


R语言之字符函数和正则表达式

字符串长度函数:
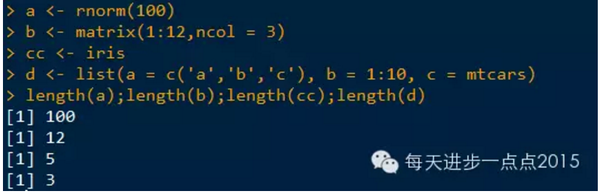
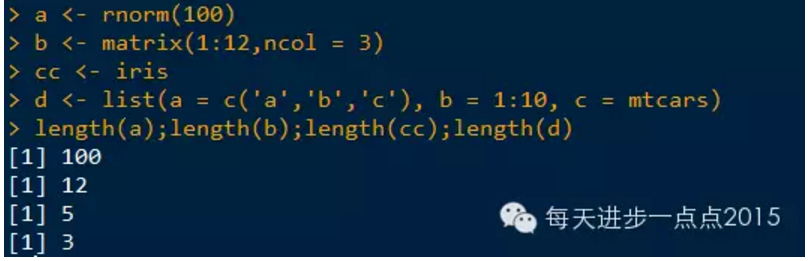
length():返回向量元素的个数、矩阵元素的个数、数据框字段数量和列表元素的个数。
nchar()
:
返回每一个字符值的字符数


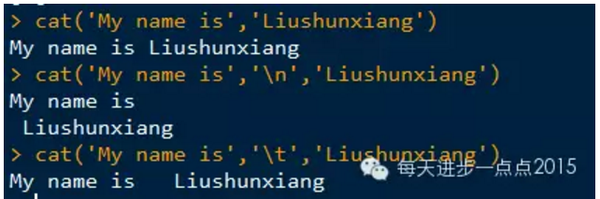
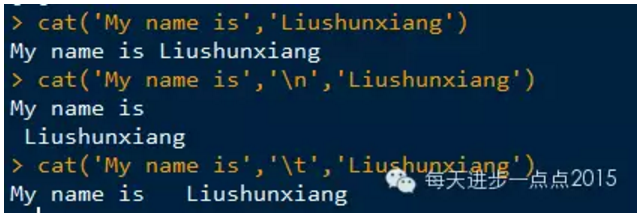
cat()函数可以显示和连接字符串。该函数可以将字符值合并,并直接打印在屏幕中,
该函数成为在函数内部打印消息或警告信息的理想函数,而paste()函数和print()函数输出效果不理想。
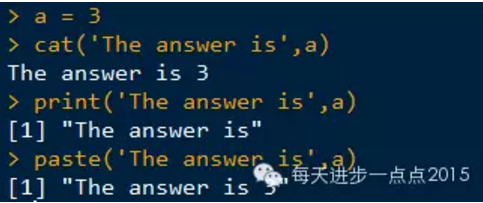
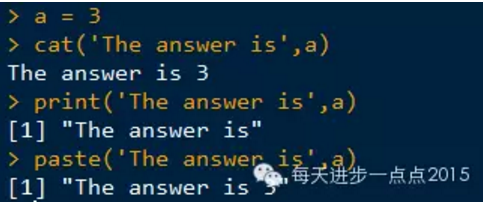
发现,用print函数和paste函数在屏幕中输出带引号的字符串,总觉得有点别扭。
cat()函数中使用'\n'参数为换行符,确保改行的完整信息。'\t'为4字节的空格
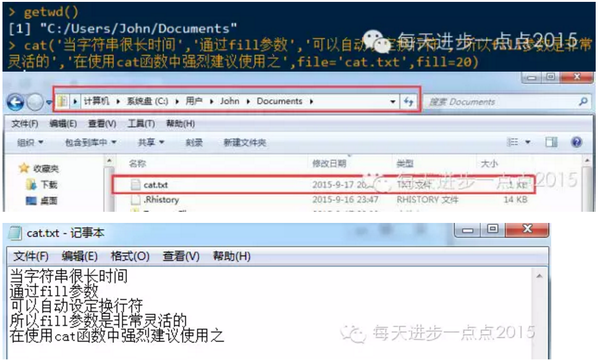
