


利用Kettle进行数据同步(上)

写这篇文章,是源于公司内部的一个常见需求:将生产环境的数据同步到测试环境,以便更方便的进行测试和bug定位。
起初是用的Navicat Premium这款DB管理软件,功能非常强大了,足以满足开发人员的日常工作需求,也包括上述的数据同步需求。
随着公司业务日臻完善,对于数据的安全性提出了更为严格的要求。
实际上,是不允许将任何环境的数据同步至生产环境的,即是生产环境的数据是错误的。Navicat Premium有数据传输这一功能,能够将一个数据库传输并覆盖到另外一个数据库,没有任何限制。
此外,为了避免开发人员直接接触到生产数据库,笔者将高权限的账号都收回了,只授予其只读权限,保留了数据查看的能力。若是如此,那么数据同步的工作压力就指向了笔者。
为了寻求更为方便、稳定的方式去完成这个数据同步的工作,笔者把思路聚焦在了 ETL 工具上了。
如果仅仅是为了完成数据同步的功能需求,把ETL的概念拿出来未免显得有些班门弄斧了。考虑到以后还会有数据处理方面的需求,研究一款ETL工具势在必行(在写此篇文章的时候,就出现了一个导出Excel的功能需求)。
理论上,日常内部的ETL需求都可以通过“代码 + 脚本”的方式实现。但是,在笔者看来都是无意义的重复造轮子,耗时耗力,如果能掌握一款ETL工具,无疑能减轻不少的工作量。
当然,市面上的ETL工具也不在少数,国内外的企业都有成品,但是本着开源免费,强大好用的原则,最终就只剩下 kettle 了。
使用kettle之前,还是需要有一些基础知识背景。说直白点,如果给不懂技术的PM使用,都将会以一句“mmp”结束。全面学习kettle是没有必要的,但是应该知道它能有哪些功能,大致能完成哪些工作,以便今后充分利用之。推荐阅读如下文章:
ETL的过程就是一条工作流,以下是此次要实现的数据同步流程:
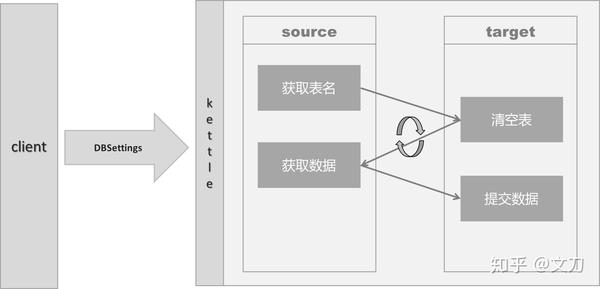

客户端填充两方数据库的设置信息,如:host、user、password、database等,这些设置信息都将以variable的形式存在于kettle中。
因为指定的database中可能有多张表,所以在kettle内部中,循环的执行获取数据,清空表,提交数据的流程。
当然,流程之间还是有些细节的,下面将讲解如何用kettle搭建数据库同步的工程。
此工程中的作业(Job)和转换(Transformation)有嵌套关系,本着“自顶向下的设计,自底向上的实现”的原则,我们先将几个子流程都配置好,再进行相关的串联。
新建一个转换,保存命名为“ 提交数据.ktr ”。
准备两个数据库连接,主对象树->右键DB连接->新建。
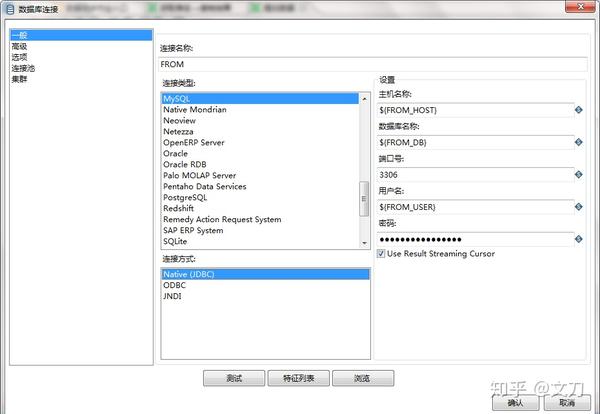

