

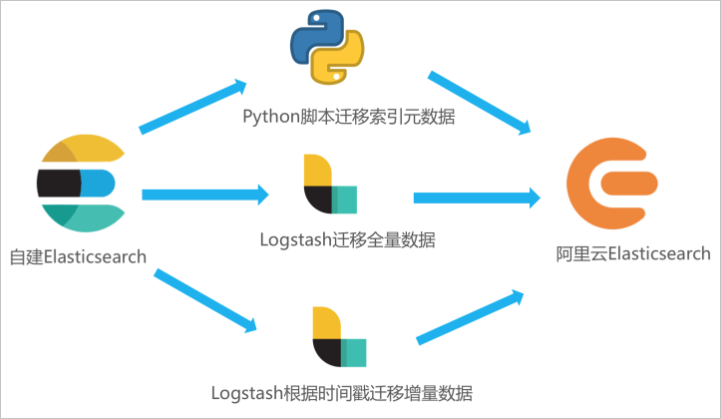
如果您需要将自建 Elasticsearch 中的全量或增量数据迁移至阿里云 Elasticsearch,可通过在 ECS 中自建 Logstash,并通过 Logstash 的管道配置功能实现。本文在 ECS 上部署自建 Elasticsearch 和自建 Logstash,并通过 Logstash 将自建 Elasticsearch 中的数据全量迁移至阿里云 Elasticsearch。
注意事项
-
自建 Logstash 所在的 ECS 需要与阿里云 Elasticsearch 集群在同一专有网络下,同时该 Logstash 需要能够同时访问源 Elasticsearch 集群(自建)和目标 Elasticsearch 集群(阿里云)。
-
数据迁移可以全量迁移或增量迁移。如果业务侧时刻存在写入更新,首次迁移时,需先全量迁移,再通过时间标识字段(或其他可标识增量的字段)进行增量迁移,否则迁移后新数据极易被旧数据覆盖。如果已有全量数据,可以只通过标识字段实现增量数据迁移。
操作流程
-
开通阿里云 Elasticsearch 服务,在 ECS 服务器部署自建 Elasticsearch、准备待迁移数据和部署自建 Logstash。
-
在 ECS 服务器运行 Python 脚本迁移索引元数据。
-
通过 Logstash 管道配置功能,将自建 Elasticsearch 中的全量数据迁移至阿里云 Elasticsearch 中。
步骤一:准备环境与实例
-
创建阿里云 Elasticsearch 实例。
具体操作请参见 创建阿里云 Elasticsearch 实例 。本文使用的测试环境如下。
环境项
环境信息
地域
华东 1(杭州)。
版本
通用商业版 7.10.0。
实例规格配置
3 个可用区、3 个数据节点、单节点 4 核 CPU、16 GB 内存、100 GB ESSD 云盘。
-
创建 ECS 实例,用于部署自建 Elasticsearch、自建 Kibana 和自建 Logstash。
具体操作请参见 自定义购买实例 。本文使用的测试环境如下。
环境项
环境信息
地域
华东 1(杭州)。
实例规格
4 vCPU 16 GiB 内存。
镜像
公共镜像、CentOS 7.9 64 位。
存储
系统盘、ESSD 云盘、100 GiB。
网络
与阿里云 Elasticsearch 相同的专有网络,选中 分配公网 IPv4 地址 ,并按使用流量计费,带宽峰值为 100 Mbps。
安全组
入方向添加 5601 端口(即 Kibana 端口),在授权对象中添加您客户端的 IP 地址。
重要-
如果您的客户端处在家庭网络或公司局域网中,您需要在授权对象中添加局域网的公网出口 IP 地址,而非客户端机器的 IP 地址。建议您通过浏览器访问 cip.cc 查询。
-
您也可以在授权对象中添加 0.0.0.0/0,表示允许所有 IPv4 地址访问 ECS 实例。此配置会导致 ECS 实例完全暴露在公网中,增加安全风险,生产环境尽量避免。
-
-
部署自建 Elasticsearch。
本文使用的自建 Elasticsearch 版本为 7.6.2,1 个数据节点,具体操作步骤如下:
-
连接 ECS 服务器。
具体操作,请参见 通过密码或密钥认证登录 Linux 实例 。
-
使用 root 用户权限创建 elastic 用户。
useradd elastic -
设置 elastic 用户的密码。
passwd elastic系统将提示您输入和确认 elastic 用户的密码。
-
将 root 用户切换为 elastic 用户。
su -l elastic -