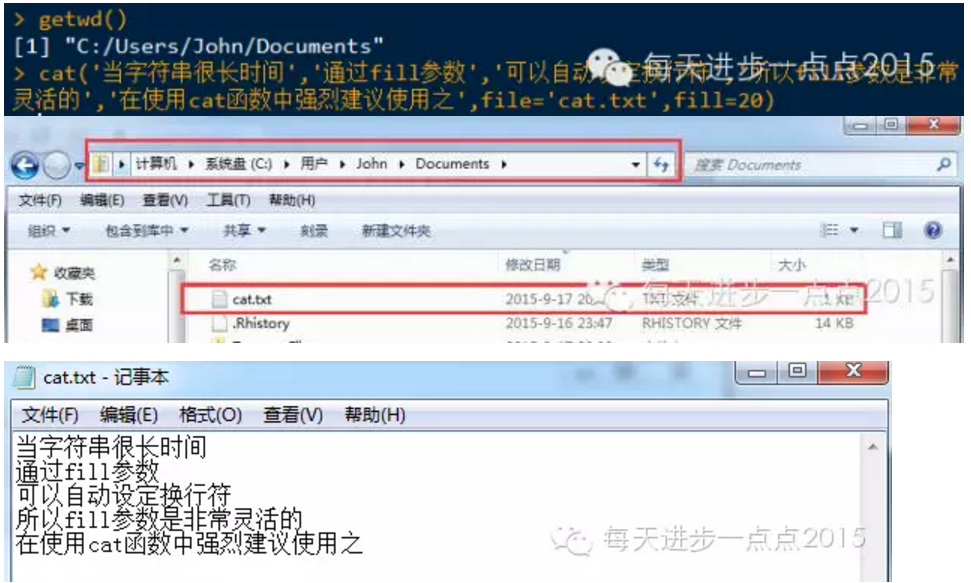
cat()函数的参数fill可用于输出字符串中自动插入换行符,如果fill设置为TRUE,则系统的width值将被用来确定行宽,
如果fill参数为一个给定的数值,则输出结果的宽度将使用该值。


cat()函数中有一个参数为file,该参数允许输出结果指定到一个文件中。
paste()函数可以无限量的连接字符串,当把一个字符向量传递给paste()函数时,通常使用collapse=参数,因为sep=参数对输入的向量不起作用


substring()或substr()函数获取字符串的子串,first(start)和last(stop)参数可以是一个数值,也可以是一个向量。
在应用中强烈建议使用substring()函数,该函数更为稳定
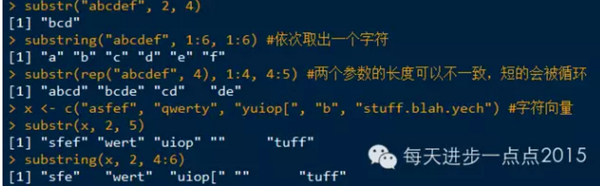
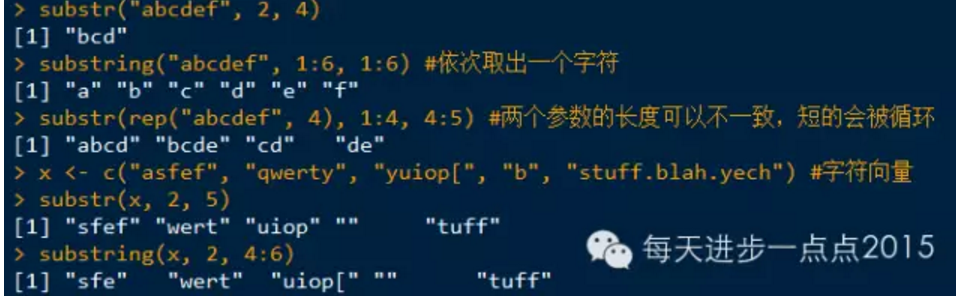
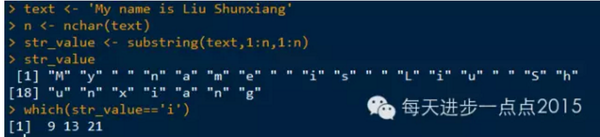
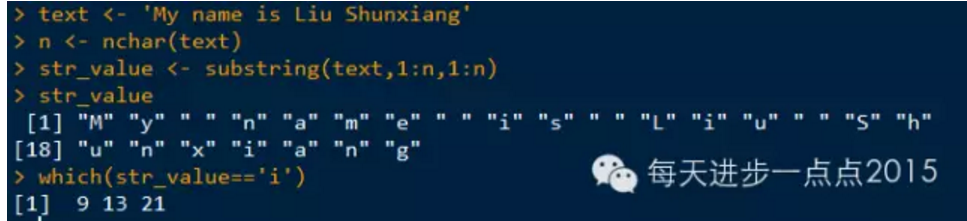
