爬取qq音乐热歌榜https://y.qq.com/n/yqq/toplist/26.html到本地文件夹

程序思路:用selenium库通过目标网页的前端获取资源地址,将地址指向的文件下载至本地
本程序的selenium要配合chrome浏览器使用,selenium使用方法可以参考
Selenium2+python自动化45-18种定位方法(find_elements)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from tqdm import tqdm
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import re
import json
import requests
import os
class QqMusic:
def __init__(self):
self.chrome_options = Options()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
chrome_driver = "C:/Users/LU/AppData/Local/Programs/Python/Python37-32/Scripts/chromedriver.exe"
self.header = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"accept-language": "zh-CN,zh;q=0.9",
"referer": "https://y.qq.com/n/yqq/toplist/26.html",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
self.driver = webdriver.Chrome(chrome_driver, options=self.chrome_options)
def loading_music(self):
self.driver.get("https://y.qq.com/n/yqq/toplist/26.html")
print(self.driver.title)
WebDriverWait(self.driver, 10).until(EC.presence_of_all_elements_located((By.CLASS_NAME, "songlist__songname_txt")))
lists = self.driver.find_elements_by_class_name("songlist__songname_txt")
pattern = re.compile(r"https://y.qq.com/n/yqq/song/(\S+).html")
for i in range(len(lists)):
li = lists.__getitem__(i)
a = li.find_element_by_class_name("js_song")
href = a.get_attribute("href")
music_name = a.get_attribute("title")
m = pattern.match(href)
yield m.group(1), music_name
def cut_download_url(self):
筛选和查找下载的url
:return:
for music_url, music_name in self.loading_music():
data = json.dumps({"req":{"module": "CDN.SrfCdnDispatchServer", "method": "GetCdnDispatch",
"param": {"guid": "3802082216", "calltype": 0, "userip": ""}
"req_0": {
"module": "vkey.GetVkeyServer","method":"CgiGetVkey",
"param": {
"guid": "3802082216","songmid": [f'{music_url}'],
