


谱聚类方法推导和对拉普拉斯矩阵的理解

谱聚类可以看作是基于图的一种聚类方法,在各大论坛有许多介绍谱聚类算法的博客,但是在看的过程中,总是会存在各种各样的困惑,尤其是拉普拉斯矩阵的引入等一些列问题上介绍的不是很清楚。这里基于 Ncut 文章中的推导,给出谱聚类算法的一个整体的推导过程和一些重要细节。
首先有必要简单介绍一些图的基本知识,为了尽可能的简单,我们仅仅介绍必要的概念:
无向图定义:
定义图无向图 G(V,E,W) ,其中, V 为图中的顶点, E 为图中的边, W 为边上权值构成的矩阵。举个栗子:
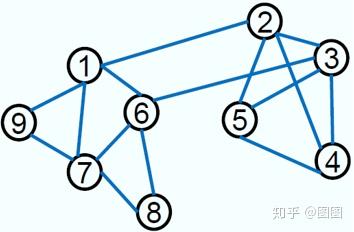
对这样的一幅图,如果我们认为连接的节点的权值是
1
,没有连接的节点的权值为
0
,则此时我们可以得到一个权值矩阵:
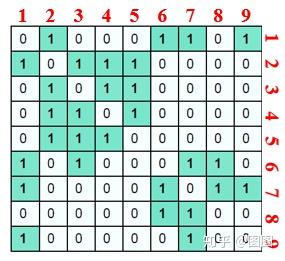
其中红色数字表示节点的标号,图中的每一行和每一列是对称的,他们都反映了该节点与其他节点的连接情况。
度:
定义顶点的
度
为该顶点与其他顶点连接权值之和:
{d_i} = \sum\limits_{j = 1}^N {{w_{ij}}}
度矩阵
D
为对角矩阵,上面图对对应的度矩阵为:
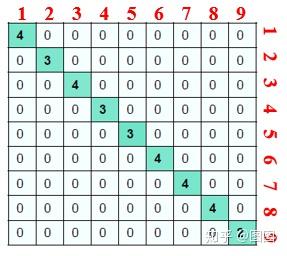
子图和子图的连接权
我们可以将上面的图划分成两个子图,如下图所示:
定义
A
和
B
是图
G
中两个不相
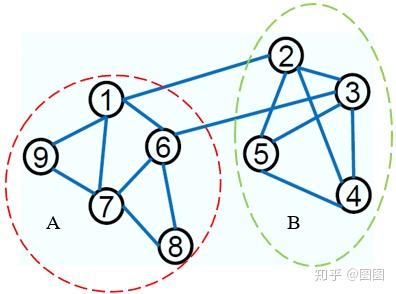
的子图,则定义子图的连接权值:
W(A,B):= \sum\limits_{i \in A,j \in B} {{w_{ij}}}
从图割问题到谱聚类
对于上面的图,我们希望通过一种最优的划分将其分为两个部分,实际上
A
和
B
两个子图的划分就是一种最优的划分:
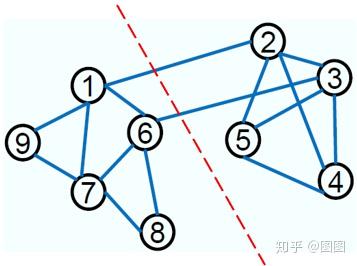
我们定义这样的划分满足
cut(A,B):= \sum\limits_{i \in A,j \in B} {{w_{ij}}}
最小。当图中有
N
个节点,有
k
个类别的情况,我们希望:
\min cut({A_1},...,{A_N}) = \sum\limits_{i = 1}^k {W({A_i},{{\bar A}i})}
这样的一个图划分问题称为最小割问题。然而在实际中,基于最割理论并不能很好的实现划分,这是因为,当仅仅依赖最小割的划分方法的话,在对图进行划分时倾向于将图中的孤立的节点划分成一类。其实这也非常容易理解,因为最小割的定义 cut(A,B) = \sum\limits_{i \in A,j \in B} {{w_{ij}}} 实际上是与两个子图之间的连接边的数量是正相关的,也就是说连接边的数量越多,该值越大。在对图划分的时候,任何一个对孤立节点的划分都会小于对该节点所在类的一个更大的子图的划分的 cut 值,所以在在该目标函数下容易产生孤立点的划分结果。
聚类的定义: 聚类就是对大量未知标注的数据集,按数据的内在相似性将数据划分成多个类别,使得类别内数据相似度较大而类别间的数据相似度较小。
Normalized cut
针对这个问题,
Normalized Cuts and Image Segmentation
中提出了
Normalized Cut
,定义如下:
Ncut({A_1},...,{A_2}): = \frac{1}{2}\sum\limits_{i = 1}^k {\frac{{W({A_i},{{\bar A}i})}}{{vol({A_i})}}} = \sum\limits{i = 1}^k {\frac{{cut({A_i},{{\bar A}i})}}{{vol({A_i})}}}
其中 vol(A_i)=\sum\limits_{a \in {A_i},b \in V} {{w_{ab}}} 。也就是说,在计算每一类的割的时候,Normalized Cut 考虑的是每类割占该类所有节点到图中所有节点连接之和的比例。此时我们分析两类的情况,考虑边上权值为简单的 [0,1] ,上式子可以写为:
Ncut(A,B) = \frac{{cut(A,B)}}{{vol(A)}} + \frac{{cut(A,B)}}{{vol(B)}}
这时我们可以假设
B
类为一个孤立节点,此时
vol(A)
为除了与
B
