


配对交易千千万,强化学习最给力!(附文档+代码讲解)


作者:WI
编译:叶别 | 公众号翻译部
本文亮点
1、可扩展的基础架构,数据获取方便;
2、Python编程技术应用;
3、编程、计量经济学、强化学习的基础概念;
4、超全策略代码;
本推文会介绍如何在利用股票分钟数据,基于强化学习来做配对交易。包括基本概念和具体实现;这里采用的强化学习方法,是类似多臂老虎机(N-armed bandit)问题。
获取全部代码,见文末
数据获取
▍Tiingo 数据源
Tiingo是一个金融研究平台,提供包括新闻、基本面和股票价格在内的数据。我们可以通过其REST IEX API提取日内股票市场数据,该API从IEX交易所检索到TOPS数据(最高价/最低价/开盘/收盘价)。
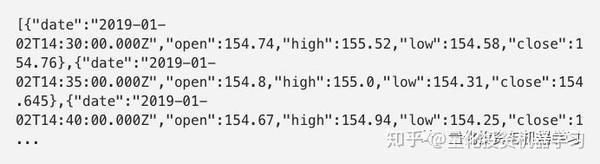
举个例子,可以通过访问以下链接来获取苹果公司在2019年1月2号中每5分钟的股价。
json返回结果:

为了使任务自动化,我们提供了一个能够在指定历史窗口内获得股票列表的标准化的日内数据的函数。
不足之处有:
1、最对提供1分钟级别的数据;
2、不同股票可以查询到的股价的天数不是固定的,即使指定365天的窗口,也可能只获得几天的数据;
3、不同股票在一天之内可以查询到的时间段也不是固定的(可能某些股票开盘后了才能查到股价);查询速度不是很快。
解决方案:
1、一次只查询一只股票、只查询一天的数据;
2、对查询到的多个时间段的数据,用固定窗口去截断(比如限制每天只取391分钟的数据);
3、异步IO。
Pandas提供了相关工具,可以从Tiingo和其它类似数据集中提取数据,但目前只提取天级别的数据。 虽然API是免费的,不过使用时也请注意调用方法,避免请求过多超出限制。
▍实现
首先注册账号、申请:
token: https:// api.tiingo.com/account/ api/token
介绍下Data/API.py下面的几个主要函数:
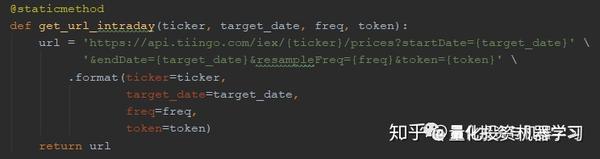
1.生成获取股价数据的url,参数有股票名(ticker),时间(target_date),请求频次(freq),token;

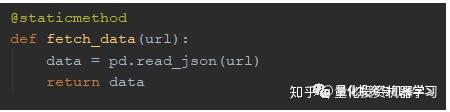
2. 获取json数据:

以上两个函数是放在Data/API.py 文件中的Tiingo 类下面的;可以根据输入不同重复执行。
▍异步IO
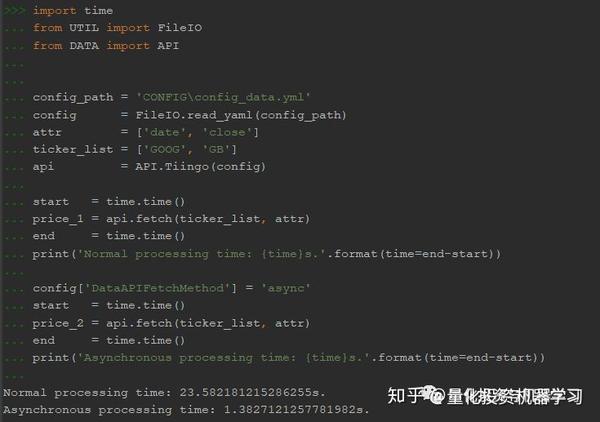
上面实现是有局限性的、性能也比较差。 每获取一条数据时,程序会建立API连接、从服务器请求数据、等待响应,重复请求直到完成所有的URL。异步IO的处理方式是不同的,下面这段代码是用异步IO的方式来获取Google和Facebook在20180101到20180131这段时间内的交易数据(每天391分钟数据, 319*24个交易日*2只股票,共约15600条数据)。可以看出, 相比于非异步请求,性能提升了17倍(1.38s->23.58s)。

