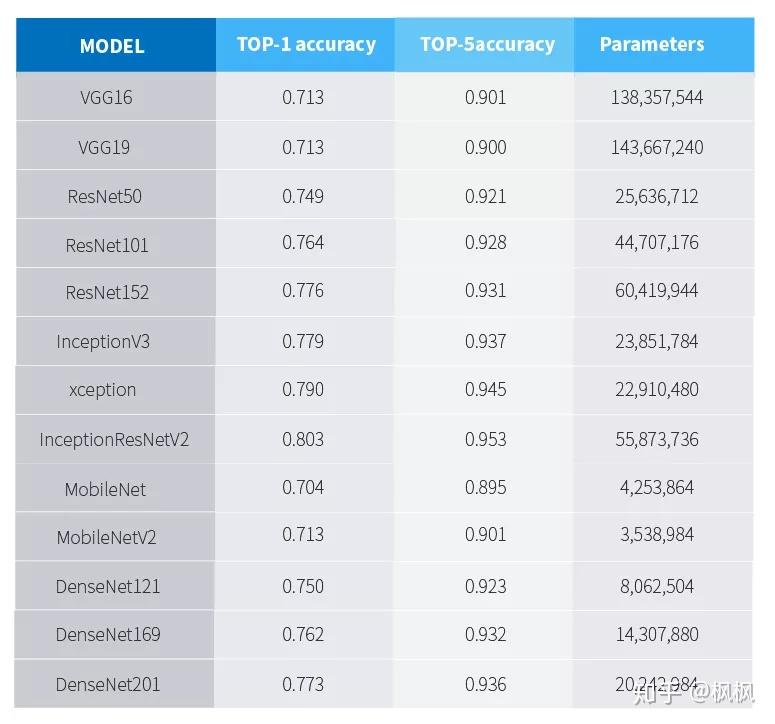
数据来源keras官网
损失函数设计
神经网络模型选择完毕之后,接着要做的事情就是设计一个损失函数,用来作为训练时神经网络权重参数调整的标准。常用的损失函数有:softmax、sphereface、cosface、arcface。
softmax
sphereface
cosface

arcface
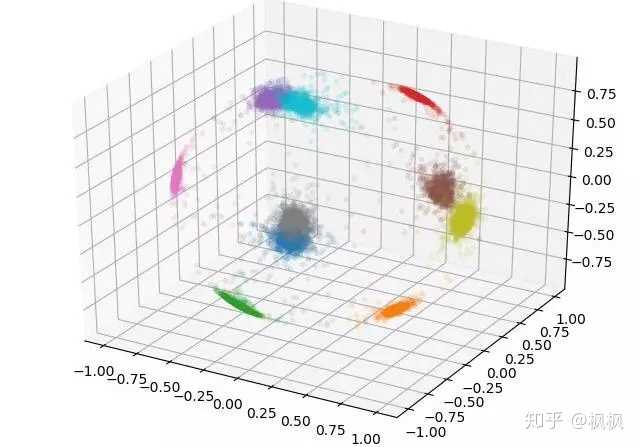
mnist的手写体数字图片分类的效果
当然除此之外还有triplet loss、center loss,还可以自己设计损失函数,好的损失函数基本上能决定了特征提取模型的好坏。
— 训练 —
准备好数据,训练设计好的神经网络模型,大量的数据集在这个时候就能发挥出作用了,数据集越大训练出的神经网络权重参数的值更好,具有更高的泛化能力,鲁棒性更好。2D的人脸数据集比较多,如开源的人脸库megafce就有超过百万的人脸数据,而3D人脸识别目前的数据集很少,设计好神经网络之后还需要花费很大的精力去收集数据集。
— 推理 —
推理部分完成图像数据的输入,经过神经网络的计算,输出特征数据。这个神经网络是怎么计算由前面的神经网络设计、损失函数设计、训练决定。
神经网络设计、损失函数设计、训练这三个步骤是可以不用去做,可以直接使用别人训练好的网络模型,如google的facenet,就提供了该模型,可以拿过来直接做推理使用,但是带来的问题就是没有在自己的数据集上训练过,所以在自己的数据集上的测试效果不会好。正确的做法是使用别人训练好的模型作为预训练参数,然后再在自己的数据上训练。
4.信息比对
完成特征提取步骤之后就是计算特征的相似度,特征就是结构化数据,不管是一维、二维还是N维,所以只需要计算出待识别图像的特征跟库中特征的相似度,然后根据相似度就可以判断是否同一个人,实现人脸识别。特征的相似度计算就是计算两组数据的相似度,方法有:
余弦相似度
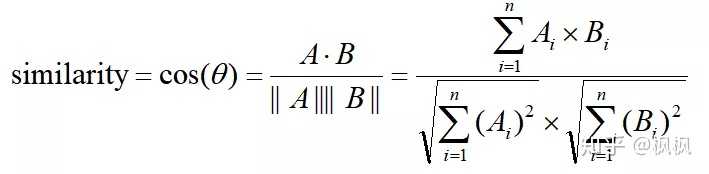
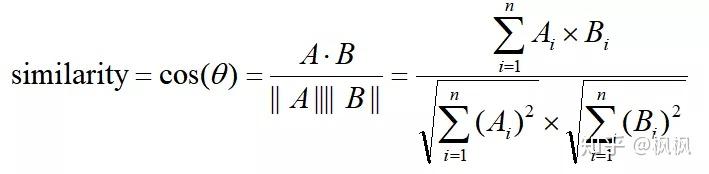
这个基本上是最常用的,最初用在计算文本相似度效果很好,由于余弦相似度表示方向上的差异,对距离不敏感,所以有时候也考虑距离上的差异会先对每个值都减去一个均值,这样称为调整余弦相似度。
欧式距离
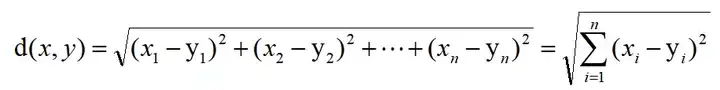
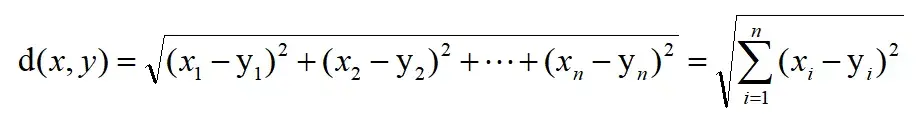
计算两个点的空间距离,欧式距离更多考虑的是空间中两条直线的距离,而余弦相似度考虑的是空间夹角。所以欧氏距离能够体现个体数值特征的绝对差异,更多的用于需要从维度的数值大小中体现差异的分析。
当然除了这些常用的之外,还有曼哈顿距离、明可夫斯基距离、皮尔森相关系数、斯皮尔曼等级相关系数等。
2D人脸识别的实现行对成熟,有很多3D人脸识别可以借鉴的地方,那么3D的人脸识别怎么实现呢,下面详细分析。