为了找到字符串中一个特定字符的位置,首先需要将字符串转换为字符向量(可以向substr函数的first和last参数传递向量来完成),然后通过which函数确定某个字符的位置
。
正则表达式是一种表达字符值模式的方法,可以被用来提取字符串的一部分或以某种方式修改这些字符串。这里主要讲解R中常用的6个正则表达式函数(split,grep,regexpr,gregexpr,sub,gsub)
strsplit()函数可以使用字符串或正则表达式将字符串划分为更小的段,该函数的第一个参数是要拆分的字符串,第二个参数是用来将字符串分解成多个部分的字符值或正则表达式。该函数将分解后的子段返回到列表中。
语法如下:
strsplit(x, split, fixed = FALSE, perl = FALSE, useBytes = FALSE)
应用:
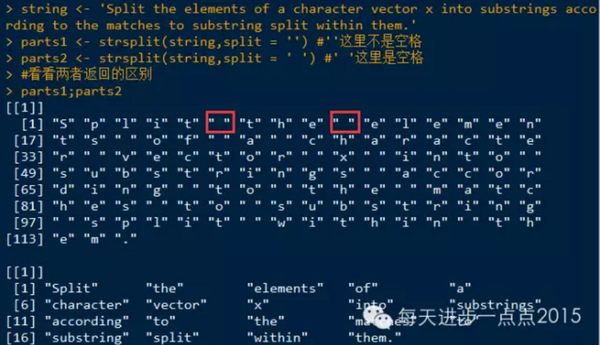
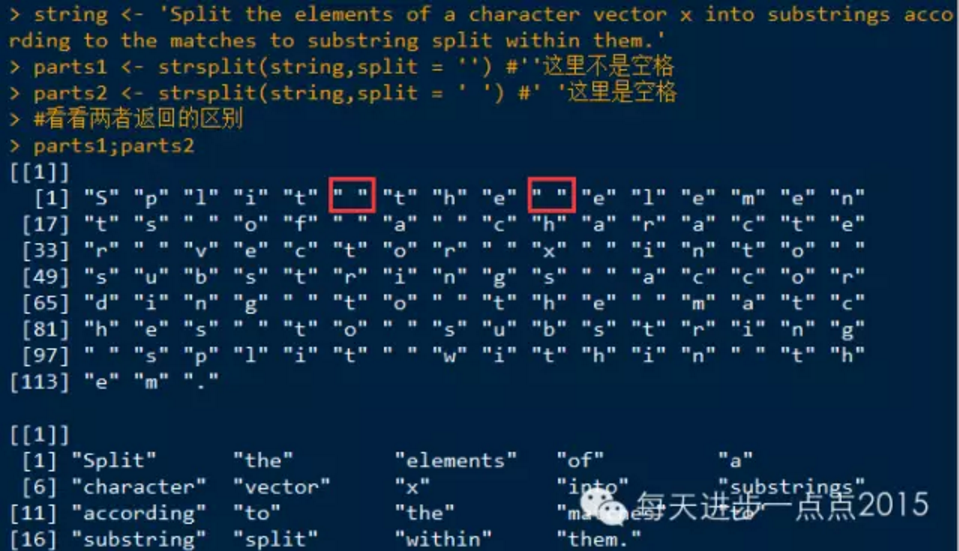
发现,parts1中会单独把空格当做值列出来。
案例,把数据框中的邮箱子段拆分成邮箱名和邮箱地址两个字段。
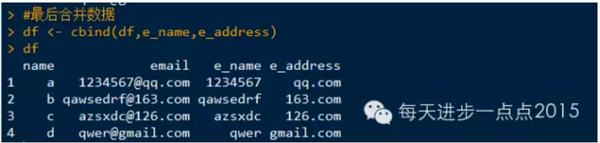
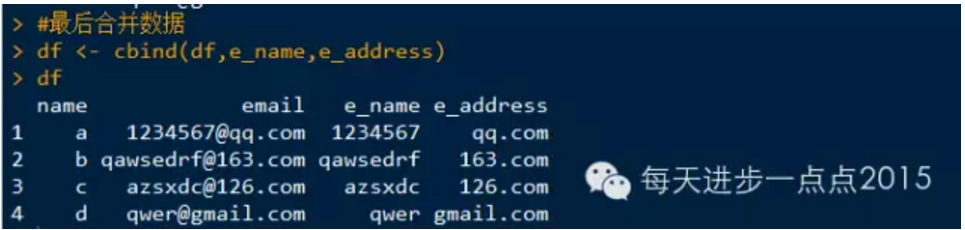