asyncio是一个使用async / await方式的并发编程的库,asyncio用作多个Python异步框架的基础,这些框架提供高性能的网络和Web服务器、数据库连接库、分布式任务队列等。AsyncIO是单线程的,它使用一个单事件处理器来组织任务分配、以便多个任务可以在其他任务空闲时开始运行。
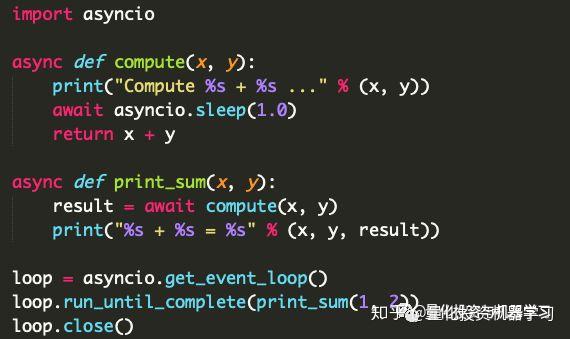
下面有个官方示例来展示asyncio的思想。
程序地址:
https:// python.readthedocs.io/f r/latest/library/asyncio-task.html

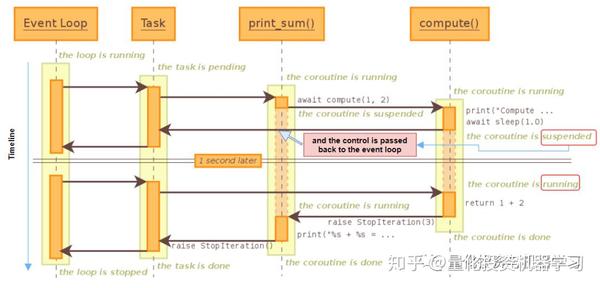

https:// python.readthedocs.io/f r/latest/library/asyncio-task.html

上面程序中的关键字 async def 将相应的函数定义为可以暂停或恢复执行的协程。 每当任务运行到在关键字 await 处,将回传一个事件控制器( loop ),该事件控制器再唤起另一个任务。 简单来说,这种方式不会浪费等待时间。
在我们的代码中也有类似的方法, _fetch_hist_async 将创建一个事件循环来控制 fetch_data_async 进程( fetch_data_async 是获取日内价格的基础任务); 遇到await时控制器返回到事件循环,即使前一个请求尚未完成,也会触发另一个请求。
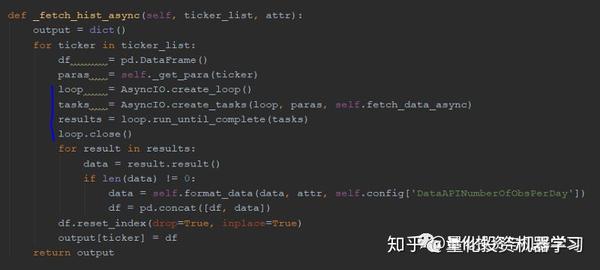