中节点有连接的所有边和,而
vol(B)=cut(A,B)
,当图的规模比较大时,此时
Ncut(A,B) \to 1
。不再是该目标函数所能取得的最小值(可以观察发现最小值时小于
1
的)
给定图
G(V,E)
的顶点
V
一个划分
A
,
B
,令
x
为
N=|V|
维的指示向量。
v_i \in A
时
x_i=1
,
v_i \in B
时
x_i=-1
。令
{d_i} = \sum\limits_{j \in N} {{w_{ij}}}
表示节点
i
与其他所有节点间的连接之和。此时我们有:
\begin{array}{l} Ncut(A,B) = \frac{{cut(A,B)}}{{vol(A)}} + \frac{{cut(B,A)}}{{vol(B)}}\ \\= \frac{{\sum\nolimits_{({x_i} > 0,{x_j} < 0)} { - {w_{ij}}{x_i}{x_j}} }}{{\sum\nolimits_{({x_i} > 0)} {{d_i}} }} + \frac{{\sum\nolimits_{({x_i} < 0,{x_j} > 0)} { - {w_{ij}}{x_i}{x_j}} }}{{\sum\nolimits_{({x_i} < 0)} {{d_i}} }} \end{array}
令 D = diag(d_i) , W={w_{ij}} ,
k = \frac{{\sum\nolimits_{({x_i} > 0)} {{d_i}} }}{{\sum\nolimits_{i \in N} {{d_i}} }}
{\bf{1}} 为 N \times 1 的全 1 向量。 令 \frac{{{\bf{1}} + x}}{2} 和 \frac{{{\bf{1}} - x}}{2} 分别为 x_i>0 和 x_i<0 的指示向量。 以 \frac{{{\bf{1}} + x}}{2} 为例, {(\frac{{{\bf{1}} + x}}{2}})^TW 所得向量中每个元素表示的是图中节点 i 与所有子图 A 中节点的连接权值之和。 {(\frac{{{\bf{1}} + x}}{2}})^TW(\frac{{{\bf{1}} - x}}{2}) 则能够得到子图 A 中与子图 B 中节点权值之和。而且根据 D 的定义我们有:
\eqalign{ & {{{{(1 + x)}^T}} \over 2}W{{(1 - x)} \over 2} \cr & = {{{{(1 + x)}^T}} \over 2}W(1 - {{(1 + x)} \over 2}) \cr & = {{{{(1 + x)}^T}} \over 2}W1 - {{{{(1 + x)}^T}} \over 2}W{{(1 + x)} \over 2} \cr & = {{{{(1 + x)}^T}} \over 2}diag(W1){{(1 + x)} \over 2} - {{{{(1 + x)}^T}} \over 2}W{{(1 + x)} \over 2} \cr & = {{{{(1 + x)}^T}} \over 2}(D - W){{(1 + x)} \over 2} \cr}
注意:
\eqalign{ & {{{{(1 + x)}^T}} \over 2}diag(W1){{(1 + x)} \over 2} \cr & = \left[ {\matrix{ 1 & 0 & \cdots & 1 \cr } } \right]\left[ {\matrix{ {{d_1}} & \cdots & 0 \cr \vdots & \ddots & \vdots \cr 0 & \cdots & {{d_n}} \cr } } \right]\left[ {\matrix{ 1 \cr 0 \cr \vdots \cr 1 \cr } } \right] \cr & = \left[ {\matrix{ 1 & 0 & \cdots & 1 \cr } } \right]\left[ {\matrix{ {{d_1}} \cr {{0}} \cr \vdots \cr {{d_n}} \cr } } \right] \cr & \left[ {\matrix{ 1 & 0 & \cdots & 1 \cr } } \right]\left[ {\matrix{ {{d_1}} \cr {{d_2}} \cr \vdots \cr {{d_n}} \cr } } \right] \cr & = {{{{(1 + x)}^T}} \over 2}W1 \cr}