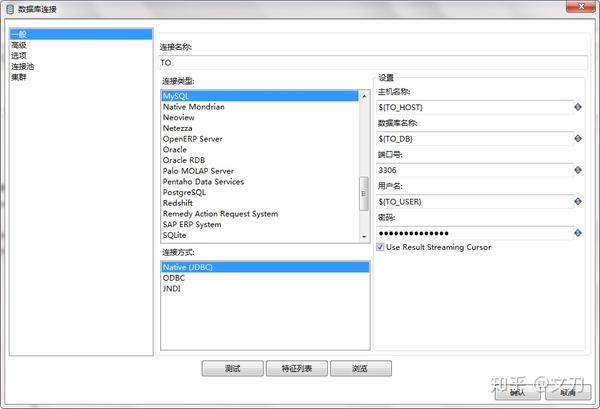

可以看到,已经预留了DB相关的variable,使用${variable}的形式。
特别说明:密码也是按照了这种形式填写,kettle也能识别这是一个variable。
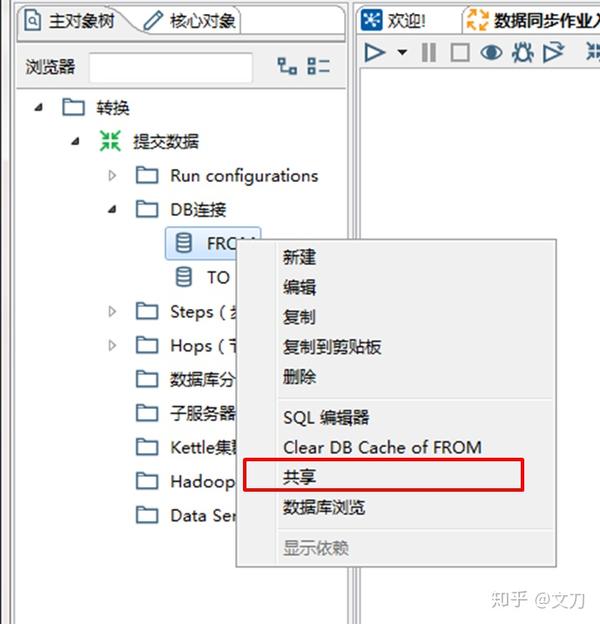
因为其他作业和转换都用到了这两个DB连接,可以将其设置成共享。

新建Transformation,保存命名为“ 数据同步.ktr ”。
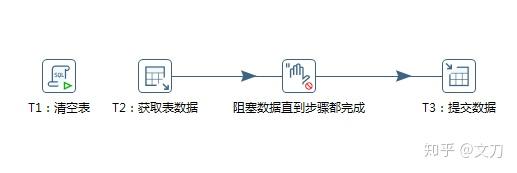

T1:清空表。核心对象->脚本->执行SQL脚本。要清空的表名使用variable代替了,勾选“变量替换”的CheckBox。
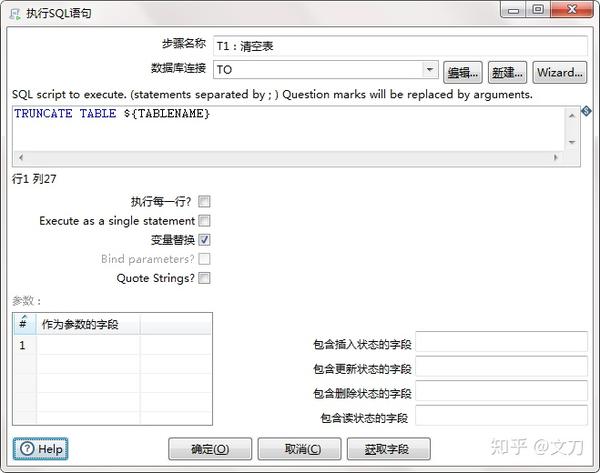

T2:获取表数据。核心对象->输入->表输入。获取表里的全部数据,选择数据来源,表名使用variable代替了,勾选“替换SQL语句的替换”的CheckBox。

T3:提交数据。核心对象->输入->表输出。选择数据库连接,目标表使用variable代替,提交记录数量指的是一次commit的数据量,视实际的数据量情况而定,默认是1000条,并且建议勾选“使用批量插入”。