▍数据存储
把数据用.csv格式保存到STATICS/PRICE目录下。


代码结构
获取全部代码,见文末
配对交易的概念和分析
▍配对交易
配对交易是市场中性策略
Gatev 等人这样描述:
“配对交易的概念非常简单, 找出价格在历史上一起变化的两只股票, 当它们之间的差距扩大时,做多价低者、做空价高者。如果历史重演,价格差距会收敛,套利者会获利。”
这里包含两个方阶段:
1、规则制订阶段:测量股票之间的价格关系,寻找潜在的股票配对。
2、在交易期间,监控股价变动,并根据预定义的规则进行交易。
Krauss (2017) 总结了配对交易的5种类型:距离法,协整方法,时间序列法,随机控制法和其他方法如机器学习、主成分分析、copula等。 本文是把经典的Engle和Granger(1987)协整方法和强化学习算法结合起来的应用 。
这里我们会用时间序列分析中的平稳性的概念, 在金融时间序列中通常用的是弱平稳性(或协方差),并遵从3个准则:
1、随机变量x的均值E[x(t)]: 该均值和时间t独立;
2、方差Var(x(t)):大于0且有限的值、且与时间t独立;
3、协方差Cov(x(t),x(s)):和t-s相关,但与单独的t和s独立。x(t)一般可以是对数股价收益(或差分),而不是价格本身。 如果一个时间序列的一阶差分平稳了,就是所谓的一阶单整I(1)。
虽然有些交易可以从定向投注中获利,但这不是我们关注的, 我们真正想要的是找到一对价格差异或价差始终保持稳定(并且协整)的股票。
▍分析(见EXAMPLE/Analysis.py)
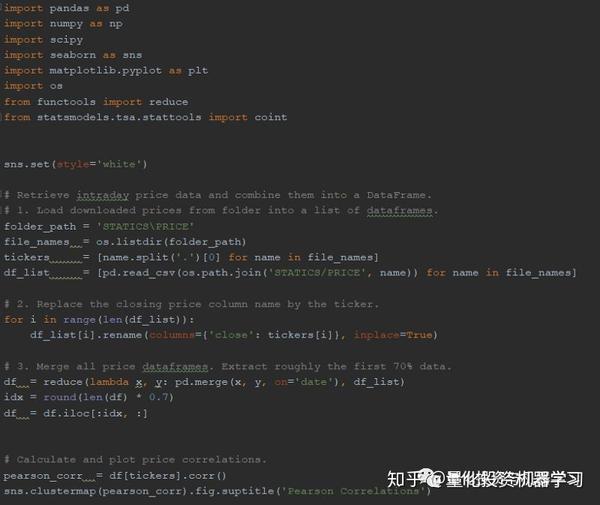
我们抽取了20180101-20180731期间的21只美股的1分钟级别的数据,用.csv格式保存在STATICS/PRICE目录下。对时间段前70%的数据,我们来进行一些分析。
▍Pearson 相关系数
先看下代码:

看下结果:
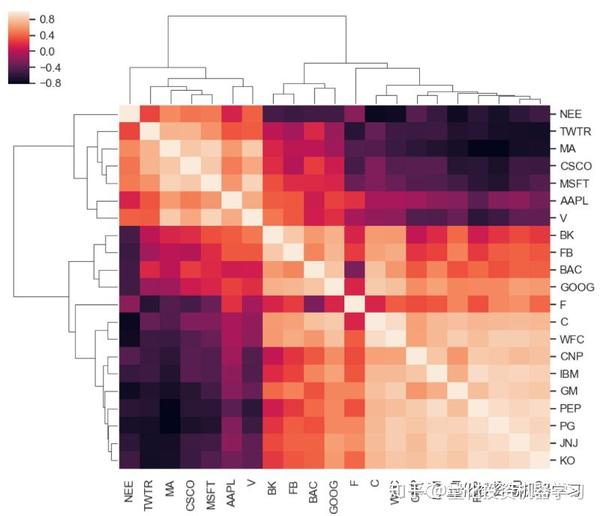

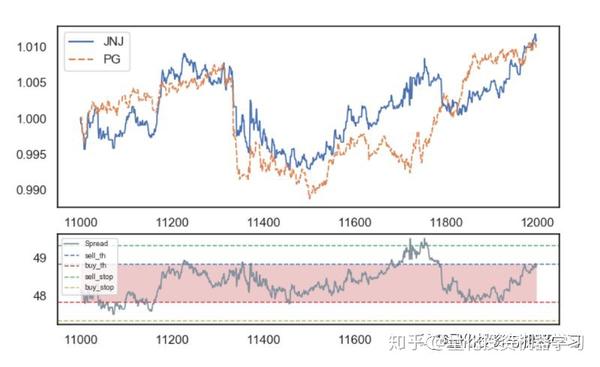
上图可以看出,最高相关性位于PEP(百事可乐)/PG(保洁)/JNJ(强生)/KO(可口可乐)这四只股票之间。从经济角度来看,可以形成两组配对:JNJ-PG和KO-PEP。 不过需要注意的是高相关性并不一定意味着协整。
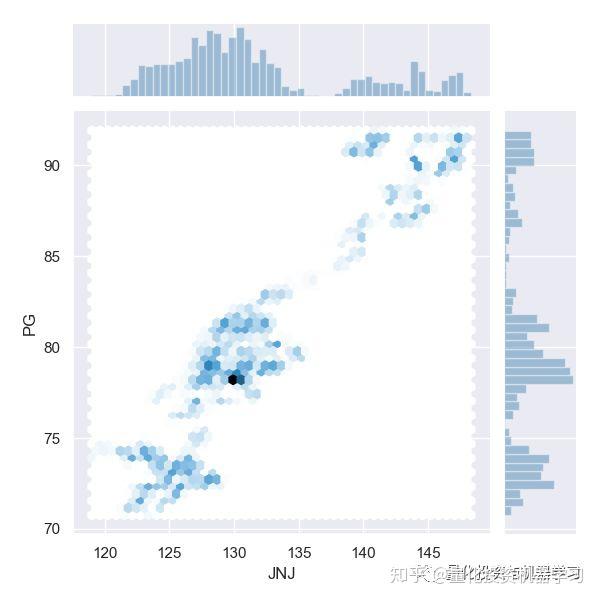
▍边缘分布
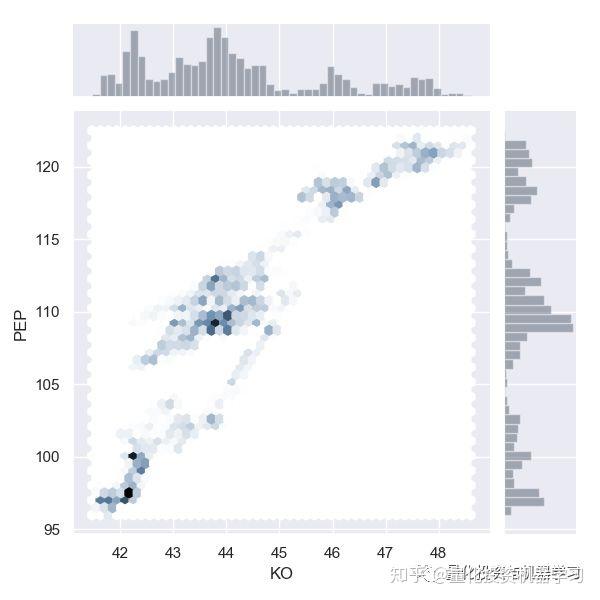
如果我们画出以上股票对的边缘分布,可以看到线性相关和一些簇的关系。
代码如下:


效果如下:


▍价格图表
我们创建一个函数来绘制样本期间的价格和价差, 价格在开始时重新定为1;其中第二个子图中的th是交易阈值(买点和买点),stop_loss是止损点。
代码如下:

效果如下:

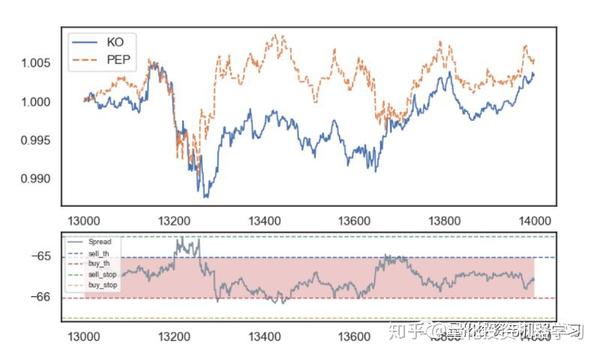

▍协整检验
以下代码计算协整检验的p值,如果p值很小观察协整关系的概率应该相对较高。
代码如下:
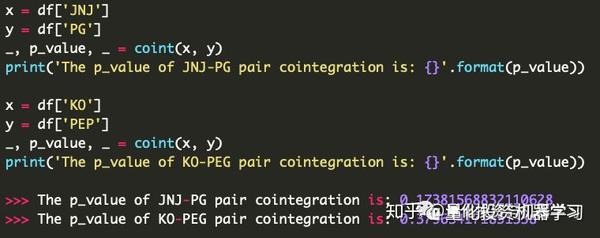

但是相关性并不等于协整。即使两对股票的相关性是差不多的,但协整关系的概率差别比较大。
有时我们可以找到相关但不是协整的价格关系。 例如如果两种股票价格随着时间一起上涨,则它们是正相关的; 然而如果这两只股票以不同的速度上涨,价差将继续增长而不是在均衡时振荡,因此是非平稳的。
下面给出一个例子, 用代码通过几何布朗运动(Geometric Brownian Motion)和Cholesky分解模拟两个相关的股票 ,每个包含1000个样本。
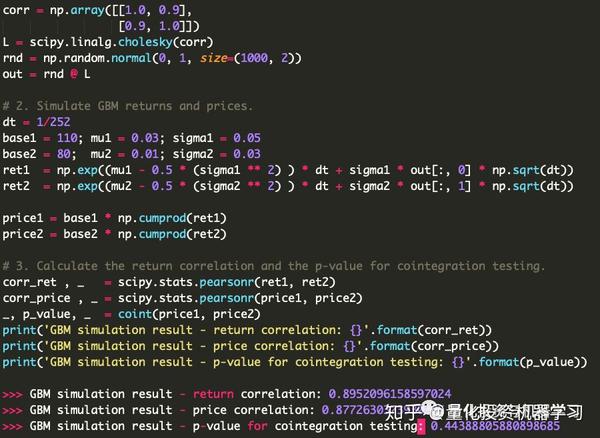