下载 Elasticsearch 软件安装包并解压缩。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-linux-x86_64.tar.gz tar -zvxf elasticsearch-7.6.2-linux-x86_64.tar.gz -
启动 Elasticsearch。
进入 Elasticsearch 的安装目录下,启动服务。
cd elasticsearch-7.6.2 ./bin/elasticsearch -d -
验证 Elasticsearch 服务是否正常运行。
cd ~ curl localhost:9200正常情况下,返回结果中会显示 Elasticsearch 版本号和
"You Know, for Search"。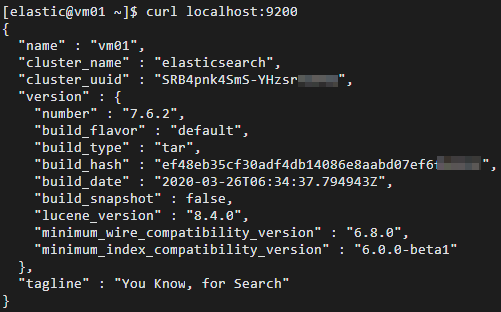
-
-
部署自建 Kibana,并准备测试数据。
本文使用的自建 Kibana 版本为 7.6.2,1 个数据节点,具体操作步骤如下:
-
连接 ECS 服务器。
具体操作请参见 通过密码或密钥认证登录 Linux 实例 。
说明本文档以普通用户权限为例。
-
下载 Kibana 软件安装包并解压缩。
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-linux-x86_64.tar.gz tar -zvxf kibana-7.6.2-linux-x86_64.tar.gz -
修改 Kibana 配置文件 config/kibana.yml ,增加
server.host: "0.0.0.0"配置,允许通过公网 IP 访问 Kibana。进入 Kibana 安装目录,修改 kibana.yml 。
cd kibana-7.6.2-linux-x86_64 vi config/kibana.yml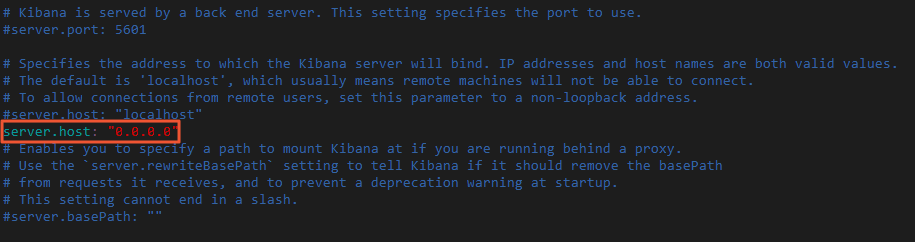
-
使用非 root 用户启用 Kibana。
sudo nohup ./bin/kibana & -
登录 Kibana 控制台,添加示例数据。
-
通过公网 IP 地址登录 Kibana 控制台。
公网 IP 地址为: http://<ECS 服务器的公网 IP 地址>:5601/app/kibana#/home 。
-
在 Kibana 控制台首页,单击 Try our sample data 。
-
在 Sample data 页签,单击日志示例数据模块下的 Add data ,添加对应数据。
-
-
-
部署自建 Logstash。
本文使用的 Logstash 版本为 7.10.0,1 个节点,具体操作步骤如下:
-
连接 ECS 服务器。
具体操作请参见 通过密码或密钥认证登录 Linux 实例 。
说明本文档以普通用户权限为例。
-
回到根目录,下载 Logstash 软件安装包并解压缩。
cd ~ wget https://artifacts.elastic.co/downloads/logstash/logstash-7.10.0-linux-x86_64.tar.gz tar -zvxf logstash-7.10.0-linux-x86_64.tar.gz -
修改 Logstash 的堆内存使用。
Logstash 默认的堆内存为 1 GB,您需要根据 ECS 规格配置合适的内存大小,加快集群数据的迁移效率。
进入 Logstash 的安装目录下,修改 Logstash 配置文件 config/jvm.options,增加-Xms8g 和-Xmx8g。
cd logstash-7.10.0 sudo vi config/jvm.options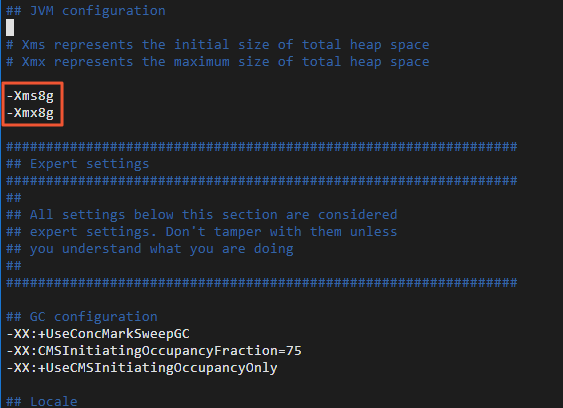