3D人脸识别实现
因为3D人脸识别基本上使用的都是点云数据,所以这里先介绍什么是点云数据,点云数据是一种常用的三维数据表示方法,三维数据表示方法除了点云还有体素网格、三角网格、多视角图等,典型的几种方法如下图:


如上图点云在表达形式上是比较全面、简洁,同时点云是非常接近原始传感器的数据集,可以比较完整的表示出物体的三维信息。
点云数据是由三维空间的坐标点以及各点的颜色组成(XYZRGB),这决定了点云的一个元素里要存的字段内容和大小。数据结构定义可以根据自己使用来重新定义,点云只是一种表达方式。
3D人脸识别因为识别的对象数据不一样,所以3D人脸识别较2D人脸识别的流程要复杂。实现步骤为:图像数据采集 -->配准 --> 3D重建 -->人脸检测 -->特征提取 -->信息比对。下面分别详细介绍每个步骤。
一、图像数据采集
图像采集主要是获取目标(这里是人脸)的RGB彩色图像,外加深度图像D,合起来就是RGBD图像,摄像头模组获取的照片数据一般按照一幅RGB的2D图像 + 一幅深度图像输出,如下图所示:



获取RGBD图像的方法有3D结构光、TOF、双目摄像头等,下面对目前使用的比较多的3D结构光进行分析,3D结构光一般有三个模组,如下:
1、IR红外光发射模组--用于发射经过特殊调制的不可见红外光至拍摄物体。
2、IR红外接收模组--接收由被拍摄物体反射回来的不可见红外光,追踪每一个光斑偏移。对比收发两端的不同追踪光点的偏移位置,从而获取物体表面的景深信息。
3、镜头模组--采用普通镜头模组,用于2D彩色图片拍摄。
获取到RGBD数据之后,需要对这些数据进行噪声滤波,去除数据中的散列点、孤立点等,常用的方法有双边滤波、高斯滤波、条件滤波、直通滤波、随机采样一致滤波等。
二、配准
步骤一的图像数据采集已经获取到RGB数据跟深度数据,这里有个问题就是RGB数据跟深度数据要对准,保证每个点的RGB数据跟深度数据都能对应,而且时间上为同一时刻。故配准分为时间上的对准、空间上的对准。
— 时间配准 —
3D模组输出的是两组数据,RGB图像跟深度数据,这两组数据分别使用两个模组采集,这里要保证使用的两个模组采集的图像数据在时间上是同步的,就是每次输出的一组数据都是要在同一时刻采集到的,要在摄像头上进行严格的时间同步,摄像头厂家一般会提供设置帧同步API。
上层的应用在调用摄像头API采集数据时要同时取出两组图像数据,要根据摄像头的输出规则获取到RGB数据跟深度数据。如摄像头输出的RGB数据跟深度数据的顺序为RGB数据-->深度数据,那么接收数据的规则就应该是RGB数据-->深度数据。一个循环就是一个完整的3D图像数据。当然接收3D数据的方案要根据摄像头的API接口来定,基本每个厂家都会有差异。
— 空间配准 —
因为模组的RGB摄像头跟深度摄像头在硬件上的安装位置可能存在偏移,摄像头的视角方向可能存在偏移,这时就需要对采集的图像数据进行偏移校准,使RGB图像上的每个点的坐标跟深度数据的每个点的坐标都一一对应,一般摄像头厂家会提供空间配准的API。
