


SQL 窗口函数 ( window function )

目录
一、什么是窗口函数?
二、如何使用窗口函数?
三、案例一:面试经典排名问题
四、案例二:面试经典 TOP N 问题
五、聚合函数作为窗口函数
六、案例三:累计求和问题
七、案例四:如何在每组里比较?
八、窗口函数的移动平均
九、窗口函数总结
十、窗口函数练习题
十一、存储过程
正文
一、什么是窗口函数?
1. 窗口函数用于解决组内排名问题
- 排名问题:每个部门按业绩来排名
- top N 问题:找出每个部门排名前 N 的员工进行奖励
2. 窗口函数的基本语法
<窗口函数> over (partition by (用于分组的列名) order by (用于排序的列名))3. 窗口函数有哪些?
- 专用窗口函数:rank、dense_rank、row_number 等
- 聚合函数:sum、avg、count、max、min
❤️ 窗口函数是对 where 或者 group by 子句处理后的结果进行操作。所以窗口函数原则上只能用在 select 子句中。
二、如何使用窗口函数
1. 专用窗口函数 rank
新建班级表
insert into 班级表(学号,班级,成绩)
values('0001','1','86');
insert into 班级表(学号,班级,成绩)
values('0002','1','95');
insert into 班级表(学号,班级,成绩)
values('0003','2','89');
insert into 班级表(学号,班级,成绩)
values('0004','1','83');
insert into 班级表(学号,班级,成绩)
values('0005','2','86');
insert into 班级表(学号,班级,成绩)
values('0006','3','92');
insert into 班级表(学号,班级,成绩)
values('0007','3','86');
insert into 班级表(学号,班级,成绩)
values('0008','1','88'); 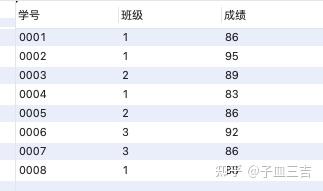
对每个班级按成绩排名
select *, rank() over(partition by 班级 order by 成绩 desc) as ranking
from 班级表;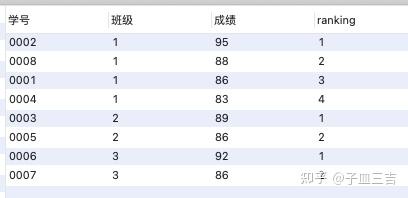
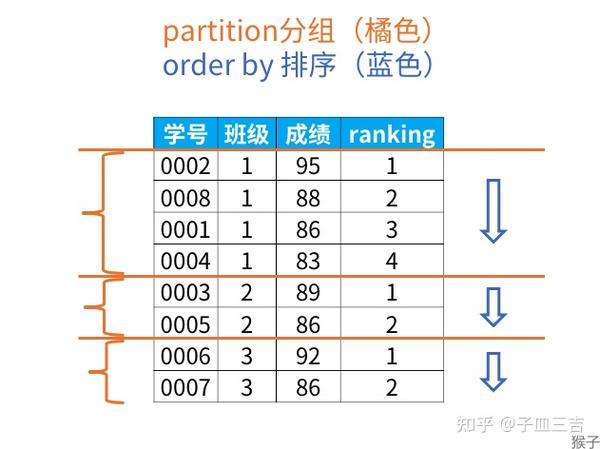
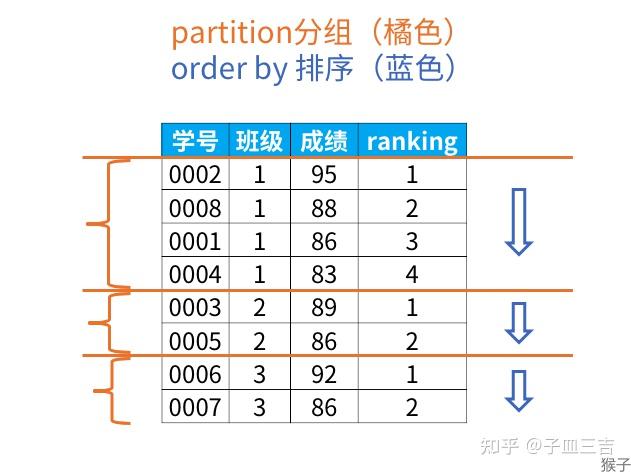
以上结果,班级 1 中,成绩 “95” 排在第一位,成绩 “83” 排在第 4 位。
对 SQL 语句解释如下:rank 是排序函数,要求是 “每个班级内按成绩排名”
- 每个班级内:按班级分组,partition by 用来对表分组,在该案例中,指定了按 “班级” 分组
- 按成绩排名:order by 子句的功能是对分组后的结果进行排序,默认按升序 ( asc ) 排列。上述案例中 order by 成绩 desc,即按成绩降序
❤️ 窗口函数具备了 group by 子句分组的功能和 order by 子句排序的功能,为什么还要用窗口函数?
- group by 分组汇总后改变了表的行数,一行只有一个类别
- partition by 和 rank 函数不会减少原表中的行数
select 班级,count(学号)
from 班级表
group by 班级;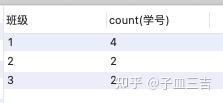
select 班级,count(学号) over (partition by 班级 order by 班级) as current_count
from 班级表; 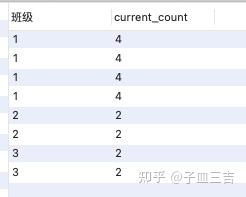
❤️ 为什么叫 “窗口函数”?