则上式可化为:
\begin{array}{l} Ncut(A,B) = \frac{{cut(A,B)}}{{vol(A)}} + \frac{{cut(B,A)}}{{vol(B)}}\ \\= \frac{{\sum\nolimits_{({x_i} > 0,{x_j} < 0)} { - {w_{ij}}{x_i}{x_j}} }}{{\sum\nolimits_{({x_i} > 0)} {{d_i}} }} + \frac{{\sum\nolimits_{({x_i} < 0,{x_j} > 0)} { - {w_{ij}}{x_i}{x_j}} }}{{\sum\nolimits_{({x_i} < 0)} {{d_i}} }}\ \\= \frac{{{{(\frac{{{\bf{1}} + x}}{2})}^T}W(\frac{{{\bf{1}} - x}}{2})}}{{k{{\bf{1}}^T}D{\bf{1}}}} + \frac{{{{(\frac{{{\bf{1}} - x}}{2})}^T}W(\frac{{{\bf{1}} + x}}{2})}}{{(1 - k){{\bf{1}}^T}D{\bf{1}}}}\ \\= \frac{{{{(\frac{{{\bf{1}} + x}}{2})}^T}(D - W)(\frac{{{\bf{1}} + x}}{2})}}{{k{{\bf{1}}^T}D{\bf{1}}}} + \frac{{{{(\frac{{{\bf{1}} - x}}{2})}^T}(D - W)(\frac{{{\bf{1}} - x}}{2})}}{{(1 - k){{\bf{1}}^T}D{\bf{1}}}}\ \\= \frac{1}{4}[\frac{{{{({\bf{1}} + x)}^T}(D - W)({\bf{1}} + x)}}{{k{{\bf{1}}^T}D{\bf{1}}}} + \frac{{{{({\bf{1}} - x)}^T}(D - W)({\bf{1}} - x)}}{{(1 - k){{\bf{1}}^T}D{\bf{1}}}}]\ \\= \frac{1}{4}[\frac{{({x^T}(D - W)x + {{\bf{1}}^T}(D - W){{\bf{1}}^T})}}{{k(1 - k){{\bf{1}}^T}D{\bf{1}}}} + \frac{{2(1 - 2k){{\bf{1}}^T}(D - W)x}}{{k(1 - k){{\bf{1}}^T}D{\bf{1}}}}] \end{array}
令:
\begin{array}{l} \alpha (x) = {x^T}(D - W)x\ \\\beta (x) = {{\bf{1}}^T}(D - W)x\\\ \gamma = {{\bf{1}}^T}(D - W){\bf{1}}\ M = {{\bf{1}}^T}D{\bf{1}} \end{array}
则:
\begin{array}{l} = \frac{1}{4}[\frac{{(\alpha (x) + \gamma ) + 2(1 - 2k)\beta (x)}}{{k(1 - k)M}}]\ \\= \frac{1}{4}[\frac{{(\alpha (x) + \gamma ) + 2(1 - 2k)\beta (x)}}{{k(1 - k)M}} - \frac{{2(\alpha (x) + \gamma )}}{M} + \frac{{2\alpha (x)}}{M} + \frac{{2\gamma }}{M}] \end{array}
在最小化的过程中可以将常数项去掉,也就是 \gamma =0 ,同时 \frac{1}{4} 也可以去掉,此时: \begin{array}{l} = \frac{{(1 - 2k + 2{k^2})(\alpha (x) + \gamma ) + 2(1 - 2k)\beta (x)}}{{k(1 - k)M}} + \frac{{2\alpha (x)}}{M}\ \\ = \frac{{\frac{{(1 - 2k + 2{k^2})}}{{{{(1 - k)}^2}}}(\alpha (x) + \gamma ) + \frac{{2(1 - 2k)}}{{{{(1 - k)}^2}}}\beta (x)}}{{\frac{k}{{(1 - k)}}M}} + \frac{{2\alpha (x)}}{M} \end{array}