三、3D重建
前面的步骤一、步骤二只是完成了图像数据的获取,获取到的3D图片数据一般是多个角度拍摄的RGBD图像数据,这时需要将这些多个角度拍摄的图片数据进行整理、配准、合并完成一个完整的3D数据,在3D人脸识别中这个完整的 3D数据一般用来进行人脸检测、人脸特征提取,这个过程就是3D重建。
根据3D重建时是否使用深度信息可分为:物理3D重建、基于2D图像的3D重建。
物理3D重建
物理3D重建主要指利用硬件设备获取深度信息、RGB信息然后重建成3D模型,处理的数据是RGBD图像数据,RGBD数据经过变换后会转换成点云数据的形式存储。目前处理3D数据使用较多的是PCL(Point Cloud Library)库,支持多种操作系统平台,提供点云获取、滤波、分割、配准、检索、特征提取、识别、追踪、 曲面重建、可视化等功能。
物理3D重建过程为:点云数据生成 -->点云配准。
— 点云数据生成 —
步骤二获取到配准的RGB图像信息跟深度信息后,需要将RGB加深度的信息转换成点云的数据结构。
首先需要做的就是坐标系的转换,这里主要计算的有两个坐标系:图像坐标系、相机坐标系。图像坐标系主要在2D图像数据中使用,一般以像素的横坐标 u 与纵坐标 v表示,如下图:
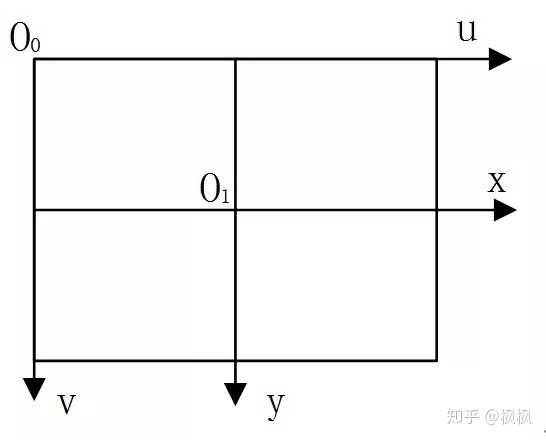
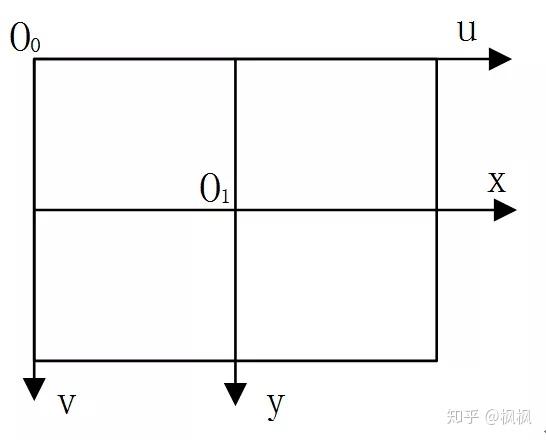
因为(u,v)只代表像素的列数与行数,而像素在图像中的位置并没有用物理单位表示出来,所以还要建立以物理单位(如毫米)表示的图像坐标系 x-y。将相机光轴与图像平面的交点(一般位于图像平面的中心处)定义为该坐标系的原点O1,而且 x 轴与 u 轴平行,y 轴与 v 轴平行,假设(u0,v0)代表O1在 u-v 坐标系下的坐标,dx 与 dy 分别表示每个像素在横轴 x 和纵轴 y 上的物理尺寸,则图像中的每个像素在 u-v 坐标系中的坐标和在 x-y 坐标系中的坐标之间都存在如下的关系:
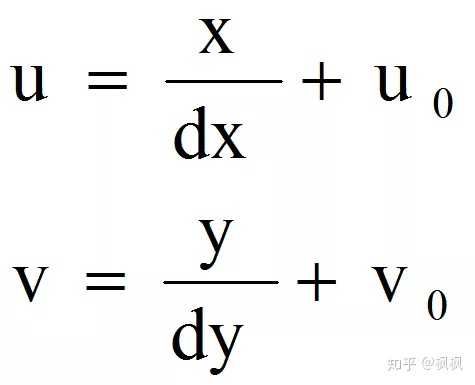
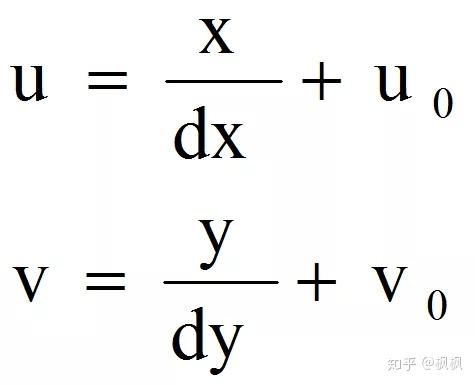
其中,dx 的单位为:毫米/像素(假设物理坐标系中的单位为毫米)。
因为我们这里使用的3D数据,坐标表示为(x,y,z),需要引入相机坐标,主要是为了表示出z坐标的位置。需要将图像坐标系转换到相机坐标系中,图像坐标系跟相机坐标系的关系如下:
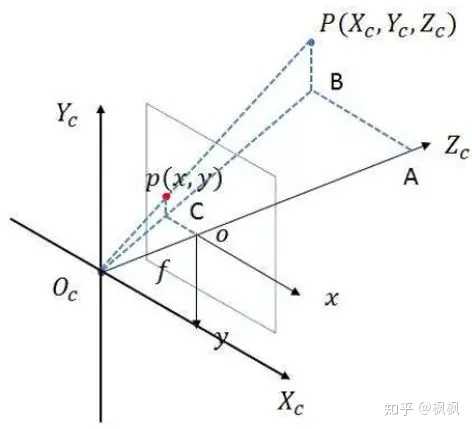
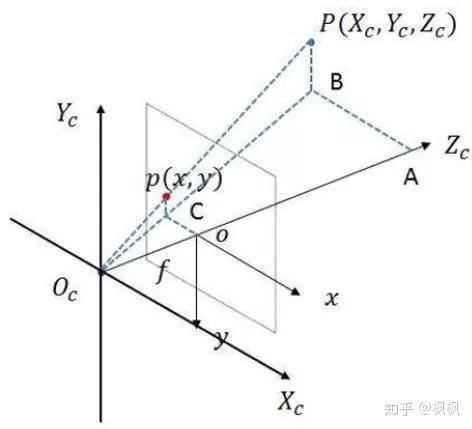
根据相似三角形的原理(三角形ABOc跟三角形oCOc相似,三角形PBOc跟三角形pCOc相似),可以得出物理点的位置P点的坐标为:
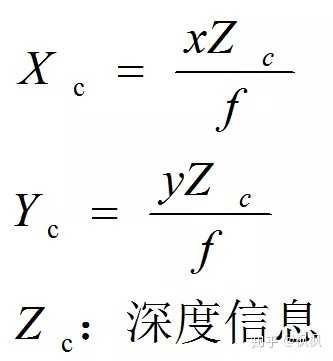