因为 partition by 分组后的结果成为 “窗口”,这里的窗口不是房间的门窗,而是表示 “范围” 的意思。
简言之,窗口函数具有以下功能
- 同时具有分组和排序的功能
- 不减少原表的行数
- 语法为:<窗口函数> over (partition by (用于分组的列名) order by (用于排序的列名) )
2. 其他专用窗口函数
专用窗口函数 rank、dense_rank、row_number 有什么区别?
select *,rank() over(order by 成绩 desc) as ranking,
dense_rank() over(order by 成绩 desc) as dese_rank,
row_number() over(order by 成绩 desc) as row_num
from 班级表;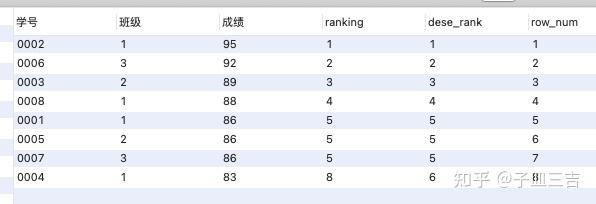

( 1 ) rank 函数: 上述案例中,ranking 列的 5 位、5 位、5 位、8 位,也就是说,如果 有并列名次的行 ,会占用下一名次的位置。例如,正常排名是:1、2、3、4,但是现在前 3 名是并列的名次,结果就是 1、1、1、4。
( 2 ) dense_rank 函数: 上述案例中,dense _ rank 列的 5 位、5 位、5 位、6 位,也就是说,如果 有并列名次的行 ,不占用下一名次的位置。例如,正常排名是:1、2、3、4,但是现在前 3 名是并列的名次,结果就是 1、1、1、2。
( 3 ) row_number 函数: 上述案例中,row _ num 列的 5 位、6 位、7 位、8 位,也就是说,不考虑并列名次的情况。例如,前 3 名是并列的名次,排名结果就是正常的 1、2、3、4。
( 4 ) 这 3 个函数的区别如下
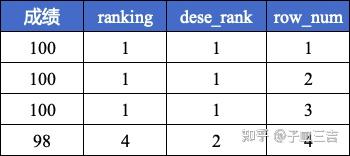
注意: 以上三个专用窗口函数中,函数后面的括号 ( ) 不需要任何参数,保持空括号就行。
三、案例一:面试经典排名问题
在班级表中,需要按成绩来排名,如果两个分数相同,则排名并列。正常排名是 1、2、3、4,现在前 3 名是并列的名次,排名结果是:1、1、1、2。
【解题思路】 涉及排名问题,可以使用窗口函数。根据前文中介绍的专用窗口函数 rank、dense_rank 和 row_number 的用法和区别以及题目要求,使用 dense_rank 函数。
select *,dense_rank() over(order by 成绩 desc) as dese_rank
from 班级表;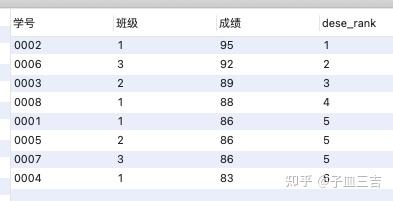
【举一反三】编写 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名 ( Rank ) 相同。并且,评分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。



insert into 成绩表_1(ID,Score)
values('1','3.50');
insert into 成绩表_1(ID,Score)
values('2','3.65');
insert into 成绩表_1(ID,Score)
values('3','4.00');
insert into 成绩表_1(ID,Score)
values('4','3.85');
insert into 成绩表_1(ID,Score)
values('5','4.00');
insert into 成绩表_1(ID,Score)
values('6','3.65');
select score,dense_rank() over(order by score desc) as dese_rank
from 成绩表_1;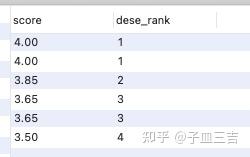
四、案例二:面试经典 TOP N 问题
工作中经常会遇到以下业务问题:
- 如何找到每个类别下用户最喜欢的产品 ( TOP1 )?
- 如何找到每个类别下用户点击最多的 5 个商品 ( TOP5 )?