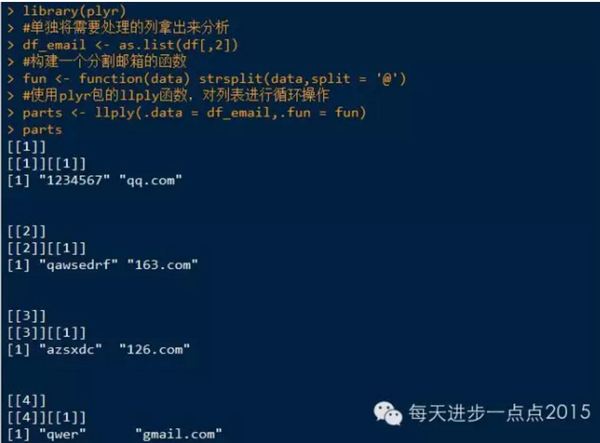
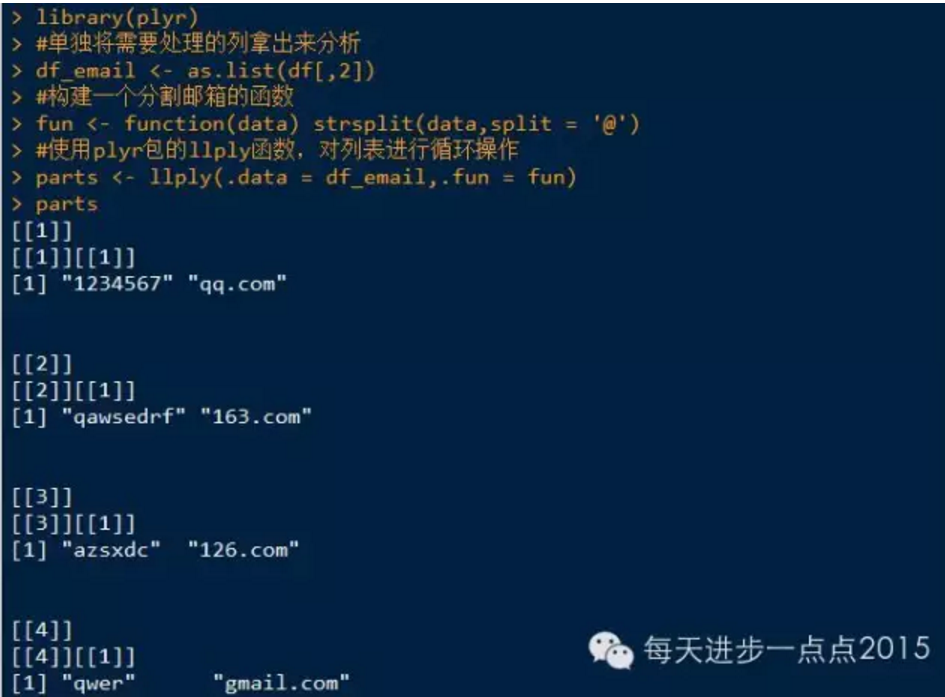
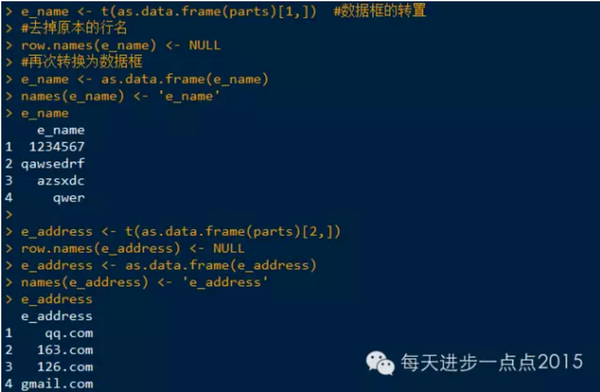
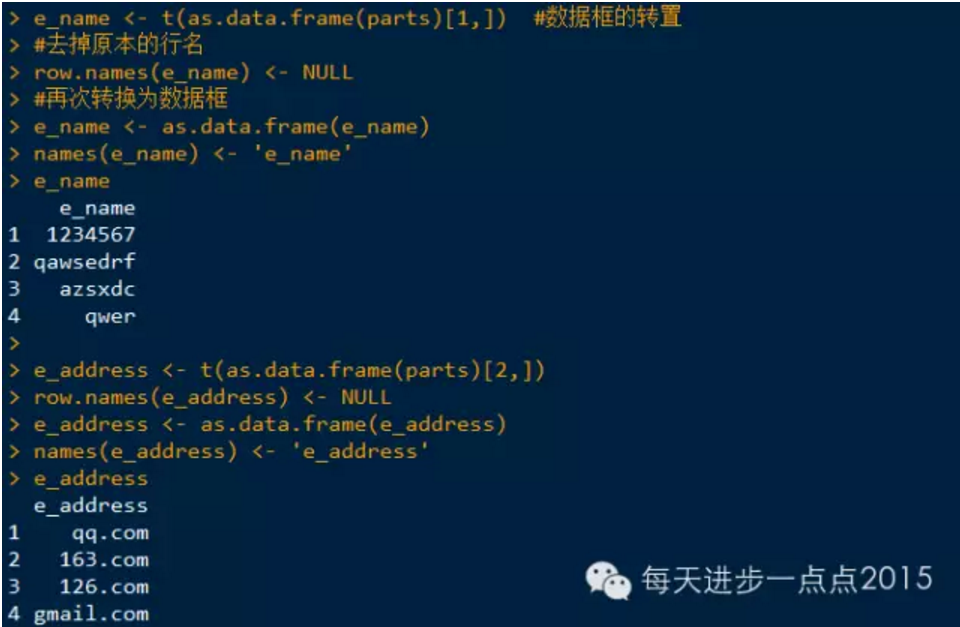
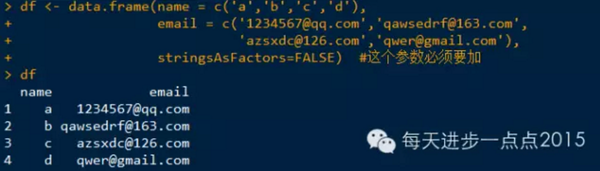
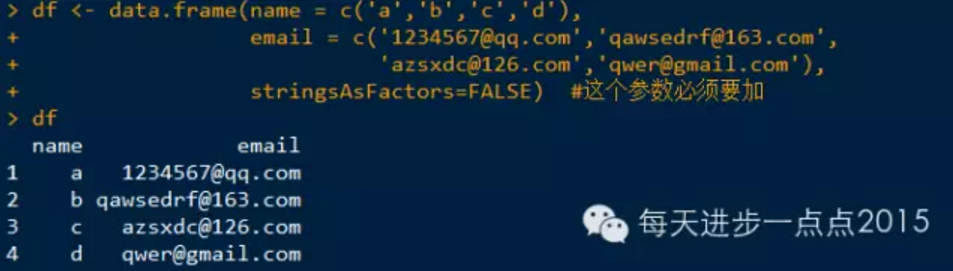
个人觉得这个方法还是繁琐了点,还请各位看官提出更方便简洁的方法~谢谢啦。
strsplit()函数还可以接受正则表达式来决定在哪里拆分字符串,例如,一个字符串中含有多个空格,当使用空格作为拆分符时,就可能返回多余的空字符串 。
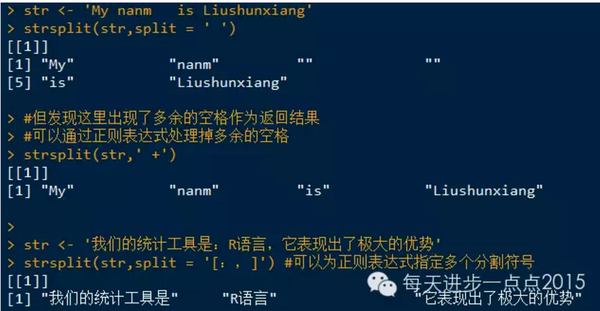
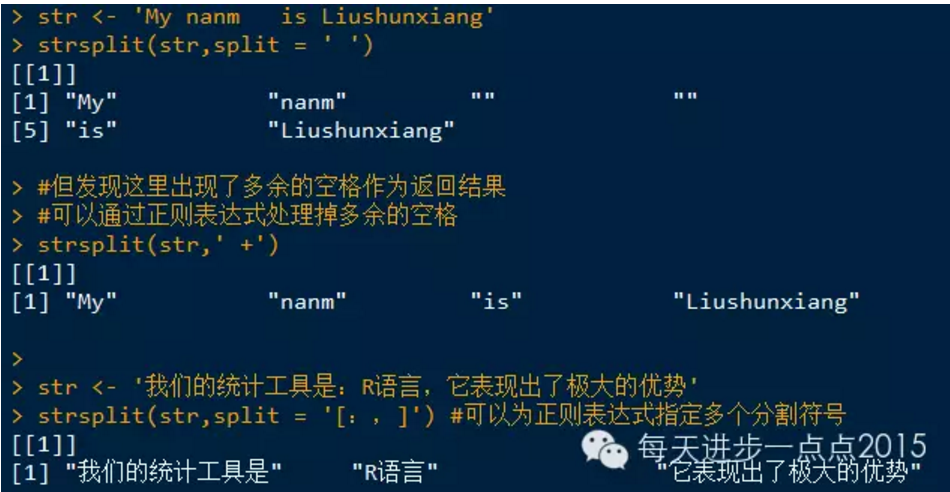
grep()函数接受一个正则表达式和一个字符串或字符串向量,并返回由正则表达式匹配的字符串元素的索引。 如果参数value=TRUE,则它将返回与正则表达式匹配的实际字符串而不是其索引号。
