

JavaScript学习7
最早的软件都是运行在大型机上的,软件使用者通过“哑终端”登陆到大型机上去运行软件。后来随着PC机的兴起,软件开始主要运行在桌面上,而数据库这样的软件运行在服务器端,这种Client/Server模式简称CS架构。
随着互联网的兴起,人们发现,CS架构不适合Web,最大的原因是Web应用程序的修改和升级非常迅速,而CS架构需要每个客户端逐个升级桌面App,因此,Browser/Server模式开始流行,简称BS架构。
在BS架构下,客户端只需要浏览器,应用程序的逻辑和数据都存储在服务器端。浏览器只需要请求服务器,获取Web页面,并把Web页面展示给用户即可。
当然,Web页面也具有极强的交互性。由于Web页面是用HTML编写的,而HTML具备超强的表现力,并且,服务器端升级后,客户端无需任何部署就可以使用到新的版本,因此,BS架构迅速流行起来。
今天,除了重量级的软件如Office,Photoshop等,大部分软件都以Web形式提供。比如,新浪提供的新闻、博客、微博等服务,均是Web应用。
Web应用开发可以说是目前软件开发中最重要的部分。Web开发也经历了好几个阶段:
静态Web页面:由文本编辑器直接编辑并生成静态的HTML页面,如果要修改Web页面的内容,就需要再次编辑HTML源文件,早期的互联网Web页面就是静态的;
CGI:由于静态Web页面无法与用户交互,比如用户填写了一个注册表单,静态Web页面就无法处理。要处理用户发送的动态数据,出现了Common Gateway Interface,简称CGI,用C/C++编写。
ASP/JSP/PHP:由于Web应用特点是修改频繁,用C/C++这样的低级语言非常不适合Web开发,而脚本语言由于开发效率高,与HTML结合紧密,因此,迅速取代了CGI模式。ASP是微软推出的用VBScript脚本编程的Web开发技术,而JSP用Java来编写脚本,PHP本身则是开源的脚本语言。
MVC:为了解决直接用脚本语言嵌入HTML导致的可维护性差的问题,Web应用也引入了Model-View-Controller的模式,来简化Web开发。ASP发展为 http:// ASP.Net ,JSP和PHP也有一大堆MVC框架。
目前,Web开发技术仍在快速发展中,异步开发、新的MVVM前端技术层出不穷。
由于Node.js把JavaScript引入了服务器端,因此,原来必须使用PHP/Java/C#/Python/Ruby等其他语言来开发服务器端程序,现在可以使用Node.js开发了!
用Node.js开发Web服务器端,有几个显著的优势:
一是后端语言也是JavaScript,以前掌握了前端JavaScript的开发人员,现在可以同时编写后端代码;
二是前后端统一使用JavaScript,就没有切换语言的障碍了;
三是速度快,非常快!这得益于Node.js天生是异步的。
在Node.js诞生后的短短几年里,出现了无数种Web框架、ORM框架、模版引擎、测试框架、自动化构建工具,数量之多,即使是JavaScript老司机,也不免眼花缭乱。
常见的Web框架包括: Express , Sails.js , koa , Meteor , DerbyJS , Total.js , restify ……
ORM框架比Web框架要少一些: Sequelize , ORM2 , Bookshelf.js , Objection.js ……
模版引擎PK: Jade , EJS , Swig , Nunjucks , doT.js ……
测试框架包括: Mocha , Expresso , Unit.js , Karma ……
构建工具有: Grunt , Gulp , Webpack ……
目前,在npm上已发布的开源Node.js模块数量超过了30万个。
有选择恐惧症的朋友,看到这里可以洗洗睡了。
好消息是这个教程已经帮你选好了,你只需要跟着教程一条道走到黑就可以了。
koa是Express的下一代基于Node.js的web框架,目前有1.x和2.0两个版本。
历史
1. Express
Express是第一代最流行的web框架,它对Node.js的http进行了封装,用起来如下:
var express = require('express');
var app = express();
app.get('/', function (req, res) {
res.send('Hello World!');
app.listen(3000, function () {
console.log('Example app listening on port 3000!');
虽然Express的API很简单,但是它是基于ES5的语法,要实现异步代码,只有一个方法:回调。如果异步嵌套层次过多,代码写起来就非常难看:
app.get('/test', function (req, res) {
fs.readFile('/file1', function (err, data) {
if (err) {
res.status(500).send('read file1 error');
fs.readFile('/file2', function (err, data) {
if (err) {
res.status(500).send('read file2 error');
res.type('text/plain');
res.send(data);
虽然可以用async这样的库来组织异步代码,但是用回调写异步实在是太痛苦了!
2. koa 1.0
随着新版Node.js开始支持ES6,Express的团队又基于ES6的generator重新编写了下一代web框架koa。和Express相比,koa 1.0使用generator实现异步,代码看起来像同步的:
var koa = require('koa');
var app = koa();
app.use('/test', function *() {
yield doReadFile1();
var data = yield doReadFile2();
this.body = data;
app.listen(3000);
用generator实现异步比回调简单了不少,但是generator的本意并不是异步。Promise才是为异步设计的,但是Promise的写法……想想就复杂。为了简化异步代码,ES7(目前是草案,还没有发布)引入了新的关键字
async
和
await
,可以轻松地把一个function变为异步模式:
async function () {
var data = await fs.read('/file1');
这是JavaScript未来标准的异步代码,非常简洁,并且易于使用。
3. koa2
koa团队并没有止步于koa 1.0,他们非常超前地基于ES7开发了koa2,和koa 1相比,koa2完全使用Promise并配合
async
来实现异步。
koa2的代码看上去像这样:
app.use(async (ctx, next) => {
await next();
var data = await doReadFile();
ctx.response.type = 'text/plain';
ctx.response.body = data;
出于兼容性考虑,目前koa2仍支持generator的写法,但下一个版本将会去掉。
选择哪个版本?
目前JavaScript处于高速进化中,ES7是大势所趋。为了紧跟时代潮流,教程将使用最新的koa2开发
先,我们创建一个目录
hello-koa
并作为工程目录用VS Code打开。然后,我们创建
app.js
,输入以下代码:
// 导入koa,和koa 1.x不同,在koa2中,我们导入的是一个class,因此用大写的Koa表示:
const Koa = require('koa');
// 创建一个Koa对象表示web app本身:
const app = new Koa();
// 对于任何请求,app将调用该异步函数处理请求:
app.use(async (ctx, next) => {
await next();
ctx.response.type = 'text/html';
ctx.response.body = '<h1>Hello, koa2!</h1>';
// 在端口3000监听:
app.listen(3000);
console.log('app started at port 3000...');
对于每一个http请求,koa将调用我们传入的异步函数来处理:
async (ctx, next) => {
await next();
// 设置response的Content-Type:
ctx.response.type = 'text/html';
// 设置response的内容:
ctx.response.body = '<h1>Hello, koa2!</h1>';
}
其中,参数
ctx
是由koa传入的封装了request和response的变量,我们可以通过它访问request和response,
next
是koa传入的将要处理的下一个异步函数。
上面的异步函数中,我们首先用
await next();
处理下一个异步函数,然后,设置response的Content-Type和内容。
由
async
标记的函数称为异步函数,在异步函数中,可以用
await
调用另一个异步函数,这两个关键字将在ES7中引入。
现在我们遇到第一个问题:koa这个包怎么装,
app.js
才能正常导入它?
方法一:可以用npm命令直接安装koa。先打开命令提示符,务必把当前目录切换到
hello-koa
这个目录,然后执行命令:
C:\...\hello-koa> npm install koa@2.0.0npm会把koa2以及koa2依赖的所有包全部安装到当前目录的node_modules目录下。
方法二:在
hello-koa
这个目录下创建一个
package.json
,这个文件描述了我们的
hello-koa
工程会用到哪些包。完整的文件内容如下:
{
"name": "hello-koa2",
"version": "1.0.0",
"description": "Hello Koa 2 example with async",
"main": "app.js",
"scripts": {
"start": "node app.js"
"keywords": [
"koa",
"async"
"author": "Michael Liao",
"license": "Apache-2.0",
"repository": {
"type": "git",
"url": "https://github.com/michaelliao/learn-javascript.git"
"dependencies": {
"koa": "2.0.0"
}
其中,
dependencies
描述了我们的工程依赖的包以及版本号。其他字段均用来描述项目信息,可任意填写。
然后,我们在
hello-koa
目录下执行
npm install
就可以把所需包以及依赖包一次性全部装好:
C:\...\hello-koa> npm install
很显然,第二个方法更靠谱,因为我们只要在
package.json
正确设置了依赖,npm就会把所有用到的包都装好。
注意
,任何时候都可以直接删除整个
node_modules
目录,因为用
npm install
命令可以完整地重新下载所有依赖。并且,这个目录不应该被放入版本控制中。
现在,我们的工程结构如下:
hello-koa/
+- .vscode/
| +- launch.json <-- VSCode 配置文件
+- app.js <-- 使用koa的js
+- package.json <-- 项目描述文件
+- node_modules/ <-- npm安装的所有依赖包
紧接着,我们在
package.json
中添加依赖包:
"dependencies": {
"koa": "2.0.0"
}
然后使用
npm install
命令安装后,在VS Code中执行
app.js
,调试控制台输出如下:
node --debug-brk=40645 --nolazy app.js
Debugger listening on port 40645
app started at port 3000...