其中f为相机的焦距,Zc为深度信息。转换成矩阵的表达方式为:
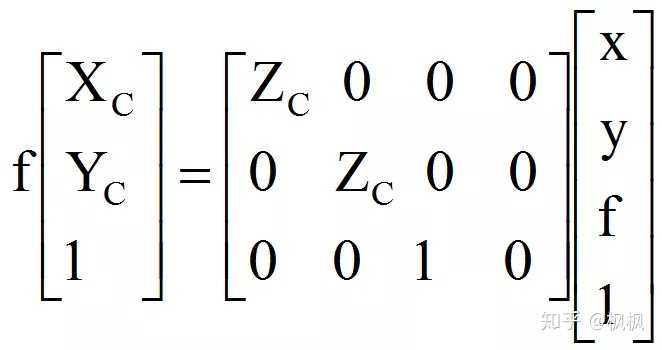
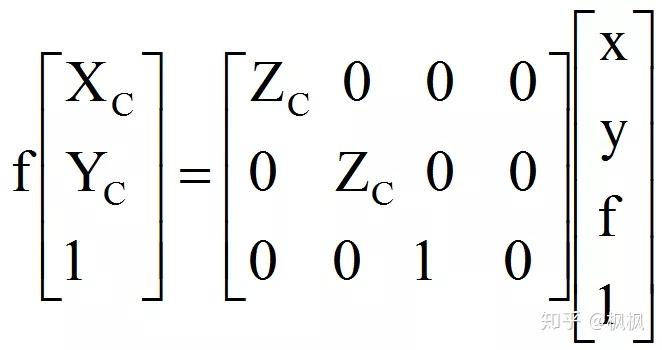
坐标系转换完毕之后就能按照PCL中定义类型<PointXYZ>PointCloud、<PointXYZRGB>PointCloud将RGBD的数据转换成点云数据。如果处理使用的是2D+人脸识别方式,则不需要将RGBD数据转换成点云的数据,后面的步骤点云配准也不需要进行,直接跳过到人脸检测。
— 点云配准 —
上面的点云数据生成步骤已经能获取到一个3D相机拍摄的点云数据,但是这些点云数据的坐标是相对相机坐标来获取的,所以当同一个物体使用不同的设备或者位置扫描,就会得出不同的点云数据,不同相机位置获取点云数据,数据的坐标排列千差万别,还有就是每个3D相机获取到的点云数据在时间上是不同步的,这样的数据很难直接通过End2End的模型处理。
点云配准就是为了解决获取点云数据时存在的问题,将不同角度、不同时间获取的多帧3D图像叠加到同一个坐标系中,这个坐标系就是世界坐标系,形成一组完整的点云数据。常用流程为首先粗配准,然后再精配准,粗配准主要是为后面的精配准准备,是很值得研究的环节,常用的算法有使用PCL库中registration模块实现的SAC-IA算法、4PCS、或者根据要配准的目标使用SIFT、SURF等尺度不变换特征。而精配准的算法有NDT算法、SSA算法、GA算法,这里主要分析著明的ICP算法(ICP算法由Besl and McKay 1992, Method for registration of 3-D shapes文章提出,该算法已经在PCL库中实现)。ICP算法本质上是基于最小二乘法的最优配准方法。通过选择对应两个点云的关系点,然后重复计算最优变换,直到满足正确配准条件。ICP算法的流程为:
/
1/
寻找对应点
因为一开始我们是不知道有哪些是对应点,一般我们在有初值的情况下,假设用初始的旋转平移矩阵对source cloud进行变换,得到的一个变换后的点云。然后将这个变换后的点云与target cloud进行比较,只要两个点云中存在距离小于一定阈值,就认为这两个点就是对应点。
/2/
R、T优化
有了对应点之后,后面就是求解对应点平移矩阵的问题,平移矩阵分为旋转R与平移T两个部分。我们可以采用最小二乘等方法求解最优的旋转平移矩阵。
/3/
迭代
我们优化得到了一个新的R与T,导致了一些点转换后的位置发生变化,一些最邻近点对也相应的发生了变化。因此,我们又回到了步骤1)中的寻找最邻近点方法。1)2)步骤不停迭代进行,直到满足一些迭代终止条件,如R、T的变化量小于一定值,或者上述目标函数的变化小于一定值,或者邻近点对不再变化等。
点云数据配准效果如下图所示:


基于2D图像的3D重建
3D人脸识别的验证、训练、测试都需要大量的3D人脸图像,但是并没有那么多的3D设备采集到3D人脸图像,那么怎么办?
