




Python固收荟 | 模块篇
来源:雪球App,作者: 债券圈,(https://xueqiu.com/7539894803/108377737)

来源:金融市场那些事儿
作者:蔡宇飞 博士 前海开源基金固定收益部投资经理
目录:
0 模块、包、库
1 基本模块介绍
2 安装方式
3 一个操作例子
4 固收领域的专用模块
5 结语
作为一个固收二级狗,数据分析软件要常伴身边,一般简单的数据分析excel就可以胜任,略微复杂的可能就需要借助其他软件。这个选择的范围其实挺广的,仁者见仁智者见智,python有他自己的优势,也有劣势。我在学习期间也走了一些弯路,因为python的资料确实浩如烟海,所以想简单介绍一下几个可以在固收领域应用的基本常用模块及方法。一方面可以作为前车之鉴,使得想学习的人尽快做好准备工作,不至于在大量的资料面前望而却步;另一方面是作为抛砖引玉,希望python能在固收领域多多普及,吸引更多的大牛,大家一起完善一些属于我们领域的独特模块。个人感觉在固收分析领域python的普及率不高,但是由于python本身不断的发展,目前已经成为数据分析和金融投资领域的一门流行语言了,所以我感觉在固收领域还是有很多使用空间可以挖掘的。
先聊一个小问题,python数据分析的优势在哪里? 这个问题其实很多人都回答过了,因为python是一门很高级的语言……这里的高级,并不说明语言的优劣,仅仅是描述了这门语言与人类语言(比如英语)的近似程度,比如一门语言编写出来非常接近英语,那么就说这门语言是高级的,从这个意义上讲,python是一门非常高级的语言。显而易见,如果一门编程语言离人类语言越接近,通过编译器翻译成计算器语言的时间就越久,所以牺牲的就是运行效率,但是对于非IT专业的人而言,那百分之几的运行效率的降低,在成倍的编程效率上的提升面前显得不值一提。这是特别推荐python的最重要原因,其入门门槛相对没有那么高,语言比较简短干练,在金融领域的运用方面,现在的普及程度也在不断的提高。当然,如果想要精通python,这就跟精通任何一门语言一样了,都是一个需要付出非常多努力的过程,当然其难度也不小。
需要多说一句的是,任何一门语言都有其独特的语法糖彰显其独特性的同时提高开发效率,python也不例外,python语言中有很多方法可以运用在数据分析领域中提升运行效率,比如列表解析、函数式编程以及切片等等,这些方法既让python成为了一门独特的语言,也大大简化了语言数量。当然,也有一些比较难理解的方法,比方说装饰器、生成器之类的,但是这些运用在数据分析中使用的频率略低一些。
模块在python当中非常重要,刚下载下来的python就像一个婴儿,几乎是一张白纸,经过模块的培养,python就可以变成各式各样的超人了。下面的介绍主要分四个部分,首先说一下模块及相关概念,然后介绍几个常用的模块,之后举一个例子,最后做一点说明。
0 模块、包、库
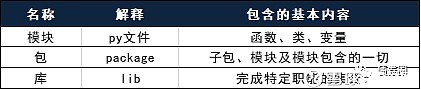
有人将python比喻成编程的乐高积木,这对于用积木的人来说是非常便利,我们只需要懂得积木的运作原理就可以直接拿来用,而不需要自己去创造一块积木。如果需要用到一块积木,要做的就是采用import函数,将这个积木导入可用,之后调用这个积木完成所交办的任务就可以了。积木有大有小,有一些积木构成一个体系,这些对于python来说,就引出了标题的三个概念:模块、包和库。
模块在python 当中是一个py文件,每一个python脚本文件都是一个模块,一旦导入,其内置的函数和类会全部可用,我们后面介绍的math就是一个模块,他下面包含了很多数学运算的函数,如果我要用到这个函数,就导入math模块,在模块里寻找函数用就可以了。