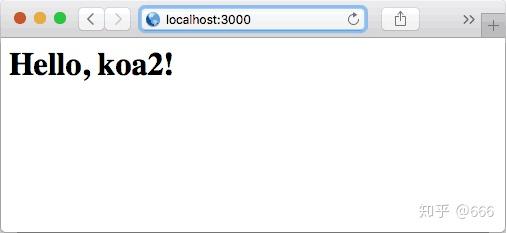
我们打开浏览器,输入
http://localhost:3000
,即可看到效果:
还可以直接用命令
node app.js
在命令行启动程序,或者用
npm start
启动。
npm start
命令会让npm执行定义在
package.json
文件中的start对应命令:
"scripts": {
"start": "node app.js"
koa middleware
让我们再仔细看看koa的执行逻辑。核心代码是:
app.use(async (ctx, next) => {
await next();
ctx.response.type = 'text/html';
ctx.response.body = '<h1>Hello, koa2!</h1>';
});
每收到一个http请求,koa就会调用通过
app.use()
注册的async函数,并传入
ctx
和
next
参数。
我们可以对
ctx
操作,并设置返回内容。但是为什么要调用
await next()
?
原因是koa把很多async函数组成一个处理链,每个async函数都可以做一些自己的事情,然后用
await next()
来调用下一个async函数。我们把每个async函数称为middleware,这些middleware可以组合起来,完成很多有用的功能。
例如,可以用以下3个middleware组成处理链,依次打印日志,记录处理时间,输出HTML:
app.use(async (ctx, next) => {
console.log(`${ctx.request.method} ${ctx.request.url}`); // 打印URL
await next(); // 调用下一个middleware
app.use(async (ctx, next) => {
const start = new Date().getTime(); // 当前时间
await next(); // 调用下一个middleware
const ms = new Date().getTime() - start; // 耗费时间
console.log(`Time: ${ms}ms`); // 打印耗费时间
app.use(async (ctx, next) => {
await next();
ctx.response.type = 'text/html';
ctx.response.body = '<h1>Hello, koa2!</h1>';
middleware的顺序很重要,也就是调用
app.use()
的顺序决定了middleware的顺序。
此外,如果一个middleware没有调用
await next()
,会怎么办?答案是后续的middleware将不再执行了。这种情况也很常见,例如,一个检测用户权限的middleware可以决定是否继续处理请求,还是直接返回403错误:
app.use(async (ctx, next) => {
if (await checkUserPermission(ctx)) {
await next();
} else {
ctx.response.status = 403;
});理解了middleware,我们就已经会用koa了!
最后注意
ctx
对象有一些简写的方法,例如
ctx.url
相当于
ctx.request.url
,
ctx.type
相当于
ctx.response.type
。
在hello-koa工程中,我们处理http请求一律返回相同的HTML,这样虽然非常简单,但是用浏览器一测,随便输入任何URL都会返回相同的网页。

正常情况下,我们应该对不同的URL调用不同的处理函数,这样才能返回不同的结果。例如像这样写:
app.use(async (ctx, next) => {
if (ctx.request.path === '/') {
ctx.response.body = 'index page';
} else {
await next();
app.use(async (ctx, next) => {
if (ctx.request.path === '/test') {
ctx.response.body = 'TEST page';
} else {
await next();
app.use(async (ctx, next) => {
if (ctx.request.path === '/error') {
ctx.response.body = 'ERROR page';
} else {
await next();
});这么写是可以运行的,但是好像有点蠢。
应该有一个能集中处理URL的middleware,它根据不同的URL调用不同的处理函数,这样,我们才能专心为每个URL编写处理函数。
koa-router
为了处理URL,我们需要引入
koa-router
这个middleware,让它负责处理URL映射。
我们把上一节的
hello-koa
工程复制一份,重命名为
url-koa
。
先在
package.json
中添加依赖项:
"koa-router": "7.0.0"
然后用
npm install
安装。
接下来,我们修改
app.js
,使用
koa-router
来处理URL:
const Koa = require('koa');
// 注意require('koa-router')返回的是函数:
const router = require('koa-router')();
const app = new Koa();
// log request URL:
app.use(async (ctx, next) => {
console.log(`Process ${ctx.request.method} ${ctx.request.url}...`);
await next();
// add url-route:
router.get('/hello/:name', async (ctx, next) => {
var name = ctx.params.name;
ctx.response.body = `<h1>Hello, ${name}!</h1>`;
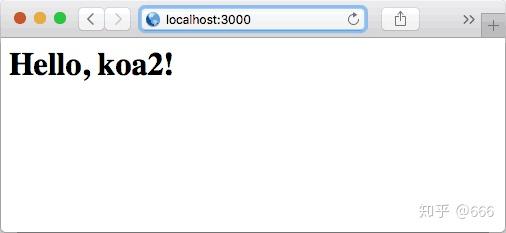
router.get('/', async (ctx, next) => {
ctx.response.body = '<h1>Index</h1>';
// add router middleware:
app.use(router.routes());
app.listen(3000);
console.log('app started at port 3000...');
注意导入
koa-router
的语句最后的
()
是函数调用:
const router = require('koa-router')();
相当于:
const fn_router = require('koa-router');
const router = fn_router();
然后,我们使用
router.get('/path', async fn)
来注册一个GET请求。可以在请求路径中使用带变量的
/hello/:name
,变量可以通过
ctx.params.name
访问。
再运行
app.js
,我们就可以测试不同的URL:
输入首页: http:// localhost:3000/
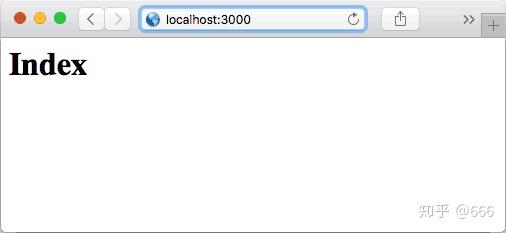
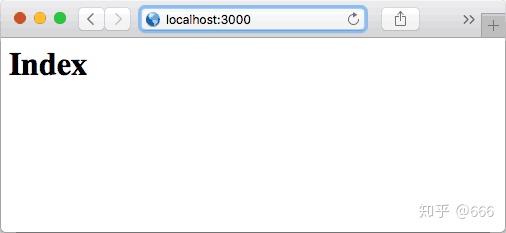
输入: http:// localhost:3000/hello/ko a
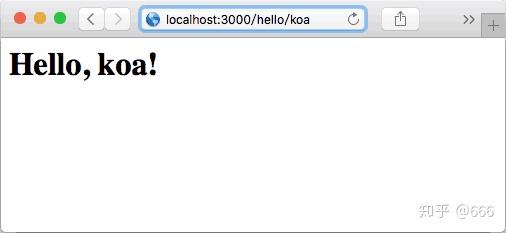
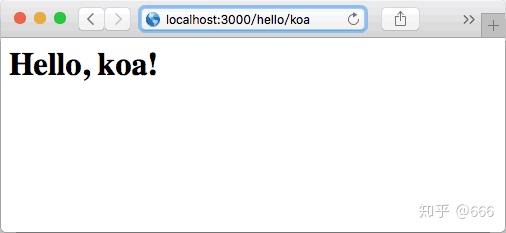
处理post请求
用
router.get('/path', async fn)
处理的是get请求。如果要处理post请求,可以用
router.post('/path', async fn)
。
用post请求处理URL时,我们会遇到一个问题:post请求通常会发送一个表单,或者JSON,它作为request的body发送,但无论是Node.js提供的原始request对象,还是koa提供的request对象,都 不提供 解析request的body的功能!