即:分组取最大值、最小值、每组最大的 N 条 ( TOP N ) 记录
本案例数据来源图 12 的数据表
insert into 成绩表_3(学号,课程号,成绩)
values('0001','0001','80');
insert into 成绩表_3(学号,课程号,成绩)
values('0001','0002','90');
insert into 成绩表_3(学号,课程号,成绩)
values('0001','0003','99');
insert into 成绩表_3(学号,课程号,成绩)
values('0002','0002',
'60');
insert into 成绩表_3(学号,课程号,成绩)
values('0002','0003','80');
insert into 成绩表_3(学号,课程号,成绩)
values('0003','0001','80');
insert into 成绩表_3(学号,课程号,成绩)
values('0003','0002','80');
insert into 成绩表_3(学号,课程号,成绩)
values('0003','0003','80');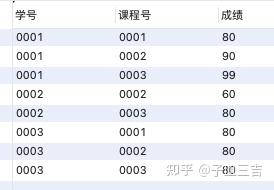
1. 分组取每组最大值
按课程号分组取得成绩最大值所在行的数据
( 1 ) 使用 group by 和汇总函数
得到每个组里的一个值 ( max,min,avg 等 ),但无法得到成绩最大值所在行的数据
select 课程号,max(成绩) as 最大成绩
from 成绩表_3
group by 课程号;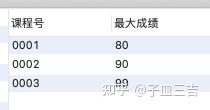
( 2 ) 使用关联子查询实现
select *
from 成绩表_3 as a
where 成绩=(select max(成绩)
from 成绩表_3 as b
where b.课程号=a.课程号);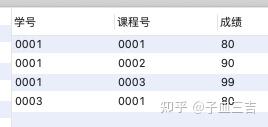
2. 分组取每组最小值
案例:按课程号分组取成绩最小值所在行的数据
使用关联子查询
select *
from 成绩表_3 as a
where 成绩=(select min(成绩)
from 成绩表_3 as b
where b.课程号=a.课程号);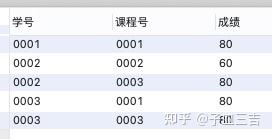
( 3 ) 每组最大的 N 条记录
案例: 现有各科成绩表,记录了每个学生的各科成绩。表格内容如下。
insert into 各科成绩表(姓名,科目,成绩)
values('猴子','语文','90');
insert into 各科成绩表(姓名,科目,成绩)
values('王思聪','语文','81');
insert into 各科成绩表(姓名,科目,成绩)
values('马云','语文','79');
insert into 各科成绩表(姓名,科目,成绩)
values('马化腾','语文','88');
insert into 各科成绩表(姓名,科目,成绩)
values('猴子','数学','85');
insert into 各科成绩表(姓名,科目,成绩)
values('王思聪','数学','86');
insert into 各科成绩表(姓名,科目,成绩)
values('马云','数学','92');
insert into 各科成绩表(姓名,科目,成绩)
values('马化腾','数学','83');
insert into 各科成绩表(姓名,科目,成绩)
values('猴子','英语','87');
insert into 各科成绩表(姓名,科目,成绩)
values('王思聪','英语','98');
insert into 各科成绩表(姓名,科目,成绩)
values('马云','英语','93');
insert into 各科成绩表(姓名,科目,成绩)
values('马化腾','英语','95');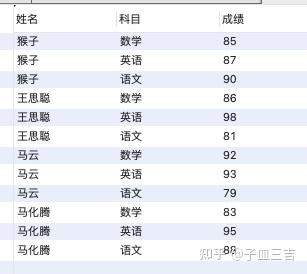
问题: 查找每个学生成绩最高的 2 个科目
【解题思路】
- 查 “每个” 学生最高的成绩,group by 姓名
- 按学生姓名分组后,成绩按降序排列,排在最前面的 2 个即 “成绩最高的 2 个科目”
- 分组后,需要排序,又不减少原表的行数,这种功能只有窗口函数才能实现
- 为了不受并列成绩的影响,使用 row_number 专用窗口函数
【解题步骤】
① 按姓名分组,partition by 姓名;按成绩降序排列,order by 成绩 desc;套入窗口函数的语法,SQL 语句如下
select *,row_number() over(partition by 姓名 order by 成绩 desc)as ranking
from 各科成绩表;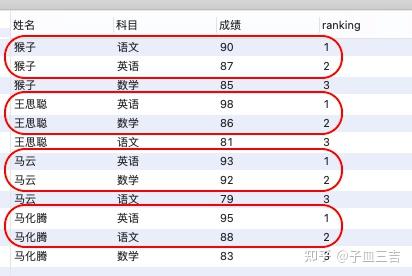
② 红色框内的数据,每个同学成绩最好的 2 个科目,就是要查询的数据。
提取 ranking <= 2 的数据即可,在 SQL 子句中加入 where 子句。
