


正则表达式全知识点,一篇文章说清楚

正则表达式全知识点,一篇文章说清楚


我是@老K玩代码,专注分享实战项目和最新行业资讯,已累计分享超1000实战项目!
前言
正则表达式
又称
Regex
,是文本处理领域中非常常见的概念,这个概念方法在各个应用领域和编程语言下都有极大的运用价值,是每个编程人员都应该熟悉的字符串过滤技巧。
在学习
正则表达式
的过程中,相信很多小伙伴都有这样的困扰:网上没有系统的
正则表达式
的学习材料。
今天老K就给大家整理了一篇文章,详细介绍了
正则表达式
的各种概念。
我们就以:
正则表达式又称Regexr,可以用普通字符(a~z 26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。
作为
示例文本
,开始介绍吧。
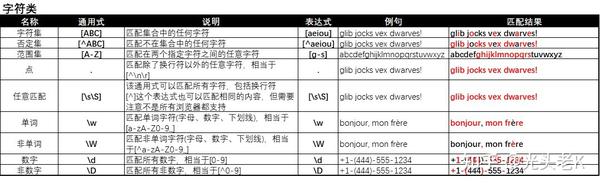
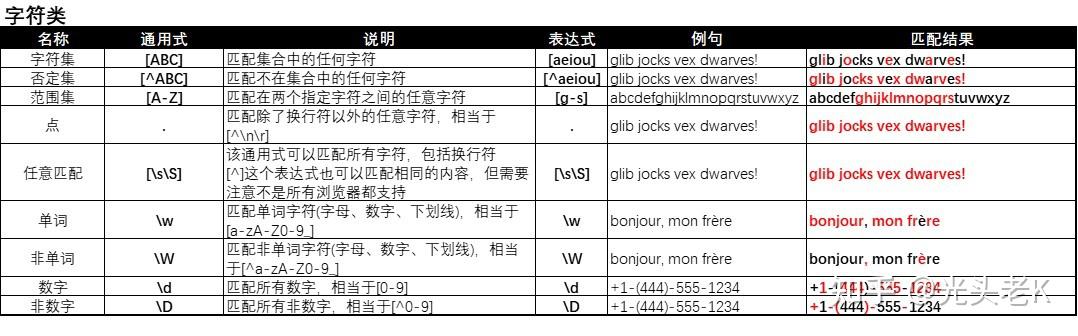
一、【字符类】匹配
-
通过
.可以匹配除换行符以外的所有字符,例:
表示所有字符:
/./g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。
-
通过
\w、\d、\s分别用来匹配罗马字符、数字、空格,例: -
表示所有罗马字符
:
/\w/g
匹配结果 :
正则表达式又称Regexr,可以用普通字符(a~z26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。 -
表示所有数字:
/\d/g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。 -
表示所有空格:
/\s/g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。
3. 通过
\W
、
\D
、
\S
用来匹配非罗马字符、非数字、非空格的字符串,例:
-
表示所有非罗马字符:
/\W/g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z 26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。 -
表示所有非数字:
/\D/g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。 -
表示所有非空格:
/\s/g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z_26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。
4. 用
[abc]
的方式设定集合,匹配集合中的字符,例:
表示"普/通/字/符"中任意字符:
/[普通字符]/g
匹配结果:
正则表达式又称Regexr,可以用
普
通
字
符
(a~z 26个英文
字
母)和特殊
字
符
(元
字
符
)组合表示某些特定
字
符
模式。
5. 用
[^abc]
的方式设定集合取反,匹配不在集合中的字符,例:
表示不在"普/通/和/特/殊/字/符"中的任意字符:
/[^普通和特殊字符]/g
结果:
正
则
表
达
式
又
称
R
e
g
e
x
r
,
可
以
用
普通字符
(
a
~
z
2
6
个
英
文
字
母
)
和特殊字符
(
元
字符
)
组
合
表
示
某
些
特定字符
模
式
。
6. 用
[a-g]