所以,我们又需要引入另一个middleware来解析原始request请求,然后,把解析后的参数,绑定到
ctx.request.body
中。
koa-bodyparser
就是用来干这个活的。
我们在
package.json
中添加依赖项:
"koa-bodyparser": "3.2.0"
然后使用
npm install
安装。
下面,修改
app.js
,引入
koa-bodyparser
:
const bodyParser = require('koa-bodyparser');
在合适的位置加上:
app.use(bodyParser());
由于middleware的顺序很重要,这个
koa-bodyparser
必须在
router
之前被注册到
app
对象上。
现在我们就可以处理post请求了。写一个简单的登录表单:
router.get('/', async (ctx, next) => {
ctx.response.body = `<h1>Index</h1>
<form action="/signin" method="post">
<p>Name: <input name="name" value="koa"></p>
<p>Password: <input name="password" type="password"></p>
<p><input type="submit" value="Submit"></p>
</form>`;
router.post('/signin', async (ctx, next) => {
name = ctx.request.body.name || '',
password = ctx.request.body.password || '';
console.log(`signin with name: ${name}, password: ${password}`);
if (name === 'koa' && password === '12345') {
ctx.response.body = `<h1>Welcome, ${name}!</h1>`;
} else {
ctx.response.body = `<h1>Login failed!</h1>
<p><a href="/">Try again</a></p>`;
});
注意到我们用
var name = ctx.request.body.name || ''
拿到表单的
name
字段,如果该字段不存在,默认值设置为
''
。
类似的,put、delete、head请求也可以由router处理。
重构
现在,我们已经可以处理不同的URL了,但是看看
app.js
,总觉得还是有点不对劲。

所有的URL处理函数都放到
app.js
里显得很乱,而且,每加一个URL,就需要修改
app.js
。随着URL越来越多,
app.js
就会越来越长。
如果能把URL处理函数集中到某个js文件,或者某几个js文件中就好了,然后让
app.js
自动导入所有处理URL的函数。这样,代码一分离,逻辑就显得清楚了。最好是这样:
url2-koa/
+- .vscode/
| +- launch.json <-- VSCode 配置文件
+- controllers/
| +- login.js <-- 处理login相关URL
| +- users.js <-- 处理用户管理相关URL
+- app.js <-- 使用koa的js
+- package.json <-- 项目描述文件
+- node_modules/ <-- npm安装的所有依赖包
于是我们把
url-koa
复制一份,重命名为
url2-koa
,准备重构这个项目。
我们先在
controllers
目录下编写
index.js
:
var fn_index = async (ctx, next) => {
ctx.response.body = `<h1>Index</h1>
<form action="/signin" method="post">
<p>Name: <input name="name" value="koa"></p>
<p>Password: <input name="password" type="password"></p>
<p><input type="submit" value="Submit"></p>
</form>`;
var fn_signin = async (ctx, next) => {
name = ctx.request.body.name || '',
password = ctx.request.body.password || '';
console.log(`signin with name: ${name}, password: ${password}`);
if (name === 'koa' && password === '12345') {
ctx.response.body = `<h1>Welcome, ${name}!</h1>`;
} else {
ctx.response.body = `<h1>Login failed!</h1>
<p><a href="/">Try again</a></p>`;
module.exports = {
'GET /': fn_index,
'POST /signin': fn_signin
};
这个
index.js
通过
module.exports
把两个URL处理函数暴露出来。
类似的,
hello.js
把一个URL处理函数暴露出来:
var fn_hello = async (ctx, next) => {
var name = ctx.params.name;
ctx.response.body = `<h1>Hello, ${name}!</h1>`;
module.exports = {
'GET /hello/:name': fn_hello
现在,我们修改
app.js
,让它自动扫描
controllers
目录,找到所有
js
文件,导入,然后注册每个URL:
// 先导入fs模块,然后用readdirSync列出文件
// 这里可以用sync是因为启动时只运行一次,不存在性能问题:
var files = fs.readdirSync(__dirname + '/controllers');
// 过滤出.js文件:
var js_files = files.filter((f)=>{
return f.endsWith('.js');
// 处理每个js文件:
for (var f of js_files) {
console.log(`process controller: ${f}...`);
// 导入js文件:
let mapping = require(__dirname + '/controllers/' + f);
for (var url in mapping) {
if (url.startsWith('GET ')) {
// 如果url类似"GET xxx":
var path = url.substring(4);
router.get(path, mapping[url]);
console.log(`register URL mapping: GET ${path}`);
} else if (url.startsWith('POST ')) {
// 如果url类似"POST xxx":
var path = url.substring(5);
router.post(path, mapping[url]);
console.log(`register URL mapping: POST ${path}`);
} else {
// 无效的URL:
console.log(`invalid URL: ${url}`);
如果上面的大段代码看起来还是有点费劲,那就把它拆成更小单元的函数:
function addMapping(router, mapping) {
for (var url in mapping) {
if (url.startsWith('GET ')) {
var path = url.substring(4);
router.get(path, mapping[url]);
console.log(`register URL mapping: GET ${path}`);
} else if (url.startsWith('POST ')) {
var path = url.substring(5);
router.post(path, mapping[url]);
console.log(`register URL mapping: POST ${path}`);
} else {
console.log(`invalid URL: ${url}`);
function addControllers(router) {
var files = fs.readdirSync(__dirname + '/controllers');
var js_files = files.filter((f) => {
return f.endsWith('.js');
for (var f of js_files) {
console.log(`process controller: ${f}...`);
let mapping = require(__dirname + '/controllers/' + f);
addMapping(router, mapping);
addControllers(router);
确保每个函数功能非常简单,一眼能看明白,是代码可维护的关键。
Controller Middleware
最后,我们把扫描
controllers
目录和创建
router
的代码从
app.js
中提取出来,作为一个简单的middleware使用,命名为
controller.js
:
const fs = require('fs');
function addMapping(router, mapping) {
function addControllers(router, dir) {
module.exports = function (dir) {
controllers_dir = dir || 'controllers', // 如果不传参数,扫描目录默认为'controllers'
router = require('koa-router')();
addControllers(router, controllers_dir);
return router.routes();
这样一来,我们在
app.js
的代码又简化了:
...
// 导入controller middleware:
const controller = require('./controller');
// 使用middleware:
app.use(controller());
经过重新整理后的工程
url2-koa
目前具备非常好的模块化,所有处理URL的函数按功能组存放在
controllers
目录,今后我们也只需要不断往这个目录下加东西就可以了,
app.js
保持不变。
Nunjucks
Nunjucks是什么东东?其实它是一个模板引擎。
那什么是模板引擎?
模板引擎就是基于模板配合数据构造出字符串输出的一个组件。比如下面的函数就是一个模板引擎:
function examResult (data) {
return `${data.name}同学一年级期末考试语文${data.chinese}分,数学${data.math}分,位于年级第${data.ranking}名。`
}如果我们输入数据如下:
examResult({
name: '小明',
chinese: 78,
math: 87,
ranking: 999
});该模板引擎把模板字符串里面对应的变量替换以后,就可以得到以下输出:
小明同学一年级期末考试语文78分,数学87分,位于年级第999名。模板引擎最常见的输出就是输出网页,也就是HTML文本。当然,也可以输出任意格式的文本,比如Text,XML,Markdown等等。
有同学要问了:既然JavaScript的模板字符串可以实现模板功能,那为什么我们还需要另外的模板引擎?
因为JavaScript的模板字符串必须写在JavaScript代码中,要想写出新浪首页这样复杂的页面,是非常困难的。
输出HTML有几个特别重要的问题需要考虑:
转义
对特殊字符要转义,避免受到XSS攻击。比如,如果变量
name
的值不是
小明
,而是
小明<script>...</script>
,模板引擎输出的HTML到了浏览器,就会自动执行恶意JavaScript代码。
格式化
对不同类型的变量要格式化,比如,货币需要变成
12,345.00
这样的格式,日期需要变成
2016-01-01
这样的格式。
简单逻辑
模板还需要能执行一些简单逻辑,比如,要按条件输出内容,需要if实现如下输出:
{{ name }}同学,
{% if score >= 90 %}
成绩优秀,应该奖励
{% elif score >=60 %}
成绩良好,继续努力
{% else %}
不及格,建议回家打屁股
{% endif %}
所以,我们需要一个功能强大的模板引擎,来完成页面输出的功能。
Nunjucks
我们选择Nunjucks作为模板引擎。Nunjucks是Mozilla开发的一个纯JavaScript编写的模板引擎,既可以用在Node环境下,又可以运行在浏览器端。但是,主要还是运行在Node环境下,因为浏览器端有更好的模板解决方案,例如MVVM框架。
如果你使用过Python的模板引擎 jinja2 ,那么使用Nunjucks就非常简单,两者的语法几乎是一模一样的,因为Nunjucks就是用JavaScript重新实现了jinjia2。
从上面的例子我们可以看到,虽然模板引擎内部可能非常复杂,但是使用一个模板引擎是非常简单的,因为本质上我们只需要构造这样一个函数:
function render(view, model) {
// TODO:...