2D图像其实是3D图像平面的影射,如果知道相机的方向和位置、光源的方向和位置可以反向计算得出3D的图像。根据相机的方向位置、光源的方向位置确定与否,有Shape from Shading、Shape from Silhouettes、Shape from DE-focus、Stereo matching等基于2D图像的3D重建算法。
上面介绍的算法都是从数学上进行分析、计算得出的,另外因为神经网络的火热,诞生了很多神经网络的2D图像3D重建的方法,由于神经网络的优势:精度高、实现相对简单、不需要复杂算法推导,基于神经网络的端到端的3D人脸重建慢慢成了主流,目前比较流行的模型有PRNet、3DDFA、face3d、2DASL、3DMM、VRNet等。
这里主要讨论业内认可度比较高的PRNet,PRNet是CVPR2018提交的作品,在3DDFA、3DMMasSTN等思想上一步步的改进得来。采用了encoder-decoder的网络架构,实现了端到端的单张RGB人图像进行3D人脸重构和密集人脸对齐的联合任务。训练集为300W-LP,3D重构的效果比较好,并且速度非常快,在GTX1080TI上达9.8ms/帧。
整体的网络结构如下所示:


图片出自: https:// arxiv.org/pdf/1803.0783 5.pdf
3D重建的效果如下:
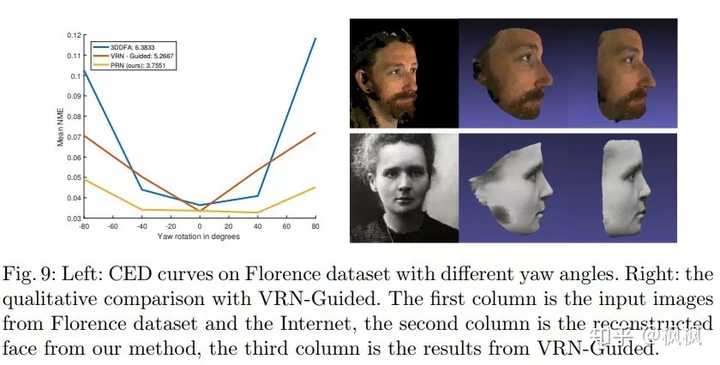
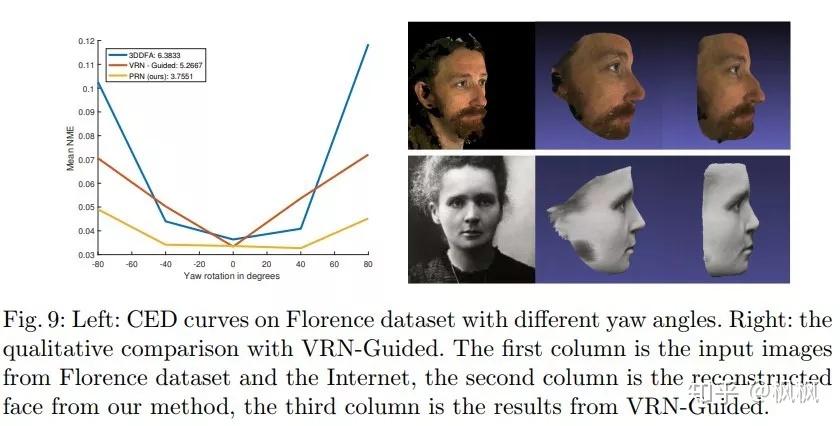
图片出自: https:// arxiv.org/pdf/1803.0783 5.pdf
四、人脸检测
3D人脸检测跟2D+人脸检测主要以处理3D数据的方式不同进行区分。3D人脸识别处理的是3D的数据,如点云、体素等,这些数据是完整的,立体的。而2D+人脸检测的处理方式是将3D的人脸数据分为2D的RGB数据+深度数据。处理的方法为先采用2D的人脸识别方法处理2D的RGB数据,然后再处理深度数据。
3D人脸检测
很多3D人脸检测的方式还是采用RGB图像检测出人脸区域,然后再获取这个区域的RGB数据、D(深度)数据,重新组合获取到人脸的3D数据。
3D图像数据RGBD进行人脸检测,目前相对2D的人脸检测不是很成熟,目前并没有比较成熟的基于点云数据的人脸检测算法,基于点云的目标检测算法已经有研究,人脸检测也属于目标检测的范畴,目前3D的目标检测方法有:
/1/
基于3D的方法
3d fully convolutional network for vehicle detection in point cloud将整个场景的点云转换为体积网格,并使用3D体积CNN作为对象提议(proposal)和分类。由于3D卷积和大型3D搜索空间的数据量非常大,这些方法的计算成本通常相当高。
/2/
点云的深度学习
在特征学习之前,大多数现有方法将点云转换为图像或体积形式。 Voxnet将点云体素化为体积网格,并将图像CNN推广到3D CNN。Vote3deep设计更有效的3D CNN或利用点云稀疏性的神经网络体系结构。