❤️ 由于 SQL 语句的运行顺序是:from 子句、where 子句、group by 子句、having 子句、select 子句,所以将第一步得到的结果作为子查询,再加入 where 子句。
select *
from (select *,row_number() over(partition by 姓名 order by 成绩 desc)as ranking
from 各科成绩表) as a
where ranking <= 2;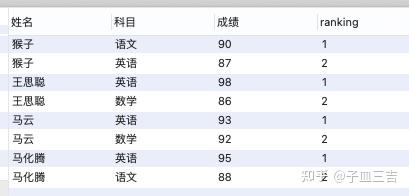
【考点】
- 考察对窗口函数的灵活使用
- 非常容易因为子查询问题报错,本案例考察了对子查询的熟练使用
- 间接考察了 SQL 语句执行顺序
【举一反三】
经典 TOP N 问题:每组最大的 N 条记录
这类涉及 “既要分组,又要排序” 的情况,用窗口函数实现。
select *
from (select *,row_number() over(partition by 要分组的列名 order by 要排序的列名 desc) as ranking
from 表名) as a
where ranking <=N;五、聚合函数作为窗口函数
聚合窗口函数和专用窗口函数用法完全相同:把聚合函数写在窗口函数的位置即可。但 聚合函数后面的括号不能为空,需要指定聚合的列名。
针对图 02 中班级表的数据,定义 SQL 查询。
select *,sum(成绩) over (order by 学号) as current_sum,
avg(成绩) over (order by 学号) as current_avg,
count(成绩) over (order by 学号) as current_count,
max(成绩) over (order by 学号) as current_max,
min(成绩) over (order by 学号) as current_min
from 班级表;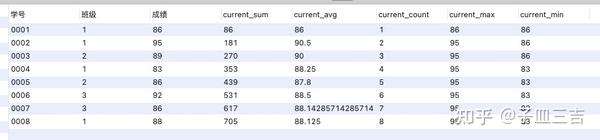
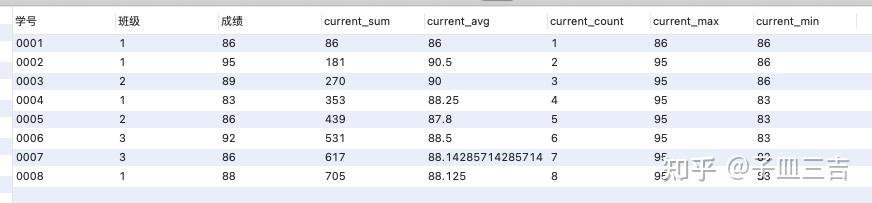
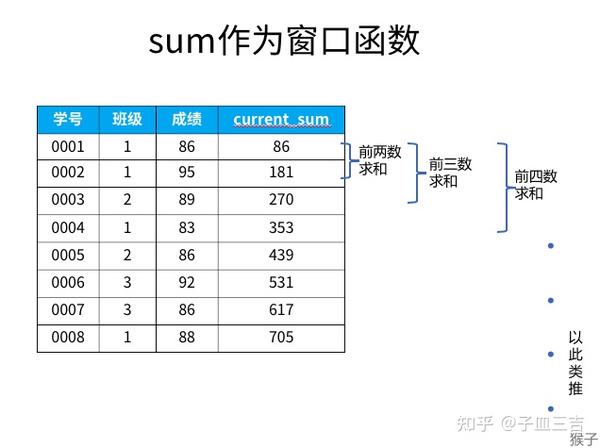

❤️ 如图 19,聚合函数 sum 在窗口函数中,是对 自身记录以及自身纪录以上的数据 进行求和的结果,例如:学号 0004,在使用 sum 窗口函数后的结果,是对 0001、0002、0003 和 0004 号的 求和;学号 0005,则结果是 0001 号 ~ 0005 号成绩的求和,以此类推,avg、count、max、min 都是针对自身纪录以及自身纪录以上的所有数据进行计算,例如:0005 号后面的聚合窗口函数结果是学号 0001 号 ~ 0005 号成绩的平均、计数、最大值和最小值。
❤️ 想知道所有人成绩的总和、平均等聚合结果,查看最后一行即可。
❓ 这样使用窗口函数有什么用呢?
- 聚合函数作为窗口函数,可以在每一行的数据里直观地看到,截止到本行数据,统计数据是多少 ( max、min 等 )
- 同时可以看出每一行数据对整体统计数据的影响。
六、案例三:累计求和问题
题目:“薪水表” 中记录了员工发放的薪水,包含雇员编码、薪水、起始日期、结束日期。其中,薪水是指该雇员在 起始日期 到 结束日期 这段时间内的薪水,当前员工是指结束日期 = '9999 - 01 - 01' 的员工 ( 该公司业务:没有离职的员工,用这个值表示 )。薪水表前 10 行如图 21。
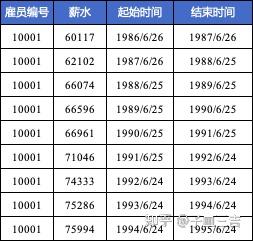
【业务问题】按照雇员升序排列,查找薪水的累计和 ( 累计薪水 )。其中,累计薪水是前 N 个当前员工 ( 结束日期 = '9999 - 01 -01' ) 的薪水的累计和,其他以此类推。需要输出的结果为图 21,每个员工的薪水累计和。
【解题步骤】
1. 将薪水数据导入 SQL
( 1 ) 在数据库中创建 “薪水表”,列名与 Excel 中对应
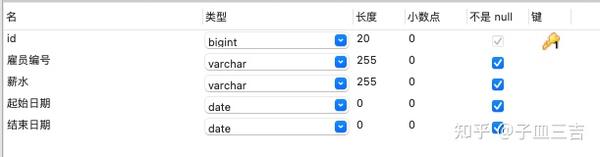
Excel 中,列名 “雇员编号” 中 有重复数据,不能作为主键, 需要在数据库的 “薪水表” 中增加列名 “id”,并设置为主键。
( 2 ) 导入 Excel 数据
右键 “薪水表” → 导入向导 → Excel 2007 → 添加文件 → 选择导入的 sheet
2. 筛选出当前员工 ( 结束日期 = '9999 - 01 - 01' 的薪水 )
select 雇员编号,薪水
from 薪水表
where 结束日期 = '9999-01-01';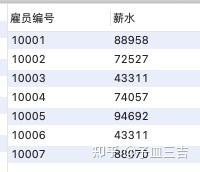
3. 什么是累计薪水?
前 N 个当前员工的薪水的累计和
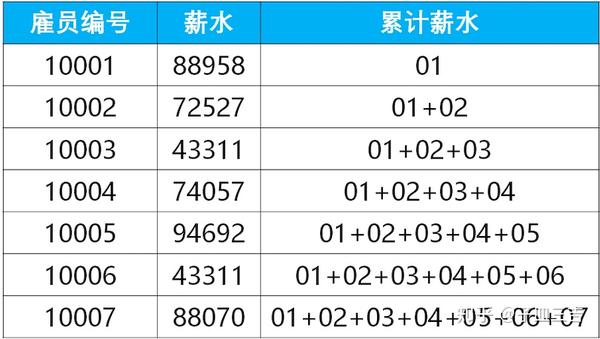

- 第一行的累计薪水为员工 10001 的
- 第二行的累计薪水为员工 10001、10002 的薪水之和
- 第三行的累计薪水为员工 10001、10002 和 10003 的薪水之和
- 以此类推
4. 如何计算出每行的累计薪水?