-
修改 Logstash 批量写入记录条数。
每批量写入 5~15 MB 数据,可以加快集群数据的迁移效率。
修改 Logstash 配置文件 config/pipelines.yml,将每批量写入记录条数 pipeline.batch.size 从 125 改为 5000。
vi config/pipelines.yml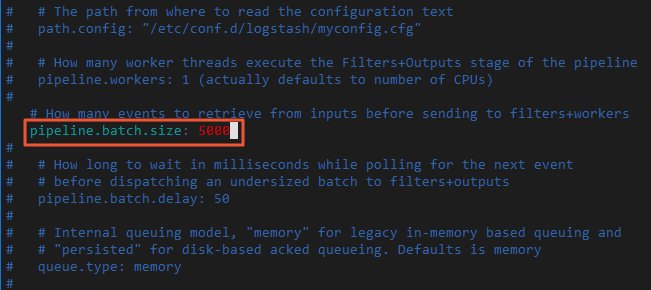
-
验证 Logstash 功能。
-
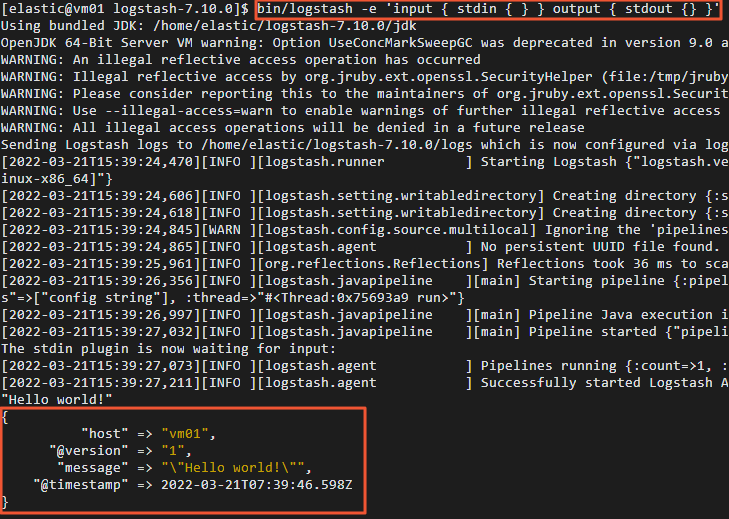
通过控制台输入输出收集数据。
bin/logstash -e 'input { stdin { } } output { stdout {} }' -
在控制台中输入 "Hello world!" 。
正常情况下,控制台会输出 "Hello world!" 。
-
-
(可选)步骤二:迁移索引元数据(设置和映射)
在进行数据迁移时,Logstash 会帮助您自动创建索引,但是自动创建的索引可能与您待迁移的索引存在差异,导致迁移前后数据的格式不一致。因此建议您在数据迁移前,在阿里云 Elasticsearch 中手动创建目标索引,确保迁移前后索引数据完全一致。
您可以通过 Python 脚本创建目标索引,具体操作步骤如下:
-
连接 ECS 服务器。
具体操作请参见 通过密码或密钥认证登录 Linux 实例 。
说明本文档以普通用户权限为例。
-
创建并打开 Python 脚本文件(本文以 indiceCreate.py 为例)。
sudo vi indiceCreate.py -
修改 Python 脚本文件,拷贝以下代码(注意修改集群的连接地址、用户名和密码)。
#!/usr/bin/python # -*- coding: UTF-8 -*- # 文件名:indiceCreate.py import sys import base64 import time import httplib import json ## 源集群host。 oldClusterHost = "localhost:9200" ## 源集群用户名,可为空。 oldClusterUserName = "elastic" ## 源集群密码,可为空。 oldClusterPassword = "xxxxxx" ## 目标集群host,可在阿里云Elasticsearch实例的基本信息页面获取。 newClusterHost = "es-cn-zvp2m4bko0009****.elasticsearch.aliyuncs.com:9200" ## 目标集群用户名。 newClusterUser = "elastic" ## 目标集群密码。 newClusterPassword = "xxxxxx" DEFAULT_REPLICAS = 0 def httpRequest(method, host, endpoint, params="", username="", password=""): conn = httplib.HTTPConnection(host) headers = {} if (username != "") : 'Hello {name}, your age is {age} !'