周末了,终于有这么一整段的时间去总结整理了,这个月很忙,需求很多,年龄不小了,生活中个人的事情也不少。时间是最公平的,因为每个人每天都是过这么长时间,好好珍惜每一分。好了,不感慨了。进入正题吧。
先说一下项目结构:angular5.0 + ionic3.0 这个月做了一个pdf展示的需求,后台小伙伴传过来一个pdf格式的url,
这个url长这样:
url = ”https://sg.ibs.baidu.com.cn/download/fla-ybkj-dmz-dev-pri/24a1bed5f3fc46d582d6ff7747445b14?attname=BS012LYT.pdf"
其实就是一个pdf格式的文件的url地址,然后前端展示一下。原本以为实现会很简单,没想坑是一个接一个,下面来一一说一下吧。
1.先把后台传过来的url做一下转化,在angular中的转化如下:
html的代码
<ion-content (ionScroll)="scrollEvent($event)">
<iframe [src]=“url” height="100%" width="100%" seamless scrolling="no" id=“deatilShow”></iframe>
</ion-content>
ts中的代码
this.url = this.sanitizer.bypassSecurityTrustResourceUrl("assets/viewer/web/viewer.html?file=" + encodeURIComponent(res.data.url));
只有转化之后的url加载到iframe中才有效
2.这个pdf.js是一个泛称,装上之后,会有这么多文件,如图:
html页面中写法如下:
<ion-content (ionScroll)="scrollEvent($event)">
<iframe [src]=“url” height="100%" width="100%" seamless scrolling="no" id=“deatilShow”></iframe>
</ion-content>
其中
scrolling属性规定是否在 iframe 中显示滚动条。有三个值 yes 、no、 auto
seamless属性规定 看上去像是包含文档的一部分。
scrollEvent是监听ion-content 内容的滚动事件。然后就开始在scrollEvent里面增加滚动后的触发事件了,代码如下:
scrollEvent(event) {
this.show = true;
let het1 = document.body.clientHeight;
let het2 = document.getElementById("deatilShow").clientHeight;
this.ngzone.run(() => {
let top = event.scrollTop;
if (het2 <= het1 + top) {
this.buttonShow = false;
上面代码中的this.ngzone.run()的用法请见我的另外一篇文章工作学习总结–angular中的NgZone的简单使用
当我滚动页面的时候,scrollEvent事件却没有触发,因为我滚动的是iframe页面,也就是嵌入的另外一个页面,所以不会触发scrollEvent事件 。所以我找了一个折中的方案,给iframe加了一个margin-bottom,当iframe滚动到底部的时候,再往上滑一点,就会触发这个事件了,也就是ion-content这个页面滚动了,但是效果不太好,在ios和安卓上体验都不是很好,所以最后也没有采用这种方法。那怎么办呢?
经过自己的搜索+思索和其他小伙伴的帮助,最后还是以一种笨方法解决了。
3.下面描述我探索的过程(探索方法一):
我首先获取iframe这个元素,监听它的滚动事件,获取到的iframe是一个html,如图:
所以给它加滚动事件无效,然后又百度方法,还是没找到有效的方法,最后谷歌了一下,找到了一个方法,就是监听irame中的id为viewerContainer的元素的滚动事件才行,这个id为viewerContainer的元素其实就是viewer.html中的一个元素,所有pdf文件页面都加载到它里面,它在viewer.html中的代码如下:
<div id="viewerContainer" tabindex="0">
<div id="viewer" class="pdfViewer"></div>
然后就去获取这个元素
setTimeout(() => {
if(this.elementRef.nativeElement.querySelector('.scroll-content #deatilShow') && this.elementRef.nativeElement.querySelector('.scroll-content #deatilShow').contentDocument && this.elementRef.nativeElement.querySelector('.scroll-content #deatilShow').contentDocument.getElementById("viewerContainer")) {
clearInterval(this.timer)
viewerContainer = this.elementRef.nativeElement.querySelector('.scroll-content #deatilShow').contentDocument.getElementById("viewerContainer");
viewerContainer.addEventListener('scroll',(event) => {
let scrollTop = event.target.scrollTop ;
let clientHeight = event.target.clientHeight ;
let scrollHeight = event.target.scrollHeight ;
if(scrollTop+clientHeight == scrollHeight){
// 添加滚到底部要处理的事件
},2000)
