


10676 怎样暴力读取二进制数据文件

.
最近几天,有不止一个人问了我一个相同的问题:有人发给他们一些数据,但数据是用二进制格式存储的,用记事本打开全是乱码(如题图),怎么办?
这个问题的答案当然是「解铃还需系铃人」,提供数据的一方,同时也有责任提供数据文件格式的说明,甚至提供读写这种文件格式的代码,这样接收方才能方便地使用这些数据。不过,现实并不总是这么理想。有时候我们联系不上数据的提供方,或者对方太忙、太懒……总之,我们手上就只有一个二进制数据文件。怎么来读取它呢?
这篇文章就来告诉你,二进制数据文件的格式,也是有套路的。凭借你对数据内容的先验知识,加上对文件内容的观察,有时我们也能从中提取出所需的数据。当然,本文的方法并非万能,比如碰上压缩过的二进制文件就无能为力了。
本文首先介绍一些准备知识,包括十六进制编辑器、二进制文件的一般结构、整数与浮点数在计算机中的表示、大端格式与小端格式,以及如何用 Matlab、Python 两种语言读取二进制文件中的数据。之后,我会展示三个破解二进制数据文件的实例,三个文件分别为 wav 格式的声音波形文件、htk 格式的 MFCC 语音特征文件、bmp 格式的图片文件。其中第二种格式只有做语音识别的研究者才会遇到,一般人不了解也没关系。
一、准备知识
1.1 十六进制编辑器
要打开一个文件,一般人都会直接双击,让电脑根据扩展名,用默认程序打开。例如,txt 文件就会用记事本打开,bmp 文件就会用画图(或其它看图软件)打开,等等。如果用错了程序,要么就打不开,要么打开就会是乱码。而一些带有非通用扩展名的文件,由于没有默认程序,一般人就打不开了。
但是有一种程序,叫「十六进制编辑器」(hex editor),它可以打开任意类型的文件。它所做的事情,是把文件里的每个字节,用十六进制形式和字符形式显示出来。例如,知乎首页的源代码(htm 格式)用十六进制编辑器打开后是这个样子:
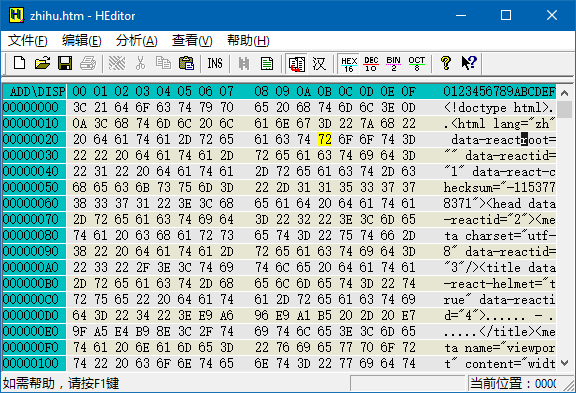
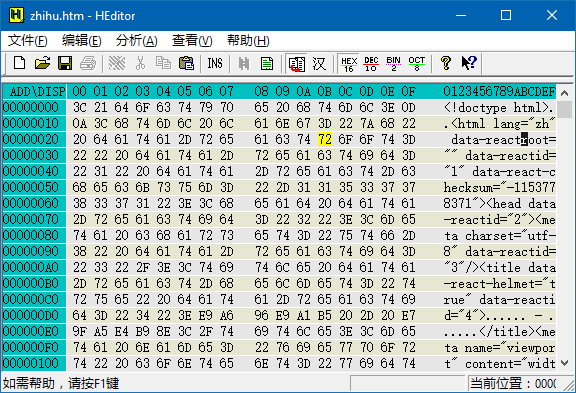
窗口的主体部分是用十六进制逐字节显示的文件内容。窗口最左侧的数字跟最上方的数字相加,表示的是每个字节在文件中的地址(address,也叫「偏移量」offset),例如黄色光标所在的地址是 0x2B(前缀 0x 表示十六进制,下同)。窗口的右侧是用字符形式显示的文件内容。htm 文件的内容是网页源代码,所以还可以读;如果是二进制文件,这里就是乱码,一般是不可读的。
十六进制编辑器软件有许多,上图展示的是 2001 年的 HEditor,现在网上应该很难找到了。据我观察,人气比较高的一款十六进制编辑器是 UltraEdit ,大家不妨一试。
1.2 二进制文件的一般结构
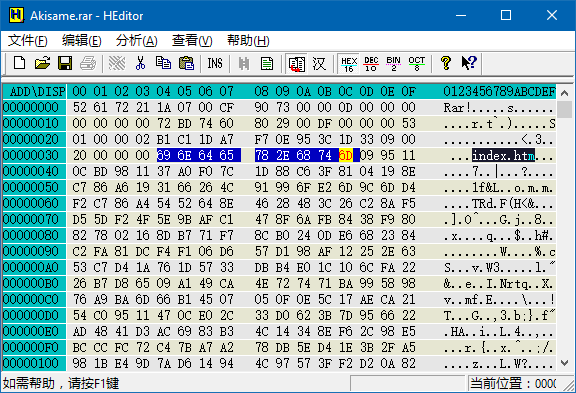
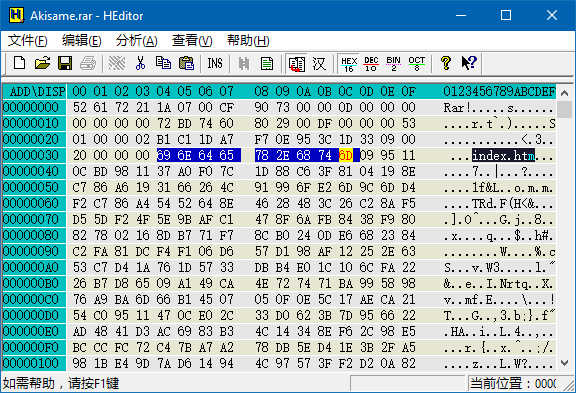