.format(name = 'Tom', age = '20') base64string = base64.encodestring('{username}:{password}'.format(username = username, password = password)).replace('\n', '') headers["Authorization"] = "Basic %s" % base64string; if "GET" == method: headers["Content-Type"] = "application/x-www-form-urlencoded" conn.request(method=method, url=endpoint, headers=headers) else : headers["Content-Type"] = "application/json" conn.request(method=method, url=endpoint, body=params, headers=headers) response = conn.getresponse() res = response.read() return res def httpGet(host, endpoint, username="", password=""): return httpRequest("GET", host, endpoint, "", username, password) def httpPost(host, endpoint, params, username="", password=""): return httpRequest("POST", host, endpoint, params, username, password) def httpPut(host, endpoint, params, username="", password=""): return httpRequest("PUT", host, endpoint, params, username, password) def getIndices(host, username="", password=""): endpoint = "/_cat/indices" indicesResult = httpGet(oldClusterHost, endpoint, oldClusterUserName, oldClusterPassword) indicesList = indicesResult.split("\n") indexList = [] for indices in indicesList: if (indices.find("open") > 0): indexList.append(indices.split()[2]) return indexList def getSettings(index, host, username="", password=""): endpoint = "/" + index + "/_settings" indexSettings = httpGet(host, endpoint, username, password) print (index + " 原始settings如下:\n" + indexSettings) settingsDict = json.loads(indexSettings) ## 分片数默认和源集群索引保持一致。 number_of_shards = settingsDict[index]["settings"]["index"]["number_of_shards"] ## 副本数默认为0。 