由于3D数据的复杂性、稀疏性、不确定性,所以处理3D目标检测的速度在NVIDIA GTX 1080i GPU上,帧速率大约为7fps。(出自 Frustum PointNets for 3D Object Detection from RGB-D Data)
2D+人脸检测
该方法实际上是将2D人脸检测的方法用到3D人脸检测,将3D图像数据分为RGB数据加深度数据,首先在分开的RGB数据上取到人脸的boundingbox,然后根据这个boundingbox获取相应的深度信息。其实就是2D的人脸检测,并没有使用到深度的信息。该方法相对基于点云数据的3D人脸检测有更多的优点:计算量少、算法相对成熟、计算速度快。
目前很多基于3D人脸识别的人脸检测都是使用这种方法。
五、特征提取
3D人脸特征提取跟2D+人脸特征提取是两个不一样的过程。3D人脸特征提取处理的是3D的数据,如点云、体素等,这些数据是完整的,立体的,而2D+人脸特征提取将3D的人脸数据分为2D的RGB数据+深度数据,处理的方法为先采用2D的人脸特征提取的方法先提取RGB数据的特征,然后再处理深度数据。
3D人脸特征提取
跟2D人脸特征提取步骤一样,特征提取就是将人脸图像数据输入给神经网络,输出对应图像数据的人脸特征。使用这个特征跟库中的特征进行对比,计算差异就能判断出对比的两个人脸特征是不是同一个人。但是3D人脸特征提取处理的图像数据基本上是点云数据(当然还有别的表示方法,这里只分析主流的基于点云的方法),点云数据在3D人脸应用中也会存在以下特点:
/1/
无序性
因为目标视角位置的影响,点云数据的三维点的排列顺序千差万别,这样的数据很难直接通过End2End的模型处理。
/2/
稀疏性
在机器人和自动驾驶的场景中,激光雷达的采样点覆盖相对于场景的尺度来讲,具有很强的稀疏性。在KITTI数据集中,如果把原始的激光雷达点云投影到对应的彩色图像上,大概只有3%的像素才有对应的雷达点。这种极强的稀疏性让基于点云的高层语义感知变得尤其困难。
/3/
信息量有限
点云的数据结构就是一些三维空间的点坐标构成的点集,本质是对三维世界几何形状的低分辨率重采样,因此只能提供片面的几何信息。
面对以上困难,PointNet给出了自己的解决方案。PointNet是第一种直接处理无序点云数据的深度神经网络。PointNet是开创性的,首次提取将点云数据送入到神经网络的模型,在此之前,点云数据的处理基本是参照2D神经网络的方式,单独处理点云数据中的RGB,深度信息则另外处理,PointNet则将点云数据的RGBD信息作为一个整体处理,并设计了新的神经网络结构,它很好地尊重了输入点的置换不变性,为从对象分类,目标分割到场景语义分析等应用程序提供统一的体系结构。虽然简单,但PointNet非常高效和有效。PointNet的网络结构如下:

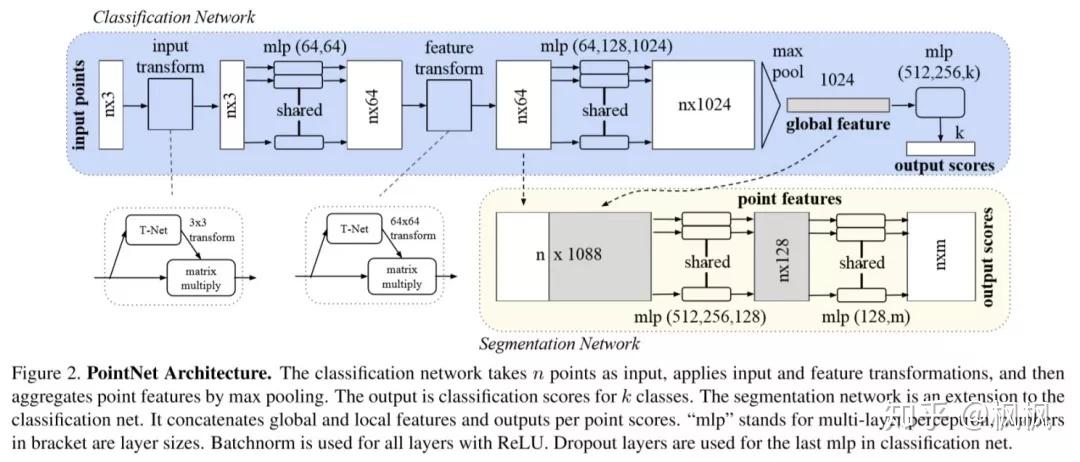
图片出自: https:// arxiv.org/pdf/1612.0059 3.pdf
