


深度学习GPU环境配置及建模(Python)


对于深度学习开发者,操作系统的选择、到深度学习相关依赖包安装、环境配置上,这些步骤看似简单基础,但其实也经常有不少麻烦。本文简要梳理了从环境配置到深度学习建模的完整的流程,有所帮助的话,可以文末点个 。
操作系统的选择
1Linux
如果是深度学习的重度用户,首选的操作系统是Linux,虽然操作门槛高一些(如命令行操作),但Linux的开发环境很友好,可以减少很多依赖包不兼容的问题,可以大大提高效率。Linux的发行版很多,比较常用的的可以安装个包含图形界面及命令行的Ubuntu。
2Windows
如果要兼顾生活及开发,就笔记本上面看看视频、写写博客、跑跑代码(像我平时就是Ctrl+C ,再跑跑代码的),Windows就够了,操作简单而且上面的各种依赖包也很齐全。(下文主要以Windows系统为例展开介绍,其他系统也是大同小异,有不清楚地方可以找相应教程)。
3双系统的方案
如果既想要Linux做开发、Windows兼顾生活,可以借助安装双系统或者虚拟机,那么有几种选择:
3.1 安装双系统
硬件资源够的话,安装双个系统是比较直接的,能够比较纯粹地使用Windows或者Linux,但是切换比较麻烦,需要开关机来回切换。
3.2虚拟机
通过在虚拟机(如vmware)上面再安装另一个操作系统,这样打开虚拟机就可以很方便使用另一个系统了,但是缺点是虚拟机的硬件资源消耗也很高,而且有性能问题及各种bug。按我之前的尝试,这里更推荐Linux作为主系统+虚拟机的Windows,能更好发挥出Linux开发的效能。
3.3WSL
适用于 Linux 的 Windows 子系统 (WSL)是微软官方发布的应用,通俗来说它也就是Windows上面启用的Linux子系统。WSL安装非常简单,运行WSL的开销比运行一个虚拟机低很多,在WSL上面还可以配置cuda调用其GPU资源(但貌似配置复杂),用于日常学习是完全够用了。缺点是不如原Linux来得纯粹,用于高强度开发的话,性能会弱些,还容易卡各种bug。
WSL安装简单,在windows功能上打勾启用wsl功能后,
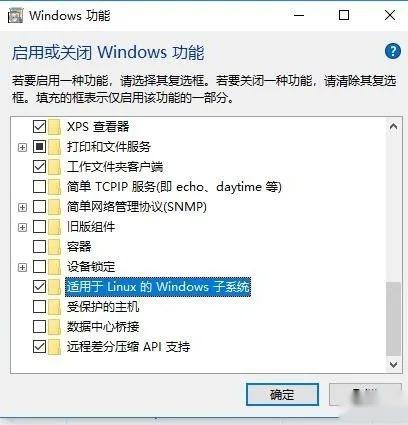