其中,
view
是模板的名称(又称为视图),因为可能存在多个模板,需要选择其中一个。
model
就是数据,在JavaScript中,它就是一个简单的Object。
render
函数返回一个字符串,就是模板的输出。
下面我们来使用Nunjucks这个模板引擎来编写几个HTML模板,并且用实际数据来渲染模板并获得最终的HTML输出。
我们创建一个
use-nunjucks
的VS Code工程结构如下:
use-nunjucks/
+- .vscode/
| +- launch.json <-- VSCode 配置文件
+- views/
| +- hello.html <-- HTML模板文件
+- app.js <-- 入口js
+- package.json <-- 项目描述文件
+- node_modules/ <-- npm安装的所有依赖包
其中,模板文件存放在
views
目录中。
我们先在
package.json
中添加
nunjucks
的依赖:
"nunjucks": "2.4.2"
注意,模板引擎是可以独立使用的,并不需要依赖koa。用
npm install
安装所有依赖包。
紧接着,我们要编写使用Nunjucks的函数
render
。怎么写?方法是查看Nunjucks的
官方文档
,仔细阅读后,在
app.js
中编写代码如下:
const nunjucks = require('nunjucks');
function createEnv(path, opts) {
autoescape = opts.autoescape === undefined ? true : opts.autoescape,
noCache = opts.noCache || false,
watch = opts.watch || false,
throwOnUndefined = opts.throwOnUndefined || false,
env = new nunjucks.Environment(
new nunjucks.FileSystemLoader('views', {
noCache: noCache,
watch: watch,
}), {
autoescape: autoescape,
throwOnUndefined: throwOnUndefined
if (opts.filters) {
for (var f in opts.filters) {
env.addFilter(f, opts.filters[f]);
return env;
var env = createEnv('views', {
watch: true,
filters: {
hex: function (n) {
return '0x' + n.toString(16);
变量
env
就表示Nunjucks模板引擎对象,它有一个
render(view, model)
方法,正好传入
view
和
model
两个参数,并返回字符串。
创建
env
需要的参数可以查看文档获知。我们用
autoescape = opts.autoescape && true
这样的代码给每个参数加上默认值,最后使用
new nunjucks.FileSystemLoader('views')
创建一个文件系统加载器,从
views
目录读取模板。
我们编写一个
hello.html
模板文件,放到
views
目录下,内容如下:
<h1>Hello {{ name }}</h1>然后,我们就可以用下面的代码来渲染这个模板:
var s = env.render('hello.html', { name: '小明' });
console.log(s);
获得输出如下:
<h1>Hello 小明</h1>咋一看,这和使用JavaScript模板字符串没啥区别嘛。不过,试试:
var s = env.render('hello.html', { name: '<script>alert("小明")</script>' });
console.log(s);获得输出如下:
<h1>Hello <script>alert("小明")</script></h1>这样就避免了输出恶意脚本。
此外,可以使用Nunjucks提供的功能强大的tag,编写条件判断、循环等功能,例如:
<!-- 循环输出名字 -->
<h3>Fruits List</h3>
{% for f in fruits %}
<p>{{ f }}</p>
{% endfor %}
</body>Nunjucks模板引擎最强大的功能在于模板的继承。仔细观察各种网站可以发现,网站的结构实际上是类似的,头部、尾部都是固定格式,只有中间页面部分内容不同。如果每个模板都重复头尾,一旦要修改头部或尾部,那就需要改动所有模板。
更好的方式是使用继承。先定义一个基本的网页框架
base.html
:
<html><body>
{% block header %} <h3>Unnamed</h3> {% endblock %}
{% block body %} <div>No body</div> {% endblock %}
{% block footer %} <div>copyright</div> {% endblock %}
</body>
base.html
定义了三个可编辑的块,分别命名为
header
、
body
和
footer
。子模板可以有选择地对块进行重新定义:
{% extends 'base.html' %}
{% block header %}<h1>{{ header }}</h1>{% endblock %}
{% block body %}<p>{{ body }}</p>{% endblock %}然后,我们对子模板进行渲染:
console.log(env.render('extend.html', {
header: 'Hello',
body: 'bla bla bla...'
}));输出HTML如下:
<html><body>
<h1>Hello</h1>
<p>bla bla bla...</p>
<div>copyright</div> <-- footer没有重定义,所以仍使用父模板的内容
</body>性能
最后我们要考虑一下Nunjucks的性能。
对于模板渲染本身来说,速度是非常非常快的,因为就是拼字符串嘛,纯CPU操作。
性能问题主要出现在从文件读取模板内容这一步。这是一个IO操作,在Node.js环境中,我们知道,单线程的JavaScript最不能忍受的就是同步IO,但Nunjucks默认就使用同步IO读取模板文件。
好消息是Nunjucks会缓存已读取的文件内容,也就是说,模板文件最多读取一次,就会放在内存中,后面的请求是不会再次读取文件的,只要我们指定了
noCache: false
这个参数。
在开发环境下,可以关闭cache,这样每次重新加载模板,便于实时修改模板。在生产环境下,一定要打开cache,这样就不会有性能问题。
Nunjucks也提供了异步读取的方式,但是这样写起来很麻烦,有简单的写法我们就不会考虑复杂的写法。保持代码简单是可维护性的关键。
MVC
我们已经可以用koa处理不同的URL,还可以用Nunjucks渲染模板。现在,是时候把这两者结合起来了!
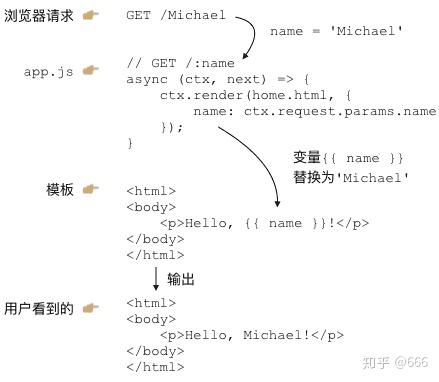
当用户通过浏览器请求一个URL时,koa将调用某个异步函数处理该URL。在这个异步函数内部,我们用一行代码:
ctx.render('home.html', { name: 'Michael' });通过Nunjucks把数据用指定的模板渲染成HTML,然后输出给浏览器,用户就可以看到渲染后的页面了:
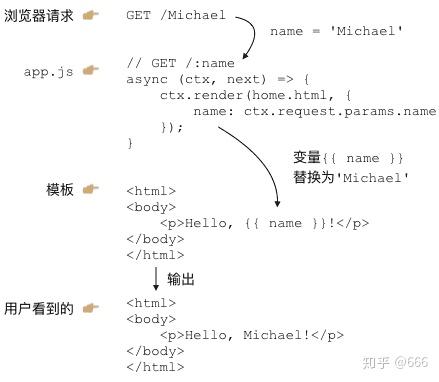
这就是传说中的MVC:Model-View-Controller,中文名“模型-视图-控制器”。
异步函数是C:Controller,Controller负责业务逻辑,比如检查用户名是否存在,取出用户信息等等;
包含变量
{{ name }}
的模板就是V:View,View负责显示逻辑,通过简单地替换一些变量,View最终输出的就是用户看到的HTML。
MVC中的Model在哪?Model是用来传给View的,这样View在替换变量的时候,就可以从Model中取出相应的数据。
上面的例子中,Model就是一个JavaScript对象:
{ name: 'Michael' }
下面,我们根据原来的
url2-koa
创建工程
view-koa
,把koa2、Nunjucks整合起来,然后,把原来直接输出字符串的方式,改为
ctx.render(view, model)
的方式。
工程
view-koa
结构如下:
view-koa/
+- .vscode/
| +- launch.json <-- VSCode 配置文件
+- controllers/ <-- Controller
+- views/ <-- html模板文件
+- static/ <-- 静态资源文件
+- controller.js <-- 扫描注册Controller
+- app.js <-- 使用koa的js
+- package.json <-- 项目描述文件
+- node_modules/ <-- npm安装的所有依赖包
在
package.json
中,我们将要用到的依赖包有:
"koa": "2.0.0",
"koa-bodyparser": "3.2.0",
"koa-router": "7.0.0",
"nunjucks": "2.4.2",
"mime": "1.3.4",
"mz": "2.4.0"
先用
npm install
安装依赖包。
然后,我们准备编写以下两个Controller:
处理首页 GET /
我们定义一个async函数处理首页URL
/
:
async (ctx, next) => {
ctx.render('index.html', {
title: 'Welcome'
}
注意到koa并没有在
ctx
对象上提供
render
方法,这里我们假设应该这么使用,这样,我们在编写Controller的时候,最后一步调用
ctx.render(view, model)
就完成了页面输出。
处理登录请求 POST /signin
我们再定义一个async函数处理登录请求
/signin
:
async (ctx, next) => {
email = ctx.request.body.email || '',
password = ctx.request.body.password || '';
if (email === 'admin@example.com' && password === '123456') {
// 登录成功:
ctx.render('signin-ok.html', {
title: 'Sign In OK',
name: 'Mr Node'
} else {
// 登录失败:
ctx.render('signin-failed.html', {
title: 'Sign In Failed'
由于登录请求是一个POST,我们就用
ctx.request.body.<name>
拿到POST请求的数据,并给一个默认值。
登录成功时我们用
signin-ok.html
渲染,登录失败时我们用
signin-failed.html
渲染,所以,我们一共需要以下3个View:
- index.html
- signin-ok.html
- signin-failed.html
编写View
在编写View的时候,我们实际上是在编写HTML页。为了让页面看起来美观大方,使用一个现成的CSS框架是非常有必要的。我们用
Bootstrap
这个CSS框架。从首页下载zip包后解压,我们把所有静态资源文件放到
/static
目录下:
view-koa/
+- static/
+- css/ <- 存放bootstrap.css等
+- fonts/ <- 存放字体文件
+- js/ <- 存放bootstrap.js等
这样我们在编写HTML的时候,可以直接用Bootstrap的CSS,像这样:
<link rel="stylesheet" href="/static/css/bootstrap.css">现在,在使用MVC之前,第一个问题来了,如何处理静态文件?