number_of_replicas = DEFAULT_REPLICAS newSetting = "\"settings\": {\"number_of_shards\": %s, \"number_of_replicas\": %s}" % (number_of_shards, number_of_replicas) return newSetting def getMapping(index, host, username="", password=""): endpoint = "/" + index + "/_mapping" indexMapping = httpGet(host, endpoint, username, password) print (index + " 原始mapping如下:\n" + indexMapping) mappingDict = json.loads(indexMapping) mappings = json.dumps(mappingDict[index]["mappings"]) newMapping = "\"mappings\" : " + mappings return newMapping def createIndexStatement(oldIndexName): settingStr = getSettings(oldIndexName, oldClusterHost, oldClusterUserName, oldClusterPassword) mappingStr = getMapping(oldIndexName, oldClusterHost, oldClusterUserName, oldClusterPassword) createstatement = "{\n" + str(settingStr) + ",\n" + str(mappingStr) + "\n}" return createstatement def createIndex(oldIndexName, newIndexName=""): if (newIndexName == "") : newIndexName = oldIndexName createstatement = createIndexStatement(oldIndexName) print ("新索引 " + newIndexName + " 的setting和mapping如下:\n" + createstatement) endpoint = "/" + newIndexName createResult = httpPut(newClusterHost, endpoint, createstatement, newClusterUser, newClusterPassword) print ("新索引 " + newIndexName + " 创建结果:" + createResult) ## main indexList = getIndices(oldClusterHost, oldClusterUserName, oldClusterPassword) systemIndex = [] for index in indexList: if (index.startswith(".")): systemIndex.append(index) else : createIndex(index, index) if (len(systemIndex) > 0) : for index in systemIndex: print (index + " 或许是系统索引,不会重新创建,如有需要,请单独处理~") -
执行 Python 脚本,创建目标索引。
sudo /usr/bin/python indiceCreate.py -
参见 登录 Kibana 控制台 ,登录目标集群的 Kibana 控制台,查看已创建的索引。
GET /_cat/indices?v
步骤三:迁移全量数据
-
连接 ECS 服务器。
具体操作请参见 通过密码或密钥认证登录 Linux 实例 。
-