用聚合函数作为窗口函数,有累计的功能。此处用聚合函数 sum 解决问题。
select
雇员编号,薪水,sum(薪水) over(order by 雇员编号) as 累计薪水
from 薪水表
where 结束日期 = '9999-01-01';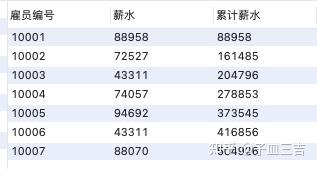
【本题考点】 对于 “累计” 问题,用聚合函数作为窗口函数,例:累计求和,用 sum
sum(列名) over(order by (用于排序的列名))
-- 累计求平均值,用avg
avg(列名) over(order by (用于排序的列名))❤️【累计求和万能模板】
select 列名1,列名2,sum(列名) over(order by 用于排序的列) as 累计值的别名
from 表名;【举一反三】
图 26 为确诊人数表,包含日期和该日期对应的新增确诊人数。
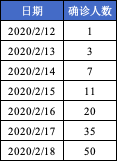
按照日期升序排列,查找日期、确诊人数以及对应的累计确诊人数。
select 日期,确诊人数,sum(确诊人数) over(order by 日期) as 累计确诊人数
from 确诊人数表;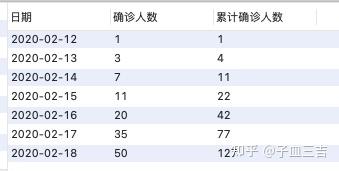
七、案例四:如何在每组里比较?
图 16 记录了每个学生各科的成绩。
问题:查找单科成绩高于该科目平均成绩的学生名单。
【解题思路】
1. “查找单科成绩高于该科目平均成绩“,也就是在 ”每个“ 科目里比较,即要进行分组,使用 group by 子句或者窗口函数的 partition by。
2. 使用聚合窗口函数 ( 求平均值 avg ),将每门课的平均成绩求出以后,找出大于平均成绩的数据,即要求分组后不能减少表的行数,此处使用窗口函数的 partition by。
【解题步骤】
1. 聚合函数 avg( ) 作为函数,求每一科目的平均成绩
聚合函数 avg( ) 作为窗口函数,求每一科目的平均成绩。
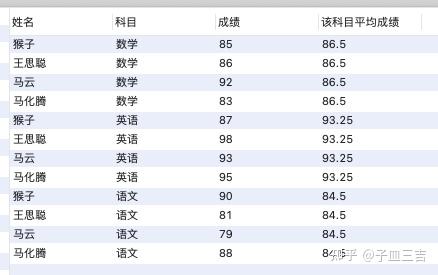
select *,avg(成绩) over(partition by 科目) as 该科目平均成绩
from 各科成绩表; 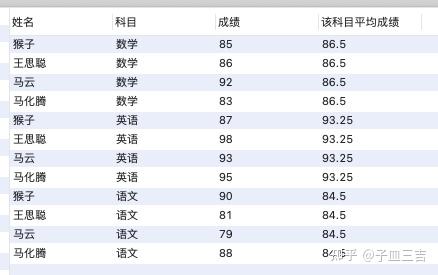
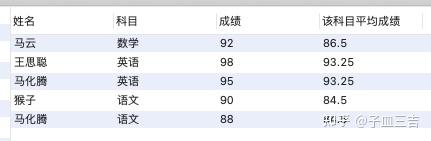
2. 筛选出成绩大于平均成绩的数据。
由于 SQL 语句运行顺序 select 子句在 where 子句之后,所以不能直接在上述 SQL 语句之后加入 where 子句, 只能将上述 SQL 语句作为子查询,再加入 where 子句,并且子查询查询出的派生表必须有别名 ( as a ) 。
select *
from(select *,avg(成绩) over(partition by 科目) as 该科目平均成绩
from 各科成绩表) as a
where 成绩 > 该科目平均成绩;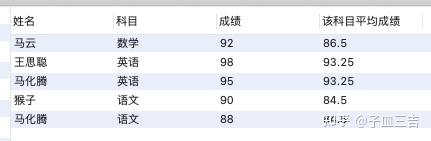
使用关联子查询
select *
from 各科成绩表 as a
where 成绩 > (select avg(成绩) as 该科目的平均成绩
from 各科成绩表 as b
where a.科目 = b.科目);
【本题考点】
1. 考察对窗口函数的灵活使用
2. 在筛选高于每个科目平均成绩的数据时,非常容易因为子查询问题而报错
3. 间接考察了 SQL 语句执行顺序
【举一反三】
查找 每个组里 大于 平均值 的数据,可以有两种方法:
- 窗口函数
- 关联子查询
八、窗口函数的移动平均
对于图 01 的班级表,用聚合函数 avg 的窗口函数举例说明。
select *,avg(成绩) over(order by 学号 rows 2 preceding) as current_avg
from 班级表;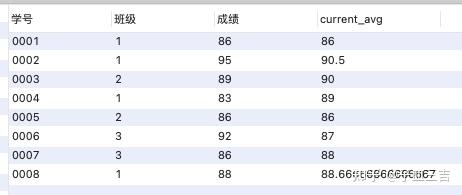
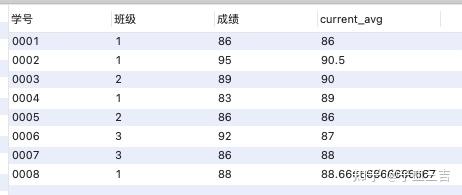
❤️ 使用 rows 和 preceding 这两个关键字,是 ”之前 N 行“ 的意思,上面的 SQL 语句中,指的是之前 2 行,即得到的结果是 自身记录及前 2 行的平均。
例如: 学号 0004 学生的 current_avg 是自己和前 2 位同学的平均,即 学号 0002、学号 0003 和学号 0004 三位同学的平均,其他数据的情况也是如此。
❤️ 想要计算当前行与前 n 行 ( 共 n + 1 行 ) 的平均值,只要调整 rows……preceding 中间的数字即可。在移动平均中,被选出的数据构成一个框架。
❓ 这样使用窗口函数有什么用呢?