包在python当中是一个package,其中必然包含一个__init__.py的文件可以使一个文件夹像模块一样被导入,包里面包含了模块、函数甚至是子包,可以说包提供了一个有层级的模块架构,既可以选择将包一次性导入,这样其内置的全部函数都可用,也可以选择只导入包中的某个或几个模块,选择性的运用其中的一些功能,比如后面介绍的numpy包,其既包含内置的一些函数,如三角函数运算,也包含了random模块,用于一些关于随机数操作,如果只想使用random模块,就可以只导入需要的这一部分。
库是一个lib,其属于更为广义的一个概念,并不存在一个文件将其描述清楚,库包含了包和模块,用库来形容可以完成一定职能的包和模块的集合,这个概念更常用于要完成一个任务时所要借用的架构体系。可以将以上的概念简单列示如下:
上面三个概念当中,最常用的概念是包,PyPI就是一个包的仓库,提供了高达4万多个的应用,几乎涵盖了目前的各类分析领域,目前这个数量还在不断的提高,同时python自带的pip为Python的包安装管理提供了极大的方便。但是由于一些网络原因,有时候访问PyPI经常会遇到一些困难,所以现在有一些用户将pip源替换成国内的镜像文件,这样安装和下载起来会便利很多,最常用的比如豆瓣上就有PyPI镜像。
尽管严格意义上最常用的是包,但是不管从使用方法上还是实现功能上,包本质上还是一个模块,所以我们很多时候将numpy之类的包也称呼为模块,这个不妨碍理解,也并不冲突。所以可以看到很多地方把numpy成为包,又有一些地方把numpy成为模块,严格意义确实是个包,但是用模块来表达,也不妨碍理解。
1 介绍基本模块
Python在固收领域的分析其实主要是几个基础模块和WindPy之间的配合,下面就一一介绍一下几个部分。
math:最基础的数学运算,内置模块,无需安装,打开python就可以直接import math导入并使用。是的,你没看错,python连实现基本的数学运算都需要模块导入。。。所以没有模块,在计算效率上python连excel都不如。math模块非常简单,功能也很少,利用dir可以调用math的所有基本功能(如下图),不理会带前后双下划线的特殊方法,可以发现很多熟悉概念,例如π、指数、对数、三角函数等等。

numpy:向量运算、矩阵运算和高级数学运算的模块。这个是重要的数学运算模块,大量的数据分析模块都是以此为基础,他的功能仍在不断完善,定义的数据结构称为array。主要原因是python中数据结构是列表,但列表并不支持很多数学上的运算,比如两个列表相加,只是将两个列表前后拼接起来,并非数学上的元素相加,定义了array后,可以将列表中偏字符的运算方式全部转化为以数据集为基础的运算,并在此基础上做大量的基于向量或矩阵的算法。
numpy经过众多大牛的不断完善,现在已经成为科学计算中非常重要的基础工具,而且非常的活跃,不断有人在补充他的功能,通过help文档可以调用几万行的numpy使用方法说明。从中可以看出numpy的计算主要包含线性代数、随机数相关操作和傅里叶变换等。对于我们来说,最常用的是第一部分,包括向量的处理(对应现金流计算),矩阵的低级和高级运算,方程组的求解等,当然numpy也有简单的回归功能,但是由于有专门的统计计量模块statsmodels(后面有介绍),所以numpy自带的这个功能本身并不常用,感兴趣的可以去网上找学习指南。
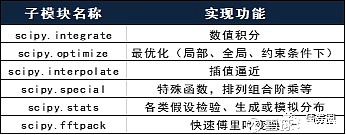
scipy:高级数学运算最为主流的包,需要numpy为基础才可以安转成功,也就是说其处理的数据类型为array,其包含的子模块较多,列示在下表当中。scipy也在被不断开发当中,最新的功能需要实时更新。关于scipy的安装,在mac系统上会便利,window系统比较复杂。因为这个模块非常重要,非常常用,所以不能因为麻烦就不安装了。关于这个安装的处理方式,下部分会详细说。