"songtype": [0],"uin": "0","loginflag": 1,"platform":"20"
},"comm": {"uin":0,"format":"json","ct":24,"cv":0}})
url = "https://u.y.qq.com/cgi-bin/musicu.fcg?callback=getplaysongvkey3131073469569151&" \
"g_tk=5381&jsonpCallback=getplaysongvkey3131073469569151&loginUin=0&hostUin=0&" \
f"format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&data={data}"
response = requests.get(url=f"{url}",
headers=self.header)
html = response.text
music_json = html.split("(")[1].split(")")[0]
music_json = json.loads(music_json)
req = music_json['req']['data']
sip = req["sip"][-1]
purl = music_json['req_0']['data']['midurlinfo'][0]['purl']
url = f"{sip}{purl}"
yield url, music_name
print(music_name)
def downloading(self, url, music_name):
:param url:
:param music_name:
:return:
res = requests.get(f"{url}")
chunk_size = 1024
if not os.path.exists("qq_music"):
os.mkdir("qq_music")
fileName = re.sub('[\/:*?"<>|]','-',music_name)
with open("qq_music/"+fileName+".m4a", 'wb') as f:
for data in res.iter_content(chunk_size=chunk_size):
f.write(data)
def run(self):
downloads = [x for x in self.cut_download_url()]
pbar = tqdm(total=len(downloads))
for num, (url, music_name) in enumerate(downloads):
self.downloading(url, music_name)
pbar.update()
QqMusic().run()
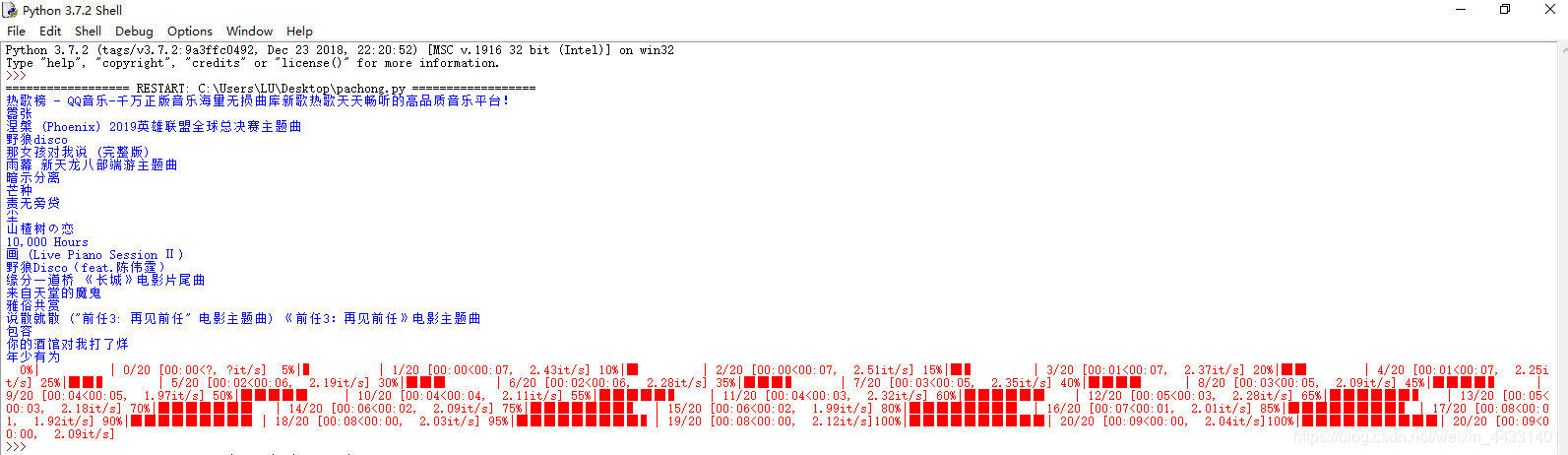
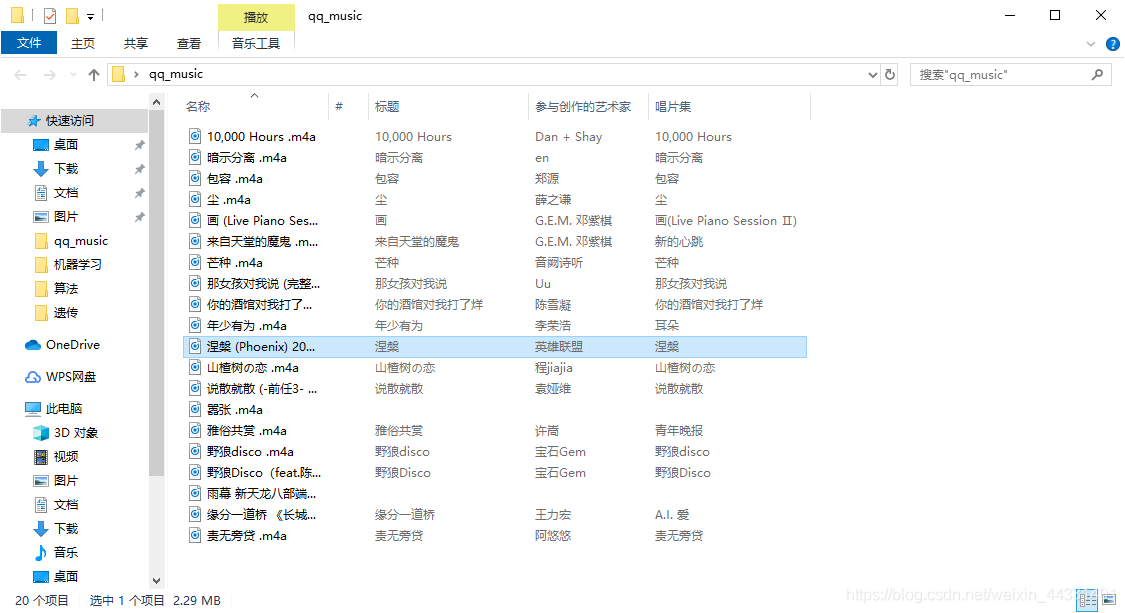
注:本代码只用于学习交流使用
20191022时该代码可以正常使用
参考 https://y.qq.com/n/yqq/toplist/26.html
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import
你是否还为付费音乐而苦恼,因为不是会员只能试听部分,那么作为一个程序员,你就不会有这种苦恼了,请看下文。小白易懂手把手教你操作,qq音乐,网易云音乐,酷狗音乐,酷我音乐等等一系列音乐手把手教你爬取下载。1、URL后面引号内部分,改成你想下载歌曲的URL,至于URL在哪里,你可以看一下你的前4步,复制粘贴过来。2、更改爬取后你保存的时候的给它一个命名,只修.mp3前面部分,.mp3是歌曲固定的后缀名。1、下载后保存的路径会自动保存在你此次Python项目的那个文件夹里,在你的左上角可以看到。
今天给大家带来用python采集QQ音乐的热评~文末有送书哦~我们可以看到这首歌曲的评论有10881条,不愧是榜首热歌,评论比较高。一.初步测试我们首先使用selenium测试一下环境:f...