WIN+R运行cmd,一句命令行wsl --install就可以安装好ubuntu系统了,安装好后 WSL就可以使用Linux系统了(命令行cli版),
两个系统之间数据可以自由访问,如访问D盘数据只要 cd /mnt/d,双系统使用上是非常方便的。
可以参考WSL官方文档: https:// learn.microsoft.com/zh- cn/windows/wsl/install
Python环境配置
搞定操作系统(比如Windows),接下来配置个Python环境。实现Python环境配置及依赖包管理最方便的就是安装个 Anaconda,官网下载 https://www. anaconda.com/download ,
如果网速慢,也可以到清华镜像上面快速下载一个 https:// mirrors.tuna.tsinghua.edu.cn /anaconda/archive/
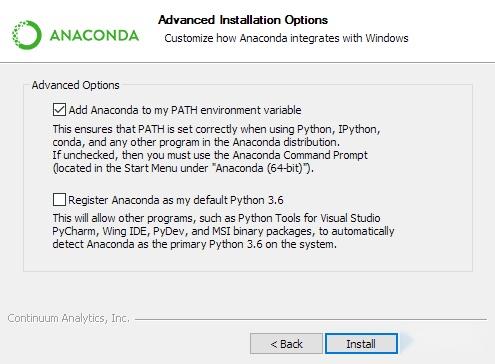
安装也很简单,一路确认就安装好了。这里可以勾选Add path 就可以配置好环境变量,也可以再勾选Anaconda作为默认Python版本,后面比较省心。
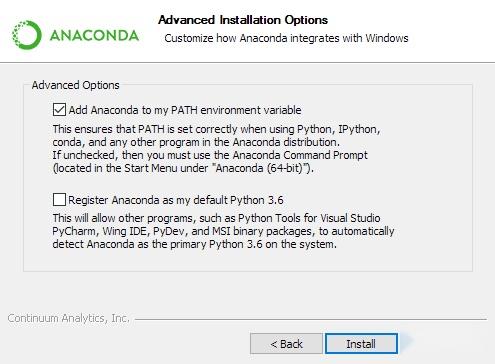
通过点击Jupyter Notebook就可以进入Python开发环境了,
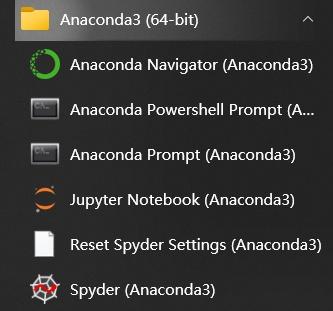
如果平时以小项目、数据分析、调调模型为主,Jupyter Notebook作为开发工具是够的。如果平时任务以大型项目居多,还可以再安装个IDE编辑器如VScode、Pycharm。
安装相关的库
这里有两种方案,如果只有CPU资源用于开发,直接选择【3.1 CPU环境配置】就可以很快开始深度学习建模。
如有GPU资源,可以选择【3.2 GPU环境配置】开始繁琐的安装配置及建模。
3.1 CPU环境配置
安装相关的python依赖包,主要的如数据处理库Pandas、机器学习库Scikit-learn、深度学习库Tensorflow、Pytorch等等。简单安装几个必要的包,后面运行项目代码,发现缺什么包再补什么。
可以点击prompt打开命令行安装,