pandas:拥有简单的绘图职能和较高级的数据运算职能,其数据结构包含series和dataframe两类,前者是时间序列分析的基础,后者是一个类似excel外观的拥有行列两维的数据集,这里可以看到其引用数据的基础是自己定义的series,尽管如此,他仍然需要numpy作为安装基础,因为无需scipy,所以其安装难度不大。
看到series就能发现了,这个模块具有处理时间序列的能力,既然是处理时间序列,最重要的就是对时间序列进行时间标序,可以是日、月、季度以及年。定义了时间之后可以进行时间序列的基本处理,包括修匀等等。后面介绍的statsmodels可以对这个数据类型进行计量化处理,包括 ARMA模型、 VAR模型等
matplotlib:从其名称可以看出其类似matlab,事实上确实如此。这是个强大的做图模块,语言风格类似matlab,安装略复杂,需要已经安装一定版本以上的numpy、scipy和pandas等作为基础,否则不会安装成功。这一点非常好理解,因为作图需要各式各样的原始数据类型,所以matplotlib必须在各种数据处理模块搭建的基础上搭建起来。
statsmodels:回归分析模块,经济金融领域分析用处较多。statsmodels可以处理array和series,也就是numpy和pandas的数据结构他都支持。这是python上最强大的计量分析软件,涵盖了方差分析、一般线性回归、广义线性回归、离散选择模型、非参数回归及时间序列分析等很多计量方法。他与scipy中的stats是不同的,stats只是提供了基础的统计假设检验方法,而Statsmodels更为系统,更为强大,同时也涵盖了scipy.stats的相关内容。因为涉及到各类数据分析,所以一样需要numpy、scipy和pandas作为安装基础。statsmodels目前没有全面介绍的中文教程,官网上有英文的handbook,英文无压力的可以忽略。有时间的话,我也想详细介绍一下这一部分。
以上所有模块均可以上其官网,官网上有着详细的各类操作解释以及很多使用者在操作过程中碰到的各式各样的问题。
WindPy:常用的万得操作模块,他无需安装,导入即可用,安装前不需要任何基础模块,只需要在终端上修复一下。但是操作上跟matlab又不同,在python里没有可视化的图形用户界面,对比一下,下图是matlab的Wind操作界面。

所谓没有图形用户界面,用大白话说就不能直接点点点取数据,所以python里只能通过代码提取数据,不知道wind将来会不会利用专门的gui模块做一些开发。但是wind也非常人性化,在wind终端里专门建立了一个代码生成模块(快捷键CG),在这里通过界面输入想得到的数据,可以生成python代码。这里看起来节省了不少时间,但是我个人觉得这只是第一步而已,真正需要花时间的是理解wind数据提取代码,然后封装成自己的函数以完成更复杂的操作。这是一个重要的操作技巧,下面会专门介绍一个例子。
后面会提到Anaconda可以整合所有模块,但是如果需要独立安装以上几个模块的话,建议的先后顺序是:numpy→pandas(scipy)→matplotlib(statsmodels),WindPy可以直接修复启动,他们构成如下一个层级关系:
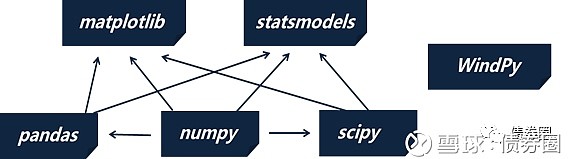
其实,numpy、scipy、pandas和matplotlib不单单是固收领域的基础模块,不夸张的说,只要是用python做数据类处理,在每一个领域都会用到,比如说做深度学习的模块scikit-learn和keras,就需要numpy和scipy为基础。所以如果对某个数据分析领域有兴趣,在掌握以上这几个模块的基础之上,专门针对自己感兴趣的模块进行理论和方法上的纵深学习就可以了。基础模块搞的好,触类旁通的进行其他的学习也会非常快。