最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧。获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据。但是有的时候我们想要的数据并不能直接获取,因为并不提供直接的下载渠道或者API供我们获取数据。那么这个时候该怎么办呢?有一种比较好的办法是通过网络爬虫,即编写计算机程序伪装成用户去获得想要的数据。利用计算机的高效,我们可以轻松快速地获取数据。
那么该如何写一个爬虫呢?有很多种语言都可以写爬虫,比如Java,php,python 等,我个人比较喜欢使用python。因为python不仅有着内置的功能强大的网络库,还有诸
【一、项目目标】通过手把手教你使用Python抓取QQ音乐数据(第一弹)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名、专辑名、播放链接。通过手把手教你使用Python抓取QQ音乐数据(第二弹)我们实现了获取 QQ 音乐指定歌曲的歌词和指定歌曲首页热评。通过手把手教你使用Python抓取QQ音乐数据(第三弹)我们实现了获取更多评论并生成词云图。此次我们将将三个项目封装在一起,通过菜...
最近在做小程序音频播放这一块的时候发现一个问题,就是微信官方提供的那首歌曲 此时此刻-许巍 真的好难听!测试组件的过程中听了强忍着听了无数遍。最终终于忍不下去决定要改变一下,但是从哪获取其他音频呢(除了从自己后台)。只能从网上了,调用QQ音乐,网易云音乐API等。但是考虑到这是微信小程序,所以保险还是选择调用QQ音乐(毕竟是一家的~)...
获取真正的url,然后通过分析得出url的翻页规律。
此处的url:https://c.y.qq.com/v8/fcg-bin/fcg_v8_toplist_cp.fcg?tpl=3&page=detail&date=2019-03-01&topid=4&am...
qq音乐免费下载,包含2个关键点,一个是根据歌名获取id,一个是根据id获取下载地址根据歌名获取idqq音乐有固定的根据歌名搜索歌曲信息api,参数是歌名。private String getSearchUrl(String songName) {
return "http://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmu...
接下来我们来梳理整个爬取流程。
#mermaid-svg-kJJtqyi4DgzgeD1q .label{font-family:'trebuchet ms', verdana, arial;font-family:var(--mermaid-font-family);fill:#333;color:#333}#mermaid-svg-kJJtqyi4DgzgeD1q .label text{fi
主要运用了Python中的Requests包和json包获取内容,写入到Mongodb数据库并保存,pandas用于导出数据,代码详细我最后会给出github
接口分析并爬取歌单id
我发现html源码并没有我想要的数据,所以分析了Ajax请求,得到了我想要的数据。
在Chrome按F12(或Fn+F12)打开开发者工具,在Network中选择JS,并且刷新页面,找到关于歌单的渲染连接。
前面,我们已经可以用requests库来获取网页的源代码,得到HTML代码。但我们真正想要的数据是包含在HTML代码之中的。要怎样才能从HTML代码中获取想要的信息呢?正则表达式是一个万能的方法!!!
**我们在用xpath或者bs爬取网页的时候经常会遇到这么一个问题:明明xpath或者bs写对的呀,为什么爬出来是个空值呢?这种问题我遇到过两种情况,第一种是xpath不对,浏览器会自动优化网页源码的xpath,这时候就需要手写xpath了(或者删去所得的xpath中的tbody试试。)第二种情况就是动态加载的网页啦~就比如咱们QQ音乐的网站:https://y.qq.com/portal/sea...