在 config 目录下,创建并打开 Logstash 配置文件。
cd logstash-7.10.0/config vi es2es_all.conf -
参考以下配置,修改 Logstash 配置文件。
说明-
8.5 版本 Logstash 的配置参数有所调整,本文同时列出了 7.10.0 版本和 8.5.1 版本 Logstash 的配置示例。
-
为了保证迁移数据的准确性,建议您创建多个 Logstash 管道配置文件,分批次迁移数据,每个 Logstash 迁移部分数据。
7.10.0 版本
input{ elasticsearch{ # 源端ES地址。 hosts => ["http://localhost:9200"] # 安全集群配置登录用户名密码。 user => "xxxxxx" password => "xxxxxx" # 需要迁移的索引列表,多个索引以英文以逗号(,)分隔。 index => "kibana_sample_data_*" # 以下三项保持默认即可,包含线程数和迁移数据大小和Logstash JVM配置相关。 docinfo=>true slices => 5 size => 5000 filter { # 去掉一些Logstash自己加的字段。 mutate { remove_field => ["@timestamp", "@version"] output{ elasticsearch{ # 目标端ES地址,可在阿里云Elasticsearch实例的基本信息页面获取。 hosts => ["http://es-cn-zvp2m4bko0009****.elasticsearch.aliyuncs.com:9200"] # 安全集群配置登录用户名密码。 user => "elastic" password => "xxxxxx" # 目标端索引名称,以下配置表示索引与源端保持一致。 index => "%{[@metadata][_index]}" # 目标端索引type,以下配置表示索引类型与源端保持一致。 document_type => "%{[@metadata][_type]}" # 目标端数据的id,如果不需要保留原id,可以删除以下这行,删除后性能会更好。 document_id => "%{[@metadata][_id]}" ilm_enabled => false manage_template => false }8.5.1 版本
input{ elasticsearch{ # 源端ES地址。 hosts => ["http://es-cn-uqm3811160002***.elasticsearch.aliyuncs.com:9200"] # 安全集群配置登录用户名密码。 user => "elastic" password => "" # 需要迁移的索引列表,多个索引以英文以逗号(,)分隔。 index => "test_ecommerce" # 以下三项保持默认即可,包含线程数和迁移数据大小和Logstash JVM配置相关。 docinfo => true size => 10000 docinfo_target => "[@metadata]" filter { # 去掉一些Logstash自己加的字段。 mutate { remove_field => ["@timestamp","@version"] output{ elasticsearch{ # 目标端ES地址,可在阿里云Elasticsearch实例的基本信息页面获取。 hosts => ["http://es-cn-nwy38aixp0001****.elasticsearch.aliyuncs.com:9200"] # 安全集群配置登录用户名密码。 