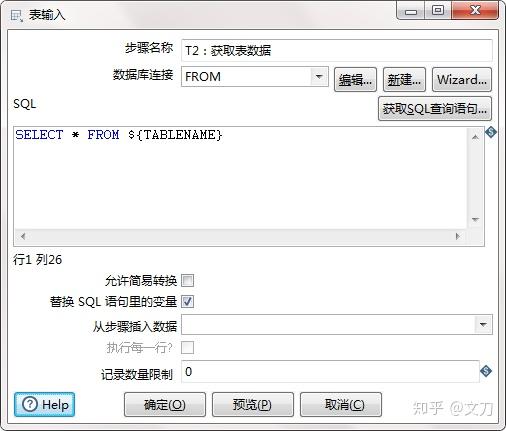
因为需要确保清空表的操作先完成,所以做了一步阻塞。也就是不完成了T1:清空表的步骤,就不会进行T3:提交数据的步骤。
核心对象->流程->阻塞数据直到步骤都完成。
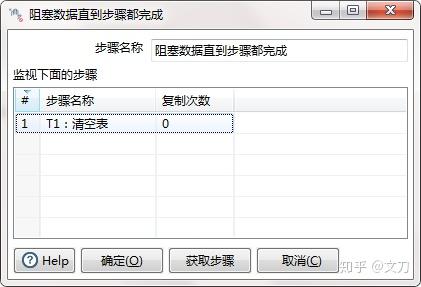

再按住shift键,将各个步骤连接起来,提交数据的Transformation就完成了。
接下来是获取表名的Transformation:
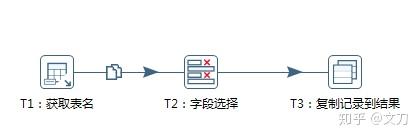
新建Transformation,保存命名为“ 获取全量表名.ktr ”。
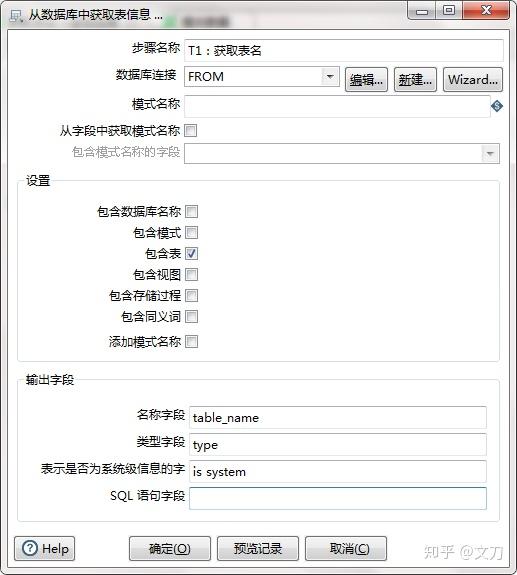
T1:获取表名,核心对象->输入->获取表名,选择数据库连接,勾选“包含表”即可,名称字段可以自定义,这里设置的是table_name。

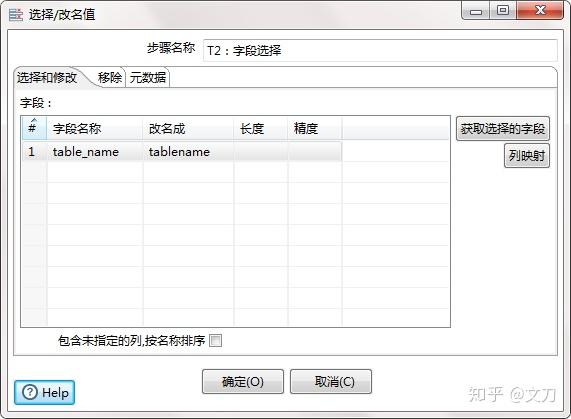
T2:选择字段,核心对象->转换->字段选择。主要是指定需要的字段,显然我们需要table_name字段,也可以自定义改名,这里改名成tablename。

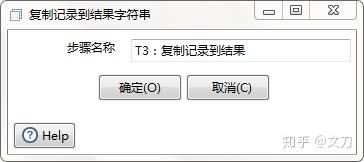
T3:复制记录到结果,核心对象->作业->复制记录到结果。主要是作为下一个步骤的输入。
再按住shift键,将各个步骤连接起来,获取表名的Transformation就完成了。
接下来是一个中间的转换过程,就是取出表名,然后设置到指定的变量中,以便提交数据的时候获取${TABLENAME}。
新建转换,保存命名为“ 获取变量.ktr ”。
T1:获取表名变量值,核心对象->作业->从结果获取记录,指定要获取的字段名称是tablename,就是上述获取表名改名成的tablename。
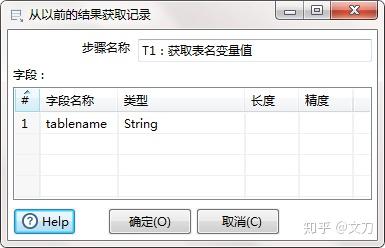
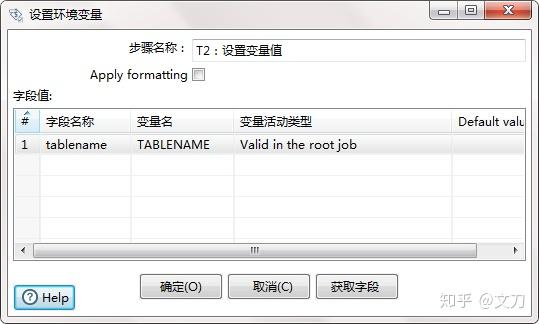
T2:设置变量值,核心对象->作业->设置变量,设置TABLENAME变量,选择变量作用范围“Valid in the root job”。