可以看到虽然很相关,但是p值却非常大。
画出时间序列上的图:

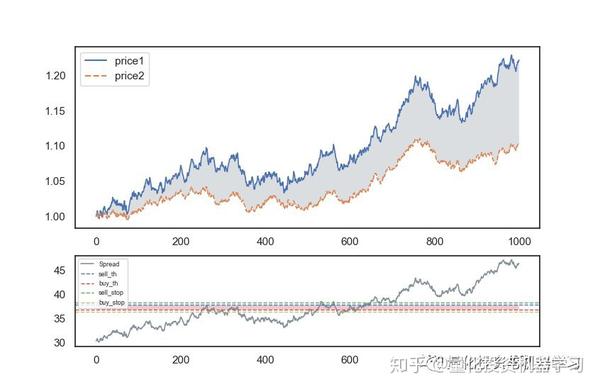

上图中的第2个子图中显示了价差不断变大,而不是均值回归。
▍协整
1987年Engle和Granger提出的协整理论,虽然一些变量的本身是非平稳序列,但是它们的线性组合却有可能是平稳序列。
这种平稳的线性组合被称为协整方程,且可解释为变量之间的长期稳定的均衡关系。具体地,如果两个I(1)对数股票价格x(1,t)和x(2,t)有协整关系,那么存在一个系数b和一个平稳的时间序列y(t), 使得:
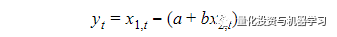
其中a是一个固定常数,y(t)是目标的平稳的价差。 显然,我们可以简单地使用普通最小二乘方法来估计价差y和系数b,通过将x(1,t)来对x(2,t)做回归。
▍协整检验
测试协整的最常用方法是DF方法(Dickey Fuller)或ADF方法(Augmented Dickey Fuller)。
▍单位根和DF检验
对于一个简单的一阶自回归AR(1)模型
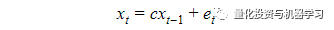
其中e(t)是白噪声,t是时间, xt是要检验的变量;如果c=1则说明单位根是存在的。
DF检验是用来测试一个自回归模型是否存在单位根,把上面的回归模型改写为:
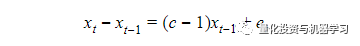
c=1也就意味着零假设c-1=0。 我们还可以添加截距或趋势项,并根据假设测试系数等于零的零假设。
▍ADF检验
把DF检验中用到的AR(1)自回归改为高阶自回归AR(p),那么就是ADF检验。
AR(p):
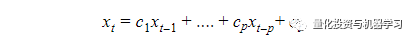
残差形式:
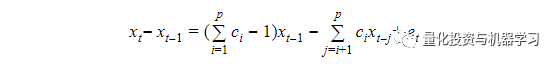

对应的零假设是:
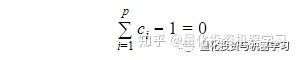
▍实现部分
我们在策略类EGCointegration中实现了上面的分析。 请注意,此处的检验是基于statsmodels.tsa.stattools.coint,在同一库中还有另一个函数statsmodels.tsa.stattools.adfuller是用来用于单元根检验的。
不同之处在于:
1、 coint 实际上是Engle-Granger协整检验,有2个时间序列输入,计算残差、对残差做检验;
2、 adfuller 是一个时间序列的输入,检验的是单变量的单位根。大部分场景下两个检验得出的结论是一致的,但是coint方法实现起来更直观。
强化学习的介绍
▍基础概念
强化学习有两个元素: Agent和环境(Environment)。 环境由具有预定义状态空间(State)的不同状态表示,而Agent学习一个策略(Policy)来确定要在动作空间(Action)中执行哪个动作。 Agent的学习周期可归纳为以下几个阶段:
1、观察环境状态
2、根据现有Policy相应地采取动作
3、收到执行动作的相应奖励(Reward)
4、更新Policy
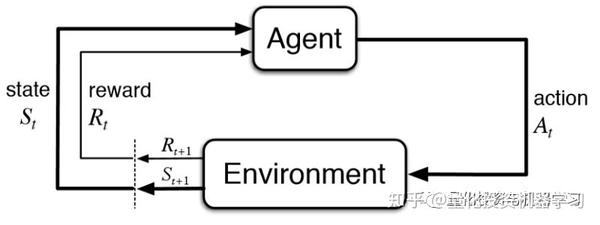