我们把所有静态资源文件全部放入
/static
目录,目的就是能统一处理静态文件。在koa中,我们需要编写一个middleware,处理以
/static/
开头的URL。
编写middleware
我们来编写一个处理静态文件的middleware。编写middleware实际上一点也不复杂。我们先创建一个
static-files.js
的文件,编写一个能处理静态文件的middleware:
const path = require('path');
const mime = require('mime');
const fs = require('mz/fs');
// url: 类似 '/static/'
// dir: 类似 __dirname + '/static'
function staticFiles(url, dir) {
return async (ctx, next) => {
let rpath = ctx.request.path;
// 判断是否以指定的url开头:
if (rpath.startsWith(url)) {
// 获取文件完整路径:
let fp = path.join(dir, rpath.substring(url.length));
// 判断文件是否存在:
if (await fs.exists(fp)) {
// 查找文件的mime:
ctx.response.type = mime.lookup(rpath);
// 读取文件内容并赋值给response.body:
ctx.response.body = await fs.readFile(fp);
} else {
// 文件不存在:
ctx.response.status = 404;
} else {
// 不是指定前缀的URL,继续处理下一个middleware:
await next();
module.exports = staticFiles;
staticFiles
是一个普通函数,它接收两个参数:URL前缀和一个目录,然后返回一个async函数。这个async函数会判断当前的URL是否以指定前缀开头,如果是,就把URL的路径视为文件,并发送文件内容。如果不是,这个async函数就不做任何事情,而是简单地调用
await next()
让下一个middleware去处理请求。
我们使用了一个
mz
的包,并通过
require('mz/fs');
导入。
mz
提供的API和Node.js的
fs
模块完全相同,但
fs
模块使用回调,而
mz
封装了
fs
对应的函数,并改为Promise。这样,我们就可以非常简单的用
await
调用
mz
的函数,而不需要任何回调。
所有的第三方包都可以通过npm官网搜索并查看其文档:
最后,这个middleware使用起来也很简单,在
app.js
里加一行代码:
let staticFiles = require('./static-files');
app.use(staticFiles('/static/', __dirname + '/static'));
注意 :也可以去npm搜索能用于koa2的处理静态文件的包并直接使用。
集成Nunjucks
集成Nunjucks实际上也是编写一个middleware,这个middleware的作用是给
ctx
对象绑定一个
render(view, model)
的方法,这样,后面的Controller就可以调用这个方法来渲染模板了。
我们创建一个
templating.js
来实现这个middleware:
const nunjucks = require('nunjucks');
function createEnv(path, opts) {
autoescape = opts.autoescape === undefined ? true : opts.autoescape,
noCache = opts.noCache || false,
watch = opts.watch || false,
throwOnUndefined = opts.throwOnUndefined || false,
env = new nunjucks.Environment(
new nunjucks.FileSystemLoader(path || 'views', {
noCache: noCache,
watch: watch,
}), {
autoescape: autoescape,
throwOnUndefined: throwOnUndefined
if (opts.filters) {
for (var f in opts.filters) {
env.addFilter(f, opts.filters[f]);
return env;
function templating(path, opts) {
// 创建Nunjucks的env对象:
var env = createEnv(path, opts);
return async (ctx, next) => {
// 给ctx绑定render函数:
ctx.render = function (view, model) {
// 把render后的内容赋值给response.body:
ctx.response.body = env.render(view, Object.assign({}, ctx.state || {}, model || {}));
// 设置Content-Type:
ctx.response.type = 'text/html';
// 继续处理请求:
await next();
module.exports = templating;
注意到
createEnv()
函数和前面使用Nunjucks时编写的函数是一模一样的。我们主要关心
tempating()
函数,它会返回一个middleware,在这个middleware中,我们只给
ctx
“安装”了一个
render()
函数,其他什么事情也没干,就继续调用下一个middleware。
使用的时候,我们在
app.js
添加如下代码:
const isProduction = process.env.NODE_ENV === 'production';
app.use(templating('views', {
noCache: !isProduction,
watch: !isProduction
这里我们定义了一个常量
isProduction
,它判断当前环境是否是production环境。如果是,就使用缓存,如果不是,就关闭缓存。在开发环境下,关闭缓存后,我们修改View,可以直接刷新浏览器看到效果,否则,每次修改都必须重启Node程序,会极大地降低开发效率。
Node.js在全局变量
process
中定义了一个环境变量
env.NODE_ENV
,为什么要使用该环境变量?因为我们在开发的时候,环境变量应该设置为
'development'
,而部署到服务器时,环境变量应该设置为
'production'
。在编写代码的时候,要根据当前环境作不同的判断。
注意
:生产环境上必须配置环境变量
NODE_ENV = 'production'
,而开发环境不需要配置,实际上
NODE_ENV
可能是
undefined
,所以判断的时候,不要用
NODE_ENV === 'development'
。
类似的,我们在使用上面编写的处理静态文件的middleware时,也可以根据环境变量判断:
if (! isProduction) {
let staticFiles = require('./static-files');
app.use(staticFiles('/static/', __dirname + '/static'));
这是因为在生产环境下,静态文件是由部署在最前面的反向代理服务器(如Nginx)处理的,Node程序不需要处理静态文件。而在开发环境下,我们希望koa能顺带处理静态文件,否则,就必须手动配置一个反向代理服务器,这样会导致开发环境非常复杂。