令 b = \frac{k}{{(1 - k)}} ,且 \gamma =0 ,则
\begin{array}{l} = \frac{{(1 + {b^2})(\alpha (x) + \gamma )}}{{bM}} + \frac{{2(1 - {b^2})\beta (x)}}{{bM}} + \frac{{2b\alpha (x)}}{{bM}}\ \\ = \frac{{(1 + {b^2})(\alpha (x) + \gamma )}}{{bM}} + \frac{{2(1 - {b^2})\beta (x)}}{{bM}} + \frac{{2b\alpha (x)}}{{bM}} - \frac{{2b\gamma }}{{bM}}\ \\ = \frac{{(1 + {b^2})({x^T}(D - W)x + {{\bf{1}}^T}(D - W){{\bf{1}}^T})}}{{b{{\bf{1}}^T}D{\bf{1}}}}\ + \frac{{2(1 - {b^2}){{\bf{1}}^T}(D - W)x}}{{b{{\bf{1}}^T}D{\bf{1}}}}\ + \frac{{2b{x^T}(D - W)x}}{{b{{\bf{1}}^T}D{\bf{1}}}} - \frac{{2b{{\bf{1}}^T}(D - W)x}}{{b{{\bf{1}}^T}D{\bf{1}}}}\ \\ = \frac{{{{({\bf{1}} + x)}^T}(D - W)({\bf{1}} + x)}}{{b{{\bf{1}}^T}D{\bf{1}}}}\ + \frac{{{b^2}{{({\bf{1}} + x)}^T}(D - W)({\bf{1}} + x)}}{{b{{\bf{1}}^T}D{\bf{1}}}}\ - \frac{{2b{{({\bf{1}} + x)}^T}(D - W)({\bf{1}} + x)}}{{b{{\bf{1}}^T}D{\bf{1}}}}\ \\= \frac{{{{[({\bf{1}} + x) - b({\bf{1}} + x)]}^T}(D - W)[({\bf{1}} + x) - b({\bf{1}} + x)]}}{{b{{\bf{1}}^T}D{\bf{1}}}} \end{array}
此时令 y=(1+x)-b(1-x) ,则有
{y^T}D{\bf{1}} = \frac{1}{2}(\sum\limits_{{x_i} > 0} {{d_i} - b\sum\limits_{{x_i} < 0} {{d_i}} } ) = 0
b = \frac{k}{{1 - k}} = \frac{{\sum\nolimits_{({x_i} > 0)} {{d_i}} }}{{\sum\nolimits_{({x_i} < 0)} {{d_i}} }}
\begin{array}{l} {y^T}Dy = \sum\limits_{{x_i} > 0} {{d_i} +{b^2}\sum\limits_{{x_i} < 0} {{d_i}} } \ \\= b\sum\limits_{{x_i} < 0} {{d_i}} + {b^2}\sum\limits_{{x_i} < 0} {{d_i}} \ \\= b(\sum\limits_{{x_i} < 0} {{d_i}} + b\sum\limits_{{x_i} < 0} {{d_i}} )\ \\= b{{\bf{1}}^T}D{\bf{1}} \end{array}
则最终,我们有:
\min Ncut(A,B) = \mathop {\min }\limits_x Ncut(x) = \mathop {\min }\limits_y \frac{{{y^T}(D - W)y}}{{{y^T}Dy}}
且满足 y_i \in \{1,-b\} , y^TD{\bf{1}}=0 我们发现这个形式刚好是广义瑞利熵的形式,对于上述形式的问题的最小化,可以利用拉格朗日乘子法进行求解:
L(y) = {y^T}(D - W)y - \lambda ({y^T}Dy - c)