举个例子,假设一只小狗(Agent)正在学习如何对他主人的命令(环境)作出反应。 它是一只懒狗,只知道如何执行三个命令:
- 坐
- 站
- 啥也不做
为了训练小狗,他的主人经常给他一套命令(State),包括“坐”,“站”和“跳”。 如果狗的反应正确,他的主人会给他一些狗粮(Reward)。起初,小狗并不真正了解他的主人想要什么,不知道(Policy)如何将命令“正确地”映射到期望的动作(Action)。 但是,偶尔他可以做正确的动作并得到了奖励(Reward),并逐渐建立他们之间的联系(更新Policy)。
经过多次试验,这个狗终于知道,只要听到“坐”或“站”这个词,他就应该坐/站立。 但无论他的主人要求他“跳”多少次,他都完全不知道该怎么办。 在这种情况下,他曾多次尝试坐下或站立,但无法获得任何奖励; 小狗最终选择了对“跳跃”命令什么都不做,因为与其他动作相比,这个选项能节约点体力(Reward不为负)。
强化学习和监督学习是不同的。在监督学习中,每个样本都有一个预测目标以便计算差值,通过不断迭代减小这个差值来更新算法。然而在强化学习中,Policy是通过评估来学习的,样本中没有直接的标注数据。Agent只能通过持续评估反馈来学习,即不断挑选Action并评估相应的奖励(Reward)以调整策略(Policy),保留最理想的结果。 强 化学习的流程要复杂一些, 如果我们在交易中应用强化学习时,需要仔细定义状态和动作空间这些基础元素。
▍几个简单的强化学习实例
多臂老虎机
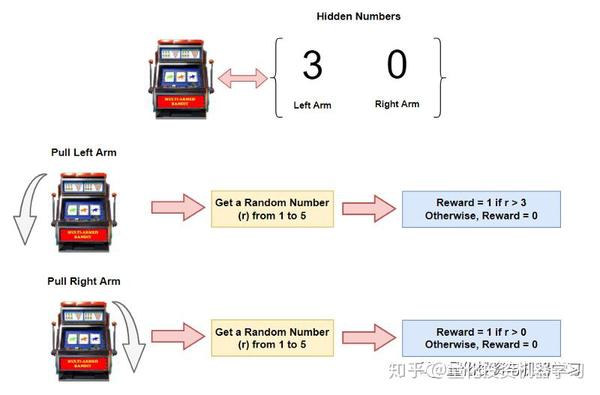

问题: 上面的2臂老虎机,我们应该选择左臂还是右臂来获取最多的奖励。
答案: 右臂。
但是机器如何学到这个策略呢? 把这个问题转化为强化学习的形式如下:
- 状态空间:无
- 动作空间: 拉左臂/右臂
- 奖励:1或0
在训练过程中,RL算法将重复上述任务(拉动手臂)并评估获得的奖励、持续更新策略(Policy)。 最后,通它应该能够得出哪个手臂最好拉动的结论。
上下文赌博机
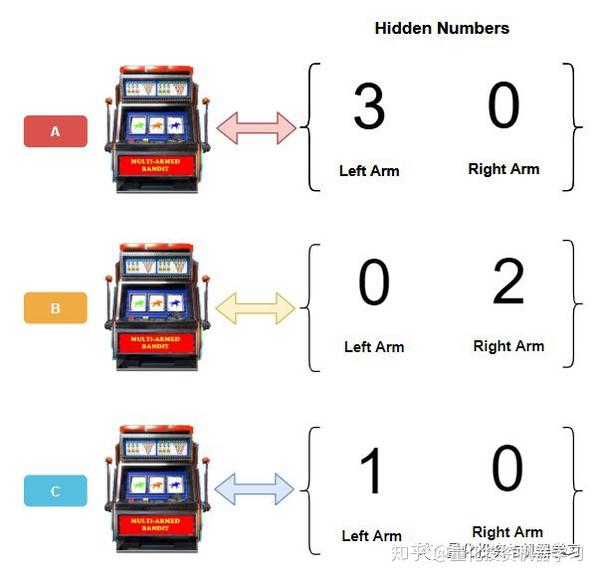