编写View
在编写View的时候,非常有必要先编写一个
base.html
作为骨架,其他模板都继承自
base.html
,这样,才能大大减少重复工作。
编写HTML不在本教程的讨论范围之内。这里我们参考Bootstrap的官网简单编写了
base.html
。
运行
一切顺利的话,这个
view-koa
工程应该可以顺利运行。运行前,我们再检查一下
app.js
里的middleware的顺序:
第一个middleware是记录URL以及页面执行时间:
app.use(async (ctx, next) => {
console.log(`Process ${ctx.request.method} ${ctx.request.url}...`);
start = new Date().getTime(),
execTime;
await next();
execTime = new Date().getTime() - start;
ctx.response.set('X-Response-Time', `${execTime}ms`);
});第二个middleware处理静态文件:
if (! isProduction) {
let staticFiles = require('./static-files');
app.use(staticFiles('/static/', __dirname + '/static'));
第三个middleware解析POST请求:
app.use(bodyParser());
第四个middleware负责给
ctx
加上
render()
来使用Nunjucks:
app.use(templating('view', {
noCache: !isProduction,
watch: !isProduction
最后一个middleware处理URL路由:
app.use(controller());
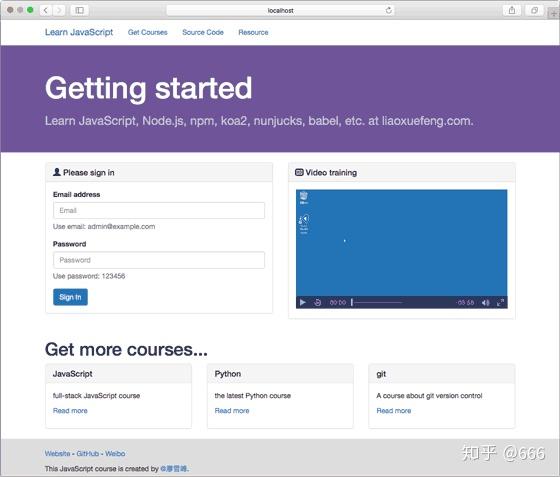
现在,在VS Code中运行代码,不出意外的话,在浏览器输入
localhost:3000/
,可以看到首页内容:
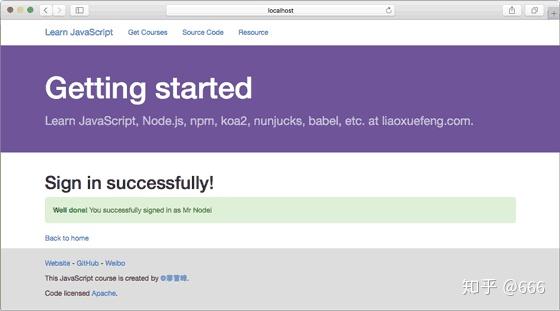
直接在首页登录,如果输入正确的Email和Password,进入登录成功的页面:
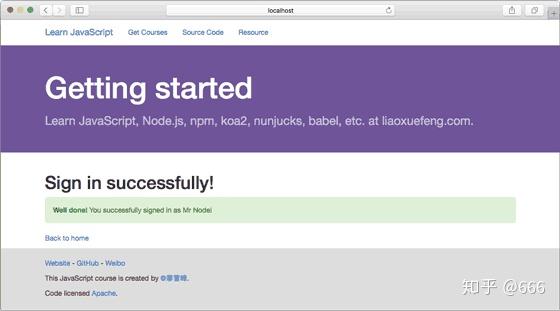
如果输入的Email和Password不正确,进入登录失败的页面:
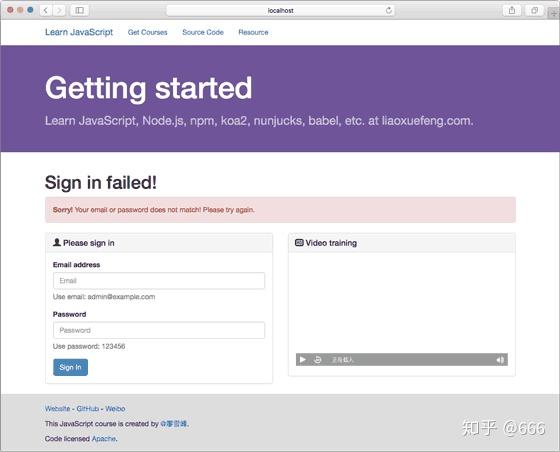
怎么判断正确的Email和Password?目前我们在
signin.js
中是这么判断的:
if (email === 'admin@example.com' && password === '123456') {
}当然,真实的网站会根据用户输入的Email和Password去数据库查询并判断登录是否成功,不过这需要涉及到Node.js环境如何操作数据库,我们后面再讨论。
扩展
注意到
ctx.render
内部渲染模板时,Model对象并不是传入的model变量,而是:
Object.assign({}, ctx.state || {}, model || {})这个小技巧是为了扩展。
首先,
model || {}
确保了即使传入
undefined
,model也会变为默认值
{}
。
Object.assign()
会把除第一个参数外的其他参数的所有属性复制到第一个参数中。第二个参数是
ctx.state || {}
,这个目的是为了能把一些公共的变量放入
ctx.state
并传给View。
例如,某个middleware负责检查用户权限,它可以把当前用户放入
ctx.state
中:
app.use(async (ctx, next) => {
var user = tryGetUserFromCookie(ctx.request);
if (user) {
ctx.state.user = user;
await next();
} else {
ctx.response.status = 403;
这样就没有必要在每个Controller的async函数中都把user变量放入model中。
访问数据库
程序运行的时候,数据都是在内存中的。当程序终止的时候,通常都需要将数据保存到磁盘上,无论是保存到本地磁盘,还是通过网络保存到服务器上,最终都会将数据写入磁盘文件。
而如何定义数据的存储格式就是一个大问题。如果我们自己来定义存储格式,比如保存一个班级所有学生的成绩单:
名字成绩Michael99Bob85Bart59Lisa87
你可以用一个文本文件保存,一行保存一个学生,用
,
隔开:
Michael,99
Bob,85
Bart,59
Lisa,87你还可以用JSON格式保存,也是文本文件:
[
{"name":"Michael","score":99},
{"name":"Bob","score":85},
{"name":"Bart","score":59},
{"name":"Lisa","score":87}
]你还可以定义各种保存格式,但是问题来了:
存储和读取需要自己实现,JSON还是标准,自己定义的格式就各式各样了;
不能做快速查询,只有把数据全部读到内存中才能自己遍历,但有时候数据的大小远远超过了内存(比如蓝光电影,40GB的数据),根本无法全部读入内存。
为了便于程序保存和读取数据,而且,能直接通过条件快速查询到指定的数据,就出现了数据库(Database)这种专门用于集中存储和查询的软件。
数据库软件诞生的历史非常久远,早在1950年数据库就诞生了。经历了网状数据库,层次数据库,我们现在广泛使用的关系数据库是20世纪70年代基于关系模型的基础上诞生的。
关系模型有一套复杂的数学理论,但是从概念上是十分容易理解的。举个学校的例子:
假设某个XX省YY市ZZ县第一实验小学有3个年级,要表示出这3个年级,可以在Excel中用一个表格画出来:

每个年级又有若干个班级,要把所有班级表示出来,可以在Excel中再画一个表格:
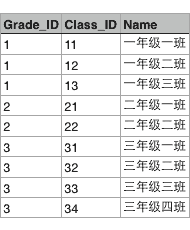
这两个表格有个映射关系,就是根据Grade_ID可以在班级表中查找到对应的所有班级:
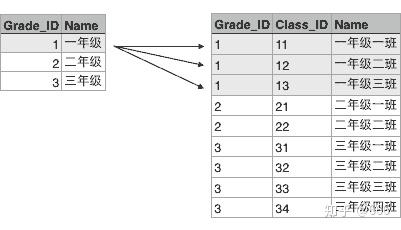
也就是Grade表的每一行对应Class表的多行,在关系数据库中,这种基于表(Table)的一对多的关系就是关系数据库的基础。
根据某个年级的ID就可以查找所有班级的行,这种查询语句在关系数据库中称为SQL语句,可以写成:
SELECT * FROM classes WHERE grade_id = '1';结果也是一个表:
---------+----------+----------
grade_id | class_id | name
---------+----------+----------
1 | 11 | 一年级一班
---------+----------+----------
1 | 12 | 一年级二班
---------+----------+----------
1 | 13 | 一年级三班
---------+----------+----------类似的,Class表的一行记录又可以关联到Student表的多行记录:
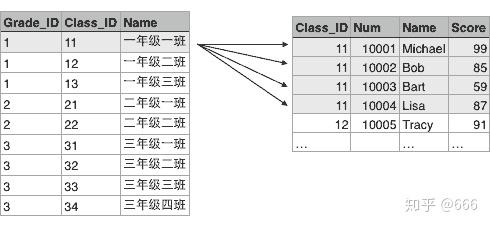
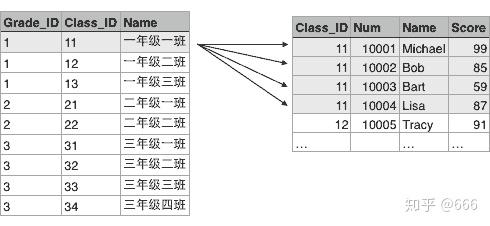
由于本教程不涉及到关系数据库的详细内容,如果你想从零学习关系数据库和基本的SQL语句,请自行搜索相关课程。
NoSQL
你也许还听说过NoSQL数据库,很多NoSQL宣传其速度和规模远远超过关系数据库,所以很多同学觉得有了NoSQL是否就不需要SQL了呢?千万不要被他们忽悠了,连SQL都不明白怎么可能搞明白NoSQL呢?