其中 \lambda 为拉格朗日乘子。
注意: 这里实际上已经有了一个近似,在我们通过函数来求解最小值的时候已经不在原始的离散空间中,而是在实数空间中。
则对上式求导,令导 \frac{{\partial L}}{{\partial y}} = 0 ,有:
(D-W)y=\lambda Dy
这时我们可以发现这个式子实际上就是对 D-W 进行特征值特征向量分解。但是我们要注意,上述的最终目标函数是由两个条件的。不过这些条件在广义的特征值特征向量分解下得到满足,即:
{{\rm{D}}^{ - \frac{1}{2}}}(D - W){D^{ - \frac{1}{2}}}z = \lambda z
其中 z = {D^{\frac{1}{2}}}y ,这时我们很容易计算得到特征值 0 所对应的特征向量 z_0=D^{\frac{1}{2}}{\bf{1}} 。考虑 D-W 为半正定矩阵,变换到原始的表示形式中可以得到,
(1) 最小 特征值 0 对应的特征向量为 y= \bf{1}
(2) 根据正交性有
z_1^T{z_0} = {{\rm{D}}^{\frac{1}{2}}}y_1^T{D^{\frac{1}{2}}}{\bf{1}} = y_1^TD{\bf{1}}=0
根据瑞利熵的一个性质:
对于实对称矩阵 A ,则 \frac{{{x^T}Ax}}{{{x^T}x}} 的最小值在其最小的非 0 特征值对应的特征向量上取得。
根据以上叙述,我们知道
z
与第一小的特征向量
z_0=D^{\frac{1}{2}}{\bf{1}}
正交,则在
z_1
时,目标函数就可以取得最小值有:
{z_1} = \arg \mathop {\min }\limits_{{z^T}{z_0} = 0} \frac{{{z^{\rm{T}}}{{\rm{D}}^{ - \frac{1}{2}}}(D - W){D^{ - \frac{1}{2}}}z}}{{{z^T}z}}
则:
{y_1} = \arg \mathop {\min }\limits_{{y^T}D{\bf{1}} = 0} \frac{{{y^T}(D - W)y}}{{{y^T}Dy}}
此时第二小的特征向量便是我们所求目标函数在实数域上的解。如果是
k
类的划分,相当于我们每次从整体的图中割出最优的一部分,第一次的最优割就是第二小的特征值对应的特征向量。而下一次的割则是与上一次割不重叠的最优的割,也就是与上一次割正交的次优的割,实际上就是第三小的特征值对应的特征向量,以此类推,我们可以得到
k
类所对应的
k
个割,这些割是互相正交的。但是,我们所定义的
y
并不是在实数域,而是可以取
y_i \in \{1,-b\}
两个值,所以我们在得到每个划分时都是一种近似,如果对其继续划分时,会产生误差的累积,所以类别过多时,结果会变得不那么精确。
另一个问题,虽然我们已经得到了实数域上目标函数的最优解,但是我们如何能够确定图的划分呢?以两类为例,我们得到的特征向量中的每个值在离散域上实际上只能够取
y_i \in \{1,-b\}
两个结果,则每个结果对应着该类的节点。而此时
y
是连续的,则我们可以通过阈值的方式来对其进行划分。如果是多类的情况,我们不能再通过只是向量将其分开,则我们可以把所得特征值向量对每个样本的表示看作是一种类别编码,我们通过聚类的方法能够得到最终结果。
谱
在上面整个方法的介绍中我们发现在并没有介绍谱的概念,我们依旧可以推导出谱聚类算法。但是我们实际上已经用到了谱的形式,
实际上矩阵
D-W
称为拉普拉斯矩阵,对它的特征值特征向量的分解就涉及到了谱分析,所以也就称为谱聚类了
。现在我们引入谱一些知识,和一些思考。
当我们提到 “谱” 这个概念的时候,都会感觉十分难以理解。而实际上我们可以简单的认为
谱
实际上就是对一个信号(视频,音频,图像,图)分解为一些简单元素的线性组合(小波基,图基)。而为了使得这种分解更加有意义,我们可以使得这些分解的元素之间是线性无关的的(正交的)。也就是说这些分解的简单元素可以看作是信号的基。
在信号处理中我们最容易想到的谱就是傅里叶变换,它提供了不同频率下的正弦和余弦波作为基,从而我们可以将信号在这些基进行分解。但是当我们讨论图的时候,我们所称的 “谱”指的是对拉普拉斯矩阵
L
的特征值分解。我们可以把拉普拉斯矩阵看作是图上邻接矩阵的一种特殊的正则化形式,而它的特征值分解过程就是我们寻找构造图所需的正交基的过程。
谱的定义:
将方阵(矩阵)作为线性算子,它的所有的特征值的全体统称为方阵的谱。定义谱半径为该方阵最大的特征值。 栗子:如果我们有一般矩阵
A
则该矩阵的谱半径为
(A^TA)
的最大特征值。
图拉普拉斯矩阵和一些它的物理意义:
图拉普拉斯矩阵,如果把它看作线性变换的话,它起的作用与分析中的拉普拉斯算子是一样的。
,我们将在下面详细讨论,这里需要一些基本的知识:
梯度(矢量) :梯度 “ \nabla ” 的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该方向处沿着该方向(此梯度方向)变化最快,变化率最大(为该梯度的模)。
假设一个三元函数
u=f(x,y,z)
在空间区域
G
内具有一阶连续偏导数,点
P(x,y,z) \in G
, 称向量
\left\{ {\frac{{\partial f}}{{\partial x}},\frac{{\partial f}}{{\partial y}},\frac{{\partial f}}{{\partial z}}} \right\} = \frac{{\partial f}}{{\partial x}}\vec i + \frac{{\partial f}}{{\partial y}}\vec j + \frac{{\partial f}}{{\partial z}}\vec k
为函数 u=f(x,y,z)
在点 P 处的梯度,记为 gradf(x,y,z) 或 \nabla f(x,y,z) 其中:
\nabla = \frac{\partial }{{\partial x}}\vec i + \frac{\partial }{{\partial y}}\vec j + \frac{\partial }{{\partial z}}\vec k
称为(三维)向量的微分算子或 Nabla 算子。
散度(标量) 散度 " \nabla \cdot " (divergence)可用于表针空间中各点矢量场发散的强弱程度,物理上,散度的意义是长的有源性。当 div(F)>0 ,表示该点有散发通量的正源(发散源);当 div(F)<0 表示该点有吸收能量的负源(洞或汇);当 div(F)=0 ,表示该点无源。
散度是作用在向量场上的一个算子。用三维空间举例,向量场就是在空间中每一点处都对应一个三维向量的向量函数:
F(x,y,z,)=(v_1(x,y,z),v_2(x,y,z),v_3(x,y,z))^T
div(F) = \frac{{\partial {v_1}}}{{\partial x}} + \frac{{\partial {v_2}}}{{\partial y}} + \frac{{\partial {v_3}}}{{\partial z}}
它是一个标量函数(场),也就是说,在定义空间中每一点的散度是一个值。矢量 $V$ 的散度在笛卡尔坐标(直角坐标系)下的表达式:
\nabla \cdot V = \frac{{\partial {V_x}}}{{\partial x}} + \frac{{\partial {V_y}}}{{\partial y}} + \frac{{\partial {V_z}}}{{\partial z}}
拉普拉斯算子: 拉普拉斯算子(Laplace Operator)是 n 维欧几里得空间中的一个二阶微分算子,定义为梯度( \nabla f )的散度( \nabla \cdot )。
\Delta f = {\nabla ^2}f = \nabla \cdot \nabla f = div(gradf)
笛卡尔坐标系下的表示法:
\Delta f = \frac{{{\partial ^2}f}}{{\partial {x^2}}} + \frac{{{\partial ^2}f}}{{\partial {y^2}}} + \frac{{{\partial ^2}f}}{{\partial {z^2}}}
n 维形式
\Delta = \sum\limits_i {\frac{{{\partial ^2}}}{{\partial x_i^2}}}
离散函数的导数:
\frac{{\partial f}}{{\partial x}} = f'(x)=f(x + 1) - f(x)
\begin{array}{l} \frac{{{\partial ^2}f}}{{\partial {x^2}}} = f''(x)\ \approx f'(x) - f'(x - 1)\ \\= f(x + 1) + f(x - 1) - 2f(x) \end{array}