在公司业绩名单排名中,可以通过移动平均,直观地查看到与相邻名次业绩的平均、求和等统计数据。
九、窗口函数总结
1. 注意事项
partition by 子句可以省略,就是可以不指定分组。
select *,rank() over(order by 成绩 desc) as rangking
from 班级表;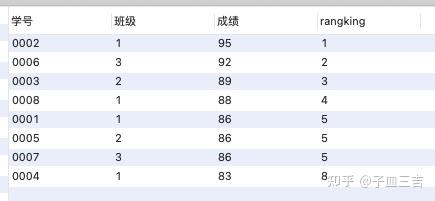

2. 总结
( 1 ) 窗口函数语法
<窗口函数> over(partition by (用于分组的列名) order by (用于排序的列名))
<窗口函数> 的位置可以放 2 种函数
- 专用窗口函数:rank、dense_rank、row_number 等
- 聚合函数:sum、avg、count、max、min
( 2 ) 窗口函数的功能
- 同时具有分组 ( partition by ) 和排序 ( order by ) 功能
- 不减少表的行数,用来在组内进行排名
( 3 ) 使用时的注意事项
窗口函数原则上只能写在 select 子句中
( 4 ) 使用场景
- 经典 TOP N 问题:找出排名前 N 的员工进行奖励
- 经典排名问题:在每组内比较,例如:每个部门按业绩来排名
- 在每个组里比较的问题:查找每个组里大于平均值的数据,窗口函数和关联子查询都可以实现
- 累计求和问题
十、窗口函数练习题
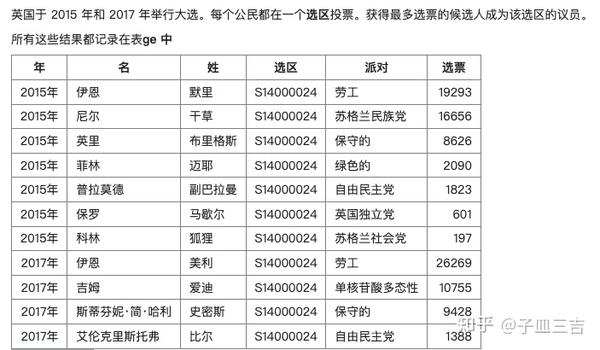
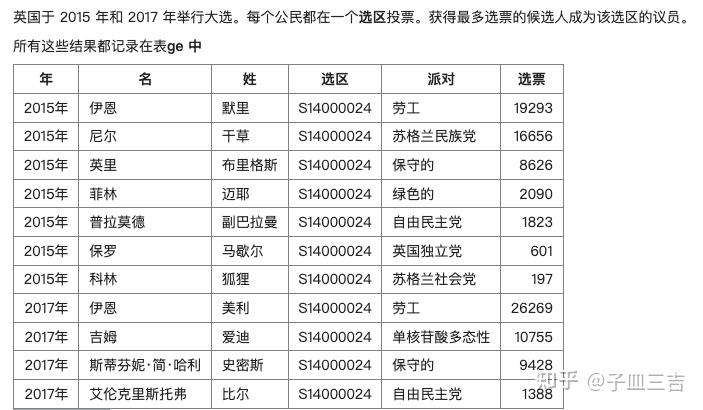
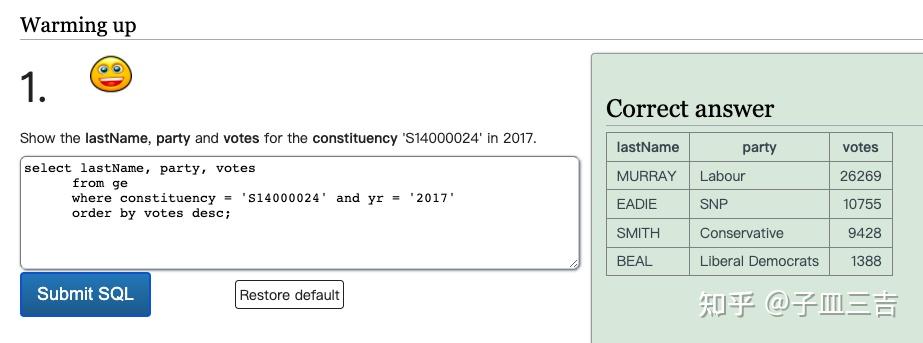
❤️ 练习题一:查询 2017 年选区(constituency)为'S14000024' 的姓(last name)、政党(party) 和选票(votes)。
select lastName, party, votes
from ge
where constituency = 'S14000024' and yr = '2017'
order by votes desc;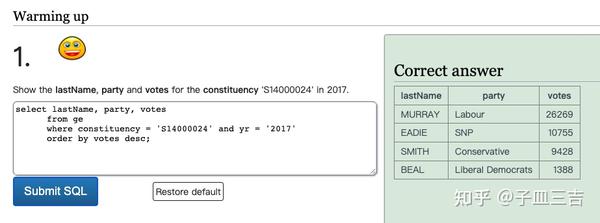
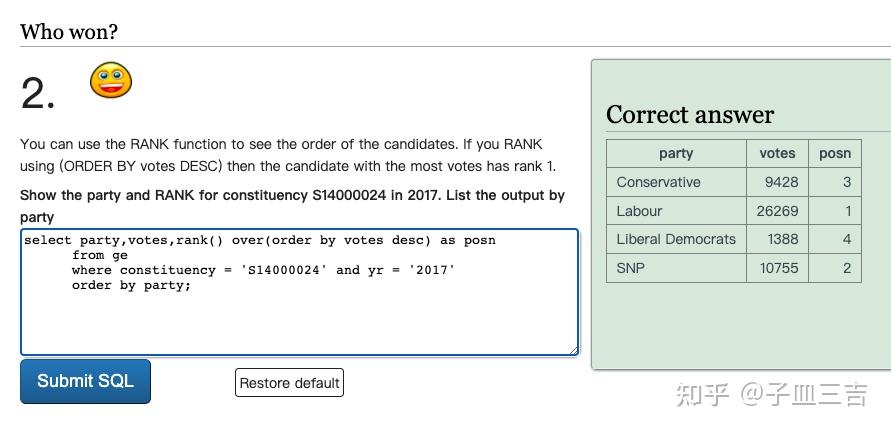
❤️ 练习题二:使用 RANK 函数可以查看候选人的排名。如果使用 (ORDER BY votes DESC) 进行排名,则得票最多的候选人将获得排名 1。查询 2017 年选区 S14000024 的政党及其排名,结果按政党列出。
select party,votes,rank() over(order by votes desc) as posn
from ge
where constituency = 'S14000024' and yr = '2017'
order by party;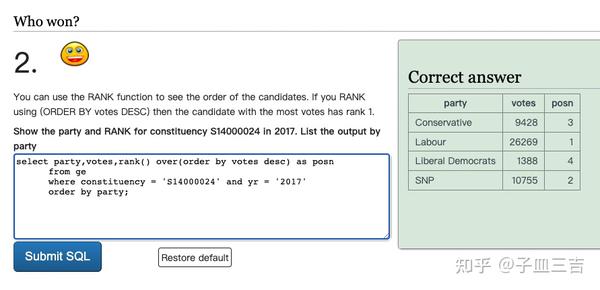
❤️ 练习题三:使用 partition 显示选取 S14000021 中各方在每年的排名。包括 yr、party、votes 和排名 ( 得票最多的一方为 1 )。
select yr,party,votes,
rank() over(partition by yr order by votes desc) as posn
from ge
where constituency = 'S14000021'
order by party,yr;