语法如下:其中x必须为字符向量
grep(pattern, x, ignore.case = FALSE, perl = FALSE, value = FALSE,fixed = FALSE, useBytes = FALSE, invert = FALSE)
应用:该函数的一个重要用途是依据名称从一个数据框中提取一组变量
如在LifeCycleSavings数据框中,存在两个变量,都是以'pop'开头,我们可以使用grep函数找到这两个变量
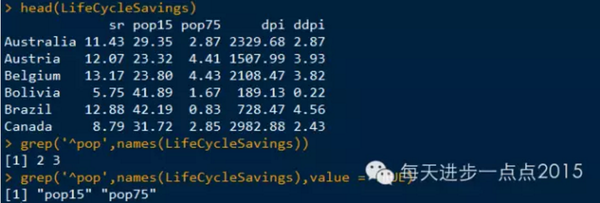
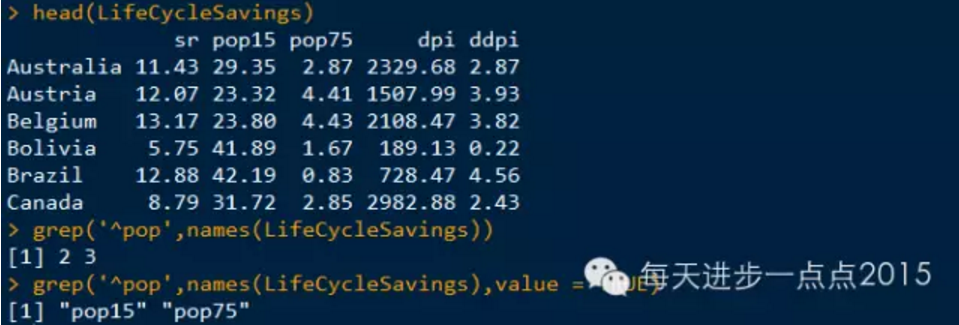






如果传递给grep的正则表达式与其任何输入都不匹配,grep将返回一个空的数值型向量, 换句话说,该函数可以用来测试一个正则表达式是否存在。
regexpr()和gregexpr()函数可用于准确指出和提取字符串中与正则表达式相匹配的部分,这两个函数的输出为一个向量和列表,由所发现的正则表达式的起始点组成;如果没有匹配发生,返回值为-1,此外,match.length属性与起始点向量结合, 提供字符匹配的准确信息。regexpr函数只提供其输入字符串中第一个匹配的有关信息,而gregexpr函数返回所有匹配的信息。