的方式表示区间,选择从a到g的字符,例:
表示在a到g的字符:
/[a-g]/g
结果:
正则表达式又称R
e
g
e
xr,可以用普通字符(
a
~z 26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。
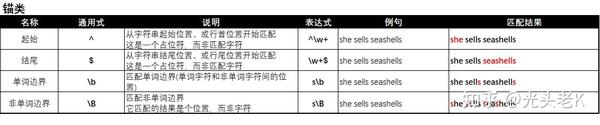
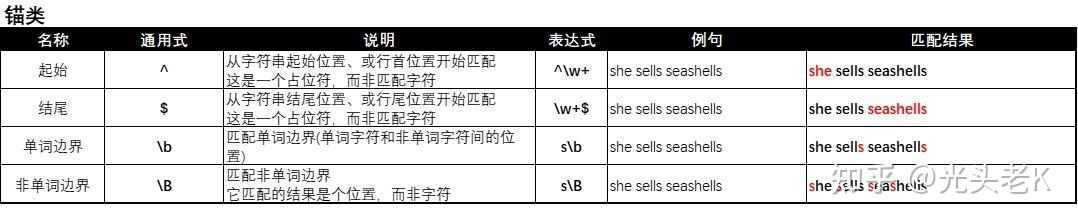
二、【锚类】匹配
-
用
^abc表示匹配字符串起始位置的字符,例:
表示在字符串开头的“正则”二字:
/^正则/g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z 26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。
说明:
如果用/^普通/g去匹配就会匹配失败,因为“普通”两字不在字符串开头
-
用
abc$表示匹配字符串结尾位置的字符,例:
表示在字符串结尾的"字符模式。":
/字符模式。$/g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z 26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。
说明:
如果"字符模式。"这几个字符不在字符串结尾,则会匹配失败。这里尤其需要注意,如果语句结尾有换行符,则字符串是以换行符结尾,需要加入\n才行
-
用
\b表示单词边界和\B非单词边界,此处的单词边界以空格或换行符作为判断逻辑,例: -
用
\b表示在单词边界的数字:
/\b\d/g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。
说明:
匹配文本里有2个数字,但由于6不在单词边界空格后面,所以没有匹配6而匹配到了2 -
用
\B表示不在单词边界的数字:
/\B\d/g
匹配结果:
正则表达式又称Regexr,可以用普通字符(a~z 26个英文字母)和特殊字符(元字符)组合表示某些特定字符模式。
说明:
匹配文本里有2个数字,但由于2在单词边界空格后面,所以没有匹配2而匹配到了6
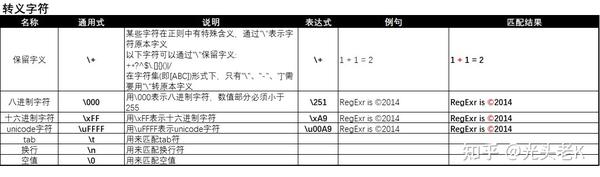
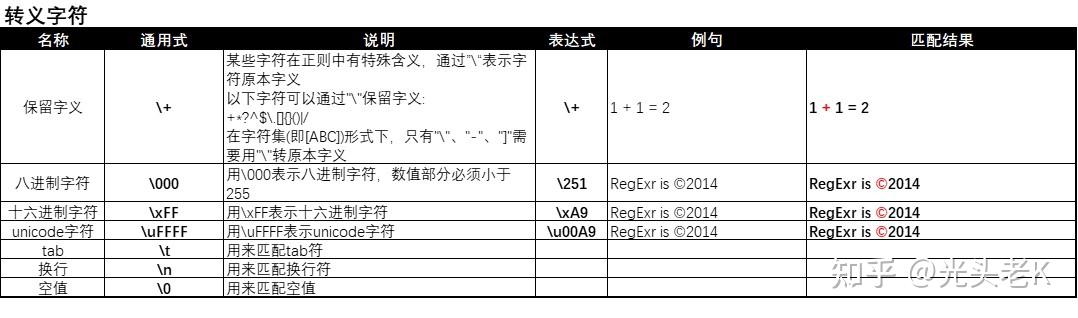
三、转义字符
由于匹配需要,很多时候会用到一些
\
+字符的组合,表示特殊含义而非其字符本身的含义。由于这种表示方式转换了字符本身的含义,所以被称为
转义字符
。
-
转义特殊字符:
-
\.:由于.在正则中表示所有字符,所以用\.表示字符"."本身; -
\*:由于*在正则中表示数量词,所以用\*表示字符"*"本身; -
\\:由于\在正则中表示转义模式,所以用\\表示字符"\"本身;
2. 字母类转义字符:
-
\t:此处用\t表示制表空格,而非字符"t"; -
\n:此处用\n表示换行符,而非字符"n"; -
\r:此处用\r表示退格键操作,而非字符"r";
四、字符组
有时候需要根据条件检索特定字符,如在电子邮箱中找到用户名,就需要先从文本中用正则找到电子邮箱的字段,再在电子邮箱的字段里用正则找到用户名,这样会让简单的工作变得复杂。
字符组让这个工作变得容易起来。这里,我们用:
hahaha haa hah!
作为例句,了解一下字符组的使用吧:
-
用圆括号表示字符组,如
(abc),见下例:
/(ha)+/g
匹配结果:
hahahahaahah!