数据库类别
既然我们要使用关系数据库,就必须选择一个关系数据库。目前广泛使用的关系数据库也就这么几种:
付费的商用数据库:
- Oracle,典型的高富帅;
- SQL Server,微软自家产品,Windows定制专款;
- DB2,IBM的产品,听起来挺高端;
- Sybase,曾经跟微软是好基友,后来关系破裂,现在家境惨淡。
这些数据库都是不开源而且付费的,最大的好处是花了钱出了问题可以找厂家解决,不过在Web的世界里,常常需要部署成千上万的数据库服务器,当然不能把大把大把的银子扔给厂家,所以,无论是Google、Facebook,还是国内的BAT,无一例外都选择了免费的开源数据库:
- MySQL,大家都在用,一般错不了;
- PostgreSQL,学术气息有点重,其实挺不错,但知名度没有MySQL高;
- sqlite,嵌入式数据库,适合桌面和移动应用。
作为一个JavaScript全栈工程师,选择哪个免费数据库呢?当然是MySQL。因为MySQL普及率最高,出了错,可以很容易找到解决方法。而且,围绕MySQL有一大堆监控和运维的工具,安装和使用很方便。
安装MySQL
为了能继续后面的学习,你需要从MySQL官方网站下载并安装 MySQL Community Server 5.6 ,这个版本是免费的,其他高级版本是要收钱的(请放心,收钱的功能我们用不上)。MySQL是跨平台的,选择对应的平台下载安装文件,安装即可。
安装时,MySQL会提示输入
root
用户的口令,请务必记清楚。如果怕记不住,就把口令设置为
password
。
在Windows上,安装时请选择
UTF-8
编码,以便正确地处理中文。
在Mac或Linux上,需要编辑MySQL的配置文件,把数据库默认的编码全部改为UTF-8。MySQL的配置文件默认存放在
/etc/my.cnf
或者
/etc/mysql/my.cnf
:
[client]
default-character-set = utf8
[mysqld]
default-storage-engine = INNODB
character-set-server = utf8
collation-server = utf8_general_ci重启MySQL后,可以通过MySQL的客户端命令行检查编码:
$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor...
mysql> show variables like '%char%';
+--------------------------+--------------------------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql-5.1.65-osx10.6-x86_64/share/charsets/ |
+--------------------------+--------------------------------------------------------+
8 rows in set (0.00 sec)
看到
utf8
字样就表示编码设置正确。
注
:如果MySQL的版本≥5.5.3,可以把编码设置为
utf8mb4
,
utf8mb4
和
utf8
完全兼容,但它支持最新的Unicode标准,可以显示emoji字符。
当我们安装好MySQL后,Node.js程序如何访问MySQL数据库呢?
访问MySQL数据库只有一种方法,就是通过网络发送SQL命令,然后,MySQL服务器执行后返回结果。
我们可以在命令行窗口输入
mysql -u root -p
,然后输入root口令后,就连接到了MySQL服务器。因为没有指定
--host
参数,所以我们连接到的是
localhost
,也就是本机的MySQL服务器。
在命令行窗口下,我们可以输入命令,操作MySQL服务器:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.05 sec)
输入
exit
退出MySQL命令行模式。
对于Node.js程序,访问MySQL也是通过网络发送SQL命令给MySQL服务器。这个访问MySQL服务器的软件包通常称为MySQL驱动程序。不同的编程语言需要实现自己的驱动,MySQL官方提供了Java、.Net、Python、Node.js、C++和C的驱动程序,官方的Node.js驱动目前仅支持5.7以上版本,而我们上面使用的命令行程序实际上用的就是C驱动。
目前使用最广泛的MySQL Node.js驱动程序是开源的
mysql
,可以直接使用npm安装。
ORM
如果直接使用
mysql
包提供的接口,我们编写的代码就比较底层,例如,查询代码:
connection.query('SELECT * FROM users WHERE id = ?', ['123'], function(err, rows) {
if (err) {
// error
} else {
for (let row in rows) {
processRow(row);
考虑到数据库表是一个二维表,包含多行多列,例如一个
pets
的表:
mysql> select * from pets;
+----+--------+------------+
| id | name | birth |
+----+--------+------------+
| 1 | Gaffey | 2007-07-07 |
| 2 | Odie | 2008-08-08 |
+----+--------+------------+
2 rows in set (0.00 sec)
每一行可以用一个JavaScript对象表示,例如第一行:
{
"id": 1,
"name": "Gaffey",
"birth": "2007-07-07"
}这就是传说中的ORM技术:Object-Relational Mapping,把关系数据库的表结构映射到对象上。是不是很简单?
但是由谁来做这个转换呢?所以ORM框架应运而生。
我们选择Node的ORM框架Sequelize来操作数据库。这样,我们读写的都是JavaScript对象,Sequelize帮我们把对象变成数据库中的行。
用Sequelize查询
pets
表,代码像这样:
Pet.findAll()
.then(function (pets) {
for (let pet in pets) {
console.log(`${pet.id}: ${pet.name}`);
}).catch(function (err) {
// error
因为Sequelize返回的对象是Promise,所以我们可以用
then()
和
catch()
分别异步响应成功和失败。
但是用
then()
和
catch()
仍然比较麻烦。有没有更简单的方法呢?
可以用ES7的await来调用任何一个Promise对象,这样我们写出来的代码就变成了:
var pets = await Pet.findAll();
真的就是这么简单!
await只有一个限制,就是必须在async函数中调用。上面的代码直接运行还差一点,我们可以改成:
(async () => {
var pets = await Pet.findAll();
})();
考虑到koa的处理函数都是async函数,所以我们实际上将来在koa的async函数中直接写await访问数据库就可以了!
这也是为什么我们选择Sequelize的原因:只要API返回Promise,就可以用await调用,写代码就非常简单!
实战
在使用Sequlize操作数据库之前,我们先在MySQL中创建一个表来测试。我们可以在
test
数据库中创建一个
pets
表。
test
数据库是MySQL安装后自动创建的用于测试的数据库。在MySQL命令行执行下列命令:
grant all privileges on test.* to 'www'@'%' identified by 'www';
use test;
create table pets (
id varchar(50) not null,
name varchar(100) not null,
gender bool not null,
birth varchar(10) not null,
createdAt bigint not null,
updatedAt bigint not null,
version bigint not null,
primary key (id)
) engine=innodb;
第一条
grant
命令是创建MySQL的用户名和口令,均为
www
,并赋予操作
test
数据库的所有权限。
第二条
use
命令把当前数据库切换为
test
。
第三条命令创建了
pets
表。
然后,我们根据前面的工程结构创建
hello-sequelize
工程,结构如下:
hello-sequelize/
+- .vscode/
| +- launch.json <-- VSCode 配置文件
+- init.txt <-- 初始化SQL命令
+- config.js <-- MySQL配置文件
+- app.js <-- 使用koa的js
+- package.json <-- 项目描述文件
+- node_modules/ <-- npm安装的所有依赖包然后,添加如下依赖包:
"sequelize": "3.24.1",
"mysql": "2.11.1"
注意
mysql
是驱动,我们不直接使用,但是
sequelize
会用。
用
npm install
安装。
config.js
实际上是一个简单的配置文件:
var config = {
database: 'test', // 使用哪个数据库
username: 'www', // 用户名
password: 'www', // 口令
host: 'localhost', // 主机名
port: 3306 // 端口号,MySQL默认3306
module.exports = config;
下面,我们就可以在
app.js
中操作数据库了。使用Sequelize操作MySQL需要先做两件准备工作:
第一步,创建一个sequelize对象实例:
const Sequelize = require('sequelize');
const config = require('./config');
var sequelize = new Sequelize(config.database, config.username, config.password, {
host: config.host,
dialect: 'mysql',
pool: {
max: 5,
min: 0,
idle: 30000
第二步,定义模型Pet,告诉Sequelize如何映射数据库表:
var Pet = sequelize.define('pet', {
id: {
type: Sequelize.STRING(50),
primaryKey: true
name: Sequelize.STRING(100),
gender: Sequelize.BOOLEAN,
birth: Sequelize.STRING(10),
createdAt: Sequelize.BIGINT,
updatedAt: Sequelize.BIGINT,
version: Sequelize.BIGINT
}, {
timestamps: false
用
sequelize.define()
定义Model时,传入名称
pet
,默认的表名就是
pets
。第二个参数指定列名和数据类型,如果是主键,需要更详细地指定。第三个参数是额外的配置,我们传入
{ timestamps: false }
是为了关闭Sequelize的自动添加timestamp的功能。所有的ORM框架都有一种很不好的风气,总是自作聪明地加上所谓“自动化”的功能,但是会让人感到完全摸不着头脑。
接下来,我们就可以往数据库中塞一些数据了。我们可以用Promise的方式写:
var now = Date.now();
Pet.create({
id: 'g-' + now,
name: 'Gaffey',
gender: false,
birth: '2007-07-07',
createdAt: now,
updatedAt: now,
version: 0
}).then(function (p) {
console.log('created.' + JSON.stringify(p));
}).catch(function (err) {
console.log('failed: ' + err);
也可以用await写:
(async () => {
var dog = await Pet.create({
id: 'd-' + now,
name: 'Odie',
gender: false,
birth: '2008-08-08',
createdAt: now,
updatedAt: now,
version: 0
console.log('created: ' + JSON.stringify(dog));
})();
显然await代码更胜一筹。
查询数据时,用await写法如下:
(async () => {
var pets = await Pet.findAll({
where: {
name: 'Gaffey'
console.log(`find ${pets.length} pets:`);
for (let p of pets) {
console.log(JSON.stringify(p));
})();
如果要更新数据,可以对查询到的实例调用
save()
方法:
(async () => {
var p = await queryFromSomewhere();
p.gender = true;