至此,所有的Transformation都完成了,需要通过Job来连接Transformation了。
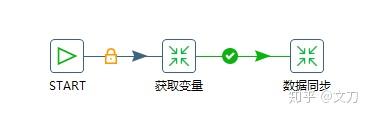
新建Job,保存命名为“ 获取变量-数据同步.kjb ”,分别在核心对象中添加一个START,和两个转换,两个转换分别对应了上述已经准备好的“ 获取变量.ktr ”和“ 数据同步.ktr ”,连接起来即可。
接下来是最后一个Job,新建Job,保存命名为“entrypoint.kjb”。添加一个START,一个转换,一个作业和一个成功结束节点。
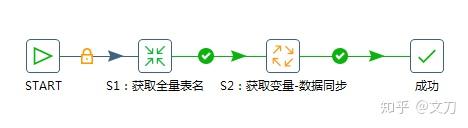

获取全量表名返回的结果是一个列表,所以“ 获取变量-数据同步 ”作业需要循环执行。在设置作业的时候,勾选“ 执行每一个输入行 ”。
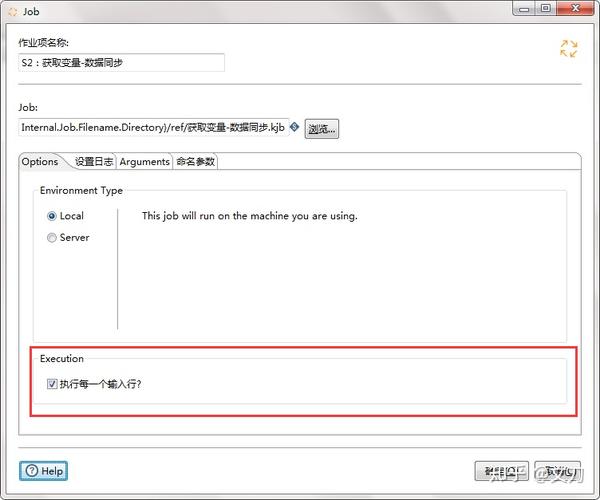

至此,整个数据同步的工程已经搭建好了,即可运行entrypoint.kjb。在运行的时候,需要设置数据库的相关参数。
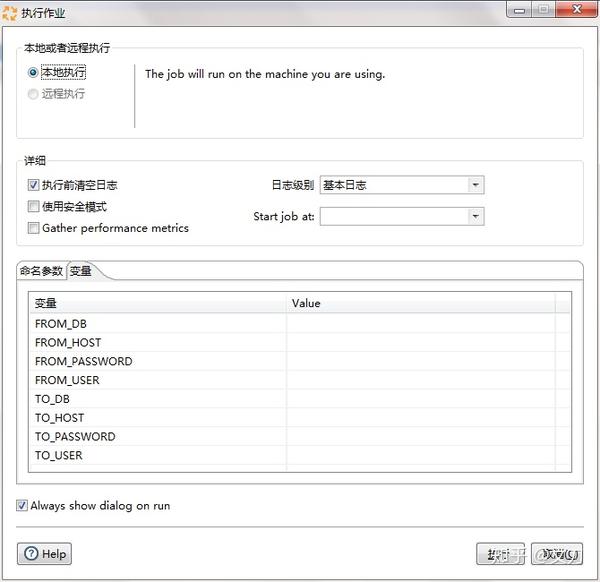

做到这一步,还是不够的,每次执行作业还需要输入这么多参数,还有可能会出现失误。
kettle的强大之处就是还提供了Java API,可以基于此,做更高层次的抽象,使操作成本进一步降低。
下篇将讲解如何实现一个基于kettle的数据同步系统。