2 安装方式
大多数的模块,直接通过pip就可以安装,现在python会自带pip,需要安装直接在cmd命令行里pip install 就可以了,问题比较大的是scipy,scipy安装不好,会直接导致matplotlib和statsmodels有问题。scipy的安装问题本质上也是个很复杂的事情。
可以去镜像上下载scipy的whl,在命令行里用pip安装,这个里面可能会遇到各式各样的问题,所要做的就是差什么补什么,但是个人不是很推荐用这个方式。下面这个方式是推荐的,就是Anaconda,Anaconda提供了包管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。毕竟我们用python就是图方便,一切都是为效率让路。
安装Anaconda可以直接去网上下载,下载的时候注意一下版本,其自带的ide是spyder,它可以调用以上提到的全部模块。操作安装完成后,无脑将所有需要的模块import就可以了,其操作界面非常类似matlab,清爽干练,所以强烈推荐。另外,Anaconda也可以用来完成深度学习,爬虫等等其他应用,特别有安装价值。
3 一个操作的例子
之前提到过,对于WindPy的最重要的应用是可以把wind的提取代码再加工,封装成一个函数,然后再结合其他基础模块进行操作,这是一个非常常用的技巧,这里不妨就拿这个来举一下例子,顺便详细说一下WindPy的简单应用,比如我想做实现以下这个目的:
取出最近一年的十年国债期货T合约在到期前一个月的CTD代码,比如T1709,想要取出他在8月份的CTD代码,T1706取出他在5月份的CTD代码,以此类推。
这个其实完全可以用excel的万得函数实现,但是这里用excel有两个比较大的问题:首先、excel不具有长期操作的复制性,当下可以取一次,但是下一次取数据,又得重新做一个excel模板,而且说不定下次就改了时间区间,那之前的白做了。其次、这里的时间是不连续的,如果让我们取出最近一年的,这个还比较好说,但是这个是离散的四个月,必须选出前一个月,这用excel来操作非常的麻烦,另外,如果取出两年甚至更长呢?excel也不方便不是吗?
这里能不能写一个函数,输入三个参数,起始日期,到期日期,国债期货合约代码,就可以自动输出这段时间内的CTD呢?这样就可以通过一个循环语言连续取出数据。而且以后想取出任意一个时段内的CTD,一行代码就可以搞定了,岂不是非常方便?有了这个指导思想,可以把上面的问题分解为以下三步:
第一步、研究wind提取CTD代码的语言格式
第二步、将wind代码封装成新的函数,包含起始日期,到期日期,国债期货合约代码三个形参,之后打包成一个模块
第三步、利用2生成的语言循环提取数据
以下就展示以下如何实现这个步骤:
第一步、研究wind提取CTD代码的格式
在万得的CG模块里可以轻松获取原始代码,这一步骤是有用户界面操作的,按照提示一直选择自己有意向的数据无脑下一步就可以了:

直接按照自己的需求点击就可以获取如下wind提取CTD的代码:
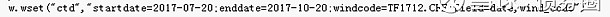
分析一下可以看出,上面代码分为两个字段,第一部分表示提取的是CTD,这个不变。第二部分就包含了起始时间(startdate)、结束时间(enddate)、提取的合约代码(windcode)以及需要提取的结果类型(field),field这里包含两类:日期和CTD的代码,第二部分是我们需要改造的部分。