则我们可以将拉普拉斯算子也转化为离散形式(以二维为例)
\begin{array}{l} \Delta f = \frac{{{\partial ^2}f}}{{\partial {x^2}}} + \frac{{{\partial ^2}f}}{{\partial {y^2}}}\\ = f(x + 1,y) + f(x - 1,y) - 2f(x,y){\kern 1pt} + f(x,y + 1) + f(x,y - 1) - 2f(x,y)\\ = f(x + 1,y) + f(x - 1,y) + f(x,y + 1) + f(x,y - 1) - 4f(x,y) \end{array}
其矩阵表示形式为:
\left( {\matrix{ 0 & 1 & 0 \cr 1 & { - 4} & 1 \cr 0 & 1 & 0 \cr } } \right)
实际上,拉普拉斯算子计算得到的是对矩阵中某一点进行微小扰动后获得的总增益
我们现在将这个结论推广到图:
假设具有 N 个节点的图 G ,此时图中每个节点的自由度至多为 N ,此时该图为完全图,即任意两个节点之间都有一条边连接,则对其中一个节点进行微扰,它可能变为图中任意一个节点。
此时以上定义的函数
f
不再是二维,而是
N
维向量:
f=(f_1,f_2,...,f_n)
,其中
f_i
为函数
f
在图中节点
i
处的函数值。类比于
f(x,y)
在节点
(x,y)
处的值。
对
i
节点进行扰动,它可能变为任意一个与它相邻的节点
j \in N_i
,
N_i
表示节点
i
的一阶邻域节点。
我们上面已经知道拉普拉斯算子可以计算一个点到它所有自由度上微小扰动的增益,则通过图来表示就是任意一个节点
j
变化到节点
i
所带来的增益,考虑图中边的权值相等(简单说就是1)则有:
\Delta {f_i} = \sum\limits_{j \in {N_i}} {({f_i} - } {f_j})
而如果边 E_{ij} 具有权重 w_{ij} 时,则有:
\Delta {f_i} = \sum\limits_{j \in {N_i}} {{w_{ij}}({f_i} - } {f_j})
由于当 w_{ij} = 0 时表示节点 i,j 不相邻,所以上式可以简化为:
\Delta {f_i} = \sum\limits_{j \in {N}} {{w_{ij}}({f_i} - } {f_j})
继续推导有:
\begin{array}{l} \Delta {f_i} = \sum\limits_{j \in N} {{w_{ij}}({f_i} - {f_j})} \ \\= \sum\limits_{j \in N} {{w_{ij}}{f_i} - \sum\limits_{j \in N} {{w_{ij}}{f_j}} } \ \\= {d_i}{f_i} - {W_{i:}}f \end{array}
对于所有的
N
个节点有:
\eqalign{ & \Delta {f} = \left( {\matrix{ {\Delta {f_1}} \cr \vdots \cr {\Delta {f_N}} \cr } } \right) = \left( {\matrix{ {{d_1}{f_1} - {W_{1:}}f} \cr \vdots \cr {{d_N}{f_N} - {W_{N:}}f} \cr } } \right) \cr & = \left( {\matrix{ {{d_1}} & \cdots & 0 \cr \vdots & \ddots & \vdots \cr 0 & \cdots & {{d_N}} \cr } } \right)f - \left( {\matrix{ {{W_{1:}}} \cr \vdots \cr {{W_{N:}}} \cr } } \right)f \cr & = diag({d_i})f - Wf \cr & = (D-W)f \cr & = Lf \cr}
这里的
(D-W)
实际上就是的拉普拉斯矩阵
L
根据前面所述,拉普拉斯矩阵中的第
i
行实际上反应了第
i
个节点在对其他所有节点产生扰动时所产生的增益累积。直观上来讲,图拉普拉斯反映了当我们在节点
i
上施加一个势,这个势以
