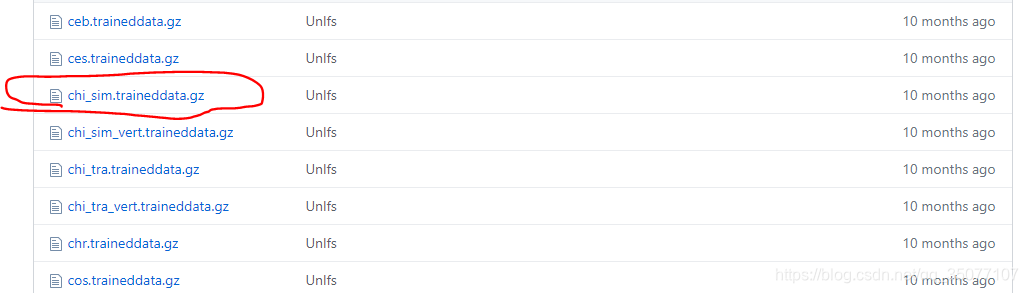
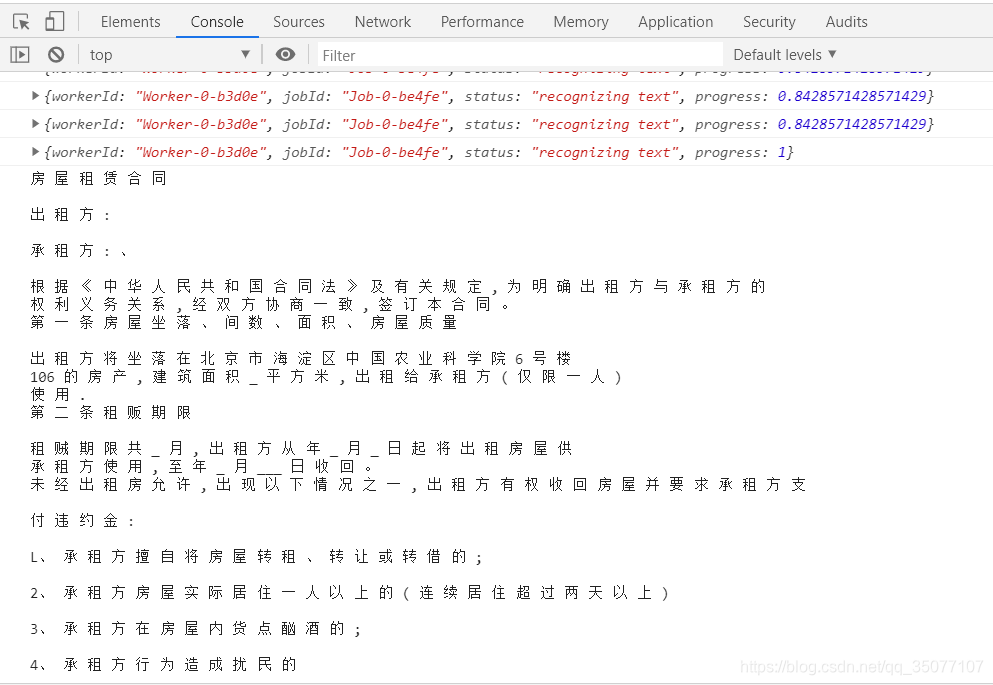
一开始是有一个在浏览器端实现离线文字识别的需求,查找资料后找到了 Tesseract.js这个开源库,但网上特别关于Tesseract.js这个js版本的学习文章介绍特别少,我参考了几篇文章,在实际使用的时候都会报错,始终无法识别。
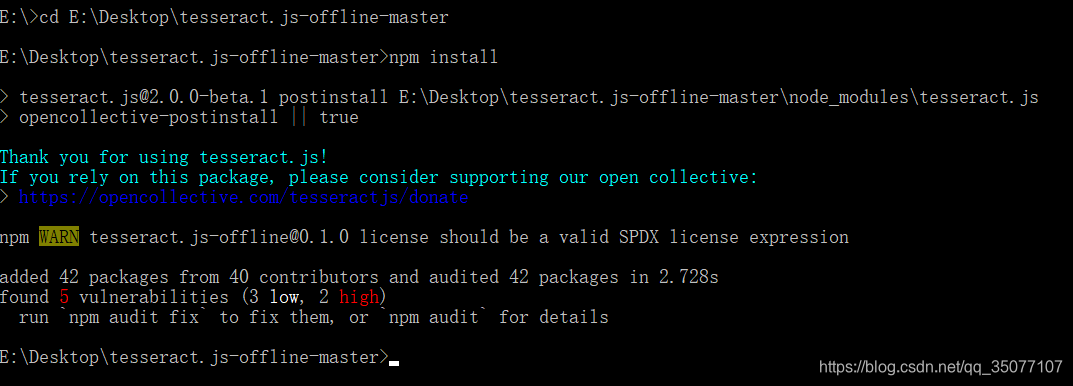
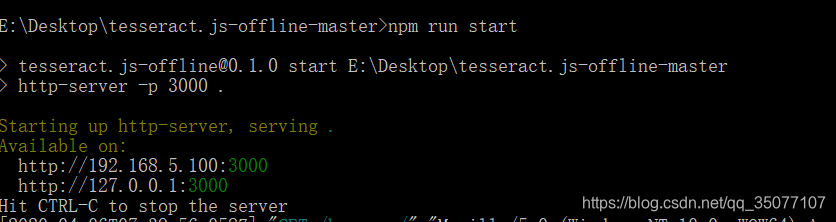
迫于无奈,只能自己看官网的文档资料,发现官网的例子基本上是都用到了node.js以及npm,给出的例子都是,先用npm安装相应的包,然后启动node.js服务器,最后通过浏览器访问相应的服务器地址,实现了识别。这让我一度以为,这个框架不能离线识别,必须连接服务器。