❤️ 练习题四:选区 Edinburgh 为 S14000021 到 S14000026。使用 partition by,显示该选区 2017 年选举时各政党的排名。对结果进行排序,首先显示获胜者,然后按选区排序。
select constituency,party,votes,
rank() over(partition by constituency order by votes desc) as posn
from ge
where constituency between 'S14000021' and 'S14000026'
and yr = '2017'
order by posn,constituency;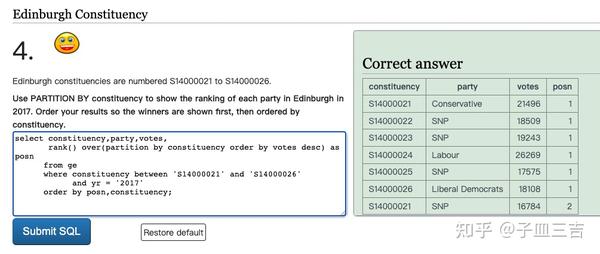
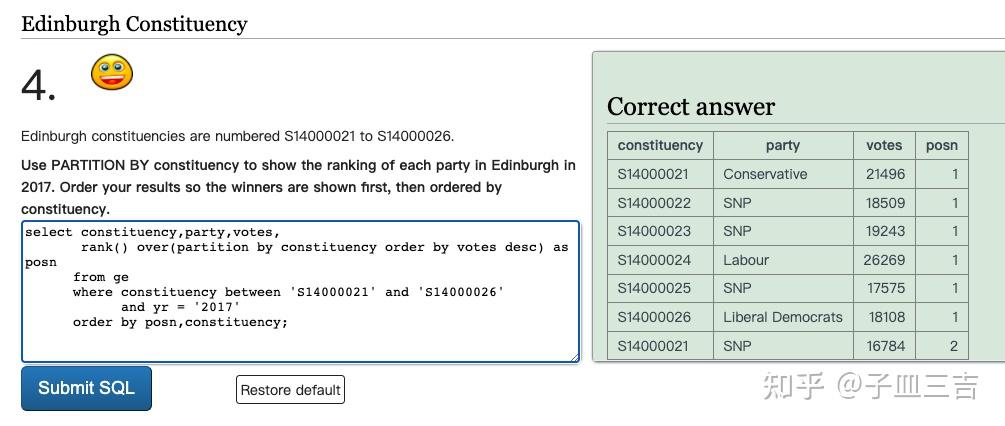
先按排名升序,再按选区号升序。
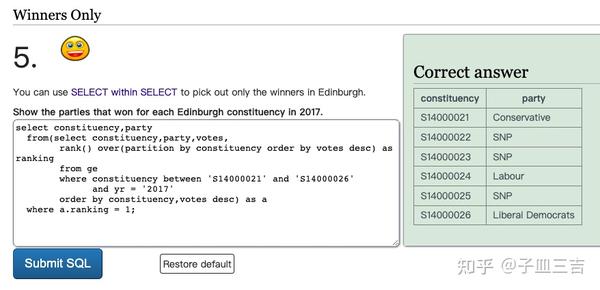
❤️ 练习题五:使用子查询找出 Edinburgh 选区的获胜者。查询 2017 年 Edinburgh 每个选区获胜的政党。
- 每个选区,即按选区分组
- 先按选区分组,再将选票数降序排列,找出选票数最高者,最后找出每个选区的获胜者
- 即每组内找票数最高者
- 使用子查询,排序,where ranking = 1
select constituency,party
from(select constituency,party,votes,
rank() over(partition by constituency order by votes desc) as ranking
from ge
where constituency between 'S14000021' and 'S14000026'
and yr = '2017'
order by constituency,votes desc) as a
where a.ranking = 1
;

❤️ 练习题六:使用 count 和 group by 查看每个政党在苏格兰的表现。苏格兰选区以 “S” 开头。查询 2017 年苏格兰每个政党的当选人数。
- 每个政党,group by party
- 当选人数,即 ranking = 1 的数量,count(1)
select party,count(ranking) as seats
from(select constituency,party,votes,
rank() over(partition by constituency order by votes desc) as ranking
from ge
where constituency like 'S%' and yr = '2017'
order by constituency,votes desc) as a
where a.ranking = 1
group by party;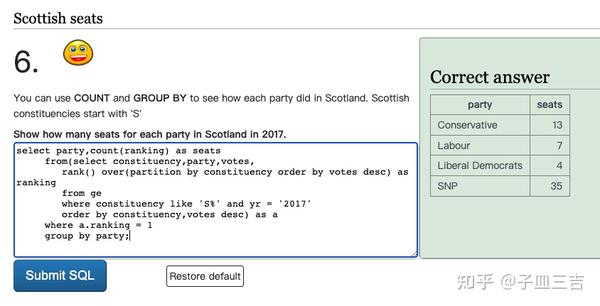

十一、存储过程
1. 什么是存储过程?
驾驶汽车的一系列动作:启动、倒车、转向等。
现有一款新车,可以自动完成以上这些重复动作,每次上车后,汽车可以自动启动和倒车。
同样的,在工作中也会遇到重复性的工作,此时就可以把常用的 SQL 写好存起来,这就是存储过程。下次遇到同样的问题,直接使用存储过程就可以,不需要再重新写一遍 SQL,进而极大地提高了工作效率。
2. 如何使用存储过程?
定义存储过程 → 使用定义好的存储过程
( 1 ) 无参数的存储过程
定义存储过程的语法形式