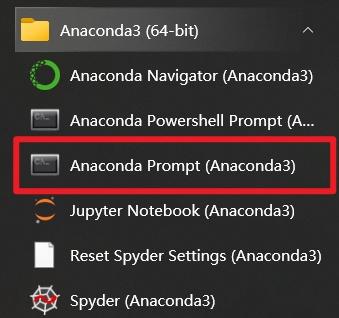
Python安装依赖也很简单,比如pip install tensorflow 就可以安装好Tensorflow神经网络库。
安装好相关的依赖包后,基本上就可以开始在CPU运算环境的深度学习、机器学习的代码开发了。
3.2 GPU环境配置
在大数据量、大模型炼丹的场景下,深度学习会耗费大量的算力及时间,这时可以用GPU来加速神经网络模型训练(唠叨一句,购置gpu首选大显存的!)。
如果硬件配置有nvdia的GPU的话(使用 AMD 的 GPU 也可行但很麻烦,相关信息可参阅: https:// rocmdocs.amd.com/en/lat est/ ),接下来就可以开始GPU开发环境cuda的配置,这个流程稍微繁琐容易出错,请耐心配置。
- 安装cuda
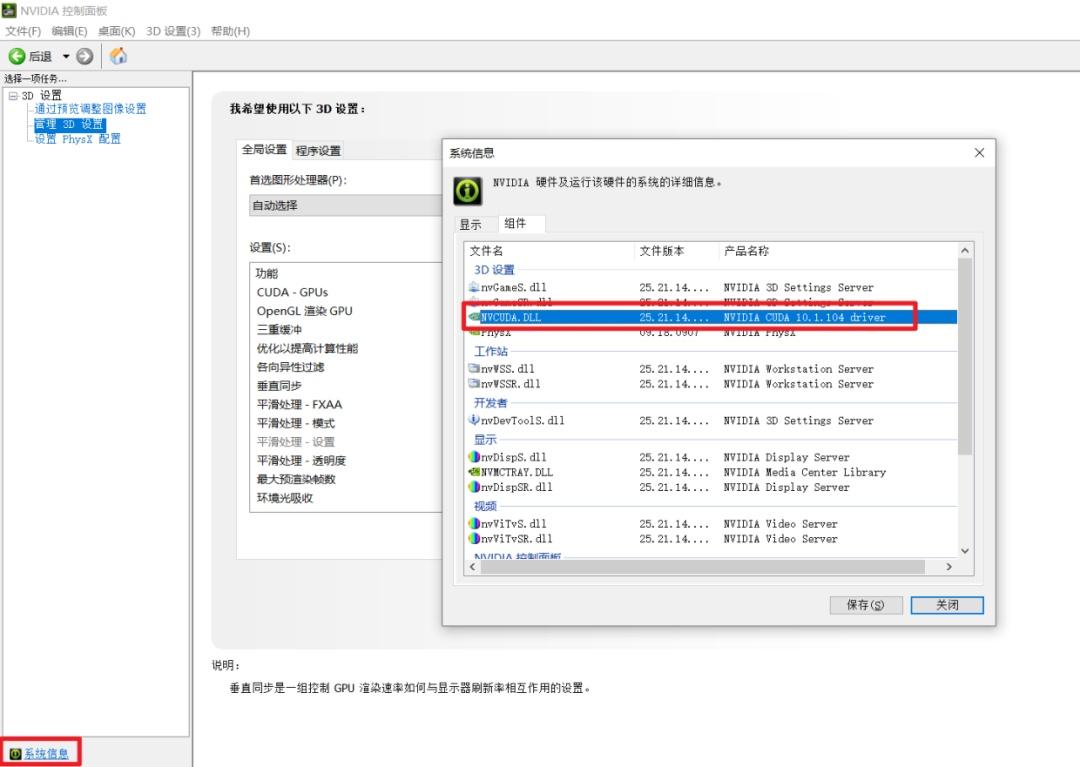
通过桌面鼠标右键进入nvdia的控制面板,看到显卡类型,可以看到我的游戏本有配了个独立显卡950M(算力仅仅为5,虽然这是GPU中的渣渣..但也比纯cpu香啊!),
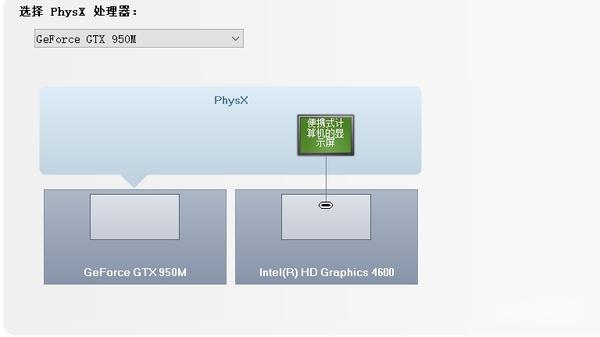
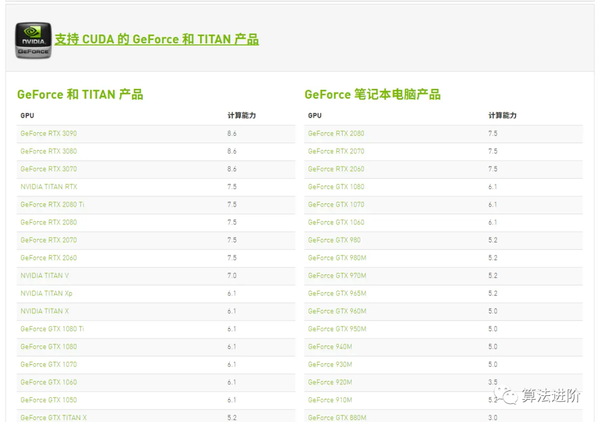
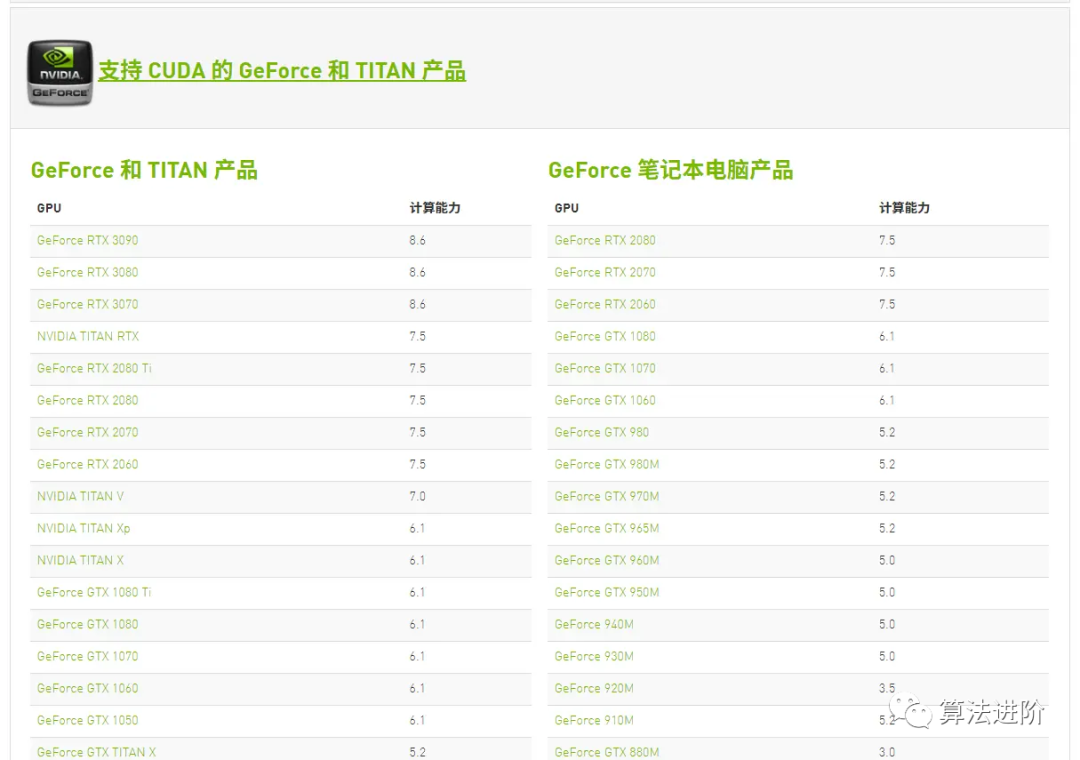
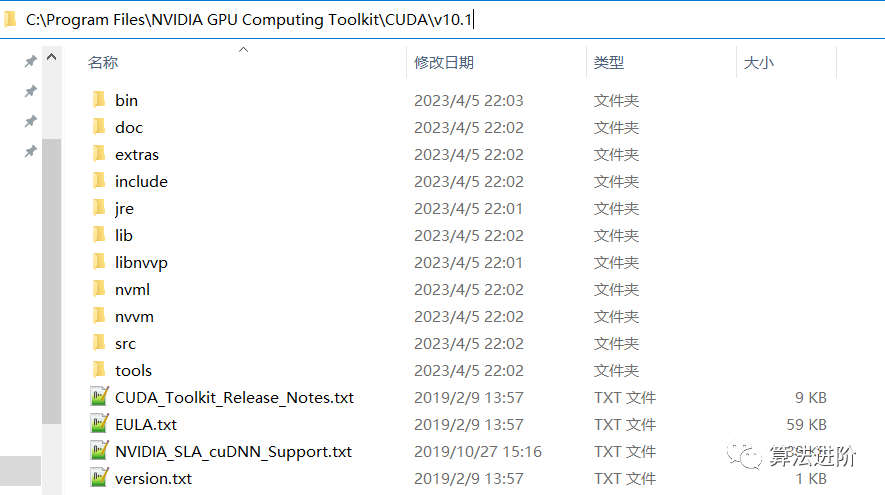
依据显卡算力我们可以知道对应支持的cuda版本号范围,像算力为5对应的cuda版本号就可以选择cuda-10.1
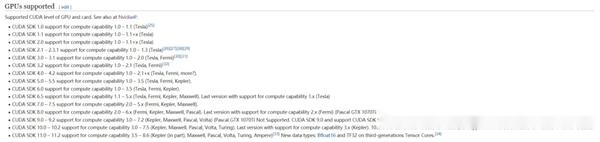
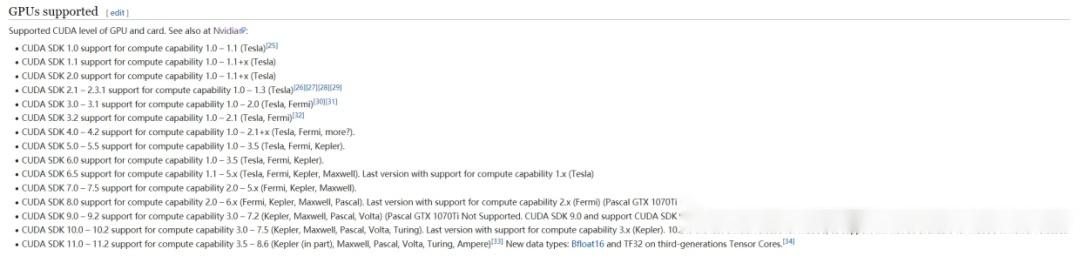
(好像也可以在nvdia控制面板的系统信息看到相关cuda的版本号)
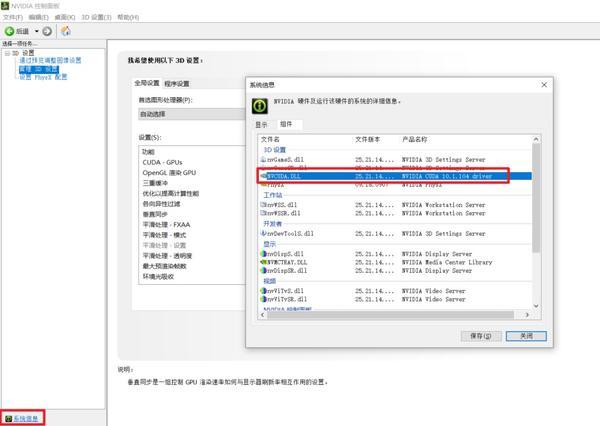
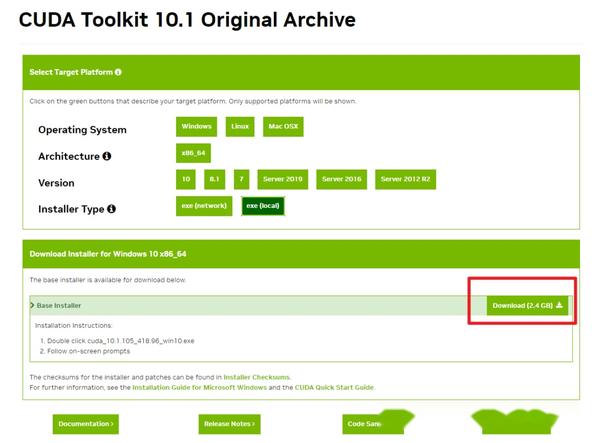
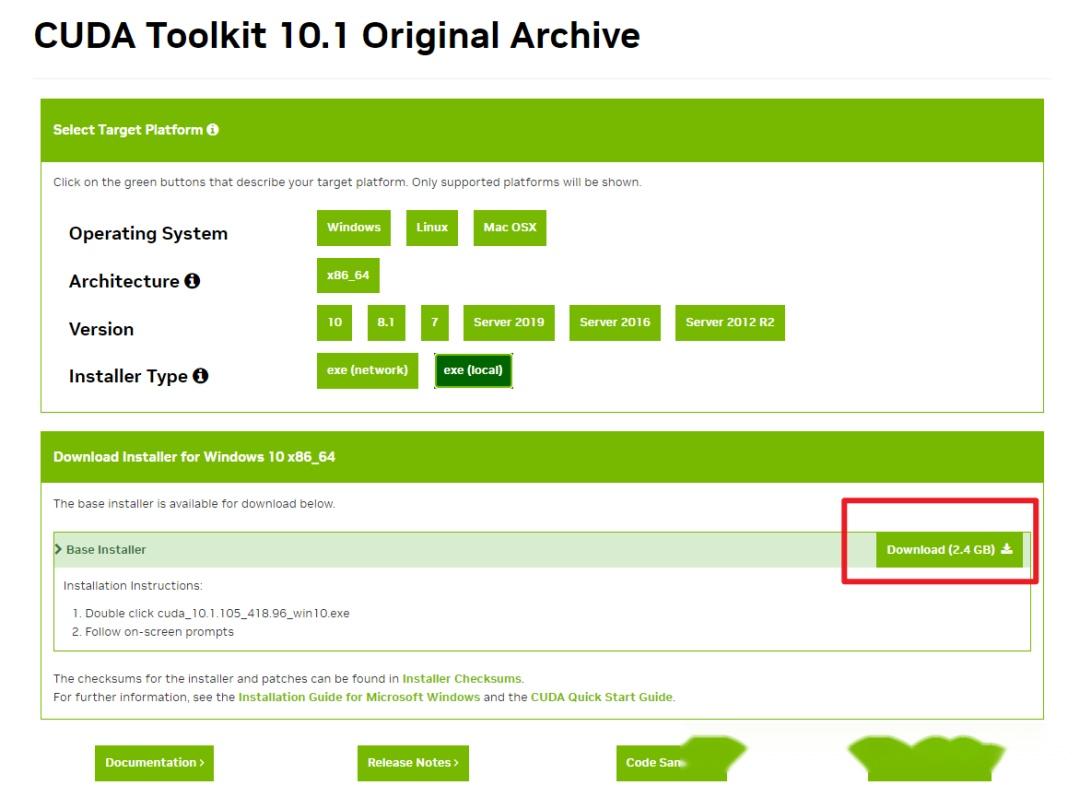