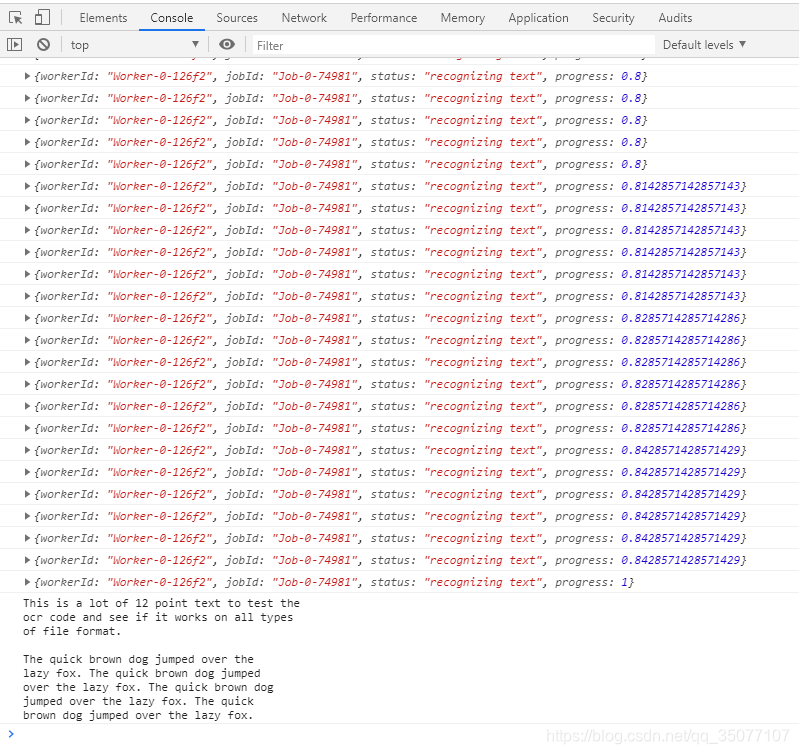
在去补了下node.js以及npm的入门知识后,经过一番操作,终于是实现了不开启服务器,只打开浏览器即可实现文字识别的功能。
在这个过程中,踩了一些坑,同时也学会了要看官方文档,官方文档是最权威的,也是最详细的,英语看不惯,别急,可以一步步慢慢来,这样有时候比起网上无厘头找教程反而要快。
Tesseract简介Tesseract是惠普布里斯托实验室在1985到1995年间开发的一一个开源的OCR引擎,曾经在1995 UNLV精确度测试中名列前茅。但1996年后基本停止了开发。2005年,惠普将其对外开源,2006 由Google对Tesseract进行改进、消除Bug、优化工作。官网项目地址:https://github.com/tesseract-ocr/tesseractT...
光学字符识别或光学字符阅读器 (OCR) 是将文本图像转换为机器编码文本的过程。例如,您可以拍摄书页的图片,然后通过 OCR 软件运行它以提取文本。
在这篇博文中,我们将使用Tesseract OCR 库。Tesseract 是用 C/C++ 编写的,最初是在 1985 年到 1994 年间由惠普公司开发的。惠普在 2005 年开源了该软件。从那时起,谷歌一直在开发和维护它。
2018 年 10 月发布的最新版本 4 包含一个新的 OCR 引擎,该引擎使用基于 LSTM 的神经网络系统,这应该会...
由于最近迷上了哔哩哔哩的直播,人穷没钱买瓜子,据说这个js能识别语音,和图片,刚好领取瓜子需要做一道数学题,又于是激动准备着手自己搞个插件自动领瓜子,哇咔咔咔~~~废话不说,表示尊重,
上git:https://github.com/naptha/tesseract.js
还有:http://tesseract.projectnaptha.com/
一、安装:1.标签式:用下面这个cdn地址或者在g
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta ht...
tesseract.js:支持多种语言的文字识别的 JS 库,能够方便、准确的把图片中的文字解析提取出来(就能复制了)。基于 Tesseract OCR 引擎实现的 JS 版本,方便前端实现文字识别功能和在浏览器中直接使用。
二、使用示例
1、图片识别
Tesseract.js 一个几乎能识别出图片中所有语言的JS库。Tesseract.js使用脚本标签,webpack / browserify和节点,安装之后,进行如下操作:Tesseract.recognize(myImage)
.progress(function (p) { console.log('progress', p) })
.then(function (result) { console.log('result', result) })查看文档以了解API的完整处理。
标签:Tesseract
在做条形码识别的时候,有可能碰到条形码因为被破坏,无法识别的情况。通常1D条形码的下面都印着对应的数字。这个时候还可以借助下OCR。虽然OCR的成功率可能不高,但是多一种识别方法也是好的。这里分享下如何用Tesseract.js来识别一张1D条形码。
如何使用Tesseract.js
使用npm的命令安装Tesseract.js:
npm install tesseract.js
获取示例代码:
https://github.com/naptha/tesseract.js/tree/master/examples
简单的运行下这些示例代码会发现第一次运行速度很慢,原因是需要下载语言包。要加快
图片转音频图片转文字 Tesseract.js```Tesseract.js```地址
图片转文字 Tesseract.js
Tesseract.js是流行的Tesseract OCR引擎的纯Javascript端口。
这个库支持100多种语言,自动文本定位和脚本检测,一个简单的界面,用于阅读段落、单词和字符边界框。Tesseract.js既可以在浏览器中运行,也可以在带有NodeJS的服务器上运行。
Tesseract.js地址
Tesseract.js官网
Tesseract.js Github地
版本2现在可用,并且在master分支中正在开发中,请阅读有关v2的故事: 检查分支的版本1
Tesseract.js是一个JavaScript库,可从图像中获取单词。 ()
视频实时识别
Tesseract.js包装了 引擎的。 它的工作原理在使用浏览器或纯脚本标记与与服务器上的。 ,使用起来很简单:
import Tesseract from 'tesseract.js' ;
Tesseract . recognize (
'https://tesseract.projectnaptha.com/img/eng_bw.png' ,
'eng' ,
{ logger : m => console . log ( m ) }
) . then ( ( { data : { text } } ) => {
console . log ( text ) ;
import { createWorker } from 'tesseract.js' ;
const worker = createWorker ( {
logger : m
Tesseract.js是一个基于JavaScript的OCR引擎,可以将印刷体字符转换为文本。在使用Tesseract.js之前,需要先安装它并配置相关参数。
第一步是安装Tesseract.js。可以使用NPM包管理器来安装它,并在应用程序中引入它。安装完成后,可以在代码中使用它的识别功能。
第二步是设置识别的参数。可以设置多种参数,例如识别语言、输出样式、解析格式等。设置参数可以提高识别的准确率和速度。
第三步是加载识别图像。使用Tesseract.js需要提供一张图像,它将会读取并将其转换为文本。图像可以是本地文件、网络URL或者HTML元素。
第四步是使用Tesseract.js进行识别。识别过程中,Tesseract.js将会使用之前设置的参数和加载的图像,将图像中的文字转换为文本。识别完成后,将会返回识别结果。
第五步是处理识别结果。可以将识别结果用于各种应用场景,例如文本分析、语言翻译等。在处理识别结果之前,需要先将其转换为适合应用场景的格式。
Tesseract.js是一个非常方便的工具,可以在JavaScript环境下进行OCR识别。通过设置参数和处理识别结果,可以实现更加精确和高效的OCR识别。