create procedure 存储过程名称() begin <SQL 语句>;end;注:begin……end 用于表示 SQL 语句的开始和结束。语法里的 SQL 语句就是重复使用的 SQL 语句。例如:查出 ”学生表“ 里的学生姓名。
select 姓名 from student;把以上 SQL 语句放入存储过程的语法里,并给这个存储过程命名 a_student1
create procedure a_student1() begin select 姓名 from student;end;在 navicat 里运行以上语句,建立的存储过程如下图
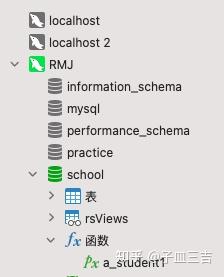
下次使用存储过程时,使用下面的 SQL 语句就可以
call a_student1;
( 2 ) 有参数的存储过程
无参数的存储过程名称后面是 ( ),括号中没有参数。
当括号中有参数时,语法如下:
create procedure 存储过程名称(参数1,参数2,……) begin <SQL 语句>; end;案例:在表 student 中找出指定学号的学生姓名。如果指定学号是 0001,则 SQL 语句如下
select 姓名 from student where 学号 = '0001';如果每次要查询的学号不同,就需要用到参数。SQL 语法如下:
create procedure getNum(num varchar(255))
begin
select 姓名
from student
where 学号 = num;
end;- getnum 表示存储过程的名称
- num 是参数名称
- varchar(100) 是参数类型,这里表示 字符串类型
存储过程中的 SQL 语句 ( where 学号 = num ) 使用了这个参数 num。
如果需要查询 学号 = '0001' 的学生姓名,SQL 语句如下:
call getNum('0001');
( 3 ) 默认参数的存储过程
默认参数
① in 输入参数
参数初始值在存储过程前被指定为 默认值 ,在存储过程中修改该参数的值,不能被返回。
set@num = 0; -- 初始化参数值
-- 初始化存储过程
create procedure in1(in num int)
begin
select num; -- 初始值被定义
set num = 1;
select num; -- 修改参数为 1
end;
-- in 参数调用
call in1( @num );
select num;不太理解运行结果,待更新……
② out 输出参数
参数初始值为空,该值可在存储过程内部被改变,并且可以返回
set@num = 0; -- 初始化参数
-- 初始化存储过程
create procedure out1(out num int)
begin
select num; -- 初始值被定义
set num = 1;
select num; -- 修改参数为 1
end;
-- in 参数调用
call out1(@num);
select num;不太理解运行结果,待更新……
③ inout 输入输出参数
参数初始值在存储过程前被指定为默认值,并且可在存储过程中被改变和在调用完毕后可被返回
set@num = 0; -- 初始化参数
-- 初始化存储过程
create procedure inout1(inout num int)
begin
select num; -- 初始值被定义
set num = 1;
select num; -- 修改参数为 1
end;