为什么加个定时器呢?是因为网速不好的时候,pdf加载很慢,有可能页面还没加载完全,可能这个时候获取不到元素。这个时候在浏览器上跑的时候报跨域的问题,所以在谷歌浏览器设置了一下跨域。这个时候页面上事件都是可以的,都可以触发了。然后打包在ios和安卓手机上测的时候无效,一点效果没有,这个时候就纳闷了。为什么呢?手机连着电脑调试了一下,发现还是viewerContainer这个元素没有获取到。查了一下,猜测应该是pdf.js安全策略,不让外界获取viewerContainer这个元素,因为pdf文件都加载到这个元素下面,怕外界对pdf文件进行修改操作。那电脑上为什么可以呢,也许是因为给谷歌设置了跨域,可以忽略这个风险,具体原因还需后续再仔细去查一下。这个方法又被pass掉了,继续想办法吧
4.探索方法二
获取不到这个元素就没有办法监听它的滚动事件。那既然外界获取不到,我就在viewer.html中获取这个元素,并给它监听这个滚动事件。先试一下,试试又不花钱。
于是我在viewer.html中给它加了这样一段代码
<script>
let number = 0;
document.getElementById("viewerContainer").addEventListener("scroll",(event)=>{
let [ top, cliHeight, scrHeight] = [ event.target.scrollTop, event.target.clientHeight, event.target.scrollHeight];
number++;
top + cliHeight + 50 >= scrHeight ? window.parent.postMessage({toBottom : true},"*") : "";
number == 5 ? window.parent.postMessage({scrolled:true},"*") : "";
</script>
然后在页面上监听postMessage发出的事件就可以了
ngOnInit() {
window.addEventListener("message",(event)=>{
event.data.toBottom?this.show = true:"";
event.data.scrolled?this.button = true:"";
问题总算解决了,但是这也只是一个临时的方案,后期如果有什么更好的方法还要去优化的。
这个方法中有两个问题需要注意一下,一个是在viewer.html页面中用 window.parent.postMessage发出消息,另外就是在父页面进行监听的时候,用event.data的数据来区分监听是哪种消息。
5.最后说一下我对pdfjs这块的源码做了哪些改动
第一点:我注释掉了跨域这一块,在viewer.js里面(在1751行到1753行)
try {
var viewerOrigin = new _pdfjsLib.URL(window.location.href).origin || 'null';
if (HOSTED_VIEWER_ORIGINS.includes(viewerOrigin)) {
return;
var _ref8 = new _pdfjsLib.URL(file, window.location.href),
origin = _ref8.origin,
protocol = _ref8.protocol;
// if (origin !== viewerOrigin && protocol !== 'blob:') {
// throw new Error('file origin does not match viewer\'s');
} catch (ex) {
第二点:需求需要,需要合同文件上展示签章,也就是盖过的章,所以在pdf.work.js里面注释掉这样几行代码
大约注释了四行代码(在28684行到28688行)
if (!Number.isInteger(data.fieldFlags) || data.fieldFlags < 0) {
data.fieldFlags = 0;
data.readOnly = _this2.hasFieldFlag(_util.AnnotationFieldFlag.READONLY);
// if (data.fieldType === 'Sig') {
// data.fieldValue = null;
// _this2.setFlags(_util.AnnotationFlag.HIDDEN);
return _this2;
我使用的pdf.js是2.0的版本
第三点:清除pdf缓存 为什么说清除pdf缓存呢?例如 我打开一个pdf文件,滑到第6页,然后退出这个页面,再进来还是在第6页。那有没有方法可以让文件从第1页开始加载呢。就开始了我的探索之路,其实开发经验丰富的人,找问题很快也很准,也许是因为开发的需求多了,接触的问题也多了。我先去在插件里面去找,在viewer.js里面找。缓存就是意味着历史记录,于是我先查history,我发现了有这样一行代码:
localStorage.setItem('pdfjs.history', databaseStr);
我感觉这就是我要找的,于是我就去浏览器的localstorage里面找,果然,请看图: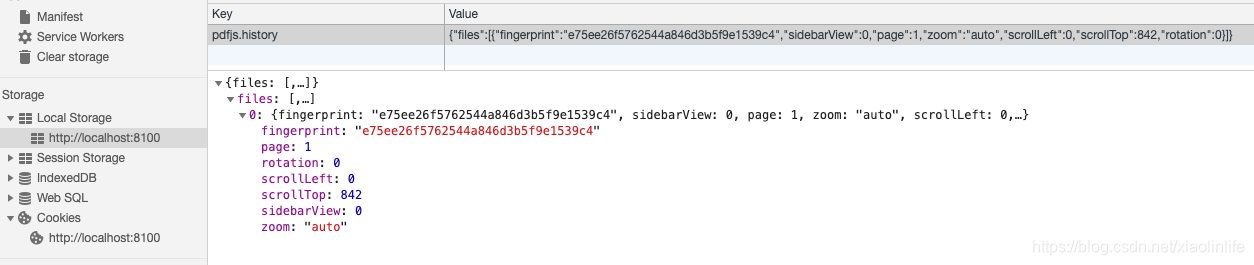
所以我在viewer.js中的第13457行把它注释掉了
_regenerator.default.mark(function _callee() {
var databaseStr;
return _regenerator.default.wrap(function _callee$(_context) {
while (1) {
switch (_context.prev = _context.next) {
case 0:
databaseStr = JSON.stringify(this.database);
// localStorage.setItem('pdfjs.history', databaseStr);
case 2:
case "end":
return _context.stop();
}, _callee, this);
然后就没有缓存了,问题也解决了。
还有一种笨方法就是在pdf的url后面加一个时间戳或者随机数。
以后关于pdf.js遇到的问题,到时候还会补充。
实现pdf分段加载的前提是,服务器端需要支持对pdf文件的分段访问,即能返回 Accept-Ranges: bytes, Content-Length: number。
然后在 PDFJS.getDocument 的时候增加配置参数 rangeChunkSize:65536(默认64k)即可开启分段加载pdf文件。...