相应的,我们到官网下载相应版本的cuda, https:// developer.nvidia.com/cu da-toolkit-archive
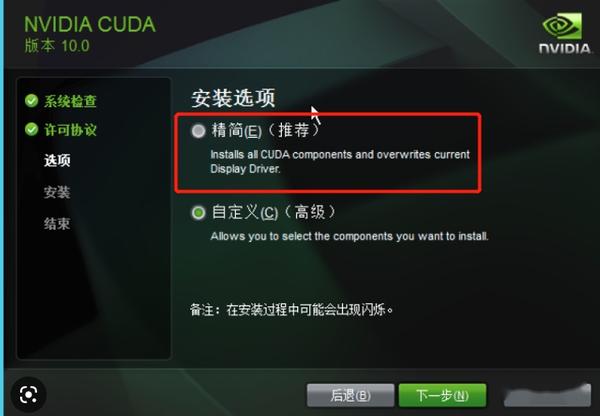
然后,运行cuda安装包,我直接精简安装,一路确认就安装好了。
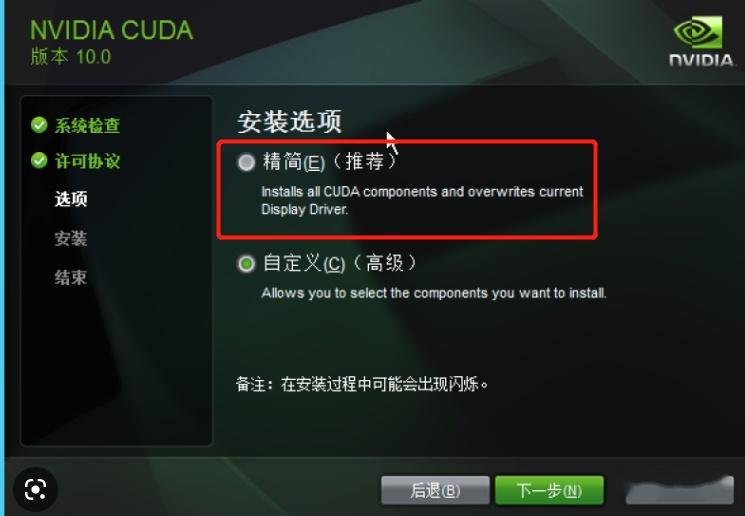
win+R 输入cmd,进入命令行界面:
输入以下指令:nvcc -V 能够正常显示版本号,cuda就安装好了
# $ nvcc -V# nvcc: NVIDIA (R) Cuda compiler driver# Copyright (c) 2005-2019 NVIDIA Corporation# Built on Fri_Feb__8_19:08:26_Pacific_Standard_Time_2019#Cudacompilationtools,release10.1,V10.1.105
- 安装cudnn
cuda安装完了还需要下载个cudnn(即 CUDA Deep Neural Network 软件库),这是一个 GPU 加速的深度神经网络基元库。不同版本的cuda 对应着不同的cudnn版本(我这边cuda10.1对应cudnn7.5的),详情可以从英伟达官网找到具体信息 https:// developer.nvidia.com/rd p/cudnn-archive ,下载cudnn还需要去英伟达官网注册。
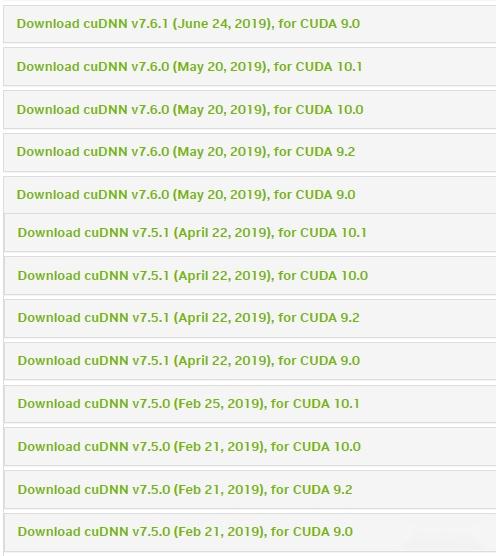
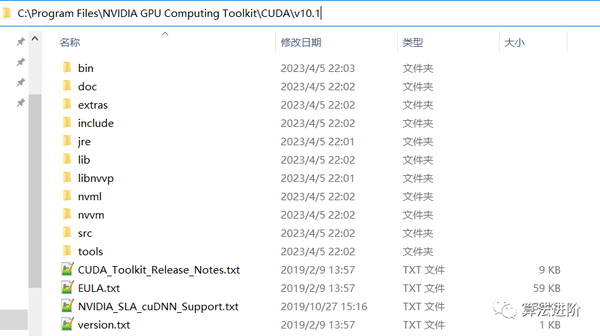
cudnn解压以后将各个子文件夹


拷贝到cuda安装目录下,到此,cuda整个环境就配置好了。
- Pytorch
最后,安装Python相关的(支持GPU)的深度学习库,本文建模用的是pytorch(tensorflow、keras等其他库也是可以的)
可以到官网下载相应的pytorch版本, https:// pytorch.org/get-started /locally/
官网会很友好地给出相应的所选的cuda版本对应的安装命令,
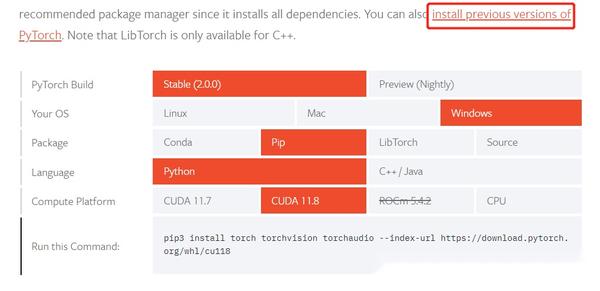