二进制文件一般由 文件头 和 数据区 组成。文件头描述了文件格式、大小等信息,数据区里存的就是数据啦。在「暴力读取」的场景下,文件头的格式是未知的,我们也不关心,我们只想从数据区里把数据读出来。那么怎么分辨数据区呢?一般来说,如果数据区是未经压缩的,那么里面的内容比较整齐,很容易看出来。比如下面是一个 wav 文件的内容,很容易看出从黄色光标处开始,下面有一串一串的竖直方向的 FF 和 00,那么从这儿开始就是数据区了。
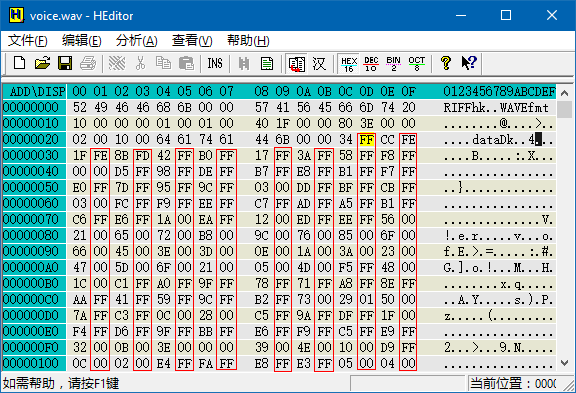
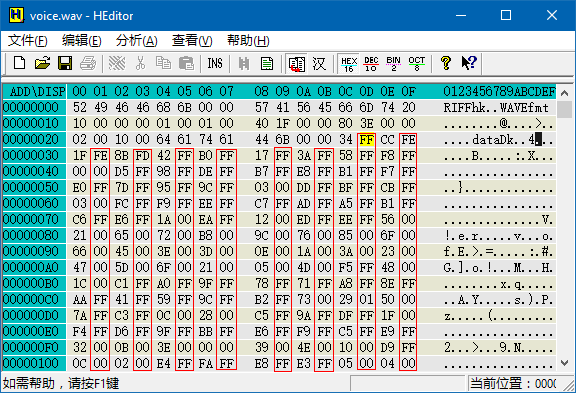
而下面是一个 rar 压缩包的内容,压缩包的内容当然是压缩过的,所以就显得杂乱无章。除了第 4 行能看出一个文件名以外,其它的部分就真是天书了。碰到压缩过的数据文件,就趁早放弃吧。
1.3 整数与浮点数在计算机中的表示
既然要读取数据,就得知道数据在计算机中是怎么表示的,在文件中是怎么存储的。常见的数据有两种类型:整数和浮点数。
1.3.1 整数在计算机中的表示
一个整数可能占 1 个、2 个或 4 个字节,即 8 个、16 个或 32 个二进制位。整数还分无符号数和有符号数。无符号数的所有二进制位都用于表示数值,于是 n 位无符号数的范围就是 0 到 2^n-1 ,例如 8 位无符号数的范围是 0 ~ 255。有符号数则把最高位用作符号位,0 表示正数(或 0),1 表示负数。剩下的 n-1 位用于表示数值,正数直接表示,而负数则用「补码」表示 —— 负数 -a 的这 n-1 位的值是 2^{n-1} - a 。因此,n 位有符号数的范围是 -2^{n-1} 到 2^{n-1} - 1 ,例如 8 位有符号数的范围是 -128 ~ 127。
举几个例子。正数 233 的二进制形式是 11101001,它用不同长度的无符号数和有符号数的表示如下图,红色的 0 表示符号位。注意图中没有 8 位有符号数,因为 233 超出了 8 位有符号数的范围。
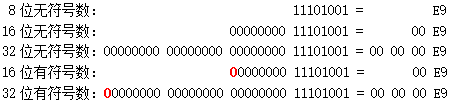
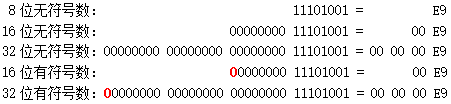
再如,负数 -23 用不同长度的有符号数的表示如下图,红色的 1 表示符号位。-23 用 8 位有符号数表示的形式跟 233 用 8 位无符号数表示的形式是一样的,请读者自行验证。
上面的内容在任意一本计算机入门教材中都会有,相信很多人已经听得耳朵起茧子了。我为什么还要重复一遍呢?我想指出的是: 如果数据的范围远小于 16 位或 32 位整数所能表示的范围,那么用十六进制编辑器打开后,你就会发现一串一串的 00 或 FF,这就是整型数据区的标志。 在上一节我们已经见过了一个例子。
1.3.2 浮点数在计算机中的表示
浮点数在计算机中是用二进制科学记数法表示的。举个例子:2.75 这个数,用十进制科学记数法表示为 2.75 \times 10^0 ,用二进制科学记数法表示则是 1.011 \times 2^1 。计算机中存储的,是 1.011 这个「尾数」,和 1 这个「指数」。另外,浮点数都是有符号的,所以还要有一个符号位。
浮点数分两种精度:单精度占 4 个字节(32 个二进制位),双精度占 8 个字节(64 个二进制位)。单精度数的结构为:1 个符号位 + 8 位指数 + 23 位尾数;双精度数的结构为:1 个符号位 + 11 位指数 + 52 位尾数。
仍以 2.75 为例。它用单精度和双精度浮点数分别表示如下:

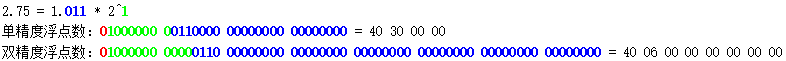
依次来看每个部分:
- 红色的符号位都是 0,代表正数。
- 然后看蓝色的尾数部分,可以发现只存了小数点后的 011,前面的 1 并没有储存。这是因为二进制科学记数法中,尾数的整数部分必定是 1,所以不必存储。
- 最后看绿色的指数部分。两种浮点表示法中的指数部分其实是一个无符号整数,它们是把实际的指数进行「偏置」后的结果;单精度浮点数中储存的是实际的指数加 127,双精度浮点数中储存的是实际的指数加 1023。例如在上面的例子中,单精度浮点数中的指数部分是 1 + 127 = 128,双精度浮点数中的指数部分是 1 + 1023 = 1024。之所以要进行偏置,是因为指数可能是负数。那么为什么不直接用有符号数来表示呢?原来,采用带偏置的无符号整数表示,在比较两个浮点数大小时更方便。不过这一点与本文无关,可以不必深究。
再举一个例子:-1/3 的二进制是 -0.010101... 循环,写成科学记数法是 -1.\dot{0}\dot{1} \times 2^{-2} 。它用单精度和双精度浮点数分别表示如下:


现在符号位变成了 1,指数部分分别是 -2 + 127 = 125 和 -2 + 1023 = 1021。
知道这些有什么用呢?我们发现, 当数据的数量级接近 1(即指数的绝对值不大)时,浮点数的第一个字节的前一半会是 3、4(正数)或 B、C(负数)。这就是浮点型数据区的标志。 在下文的第二个实例中,我们就会用到这一点。另外,当数据是分母不大的有理数时,对应于尾数部分的几个字节会是重复的。不过实际数据不一定是分母不大的有理数,所以这一点的用处有限。
1.3.3 大端格式与小端格式
除了 8 位整型以外,所有的数值在计算机中的表示都占多个字节。这些字节在文件中的存储顺序,就有两种不同的选择。如果就按上文中书写的顺序存储,即先存高位,比如把整数 233 存储为四个字节 00 00 00 E9,那么这种格式就叫「大端格式」(big-endian)。如果反过来,先存低位,比如把整数 233 存储为 E9 00 00 00,那么这种格式就叫「小端格式」(little-endian)。二进制数据文件不一定采用哪一种格式,需要观察。
豆知识: 「大端」和「小端」这两个词来自小说《格列佛游记》。书中的小人国里有两个敌对的派别,敌对的原因就是在剥煮鸡蛋壳的时候,一拨人从大头剥,另一拨人从小头剥。
1.4 编程读取二进制数据
1.4.1 Matlab 语言
Matlab 语言中有一个 fread 函数,可以从文件中读取二进制数据。它带有五个参数,例如:
A = fread(fid, [5 10], 'int32', 0, 'b');各个参数的含义如下:
- 第一个参数是文件句柄,可由 fopen 函数获得。
- 第二个参数指明要读取的数据数量,以及结果的形状。它可以是一个整数或一个二维向量。当它是一个整数时,结果是一个列向量,可以用 inf 表示读到文件末尾。当它是二维向量时,结果是一个二维矩阵,数据逐列填充。
- 第三个参数指明数据的类型,允许的值包括 int8, uint8, int16, uint16, int32, uint32, float, double。前缀 u 表示无符号,其它值的意义不言自明。读入后的数据在内存中都会被转换成 double 格式,如果要保留源格式,则要写成 'int32=>int32' 这样,箭头后面表示读入后存成的格式。
- 第四个参数指明每读一个数据后跳过几个字节,在此取为 0。
- 第五个参数用字母 b 或 l 指明大端还是小端格式。当大小端格式无关紧要(即数据为 8 位整数)时,可以省略第四、五个参数。
上面的命令,将从 fid 代表的文件中,按大端格式读取 50 个 32 位有符号整数,并存入 5 * 10 的二维矩阵 A。
Matlab 中还有一个函数 fseek ,可以在 fread 之前使用,指定开始读取的位置。例如,命令 fseek(fid, 44, -1) 可以跳过文件开头的 44 个字节。fseek 函数的第二个参数指明下一次读取的位置是以什么为基准计算的:-1 表示相对于文件开头,0 表示相对于当前位置,1 表示相对于文件结尾。
1.4.2 Python 语言
用 Python 处理数据,常常会用到 numpy 库。numpy 库中有一个 numpy.fromfile 函数,可以从二进制文件中读取数据。它的用法如下:
A = numpy.fromfile(file, dtype, count)各个参数的含义为:
- 第一个参数为文件对象,也可以是字符串形式的文件名;
- 第二个参数为数据格式,用字符串表示,例如 '>i4'。第一个字符用大于号或小于号表示大端或小端格式;第二个字符为 i 表示有符号整数,为 u 表示无符号整数,为 f 表示浮点数;第三个字符表示每个数据所占的字节数。
- 第三个参数表示读取多少个数,可以用 -1 表示读到文件尾。
读入的数据储存在一维 numpy 数组 A 中,你可以再把它 reshape 成所需的形状,例如 A.reshape((5, 10))。注意 reshape 时数据是逐行填充的,这与 Matlab 不同。
Python 的文件对象同样有 seek 功能,例如 f.seek(44, 0) 表示移动到距文件开头 44 字节处。这里,第二个参数的含义与 Matlab 语言不同,在 Python 语言中,用 0、1、2 分别表示文件开头、当前位置、文件末尾。
二、实战演练
在这一部分中,我们将用暴力方法从三个二进制数据文件中读取数据。第一个文件是 2008 年夏季清华电子系 Matlab 课上用过的一段 wav 格式的语音波形,内容是男声「电灯比油灯进步多了」。第二个文件是用 openSMILE 工具包提取的上述语音的 MFCC 特征(13 维 + 两阶差分,共 39 维)。第三个文件是下面这张比丢图,bmp 格式:

三个文件可以在这里下载:
- wav 格式的声音波形文件: http://www. cs.cmu.edu/~yunwang/dem o/read-binary-files/voice.wav
- htk 格式的 MFCC 语音特征文件: http://www. cs.cmu.edu/~yunwang/dem o/read-binary-files/voice.htk
- bmp 格式的图片文件: http://www. cs.cmu.edu/~yunwang/dem o/read-binary-files/biu.bmp
为节省篇幅,读取时的试错过程我就只用 Matlab 语言演示,因为我更熟悉 Matlab 语言的绘图操作。最终的代码会有 Matlab 和 Python 两个版本。
当然,Matlab 和 Python 语言中都有读取 wav 波形和 bmp 图片的库,事实上并不需要使用下面要讲的「暴力」读取方式。但重要的是举一反三,本文展示的技术,可以用于许多未知格式的二进制数据文件。
2.1 暴力读取 wav 文件
首先用十六进制编辑器打开文件:
可以看到从光标处开始,有一串串竖直的 FF 或 00,这说明数据类型为有符号整型,这些 FF 或 00 是高位。由于每 2 列就会出现一串 FF 或 00,所以每个整数占 2 个字节,即 16 位有符号整型。这些数据是大端格式还是小端格式呢?我们把滚动条拉到文件末尾:
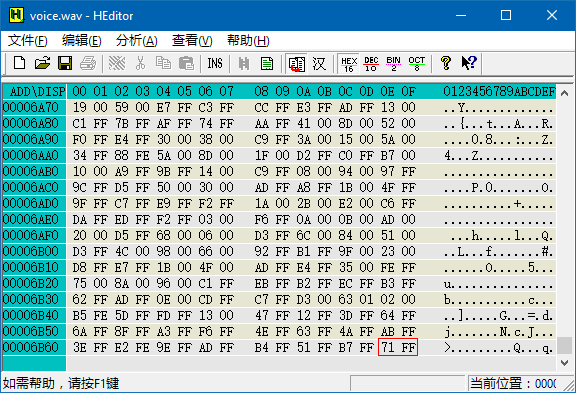
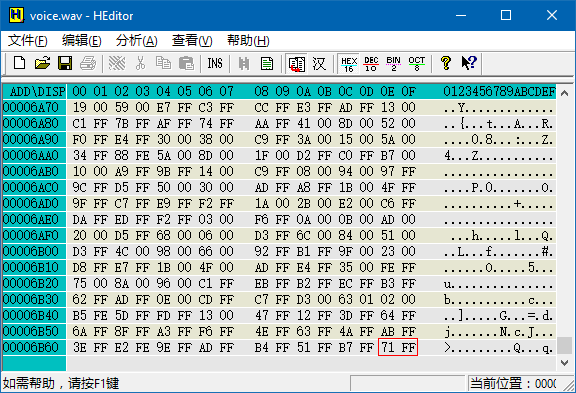
可以看到最后一个字节是 FF,所以最后的 71 FF 代表一个整数,数据为小端格式。此时再回到文件开头,第一个整数应该是 34 FF,所以文件头一共有 44 个字节。
有了这些信息,就可以用以下的 Matlab 代码读取波形了:
fid = fopen('voice.wav', 'rb'); % 注意:在Windows下打开二进制文件必须指明b模式
fseek(fid, 44, -1); % 跳过 44 字节的文件头
A = fread(fid, inf, 'int16', 0, 'l'); % 按小端格式读取 16 位有符号整数,直到文件末尾
fclose(fid);把读进来的波形画出来看一下:
plot(A);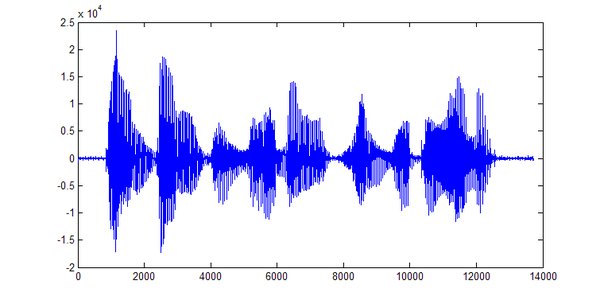
看起来是对的。采样率并不知道,先用 8000 Hz 试着播放一下:
soundsc(A, 8000);听起来声音完全正常,破解成功!
(事实上,我们并未排除声音是 4000 Hz 采样、双声道的可能。不过 4000 Hz 这个采样率并不常见,就先不管了)
用 Python 语言读取波形的代码如下:
import numpy
with open('voice.wav', 'rb') as f: # 注意:在Windows下打开二进制文件必须指明b模式
f.seek(44, 0) # 跳过 44 字节的文件头
A = numpy.fromfile(f, '<i2', -1) # 按小端格式读取 16 位有符号整数,直到文件末尾除了 wav 格式以外,有一些语音识别数据库中的语音是以 NIST sph 格式存储的。sph 格式与 wav 格式相似,只不过文件头的长度是 1024 字节。而这个文件头是纯文本的,其中包含了采样率、声道数、每个样本的格式等信息,利用它们可以减少「猜测」的工作量。
2.2 暴力读取 htk 格式的 MFCC 特征文件
在本节中,你并不需要知道 MFCC 是什么东西,只需要知道文件中存的是一个 n * 39 或 39 * n 的矩阵就行了。
同样先用十六进制编辑器查看文件内容:
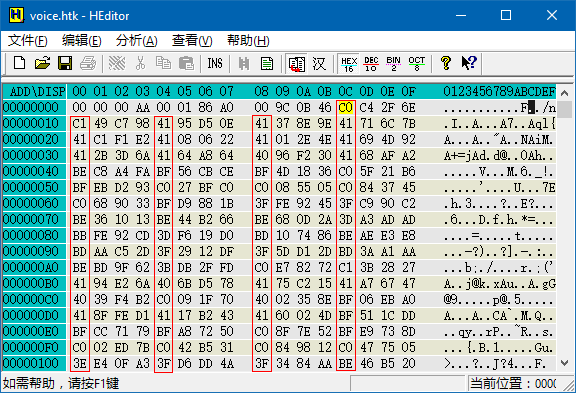
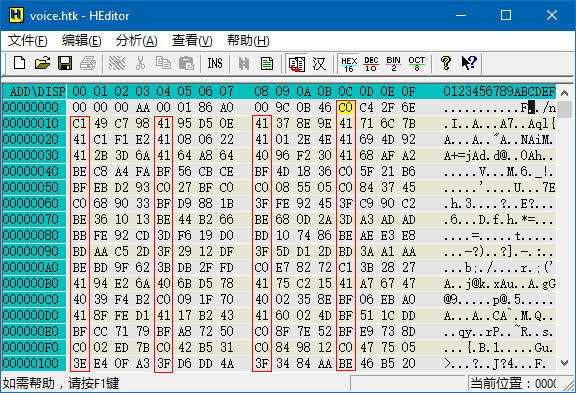
可以看到有 4 列都是以 3, 4, B, C 开头的,这是浮点数据区的特征。由于每 4 列出现一次这种特征,所以数据为单精度浮点型。这种特征开始的位置是 0x0C。拉到文件末尾可以看出,数据为大端格式。
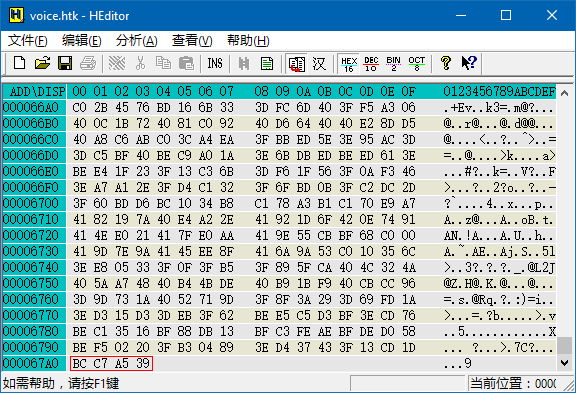
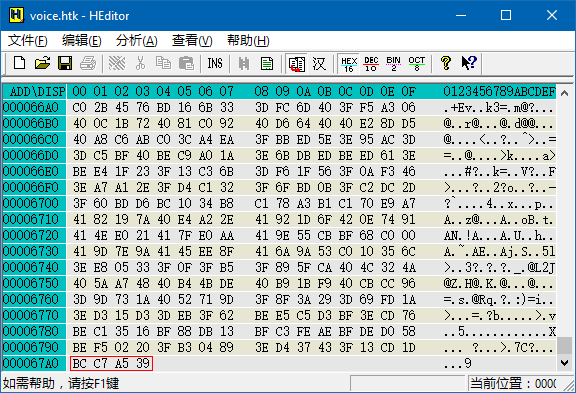
从上图还可以读出文件的总长度为 0x67A4。文件头的长度为 0x0C,所以数据区的总长为 0x6798,换算成十进制为 26,520。每个浮点数占 4 个字节,所以数据区共有 6,630 个浮点数,正好组成一个 170 * 39 或 39 * 170 的矩阵。
先按 170 * 39 读进来试一下:
fid = fopen('voice.htk', 'rb');
fseek(fid, 12, -1); % 跳过 12 字节的文件头
A = fread(fid, [170 39], 'float', 0, 'b'); % 按大端格式读入170*39的单精度浮点数矩阵
fclose(fid);画图:
imagesc(A);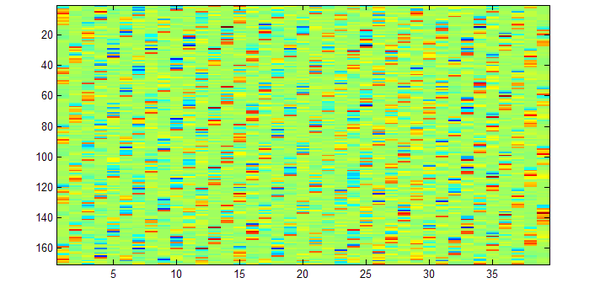
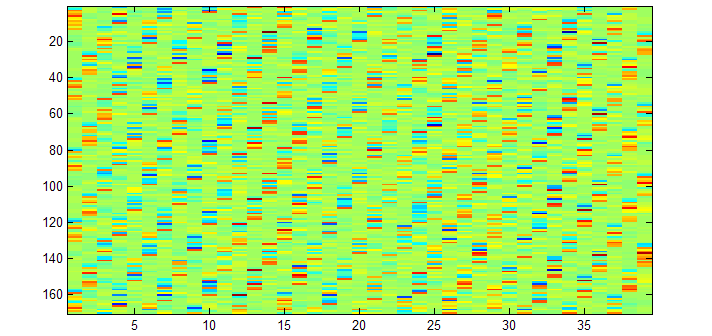
出现这种斜纹,一般就表示矩阵的行、列弄反了。反过来按 39 * 170 试一下:
fid = fopen('voice.htk', 'rb');
fseek(fid, 12, -1); % 跳过 12 字节的文件头
A = fread(fid, [39 170], 'float', 0, 'b'); % 按大端格式读入39*170的单精度浮点数矩阵
fclose(fid);画图:
imagesc(A);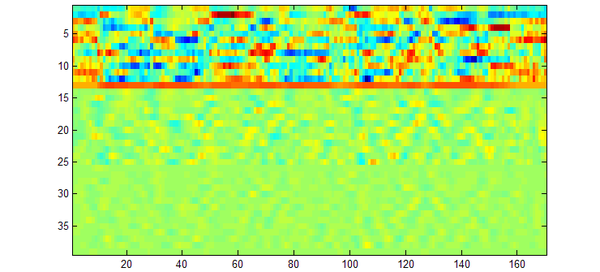
这次正常了!懂行的朋友应该能看出,横轴是时间轴,表示语音信号一共有 170 帧;矩阵的前 13 行是 MFCC 系数本身,中间 13 行是一阶差分,最后 13 行是二阶差分。
用 Python 语言读取 MFCC 特征的代码如下。注意 Matlab 中二维矩阵是逐列填充的,而 Python 语言中二维矩阵是逐行填充的,所以 reshape 时指定的矩阵形状应该是 170 * 39,得到的矩阵与 Matlab 中的矩阵互为转置关系。
import numpy
with open('voice.htk', 'rb') as f:
f.seek(12, 0) # 跳过 12 字节的文件头
A = numpy.fromfile(f, '>f4', -1).reshape((170, 39))
# 按大端格式读入单精度浮点数,直到文件末尾,
# 并存入 170 * 39 的矩阵2.3 暴力读取 bmp 图片
依然先用十六进制编辑器查看比丢图的内容:
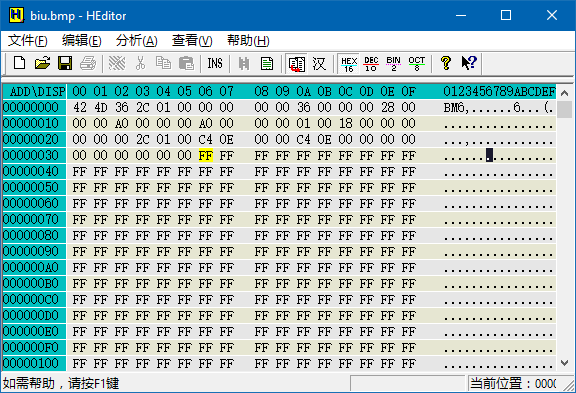
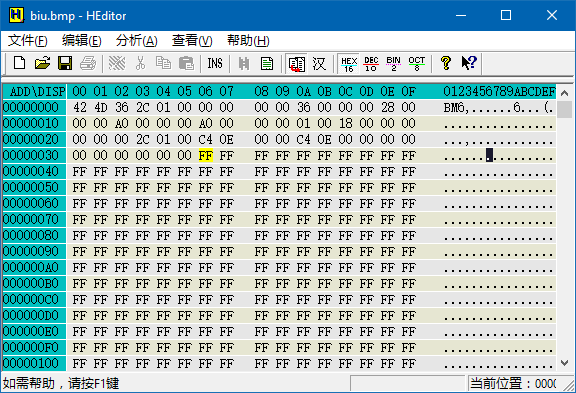
从地址 0x36 起,发现一大片的 FF。比丢图的背景为白色,其红、绿、蓝三个分量都应取最大值,所以推测 0x36 就是数据区的开头,数据类型为 8 位无符号整数,每 3 个字节表示一个像素,这 3 个字节分别表示红、绿、蓝分量。
把滚动条往下拉,可以发现在 FF 中穿插着一些 3 个字节一重复的区域,这更加印证了「每 3 个字节表示一个像素」的猜想。
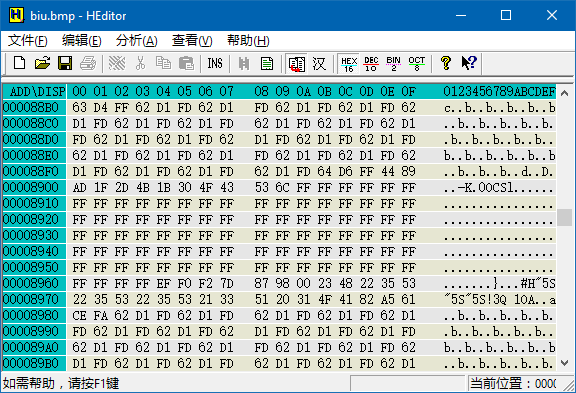
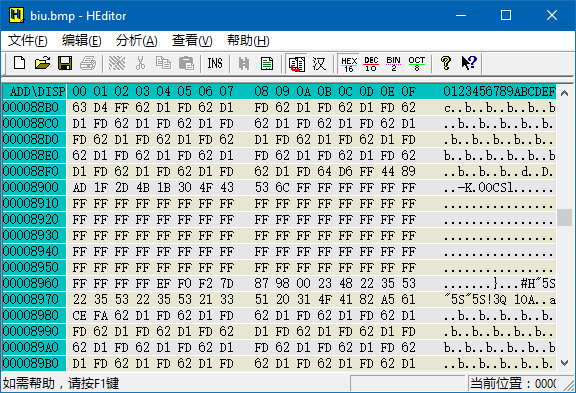
比丢图文件的总长度为 0x12C36(图略),减去文件头长度 0x36,数据区的长度就是 0x12C00 = 76,800 字节,这表示了 25,600 个像素。比丢图的大小是 160 * 160,正好吻合。
用 Matlab 读入比丢图的代码如下:
fid = fopen('biu.bmp', 'rb');
fseek(fid, 54, -1); % 跳过 54 字节的文件头
A = fread(fid, inf, 'uint8=>uint8'); % 把文件剩余内容当作 8 位无符号整数读取,
% 读取的结果也保存成 8 位无符号整型
A = reshape(A, [160 160 3]); % 把读入的数据转换成 160 * 160 的 RGB 图片
fclose(fid);画图看看吧!
imshow(A);
比丢!比丢你怎么了比丢!
出现这种色彩的混乱,一般是因为弄混了图片张量的三个轴。在 reshape(A, [160 160 3]) 这条命令中,Matlab 是按如下的顺序填充大小为 160 * 160 * 3 的张量的:先填满红色平面,再填满绿色平面,最后填满蓝色平面。而实际上,文件中的数据是按红、绿、蓝、红、绿、蓝……的顺序存储的。为了让 reshape 按照期望的顺序填充图片张量,需要先把 A reshape 成一个 3 * 160 * 160 的张量,再用 permute 函数把第一维挪到后面去:
A = reshape(A, [3 160 160]);
A = permute(A, [2 3 1]);
imshow(A);


上面的比丢图有两个问题:一是图片顺时针旋转了 90 度,二是比丢变成了浅蓝色。注意 Matlab 是 从左往右逐列 填充图片的,既然图片顺时针旋转了 90 度,那说明在 bmp 文件中,数据本来的顺序是 从下往上逐行 填充的。这要求我们把图片的水平、竖直两个维度也调换一下,并且再把上下方向颠倒。至于颜色问题,比丢本来的橙黄色是红色加一点绿色组成的,而现在的浅蓝色是蓝色加一点绿色组成的。这说明 bmp 文件中每个像素点三个颜色分量的顺序是 蓝、绿、红 ,而不是红、绿、蓝,图片的第 3 个维度的方向也需要颠倒。
包含了上述所有变换的完整读取代码如下:
fid = fopen('biu.bmp', 'rb');
fseek(fid, 54, -1); % 跳过 54 字节的文件头
A = fread(fid, inf, 'uint8=>uint8'); % 把文件剩余内容当作 8 位无符号整数读取,
% 读取的结果也保存成 8 位无符号整型
A = reshape(A, [3 160 160]); % 三个维度分别为色、列、行
A = permute(A, [3 2 1]); % 调整三个维度的顺序为行、列、色
A = A(end:-1:1, :, end:-1:1); % 把行、色两个维度的方向反转
fclose(fid);这回读入的比丢图就正常了。

读取并显示 bmp 图片的 Python 代码如下。由于 Python 在 reshape 时的填充顺序与 Matlab 不同,Python 并不需要调换张量的三个维度,显得更加简洁。
import numpy
with open('biu.bmp', 'rb') as f:
f.seek(54, 0) # 跳过 54 字节的文件头
A = numpy.fromfile(f, 'u1', -1) # 把文件剩余内容当作 8 位无符号整数读取