PointNet设计的目的是解决点云数据的分类和目标的分割,所以可以使用PointNet中神经网层输入到分类器的数据作为特征输出,设计一个新的损失函数即可完成基于点云数据的人脸特征提取模型。
当然PointNet之后,相继出现了一批优秀的点云数据处理模型:PointNet++、PointCNN、PointSIFT、VoxelNet、Pointwise Convolutional Neural Networks 等。
上面的基于点云数据的处理模型都是可以用来作为提取人脸特征的模型,模型确定了,剩下的事情就是损失函数的设计、训练、推理。
损失函数设计
因为人脸图像数据经过特征提取模型转换之后输出的特征在数学上都是结构化数据,不管输入的图片数据是2D的还是3D的,特征数据结构是一样的,所以损失函数的设计3D的人脸特征提取跟2D的人脸特征提取是基本可以通用。损失函数的设计可以参考2D人脸识别使用的损失函数,如softmax、sphereface、cosface、arcface、triplet loss等。
— 训练 —
给设计好的神经网络模型+损失函数灌入大量的数据,根据损失函数计算的结果调整神经网络模型的权重参数,反复调整,使损失函数计算的结果最小或者不再变化,则停止训练,保存权重文件。Apple称在推出faceID是就使用了10亿张3D的图像进行训练,该10亿张3D照片是Apple自己使用设备获取的,是非公开的。我们要训练自己的3D人脸识别模型的话首先就得收集大量的3D人脸图像,3D人脸数据集太少是3D人脸识别没有很好普及的原因之一。
— 推理 —
推理部分跟2D人脸特征提取的基本一致,都是完成图像数据的输入,经过神经网络的计算,输出特征数据。这个神经网络是怎么计算由前面的神经网络设计、损失函数设计、训练决定。
2D+人脸特征提取
2D+人脸特征提取的实现就是将3D的数据人为的分开成RGB数据、D数据,将2D人脸特征提取的方法用在分开后的RGB数据上,先提取RGB图像数据的特征,然后再获取深度信息D的特征。而深度信息的特征提取有如下方法:
1)使用部分深度信息作为辅助特征
如鼻子的高度、脸型,嘴巴鼻子的高度比等,这些是比较简单的、而且是人可以理解的信息(相对于CNN提取的不可理解的特征而言)。
2)使用类似RGB图像数据的处理方式
设计一个CNN神经网络,把人脸的深度图像当成是一张灰度的照片进行训练,得出一个分类的模型,从而辅助人脸基于RGB部分的2D人脸识别。
上面的这两种深度信息特征提取方式借鉴了2D人脸识别的方法,处理速度、实现方法上有很大的优势。
2D+人脸识别无法处理侧脸的情况,侧脸时不管是RGB数据还是深度数据都是会发生改变的,而点云数据则没有变化。
六、信息比对
信息比对是识别的过程,就是处理人脸图像数据提取出来的特征,处理的方法跟2D人脸识别的信息比对类似。主要计算两组数据的相似度,计算的方式有余弦距离、欧氏距离、曼哈顿距离、明可夫斯基距离、皮尔森相关系数、斯皮尔曼等级相关系数等。
总结
基于上述分析,2D人脸识别跟3D人脸识别的特点如下:
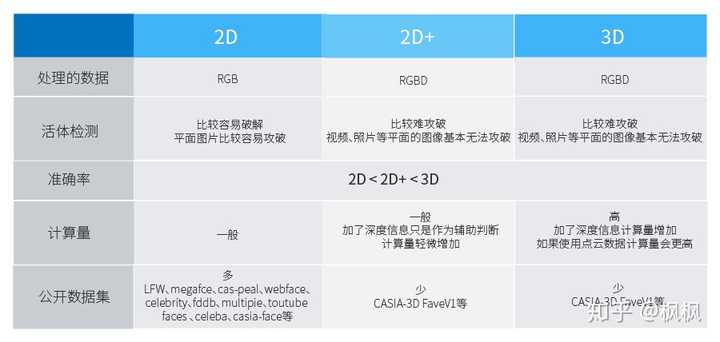
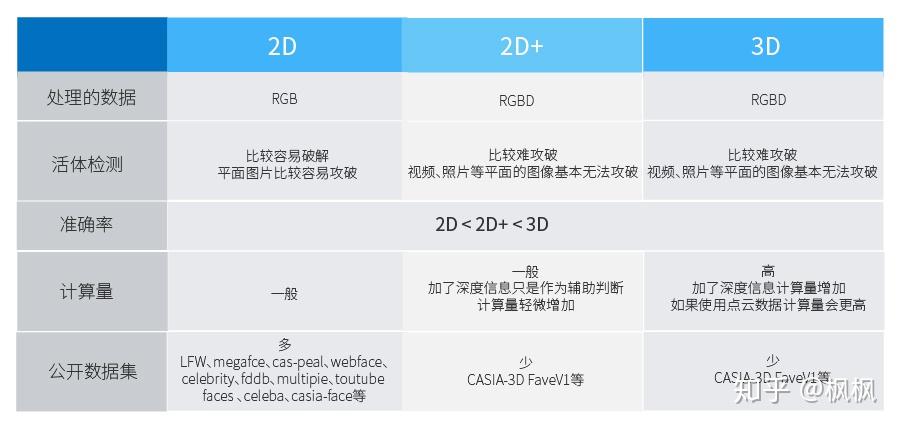
2D、3D人脸识别的区别实际就是 图像数据的差异 。2D的人脸识别只有 RGB数据 ,而3D人脸识别基本是 点云数据 ,点云数据多了深度信息,所以基于点云处理的模型比只有RGB数据的模型具有更高的识别准确率、更高的活体检测准确率。但是点云网络的计算因为点云数据的复杂性,需要消耗大量的运算资源,PointNet官方给出的单帧处理速度是0.17s。如果是2D+人脸识别的话,计算量跟2D人脸识别相比只是多了计算深度数据的特征,不会增加很大的计算量。
2D人脸识别有更成熟的图像预处理算法、人脸获取模型、特征提取模型,还有大量的数据支撑,工程上使用起来会更方便。使用基于2D人脸识别加深度信息辅助判断的2D+人脸识别能解决一定的问题,在活体检测准确率、识别准确率上都会比2D的人脸识别有提高。基于点云的3D数据处理不仅在人脸识别,在自动驾驶、机器视觉等领域都有很大的优势。2D、3D数据处理各有优势与不足,在不断的发展中相互借鉴,相互促进。

1、简单直接的举个例子:2D vs 3D
人脸识别的原理,可以简单的把摄像头传感器看做是人的眼睛,识别的过程就相当于用人的眼睛去看待2D图片和3D物体一样的感觉,直观的差别就是有没有立体深度信息,深度的结果差异就是识别物体的维度信息差异。
2、人脸识别2D与3D的本质区别。
可以用如下表格归纳一下:
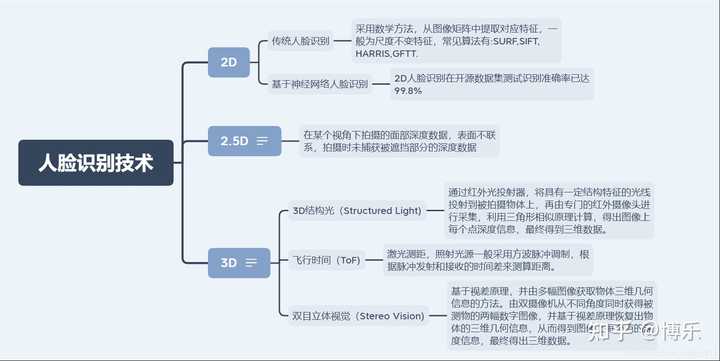
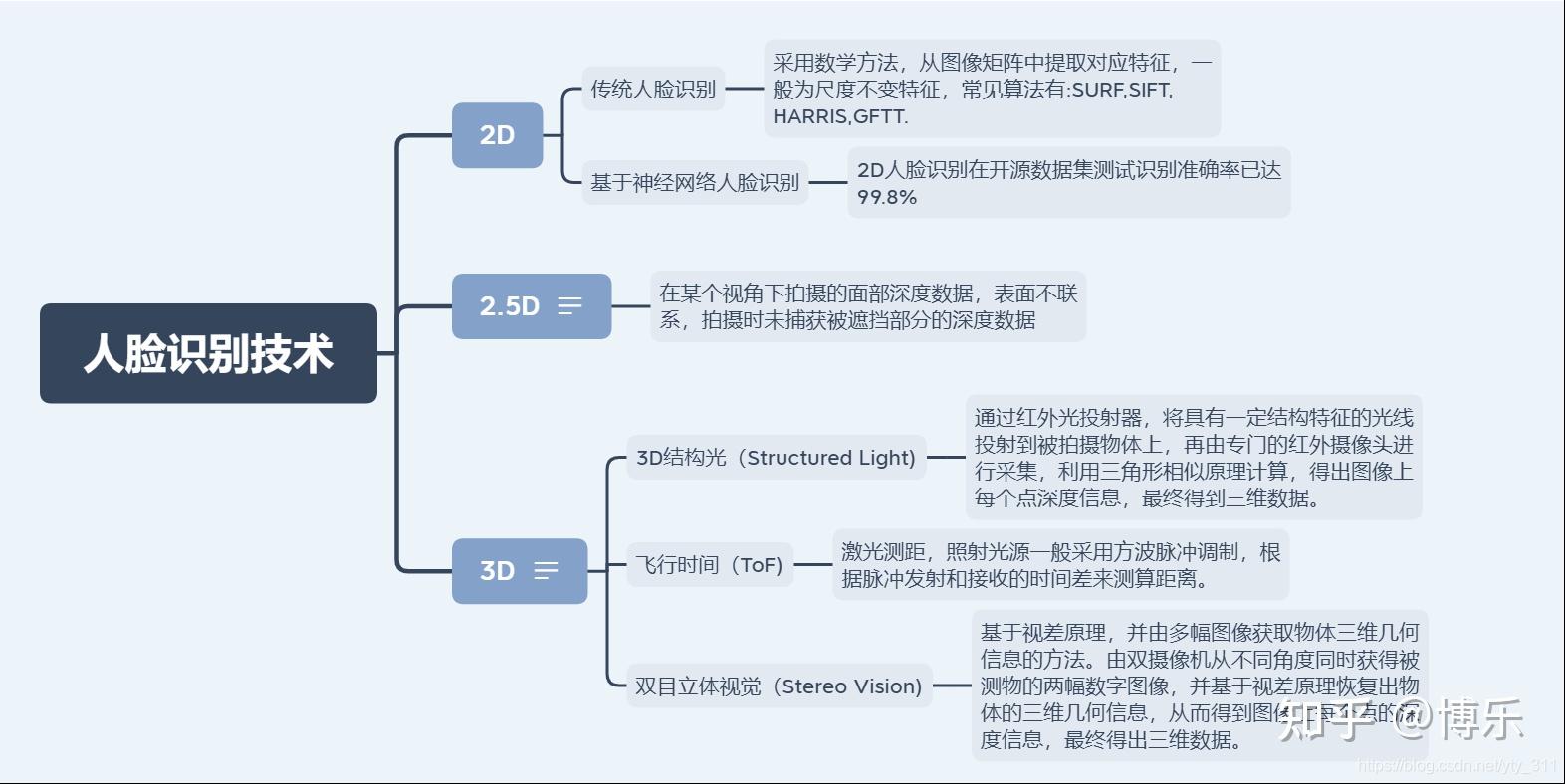
2D人脸识别技术成本低,但是致命的问题是在防伪方面门槛很低,可以被比如打印照片,图片,视频画面等2D人脸源攻击。
3D人脸识别是在增加了深度信息的识别技术,根据原理的不同分为3D结构光,双目识别,TOF三种类别,在不同的场景都有不同程度的应用。
相关专题文章参考:
3、当前2D流行,3D应用普及度差一些的原因
要说2D人脸比3D流行,当前市场环境确实是这样的,究其原因也很简单:
1)技术发展有先后
最早2D人脸识别技术发展和应用比较广泛,也是市场的需求和类似支付等安全级别要求高的场景的推动,3D人脸识别技术才开始发展和衍变。
就好比,现在市场上燃油车的比例就是高于电动车一样,不见得是孰好孰坏,主要原因是的发展先后的问题。
2)成本,成本,成本!
对于很多应用来说,安全性和防伪性要求没有那么高,那么厂家和应用方更在乎的是成本,很显然2D摄像头自然比3D的无论是硬件成本还是算法投入方面都极具优势。
比如捷顺,海康等老牌厂家的用在社区的门禁对讲设备这些的终端还有不少是2D的。
但是在支付方面,比如阿里的人脸识别支付终端,全部是采用的3D结构光的人脸识别技术,支付金融级的,安全是第一位的。
在智能门锁上面,在18年左右中山永康大部分人脸识别产品都是2D的,行业内也爆出过使用照片,视频等攻击手法开锁的问题,当前2022年,很多大品牌的智能锁都使用3D人脸识别技术了,主要还是考虑安全。