user => "elastic" password => "" # 目标端索引名称,以下配置表示索引与源端保持一致。 index => "%{[@metadata][_index]}" # 目标端数据的id,如果不需要保留原id,可以删除以下这行,删除后性能会更好。 document_id => "%{[@metadata][_id]}" ilm_enabled => false manage_template => false }Elasticsearch input 插件可以根据配置的查询语句,从 Elasticsearch 集群读取文档数据,适用于批量导入测试日志等操作。默认读取完数据后,同步动作会自动关闭,而阿里云 Logstash 需保证进程一直运行,关闭后将会重新启动进程,导致某些单一任务场景(如 logstash input es)存在重复写数据的情况。设置长时间范围的定时任务可绕过写重复的情况,如每年 3 月 5 日 13 点 20 分触发任务执行,执行完第一次任务后停止管道运行,可避免重复写情况。可以通过 cron 语法配合 schedule 参数实现,详情请参见 Logstash 官网 Scheduling 介绍 。
例如,设置 3 月 5 日 13 点 20 分执行任务:
schedule => "20 13 5 3 *" -
-
进入 Logstash 目录。
cd ~/logstash-7.10.0 -
启动 Logstash 全量迁移任务。
nohup bin/logstash -f config/es2es_all.conf >/dev/null 2>&1 &
步骤四:迁移增量数据
-
连接 ECS 服务器,在 config 目录下,创建并打开 Logstash 增量配置文件。
cd config vi es2es_kibana_sample_data_logs.conf说明本文档以普通用户权限为例。
-
参考以下配置,修改 Logstash 配置文件。
7.10.0 版本配置示例如下。
说明-
8.5 版本 Logstash 的配置参数有所调整,需要去掉
document_type => "%{[@metadata][_type]}"。 -
按如下脚本修改 Logstash 配置文件后,开启 Logstash 定时任务即可触发增量迁移。
input{ elasticsearch{ # 源端ES地址。 hosts => ["http://localhost:9200"] # 安全集群配置登录用户名密码。 user => "xxxxxx" password => "xxxxxx" # 需要迁移的索引列表,多个索引使用英文逗号(,)分隔。 index => "kibana_sample_data_logs" # 按时间范围查询增量数据,以下配置表示查询最近5分钟的数据。 query => '{"query":{"range":{"@timestamp":{"gte":"now-5m","lte":"now/m"}}}}' # 定时任务,以下配置表示每分钟执行一次。 schedule => "* * * * *" scroll => "5m" docinfo=>true size => 5000 filter { # 去掉一些Logstash自己加的字段. mutate { remove_field => ["@timestamp", "@version"] output{ elasticsearch{ # 目标端ES地址,可在阿里云Elasticsearch实例的基本信息页面获取。 hosts => ["http://es-cn-zvp2m4bko0009****.elasticsearch.aliyuncs.com:9200"] # 安全集群配置登录用户名密码. user => "elastic" password => "xxxxxx" # 目标端索引名称,以下配置表示索引与源端保持一致。 