分析完了就可以用python将上面的代进行改造码封装成函数,主要修改是针对第二个部分,这里需要替换时间和提取的合约代码。
第二步、将wind代码封装成新的函数
下面定义起始日期,到期日期,国债期货合约代码三个形参,之后提取数据。直接展示编写完成后的py文件:
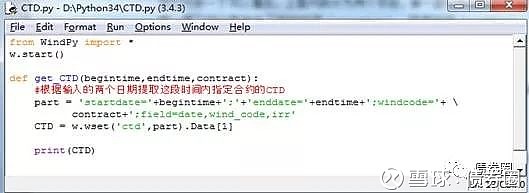
上面代码不算复杂,做一点说明:
(1)前两句是启动万得
(2)def定义一个函数后,用part这个字符串去替换万得原始代码当中的字符串,将需要的参数传入函数,形成一个新的提取代码
(3)w.之后的操作是利用万得提取CTD,这里用了列表切片,将CTD代码单独抽出来
(4)print仅仅是做了展示,这里如果需要这个代码做进一步运算,可以采用return
(5) 写完之后,命名一个py文件,一个崭新的模块就完成了,将这个模块命名成CTD,将目前的这个函数操作命名成get_CTD,如果以后有关于CTD的任何操作,都可以继续在这个模块后面编写,只是不同的函数而已。
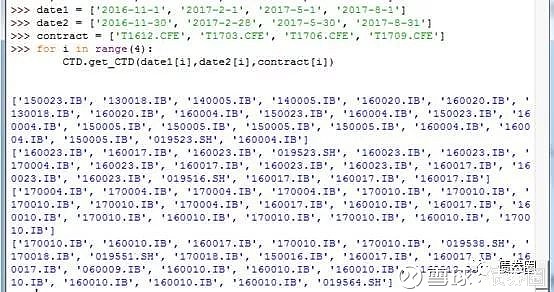
第三步、循环提取数据
从下图可以看出,利用上一部分完成的工作,一次性提取出了四个离散时间段的CTD代码,理论上可以不断的复制这个操作,时间区间再长都可以高效的完成。
当然也可以加工成更复杂的操作,比如说,可以加入筛选仅提取交易所或仅提取银行间的代码,可以筛选是否需要提取CTD的IRR等等。
上面操作的优势在于:
(1)可以反复利用这个代码,一次编写完成,之后的操作可以节省大量时间
(2)以后每次提取节省时间,提高效率,连CG窗口都不用打开
(3)可以对数据做后续的更方便处理,例如利用numpy等模块对CTD做数据分析,后续这些就不一一列举了。
4 固收领域的专用模块
写到这儿其实我们都会发现,以上提到这些模块并不是固收领域的专用模块啊?WindPy里可能有一些,但是也没有形成固收排他的体系,有没有只能固收领域能用的呢?我想说的是,开源的模块里面真的是没有的,但是每一个人其实都可以编写自己的只适用于固收的一些模块,就像上面做的那样。如果这些模块的实用性高,得到了广泛的认可,也可以将其封装起来,利用distutils打包发布自己的原创成果,造福于大家。其实python就是因为有了无数如此无私的人才发展这么快的,上面提到的那些常用工具,都是无数pythonist一砖一瓦不断完善起来最终呈现在我们面前的。
可以想到国债期货里面就有很多可以挖掘的,比方可以自己写一个模块实时的监控净基差水平,据我所知,目前的软件是可以提供算净基差的渠道,但是不能每时每刻都进软件里算一遍吧,可以像之前那一部分介绍的那样写一个函数封装起来,自动的每隔一段时间提取一次。每个人也可以根据自己的思路,对国债期货的一些指标做各种各样的监控。
再比如我们是场外市场,将来信息变畅通了,可以不可以利用爬虫技术去获取全市场的成交和报价数据,而不依赖于某些平台呢?当然爬虫技术本身也是一项比较浩大的工程,需要很多的前端知识,写正则表达式也是个技术活儿,但是不可否认的是这都有可能成为发展的方向,提升我们的效率。
5 结语
Python要说复杂真的可以非常复杂,复杂到可以去做很多项目的开源。而且python的应用面积太广了,能够将其中一两个部分研究透彻并运用好都已经是非常不容易的事情了。
上述其实每一个部分要展开都需要很大的篇幅,希望未来有机会可以详细把每一个模块的用法介绍一下,也可以把我自己做的一些模块分享给大家。其实这一次主要是想介绍一些基础的概念,毕竟万事开头难,把一些准备工作做好,后面的就是进行理论学习就可以了。另外,如果有提升效率的一些东西,都可以讨论,也希望能够看到python在固收圈里越来越普及。
上帝说,要有光。
So,
import light。
To be continued。
END