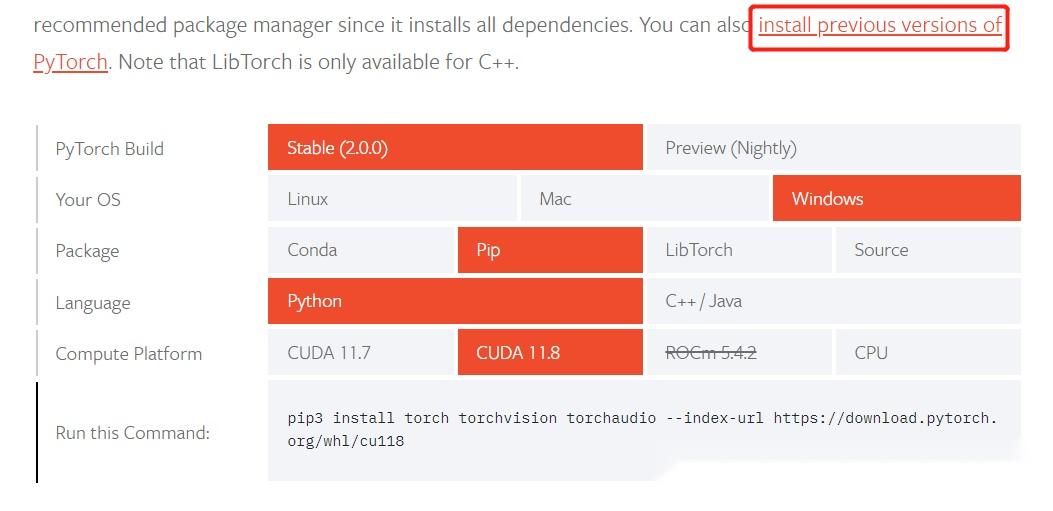
比如我这边cuda10.1对应的命令如下,在anaconda命令行输入就可以安装相关依赖包。
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=10.1 -c pytorch
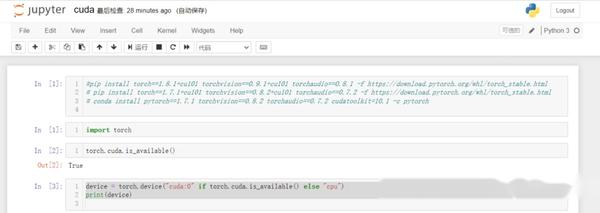
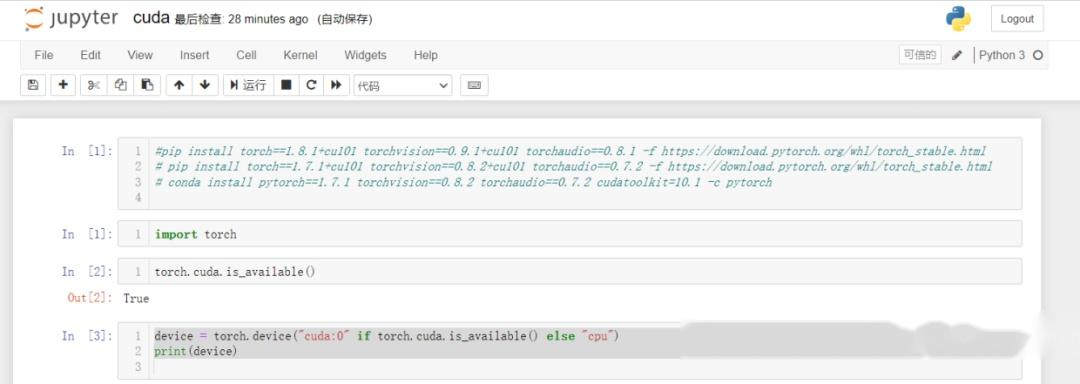
安装以后,可以检查GPU的可用性 ,通过调用torch.cuda.is_available()。如果结果为 True,则表明系统已正确安装Nvidia驱动。进入jupyter notebook运行:import torch torch.cuda.is_available()


四、 深度学习模型训练
本节的示例是调用GPU或CPU版的pytorch搭建深度学习图像分类模型(CNN),并对比下性能差异。详细的深度学习建模过程可以参考之前文章 《一文搞定深度学习建模》
%%timeimport torch,torchvisionimport torch.nn as nnimport torchvision.transforms as transforms## 项目源码可以到https://github.com/aialgorithm/Blog## 算法进阶公众号阅读原文也可跳转到源码 #定义CNN神经网络模型class CNNCifar(nn.Module):def __init__(self): super(CNNCifar,self).__init__() self.feature = nn.Sequential( nn.Conv2d(3,64,3,padding=2), nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(2,2), nn.Conv2d(64,128,3,padding=2), nn.BatchNorm2d(128), nn.ReLU(), nn.MaxPool2d(2,2), nn.Conv2d(128,256,3,padding=1),nn.BatchNorm2d(256), nn.ReLU(), nn.MaxPool2d(2,2), nn.Conv2d(256,512,3,padding=1),nn.BatchNorm2d(512), nn.ReLU(), nn.MaxPool2d(2,2) ) self.classifier=nn.Sequential( nn.Flatten(), nn.Linear(2048, 4096),nn.ReLU(),nn.Dropout(0.5), nn.Linear(4096,4096), nn.ReLU(),nn.Dropout(0.5), nn.Linear(4096,100) )def forward(self, x): x = self.feature(x) output = self.classifier(x)return outputnet = CNNCifar()print(net)#加载数据集apply_transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ])train_dataset = torchvision.datasets.CIFAR10(root='../data/cifar100', train=True, download=True,transform=apply_transform)test_dataset = torchvision.datasets.CIFAR10(root='../data/cifar100', train=False, download=True,transform=apply_transform)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, num_workers=2, pin_memory=True,shuffle=True)test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, num_workers=2, pin_memory=True,shuffle=False)#定义损失函数和优化器criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(net.parameters(), lr=0.001,weight_decay=5e-4)#获取设备:如果有gpu就使用gpu,否则使用cpudevice = torch.device('cuda'if torch.cuda.is_available() else 'cpu')net = net.to(device) # 简单通过.to(device), 数据或模型就可以转移至GPU#训练模型print('training on: ',device)def test(): net.eval() acc = 0.0 sum = 0.0 loss_sum = 0for batch, (data, target) in enumerate(test_loader): data, target = data.to(device), target.to(device) output = net(data) loss = criterion(output, target) acc+=torch.sum(torch.argmax(output,dim=1)==target).item() sum+=len(target) loss_sum+=loss.item() print('test acc: %.2f%%, loss: %.4f'%(100*acc/sum, loss_sum/(batch+1)))def train(): net.train() acc = 0.0 sum = 0.0 loss_sum = 0for batch, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = net(data) loss = criterion(output, target) loss.backward() optimizer.step() acc +=torch.sum(torch.argmax(output,dim=1)==target).item() sum+=len(target) loss_sum+=loss.item()if batch%200==0: print('\tbatch: %d, loss: %.4f'%(batch, loss.item())) print('train acc: %.2f%%, loss: %.4f'%(100*acc/sum, loss_sum/(batch+1)))## 开始训练模型for epoch in range(5): print('epoch: %d'%epoch) train() test()
可以通过device = torch.device('cuda'if torch.cuda.is_available() else 'cpu')分别修改相应的运算设备gpu或者cpu, 对比使用cpu、gpu资源占用的变化:
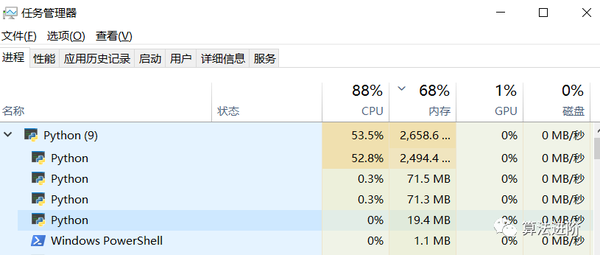
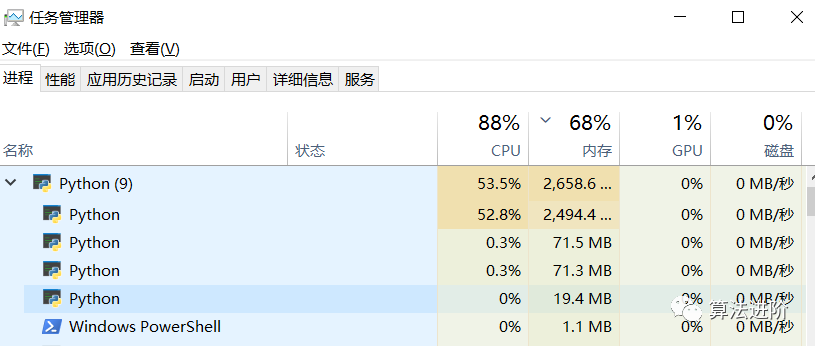
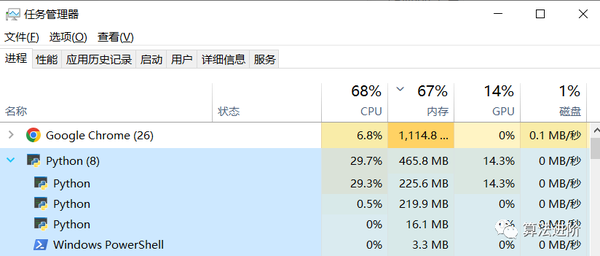
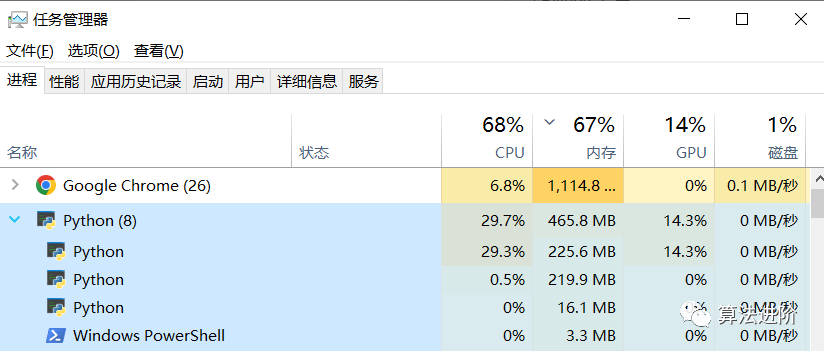
同一超参数下模型预测效果上面来看两者差不多,但运行时间CPU是GPU的5倍左右,GPU对深度学习训练的效率提升还是很明显的!
###################training on: cpuepoch: 0batch: 0, loss: 4.5887batch: 200, loss: 1.5186batch: 400, loss: 1.3614batch: 600, loss: 1.2306train acc: 42.96%, loss: 1.5834test acc: 54.61%, loss: 1.2249# 耗时Wall time: 18min 27s###################training on: cudaepoch: 0batch: 0, loss: 4.6759batch: 200, loss: 1.5816batch: 400, loss: 1.6414batch: 600, loss: 1.2504train acc: 43.72%, loss: 1.5647test acc: 53.02%, loss: 1.2784# 耗时 Wall time: 3min 22s