-
用
\1表示正则表达式里的第一个字符组,\2表示正则表达式里第二个字符组,\3、\4依次类推:
(\w)a\1
匹配结果:
hahdadbad dabgaggab
说明:
此例中,当(\w)匹配的结果为字符h,则\1就表示h。\1的匹配结果需要参考第一个字符组,即(\w)的结果。
五、相邻判断
匹配例句:
1pt 2px 3em 4px
-
可以用
(?=ABC)、(?!ABC)的表达式,表示前瞻判断:
-
正向前瞻判断,示例如下:
表示在字符"px"前的数字:
/\d(?=px)/g
匹配结果:
1pt2px 3em4px
说明:
此处的(?=px)表示一个占位符,而非具体的字符 -
负向前瞻判断,示例如下:
表示不在字符"px"前的数字 :
/\d(?!px)/g
匹配结果:
1pt 2px3em 4px
说明:
此处的(?!px)表示一个占位符,而非具体的字符 -
可以用
(?<=ABC)、(?<!ABC)的表达式,表示回顾判断:
-
正向回顾判断,示例如下:
表示在字符"p"后的罗马字符:
/(?<=p)\w/g
匹配结果:
1pt2px3em 4px -
负向回顾判断,示例如下:
表示不在字符"p"后的罗马字符:
/(?<!p)\w/g
匹配结果:
1pt2px3em4px
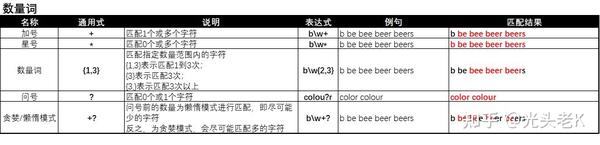
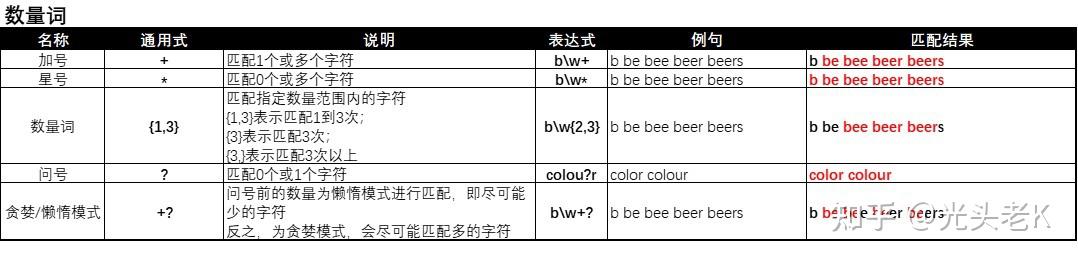
六、数量词
匹配例句:
b be bee beer beers beeeee
-
用数字表示的数量词:
-
{n}表示匹配n个字符:
/e{2}/g
匹配结果:
b be beebeer beers beeeee -
{n,}表示匹配n个以上字符:
/e{2,}/g
匹配结果:
b be beebeer beers beeeee -
{n,m}表示匹配n到m个字符 :
/e{2,3}/g
匹配结果:
b be beebeer beers beeeee
2. 用特殊符号
*
、
+
、
?
表示的数量词:
-
*表示0个或多个字符:
/e*/g
匹配结果:
b bebeebeer beers beeeee -
+表示1个或多个字符:
/e+/g
匹配结果 :
b bebeebeer beers beeeee -
?表示0个或1个字符:
/b?/g
匹配结果:
bbebeebeerbeersbeeeee -
关于
*和+差别的说明:
有些小伙伴可能会困惑在匹配时*和+都是匹配多个,但匹配0个和1个的差别是什么?有这个问题的小伙伴可以看下例是如何匹配字符串abc:
/a.*bc/g能匹配上述字符串;
/a.+bc/g不能匹配上述字符串,因为这个表达式不允许a和b没有字符;
七、贪婪模式
-
.+表示用贪婪模式进行匹配:
/b\w+/g
匹配结果:
bbebeebeerbeersbeeeee
-
.+?表示用非贪婪模式(懒惰模式)进行匹配
/b\w+?/g
匹配结果:
bbebeebeerbeersbeeeee
-
贪婪模式和懒惰模式:
贪婪模式 就是在满足表达式的前提下,匹配尽可能多的字符;
懒惰模式 ,又称 非贪婪模式 ,表示在满足表达式的前提下,匹配尽可能少的字符。
总结
正则表达式是一项非常实用的技术,是每一个程序员都应该掌握的技能。
老K将所有的知识点汇总成了图表:




高清原图和原始文件获得方式见文末。
我是@老K玩代码,专注分享实战项目和最新行业资讯,已累计分享超1000实战项目!
薇信伀从呺 关键词/ 正则表达式 /,相关学习资源。