语法如下:
regexpr(pattern, text, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
gregexpr(pattern, text, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
应用:
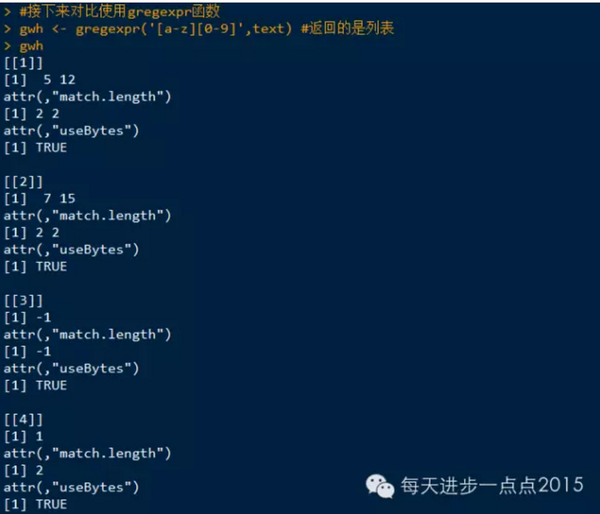
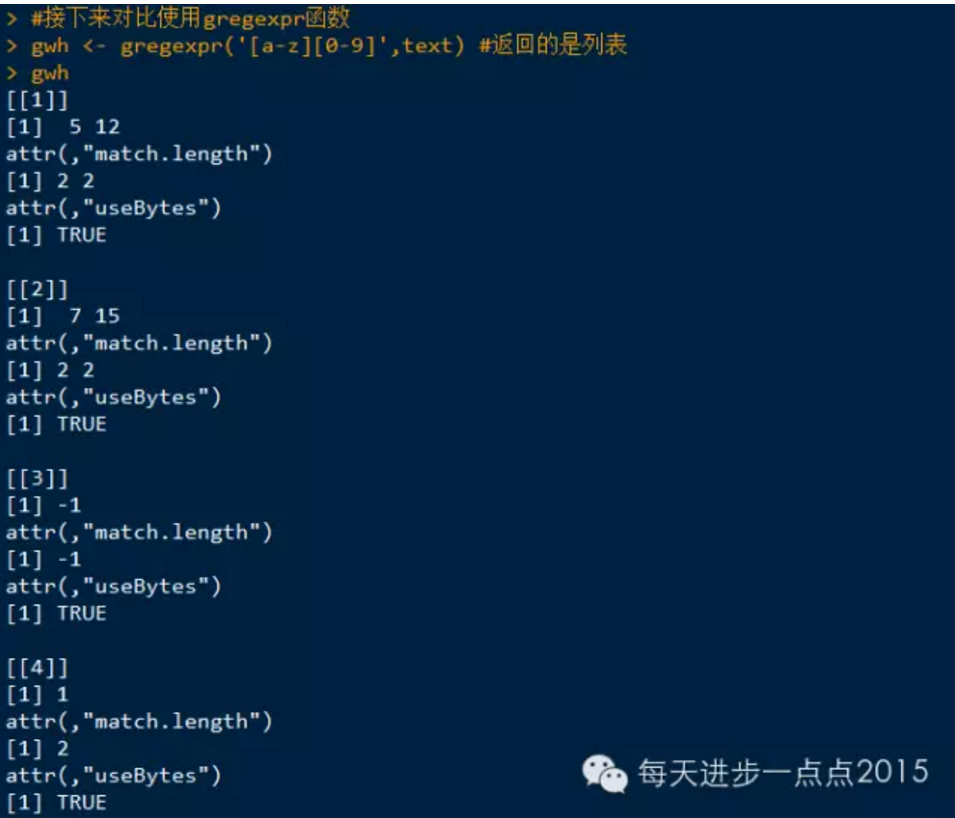
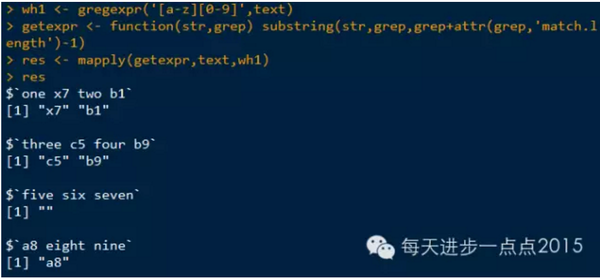
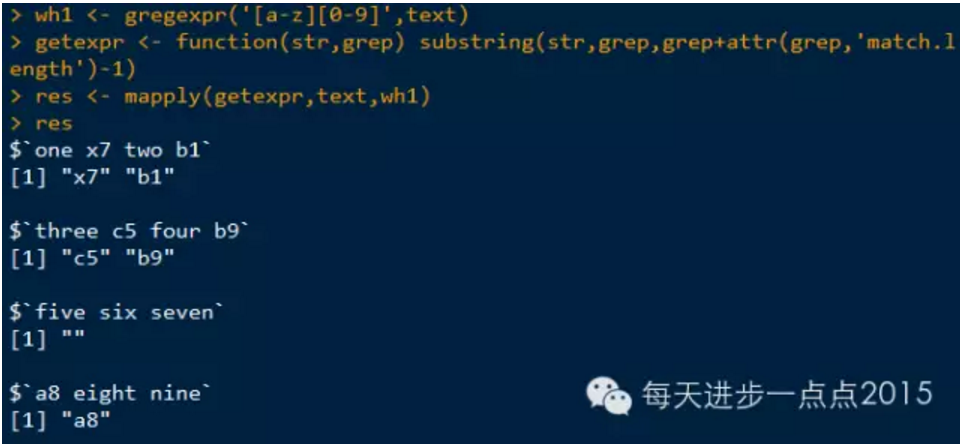
提取出匹配的字符
在这里使用另一个处理输出的函数mapply,该函数的第一个参数为函数, 接受多个参数,其余参数是长度相同的向量,其元素将逐一传递到函数中。
sub()和gsub()函数是基于正则表达式的文字替换,它们均接受正则表达式的输入参数。
sub()函数只改变第一次出现的正则表达式,而gsub()函数可以替换所有满足正则表达式的字符。
这两个函数的一个重要用途涉及到数值型数据中,这些数据从网页或财务报表中读入,并可能包含逗号或美元符号。