哪个
方向能够多
顺畅
的流向其他节点。谱聚类中的拉普拉斯矩阵可以理解为是对图的一种矩阵表示形式。
拉普拉斯矩阵的性质
f^TLf = \frac{1}{2}\sum\limits_{i,j = 1}^n {{w_{ij}}{{({f_i} - {f_j})}^2}{\kern 1pt} {\kern 1pt} {\kern 1pt} f \in {R^n}}
推导:
\begin{array}{l} {f^T}Lf\ = {f^T}Df - {f^T}Wf\ \\ = \sum\limits_{i = 1}^n {{d_i}f_i^2 - \sum\limits_{i,j = 1}^n {{f_i}{f_j}{w_{ij}}} } \ \\ = \frac{1}{2}(\sum\limits_{i = 1}^n {{d_i}f_i^2} - 2\sum\limits_{i,j}^n {{f_i}{f_j}{w_{ij}}} + \sum\limits_{j = 1}^n {{d_j}f_j^2} )\ \\= \frac{1}{2}(\sum\limits_{i = 1}^n {(\sum\limits_{a = 1}^n {{w_{ia}}} )f_i^2} - 2\sum\limits_{i,j}^n {{f_i}{f_j}{w_{ij}}} + \sum\limits_{j = 1}^n {(\sum\limits_{b = 1}^n {{w_{jb}}} )f_j^2} )\ \\= \frac{1}{2}(\sum\limits_{i,a = 1}^n {{w_{ia}}f_i^2} - 2\sum\limits_{i,j = 1}^n {{f_i}{f_j}{w_{ij}}} + \sum\limits_{j,b = 1}^n {{w_{jb}}f_j^2} )\ \\= \frac{1}{2}(\sum\limits_{i,j = 1}^n {{w_{ij}}f_i^2} - 2\sum\limits_{i,j = 1}^n {{f_i}{f_j}{w_{ij}}} + \sum\limits_{j,i = 1}^n {{w_{ji}}f_j^2} )\ \\ = \frac{1}{2}(\sum\limits_{i,j = 1}^n {{w_{ij}}f_i^2} - 2\sum\limits_{i,j = 1}^n {{f_i}{f_j}{w_{ij}}} + \sum\limits_{j,i = 1}^n {{w_{ij}}f_j^2} )\ \\= \frac{1}{2}\sum\limits_{i,j = 1}^n {{w_{ij}}(f_i^2 - 2{f_i}{f_j} + f_j^2)} \ \\= \frac{1}{2}\sum\limits_{i,j = 1}^n {{w_{ij}}{{({f_i} - {f_j})}^2}} \end{array}
L 是对称半正定矩阵 L 的最小特征值是 0 ,相应的特征向量是 1 , L 的 n 个非负实特征值 0=\lambda_1 \le \lambda_2 \le ... \le \lambda_n
正则拉普拉斯矩阵的定义及性质:
1)symmetric:
{L_{sym}}: = {D^{ - 1/2}}L{D^{ - 1/2}} = I - {D^{ - 1/2}}W{D^{ - 1/2}}
2) Random walk:
L_{rw}:=D^{-1}L=I-D^{-1}W
有如下性质:
1)如果 (\lambda,u) 是 L_{rw} 的特征值和特征向量,当且仅当 (\lambda, D^{1/2}u) 是 L_{sym} 的特征值特征向量。
2) (0,1) 是 L_{rw} 的特征值和特征向量, (0,D^{1/2}1) 是 L_{sym} 的特征值和特征向量; 3) L_{sym} 和 L_{rw} 是半正定的,由 n 个非负实特征值
{f^T}{L_{sym}}f = \frac{1}{2}\sum\limits_{i,j = 1}^n {{w_{ij}}{{(\frac{{{f_i}}}{{\sqrt {{d_i}} }} - \frac{{{f_j}}}{{\sqrt {{d_j}} }})}^2}} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} f \in {R^n}
参考:

