该论文提出,使用LSTM使得网络能够“记忆”一些画面。因为保留“记忆”可以在POMDP的时候提供帮助。
有一些游戏单靠一帧是没有办法获得全部信息的(如小球的运动方向)。
当在正常游戏 (MDP) 上训练, 然后在闪烁的游戏 (POMDPs) 上进行评估时, DRQN 下降比 DQN 更少。
在没有闪现的游戏中其实没有系统性的提升,只有在认为增加“意外”的时候才会有明显的提高。
(在我看来,这其实只是稍稍提高了一点点鲁棒性罢了。)
使用LSTM解决了传统DQN的两点局限性:
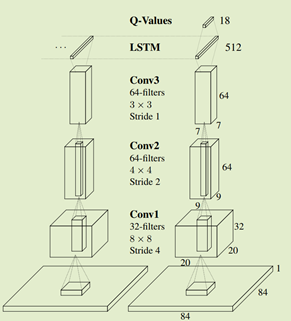
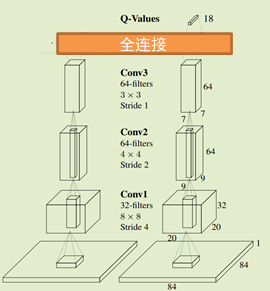
本文的网络结构和之前的DQN相似,仅仅把最后一层全连接层替换为LSTM。
本文还比较了两种LSTM参数更新方式
前者是从观察并记忆到的特征中随机选择,并在开始时进行更新,直至一幕结束,LSTM隐藏状态被一直保留并不断更新;后者则是在一幕的随机点开始进行更新并直至一次训练迭代结束,LSTM隐藏状态初始值在每次开始更新时被置零(不再保留)。
前者更善于保留信息,而后者更符合随机采样的原则。效果两者差不多。

dueling network 将状态价值评估和动作价值评估“分离”。
通过修改第一篇文章最后一层全连接层的输出,将之分为两个输出
-
当前状态的价值V
-
各个动作的价值向量A

将网络输出分为V和A,其中A中各个分量之和为0。使得对V、A的估计更加准确,更好地评价当前局面的状态价值和动作价值。

《Sutton》上没有收录这种方法。
Dueling Network的输入和输出与DQN完全一样,Dueling Network与DQN的功能也完全一样,两者唯一的区别就是神经网络的结构。
训练方式:e-greedy ,e is chosen to be 0:001. 使用和原来DQN一样的网络,只把最后一层全连接层一分为二,一部分输出V,一部分输出A。V值就是当前的Q值。
论文在实验中发现,动作选择越多,效果越好。
Dueling直译是决斗,我想知道为什么这个网络的命名者为它取了这个名字。

在抽取经验池中过往经验样本时,采取按优先级抽取的方法。传统随机抽取经验忽略了经验之间的重要程度。
思想很朴实。用二八定律解释的话,就是百分之二十的行为带来了百分之八十的收益。应该重点学习那百分之二十的行为。
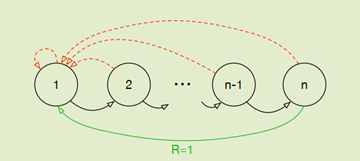
在上面这个例子中,如果一开始是随即策略,那么只有很少的时候能够到达节点n,也就是说buffer中几乎都是价值为0的经历。使用PER后,网络会更加乐意去学习那些能够带来收益的经历。在稀疏奖励强化中,这应该是非常重要的手段。(这让我想起了gyn库里的小游戏mountain car)
最基础的方法就是用TD-error来表示优先级。然后根据把归一化后的优先级当作被pick的概率。
并且使用PER算法更快收敛,效果更好。
文章中提出,优化后的PER方法总体耗时提高2%-4%。这几乎没有增加额外的计算负担。
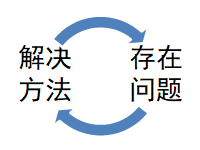
这篇论文一直在存在问题、解决方法的循环讨论。是值得借鉴的思想。
比如最初的直接将TD(0)误差作为权重时:
论文提出TD(0)作为权重的算法存在问题:
1、为了避免由于扫描整个经验池带来的昂贵代价,只会更新被重放的transition的TD-error值,这样会造成:第一次见到过的一个有很小的TD-error的transition存放到经验池后,在很长时间都不会被回放
2、TD-error对于噪声很敏感,容易将源于噪声的估计误差加入。
3、这个算法专注于经验的一小部分,TD-error减小慢,特别是在使用函数近似(Function approximation,有linear函数估计,例如线性回归,以权重作为参数;有non-linear函数估计,例如NN),高的TD-error由于重放频繁会使得丧失多样性造成过拟合。
论文提出解决方法:
1.第一种变体 proportional prioritization,用sumtree结构(更常用),与普通的二进制堆结构不同,每个节点是其子节点的和
2.第二种变体 rank-based prioritization ,基于二进制堆结构用优先队列直接存储各个transition
DQN还有很多方法不再展开了:

来看彩虹:

DQN集之前7种所有方法的大乘之作。
实验曲线非常好看:

当采用其中不冲突的方法后,训练以后的结果自然一骑绝尘。
并且团队还进行了消融实验:看看在彩虹中有没有哪种方法在滥竽充数:

欸嘿嘿,是DDQN(double-dqn)在滥竽充数(紫色线)。在去掉它之后曲线并没有什么下降。其实不难理解,因为有了Multi-step后其实几乎已经不会有过估计的问题了。DDQN主要解决的问题已经不存在了,所以去掉以后没有产生不良影响也是可以理解的。
Deepmind团队在2017年做的实验。总结应用了互相不冲突的各种DQN方法,是DQN的大杂烩。
七种方法,互不冲突。品一品,颇有七剑下天山的滋味。也断绝了后续很多所谓改进DQN的“水论文”行为。
DQN是一个很广阔的领域,很多科研爱好者都在这个领域奋斗。我也属于刚接触RL,水平有限,如有错漏烦请指点。
都看到这里了,就顺手点个赞吧~
DQN
论文
笔记
1. Abstract2. Background3. Technical利用CNN进行值函数拟合采用经验回放方法进行
强化学习
训练训练流程设置target network单独计算TD目标的error三级目录
1. Abstract
本文将深度
神经网络
应用于Reinforcement Learning(RL)提出一种全新的算法名为Deep Q-Network,引入两个关键技术:experience replay与target network,解决了以往
神经网络
难以应用在
强化学习
的几个问题,并使用卷
内容概要: 本文深入探讨了
强化学习
(Reinforcement Learning)以及深度
强化学习
(Deep Reinforcement Learning)的关键概念和应用。文章首先介绍了
强化学习
的基本概念,如目标、交互方式等,然后详解了马尔科夫决策过程(MDP)、值函数与策略等核心要素。随后,文章深入介绍了基于
深度学习
的
强化学习
算法——Deep Q-Networks(
DQN
)以及其运作原理。此外,文章提及了AlphaGo作为一个成功的
强化学习
应用案例,通过自我对弈学习来战胜围棋顶尖选手。最后,文章给出了一个实际的代码示例,展示了如何使用
DQN
解决OpenAI Gym中的CartPole问题。
适合人群: 适合对
强化学习
和
深度学习
感兴趣的学习者。
能学到什么: 阅读本文后,读者将能够深入了解
强化学习
的核心概念、马尔科夫决策过程、值函数、策略等。同时,对于已掌握机器学习和
深度学习
基础的读者,将能够深入理解Deep Q-Networks(
DQN
)算法及其实现细节。
本文是
论文
《Deep Reinforcement Learning with Knowledge Transfer for Online Rides Order Dispatching》的阅读
笔记
。
文章把订单分配问题建模成一个 MDP,并且提出了基于
DQN
的解决策略,为了增强的模型的适应性和效率,文章还提出了一种相关特征渐进迁移(Correlated Feature Progressive Transfer)的方法,并证明了先从源城市学习到分配策略,然后再将其迁移到目标城市或者同一个城市的
1. 《Reinforcement Learning: An Introduction》Richard S. Sutton and Andrew G.Bartohttp://incompleteideas.net/book/RLbook2020.pdf
Code (Python Implementation): GitHub - ShangtongZhang/reinforcement-learning-an-introduction: Python Implementation of Rein.
文章目录2020REINFORCED ACTIVE LEARNING FOR IMAGE SEGMENTATION
REINFORCED ACTIVE LEARNING FOR IMAGE SEGMENTATION
code: https://github.com/ArantxaCasanova/ralis
基于学习的语义分割方法有两个固有的挑战。首先,获取像素级标签是昂贵和耗时的。其次,真实的分割数据集是高度不平衡的:一些类别比其他类别要丰富得多,从而使性能偏向于最具代表性的类别。在本文中
# 绘制单条线
self.p1 = self.win.addPlot(title="单条曲线")
self.p1.addLegend(offset=(0, 0), size=(10, 20), labelTextColor='r') # 先add,在plot
self.p1.plot(x, y, name='2022年', pen=pen, symbol='o', symbolSize=15, symbolBrush='r')