当使用pdfjs来实现预览功能的时候,遇到了2个问题:
一是带宽占用过大,会下载整个pdf文件,这对部署在公网的应用来说,成本压力很大,因为云服务带宽是很贵的。
二是内存占用过大,一个80M的pdf,在预览时占用内存高达600M,在一些内存较小的手机上容易发生崩溃。
pdfjs默认配置下,会加载所有的分片(内容),即使只预览一个页面也会加载整个文件。能不能实现按需加载呢?只加载所预览的页面?答案是可以,下面我就详细地介绍如何做。
2 测试环境
pdfjs 1.10.10
2、从后端获取blob形式的pdf文件,具体怎么获取和后端商定(思路,后端提供一个接口,参数为文件链接,前端带参文件链接请求接口后,接口返回此文件链接的blob形式的文件流。老版本和新版本同时引入,当请求页面是判断当前客户端类型,若是ios则使用老版本的pdf.js文件。此链接可下载最新版本,不兼容老版本浏览器和苹果系统,若需在苹果展示则使用最上面。找到/web/viewer.js,搜索 fileOrigin,并注释以下代码段。3、获取到blob形式的pdf文件后,添加到iframe中,完成。
其实就是同时使用了ofdjs和pdfjs才造成的了冲突的问题,利用的技术就是懒加载。
两个同时使用,ofdjs使用了pdf部分代码一样,直接这样写就解决了
后来发现,打包的时候,pdfjs不知道为什么会提前加载,即使没有进入那个页面,它太大了,我也看不懂如何懒点加载那个插件,我就采用了在那个组件的时候再去加载那个插件,在mounted里面加载
.........
pdf-annotate.js
合并后的分支和已删除的DynamicEnvironmentSystems / pdf-annotate.js的分支。 下内使用积极发展 。
要报告pdf-annotate.js的问题,请将其提交到存储库下。
为提供一个低层注释层。
可选的高级UI,用于管理注释。
与后端StoreAdapter ,只需提供您自己的StoreAdapter即可获取/存储数据。
规定注释格式。
import pdfjsLib from 'pdfjs-dist/build/pdf' ;
import PDFJSAnnotate from 'pdfjs-annotate' ;
const { UI } = PDFJSAnnotate ;
const VIEWER = document . getElementById ( 'viewer' ) ;
在网页中加载并显示PDF文件是最常见的业务需求。例如以下应用场景:(1)在电商网站上购物之后,下载电子发票之前先预览发票。(2)电子政务管理系统中查看发布的公文,公文文件一般是PDF格式的文件。
目前随着浏览器技术发展的不断成熟与强大,大部分的浏览器都支持直接把PDF文件拖到浏览器中显示,最方便的是这个操作不需要额外的插件支持。但是不同的浏览器加载显示PDF的效果不同。这时就需要专门的JS插件来处理。Mozilla开源了一个插件pdf.js,无需任何本地支持就可以在所有主流的浏览器上显示PDF文档,使用起来
直接使用a标签,将href属性的值赋为你想要展示的文件的路径地址。
我用自己的手机测试(android)时,主要要经过下面的流程
打开----->首先下载QQ浏览器(手机没有安装的情况下)----->点击下载文件(这个文件会在QQ)浏览器中的下载那里出现(不会直接显示出来需要自己点击)------>点击这个文件之后会询问使用手机上面那个软件打开(如:WPS Offi...
发现有许多成熟的方案,最终决定使用PDF.js进行开发
首先先在官网下载
http://mozilla.github.io/pdf.js/getting_started/#download
下载完成后目录结构是这样:
我们打开web后点击:
这里有一个坑,我怎么都打不开,结果最后发现是因为需要启动服务才能使用这里我使用的是li
预览pdf文件的时候,h5页面导致浏览器崩溃,在h5打包的app上,造成了app闪退。其原因是一次性转码和渲染pdf文件非常耗性能。用懒加载的方式,当页面展示在可视区域内的时候去加载。具体方法如下:
在pdf.html文件中添加:lazy:true,用懒加载的方式解决。
如何实现pdf在线预览