p.updatedAt = Date.now();
p.version ++;
await p.save();
})();
如果要删除数据,可以对查询到的实例调用
destroy()
方法:
(async () => {
var p = await queryFromSomewhere();
await p.destroy();
})();
运行代码,可以看到Sequelize打印出的每一个SQL语句,便于我们查看:
Executing (default): INSERT INTO `pets` (`id`,`name`,`gender`,`birth`,`createdAt`,`updatedAt`,`version`) VALUES ('g-1471961204219','Gaffey',false,'2007-07-07',1471961204219,1471961204219,0);Model
我们把通过
sequelize.define()
返回的
Pet
称为Model,它表示一个数据模型。
我们把通过
Pet.findAll()
返回的一个或一组对象称为Model实例,每个实例都可以直接通过
JSON.stringify
序列化为JSON字符串。但是它们和普通JSON对象相比,多了一些由Sequelize添加的方法,比如
save()
和
destroy()
。调用这些方法我们可以执行更新或者删除操作。
所以,使用Sequelize操作数据库的一般步骤就是:
首先,通过某个Model对象的
findAll()
方法获取实例;
如果要更新实例,先对实例属性赋新值,再调用
save()
方法;
如果要删除实例,直接调用
destroy()
方法。
注意
findAll()
方法可以接收
where
、
order
这些参数,这和将要生成的SQL语句是对应的。
文档
Sequelize的API可以参考 官方文档 。
直接使用Sequelize虽然可以,但是存在一些问题。
团队开发时,有人喜欢自己加timestamp:
var Pet = sequelize.define('pet', {
id: {
type: Sequelize.STRING(50),
primaryKey: true
name: Sequelize.STRING(100),
createdAt: Sequelize.BIGINT,
updatedAt: Sequelize.BIGINT
}, {
timestamps: false
有人又喜欢自增主键,并且自定义表名:
var Pet = sequelize.define('pet', {
id: {
type: Sequelize.INTEGER,
autoIncrement: true,
primaryKey: true
name: Sequelize.STRING(100)
}, {
tableName: 't_pet'
一个大型Web App通常都有几十个映射表,一个映射表就是一个Model。如果按照各自喜好,那业务代码就不好写。Model不统一,很多代码也无法复用。
所以我们需要一个统一的模型,强迫所有Model都遵守同一个规范,这样不但实现简单,而且容易统一风格。
Model
我们首先要定义的就是Model存放的文件夹必须在
models
内,并且以Model名字命名,例如:
Pet.js
,
User.js
等等。
其次,每个Model必须遵守一套规范:
-
统一主键,名称必须是
id,类型必须是STRING(50); - 主键可以自己指定,也可以由框架自动生成(如果为null或undefined);
-
所有字段默认为
NOT NULL,除非显式指定; -
统一timestamp机制,每个Model必须有
createdAt、updatedAt和version,分别记录创建时间、修改时间和版本号。其中,createdAt和updatedAt以BIGINT存储时间戳,最大的好处是无需处理时区,排序方便。version每次修改时自增。
所以,我们不要直接使用Sequelize的API,而是通过
db.js
间接地定义Model。例如,
User.js
应该定义如下:
const db = require('../db');
module.exports = db.defineModel('users', {
email: {
type: db.STRING(100),
unique: true
passwd: db.STRING(100),
name: db.STRING(100),
gender: db.BOOLEAN
});
这样,User就具有
email
、
passwd
、
name
和
gender
这4个业务字段。
id
、
createdAt
、
updatedAt
和
version
应该自动加上,而不是每个Model都去重复定义。
所以,
db.js
的作用就是统一Model的定义:
const Sequelize = require('sequelize');
console.log('init sequelize...');
var sequelize = new Sequelize('dbname', 'username', 'password', {
host: 'localhost',
dialect: 'mysql',
pool: {
max: 5,
min: 0,
idle: 10000
const ID_TYPE = Sequelize.STRING(50);
function defineModel(name, attributes) {
var attrs = {};
for (let key in attributes) {
let value = attributes[key];
if (typeof value === 'object' && value['type']) {
value.allowNull = value.allowNull || false;
attrs[key] = value;
} else {
attrs[key] = {
type: value,
allowNull: false
attrs.id = {
type: ID_TYPE,
primaryKey: true
attrs.createdAt = {
type: Sequelize.BIGINT,
allowNull: false
attrs.updatedAt = {
type: Sequelize.BIGINT,
allowNull: false
attrs.version = {
type: Sequelize.BIGINT,
allowNull: false
return sequelize.define(name, attrs, {
tableName: name,
timestamps: false,
hooks: {
beforeValidate: function (obj) {
let now = Date.now();
if (obj.isNewRecord) {
if (!obj.id) {
obj.id = generateId();
obj.createdAt = now;
obj.updatedAt = now;
obj.version = 0;
} else {
obj.updatedAt = Date.now();
obj.version++;
我们定义的
defineModel
就是为了强制实现上述规则。
Sequelize在创建、修改Entity时会调用我们指定的函数,这些函数通过
hooks
在定义Model时设定。我们在
beforeValidate
这个事件中根据是否是
isNewRecord
设置主键(如果主键为
null
或
undefined
)、设置时间戳和版本号。
这么一来,Model定义的时候就可以大大简化。
数据库配置
接下来,我们把简单的
config.js
拆成3个配置文件:
- config-default.js:存储默认的配置;
- config-override.js:存储特定的配置;
- config-test.js:存储用于测试的配置。
例如,默认的
config-default.js
可以配置如下:
var config = {
dialect: 'mysql',
database: 'nodejs',
username: 'www',
password: 'www',
host: 'localhost',
port: 3306
module.exports = config;
而
config-override.js
可应用实际配置:
var config = {
database: 'production',
username: 'www',
password: 'secret-password',
host: '192.168.1.199'
module.exports = config;
config-test.js
可应用测试环境的配置:
var config = {
database: 'test'
module.exports = config;
读取配置的时候,我们用
config.js
实现不同环境读取不同的配置文件:
const defaultConfig = './config-default.js';
// 可设定为绝对路径,如 /opt/product/config-override.js
const overrideConfig = './config-override.js';
const testConfig = './config-test.js';
const fs = require('fs');
var config = null;
if (process.env.NODE_ENV === 'test') {
console.log(`Load ${testConfig}...`);
config = require(testConfig);
} else {
console.log(`Load ${defaultConfig}...`);
config = require(defaultConfig);
try {
if (fs.statSync(overrideConfig).isFile()) {
console.log(`Load ${overrideConfig}...`);
config = Object.assign(config, require(overrideConfig));
} catch (err) {
console.log(`Cannot load ${overrideConfig}.`);
module.exports = config;
具体的规则是:
-
先读取
config-default.js; -
如果不是测试环境,就读取
config-override.js,如果文件不存在,就忽略。 -
如果是测试环境,就读取
config-test.js。
这样做的好处是,开发环境下,团队统一使用默认的配置,并且无需
config-override.js
。部署到服务器时,由运维团队配置好
config-override.js
,以覆盖
config-override.js
的默认设置。测试环境下,本地和CI服务器统一使用
config-test.js
,测试数据库可以反复清空,不会影响开发。
配置文件表面上写起来很容易,但是,既要保证开发效率,又要避免服务器配置文件泄漏,还要能方便地执行测试,就需要一开始搭建出好的结构,才能提升工程能力。
使用Model
要使用Model,就需要引入对应的Model文件,例如:
User.js
。一旦Model多了起来,如何引用也是一件麻烦事。
自动化永远比手工做效率高,而且更可靠。我们写一个
model.js
,自动扫描并导入所有Model:
const fs = require('fs');
const db = require('./db');
let files = fs.readdirSync(__dirname + '/models');
let js_files = files.filter((f)=>{
return f.endsWith('.js');
}, files);
module.exports = {};
for (let f of js_files) {
console.log(`import model from file ${f}...`);
let name = f.substring(0, f.length - 3);
module.exports[name] = require(__dirname + '/models/' + f);
module.exports.sync = () => {
db.sync();
};这样,需要用的时候,写起来就像这样:
const model = require('./model');
Pet = model.Pet,
User = model.User;
var pet = await Pet.create({ ... });
工程结构
最终,我们创建的工程
model-sequelize
结构如下:
model-sequelize/
+- .vscode/
| +- launch.json <-- VSCode 配置文件
+- models/ <-- 存放所有Model
| +- Pet.js <-- Pet
| +- User.js <-- User
+- config.js <-- 配置文件入口
+- config-default.js <-- 默认配置文件
+- config-test.js <-- 测试配置文件
+- db.js <-- 如何定义Model
+- model.js <-- 如何导入Model
+- init-db.js <-- 初始化数据库
+- app.js <-- 业务代码
+- package.json <-- 项目描述文件