语法:
sub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
gsub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,fixed = FALSE, useBytes = FALSE)
应用:


大致正则表达式的语法和案例就介绍到这里,接下来对正则表达式做一些总结性的工作 (参考《R语言数据操作》这本书):
1、反斜杠\字符用在正则表达式中,表示正则表达式中某些具体特殊含义的字符应该作为普通的字符来对待。在R中,当遇到特殊字符时(\t,\n等)需要输入两个反斜杠。
2、正则表达式由3个部分组成:
a、原意符,它是由一个单一的字符匹配
b、字符类,它可以与许多字符值的任何一个相匹配
c、修正符,对原意符和字符类进行操作
3、由于许多表点符号是正则表达式的修正符,必须始终加一个反斜杠保留其原意:
. ^ $ + ? * ( ) [ ] { } | \
4、要形成一个字符类,使用方括号[]把需要匹配的字符括起来。如需要创建一个由a,b或3组成的字符类,可用[ab3]表示。破折号可用在字符类内部来表示值域[a-z],[A-Z],[0-9]
5、如果在R中输入一个正则表达式,是使用双引号的字符串,就需要双反斜杠,如果使用readline输入表达式,只需要一个反斜杠。
6、R中正则表达式的修正符:
修正符 含义
^ 定位表达式,目标开始
$ 定位表达式,目标结束
. 匹配换行符以外的任何单个字符
| 分割不同的模式
( ) 将相同模式放在一起
* 匹配前面的实体出现0次或更多次
? 匹配前面的实体出现0次或1次
+ 匹配前面的实体出现1次或更多次
{n} 匹配前面的实体精确地出现n次
{n,} 匹配前面的实体至少出现n次
{n.m} 匹配出现次数在n和m次之间
总结:常用的字符串函数
length()
nchar()
cat()
paste()
substring()
strsplit()
grep()
regexpr()
gregexpr()
sub()
gsub()
作者:刘顺祥
公众号:每天进步一点点
博客专栏:
每天进步一点点2015友情提醒: 本周四晚上8点半, 刘顺祥老师《手把手教你做文本处理》欢迎大家报名:
Hellobi Live | 手把手教你做文本处理内容:1、jiebaR的简介及切词 2、文字云的绘制;3、tm包的简介及构建文档词条矩阵; 4、聚类的简单使用; 。 可以加下小编微信:tswenqu ,可以到对应微信群跟顺祥老师互动。