index => "%{[@metadata][_index]}" # 目标端索引type,以下配置表示索引类型与源端保持一致。 document_type => "%{[@metadata][_type]}" # 目标端数据的id,如果不需要保留原id,可以删除以下这行,删除后性能会更好。 document_id => "%{[@metadata][_id]}" ilm_enabled => false manage_template => false }重要-
Logstash 记录的时间戳为 UTC 时间,如果您的本地时间为北京时间(东八区),那么两者会存在 8 个小时的时区差,此时将 UTC 时间转化为北京时间,可使用公式:UTC+时区差=北京时间。例如,以上示例中通过源端索引中的 @timestamp 字段进行 range 范围过滤查询获取增量数据,并在对应的时间上+8h 转换为北京时间。
-
通过 Logstash 控制时间字段实现增量数据的同步,需确保原索引中有可控制的时间字段,如果原索引中没有时间字段数据,可使用 ingest pipeline 指定 _ingest.timestamp 获取元数据值,从而引入 @timestamp 时间字段。
-
-
进入 Logstash 目录。
cd ~/logstash-7.10.0 -
启动 Logstash 增量迁移任务。
sudo nohup bin/logstash -f config/es2es_kibana_sample_data_logs.conf >/dev/null 2>&1 & -
在目标端 Elasticsearch 集群的 Kibana 中,查询最近更新的记录,验证增量数据是否同步。
以下示例的查询条件为:索引名称为 kibana_sample_data_logs、最近时间范围为 5 分钟。
GET kibana_sample_data_logs/_search "query": { "range": { "@timestamp": { "gte": "now-5m", "lte": "now/m" "sort": [ "@timestamp": { "order": "desc"
步骤五:查看数据迁移结果
-
查看是否完成全量迁移。
-
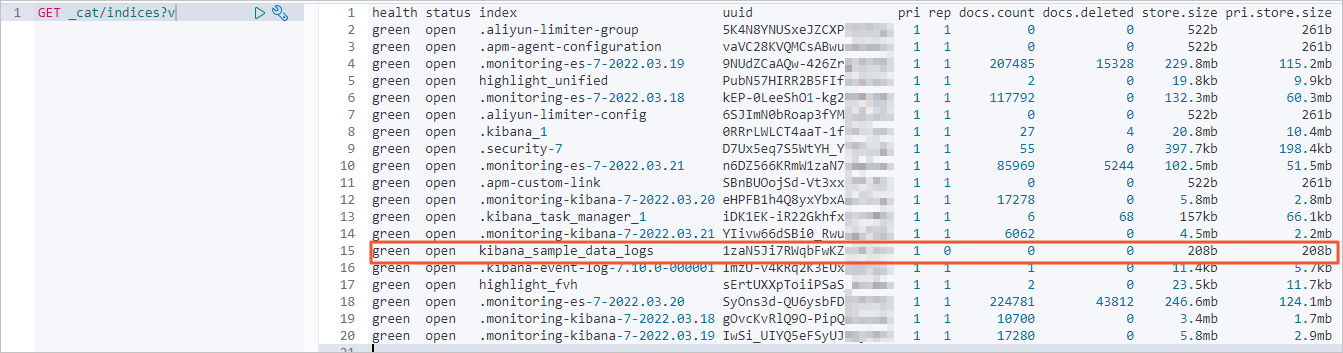
查看自建 Elasticsearch 集群的索引和数据量信息。
GET _cat/indices?v结果如下。

-
全量迁移前,查看阿里云 Elasticsearch 集群的索引和数据量信息。
-
全量迁移后,查看阿里云 Elasticsearch 集群索引和数据量信息。
正常情况下,返回的记录条数应该与自建 Elasticsearch 集群一致。
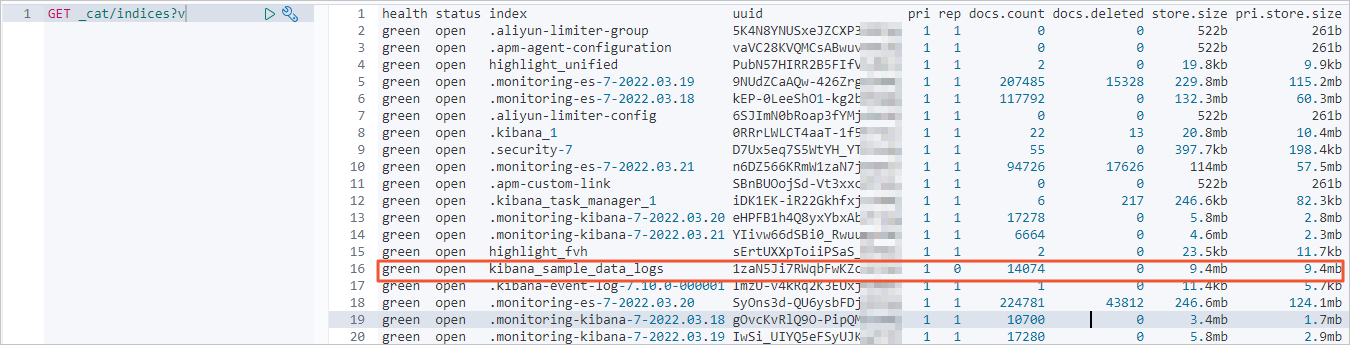
-
-
查看是否完成增量迁移。
查看自建 Elasticsearch 集群的最近更新记录。
GET kibana_sample_data_logs/_search "query": { "range": { "@timestamp": { "gte": "now-5m", "lte": "now/m" "sort": [ "@timestamp": { "order": "desc" }返回结果如下。
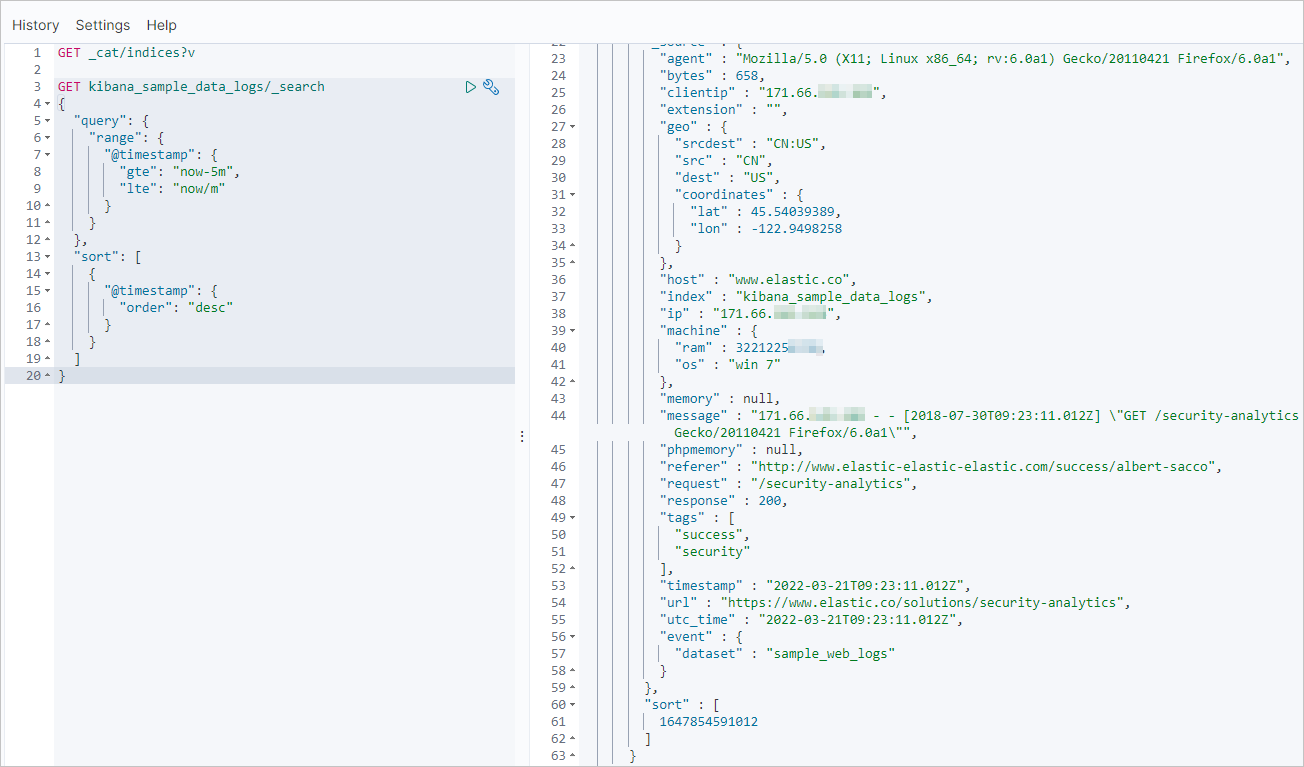
增量迁移完成后,使用同样命令查看阿里云 Elasticsearch 集群最近的更新记录。正常情况下,阿里云 Elasticsearch 集群的更新记录会与自建集群一致。