set PYTHONPATH=$PYTHONPATH:.
set CUDA_VISIBLE_DEVICES=0(默认只有一个GPU)
python -u tools/train.py -c configs/yolov3_mobilenet_v1_fruit.yml --use_tb=True --tb_log_dir=tb_fruit_dir/scalar --eval
运行如下命令,即可开始训练

出现如下图所示现象,可以表示为训练正常,可等待训练结束。
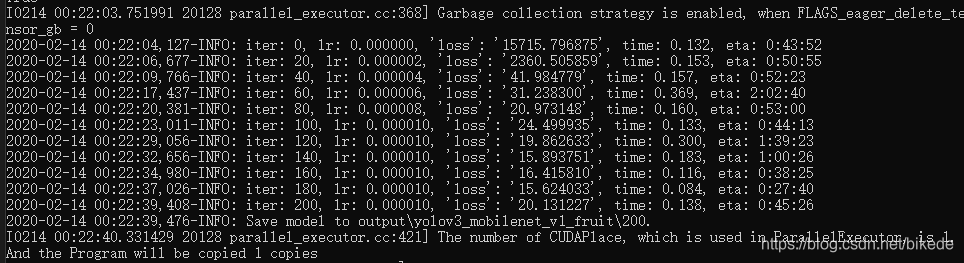
关于训练命令的阐述:
-c configs/yolov3_mobilenet_v1_fruit.yml 用来指定配置文件
–use_tb 是否使用tb-paddle记录数据,进而在TensorBoard中显示,默认值是False
–tb_log_dir 指定 tb-paddle 记录数据的存储路径
–eval 是否边训练边测试
备注:
关于–eval参数的使用:
在训练中交替执行评估, 评估在每个snapshot_iter时开始。每次评估后还会评出最佳mAP模型保存到best_model文件夹下,建议训练时候使用该参数,可以使得完成训练后快速找到最好的模型。
可选参数列表
以下列表可以通过 –help 查看
| FLAG | 支持脚本 | 用途 | 默认值 | 备注 |
|---|
| -c | ALL | 指定配置文件 | None | |
| -o | ALL | 设置配置文件里的参数内容 | None | 使用-o配置相较于-c选择的配置文件具有更高的优先级。例如:-o use_gpu=False max_iter=10000 |
| -r/–resume_checkpoint | train | 从某一检查点恢复训练 | None | -r output/faster_rcnn_r50_1x/10000 |
| –eval | train | 是否边训练边测试 | False | |
| –output_eval | train/eval | 编辑评测保存json路径 | 当前路径 | –output_eval ./json_result |
| –fp16 | train | 是否使用混合精度训练模式 | False | 需使用GPU训练 |
| –loss_scale | train | 设置混合精度训练模式中损失值的缩放比例 | 8.0 | 需先开启–fp16后使用 |
| –json_eval | eval | 是否通过已存在的bbox.json或者mask.json进行评估 | False | json文件路径在–output_eval中设置 |
| –output_dir | infer | 输出推断后可视化文件 | ./output | –output_dir output |
| –draw_threshold | infer 可视化时分数阈值 | 0.5 | –draw_threshold 0.7 | |
| –infer_dir | infer | 用于推断的图片文件夹路径 | None | |
| –infer_img | infer | 用于推断的图片路径 | None | 相较于–infer_dir具有更高优先级 |
| –use_tb | train/infer | 是否使用tb-paddle记录数据,进而在TensorBoard中显示 | False | |
Fine-tune其他任务
使用预训练模型fine-tune其他任务时,可采用如下两种方式:
- 在YAML配置文件中设置
finetune_exclude_pretrained_params - 在命令行中添加
-o finetune_exclude_pretrained_params对预训练模型进行选择性加载。







 当显示Successfully…… ,基本上表示安装完成了,具体是否成功,下一步的测试验证。
当显示Successfully…… ,基本上表示安装完成了,具体是否成功,下一步的测试验证。





