上下文赌博机是多臂老虎机的扩展,如上图有3个机器、对于每个机器我们要选择不同的手臂。转化为强化学习形式如下:
- 状态空间: 机器A、机器B、机器C
- 动作空间:拉左臂/右臂
- 奖励:1或0
▍ 实现
我们究竟希望机器学会如何执行?对于时间序列中的配对交易, 我们需要选择合适的历史窗口、交易窗口、交易阈值和止损这些都是动作(Action)的最佳组合来学习最大化预期交易利润(Reward) 。从强化学习的角度来看:
- 状态空间: 无(只有一定的交易成本)
- 动作空间: 历史窗口、交易窗口、交易阈值、止损点、信心水平
- 奖励: 平均收益
用强化学习实现配对交易
实施的6个步骤有:
1、加载相关配置和价格数据
2、将它们标准化并分成训练和测试集
3、创建状态空间和动作空间
4、构建网络
5、创建学习对象并开始训练
6、执行测试分析
参数:
配对股票 :JNJ-PG(强生vs宝洁)
时间范围: 20180101-20180730
数据频率: 分钟级别的
状态空间: 无
动作空间:
a. 历史窗口: 从60分钟到600分钟,每60分钟一步
b. 交易窗口: 从120分钟到1200分钟,每60分钟一步
c. 交易阈值: 增加/减少的访问时1-5, 每步是1
d. 止损点: 交易阈值基础上加减1-2, 每步是0.5
e. 信心水平:90%或95%
奖励: 平均收益
交易数量: 每个买买信号交易1个价差
价格校准: 标准化
交易价格: 实际价格
为了减轻极高回报的影响,平均回报的上限为10。
配置
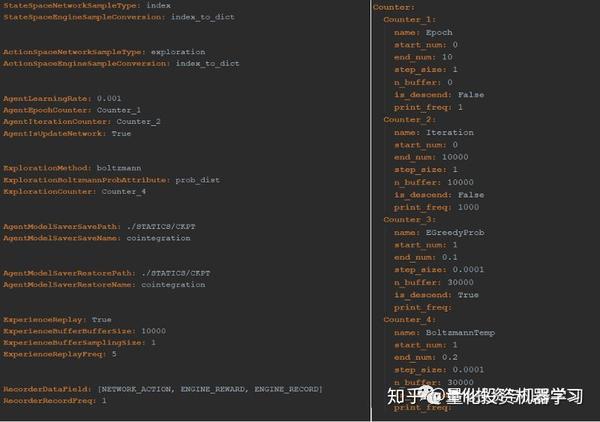

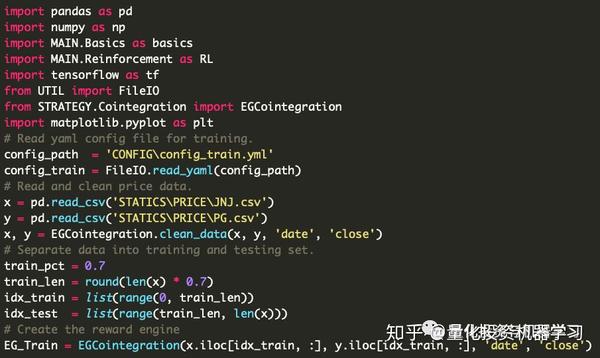
第一步和第二步:
加载相关配置和价格数据&& 将它们标准化并分成训练和测试集。

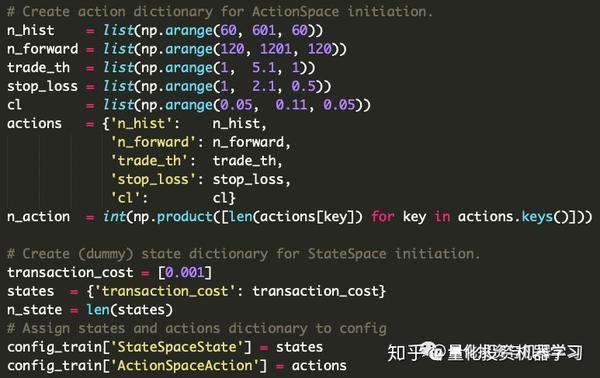
第三步:
创建状态空间和动作空间

第四步:
构建网络
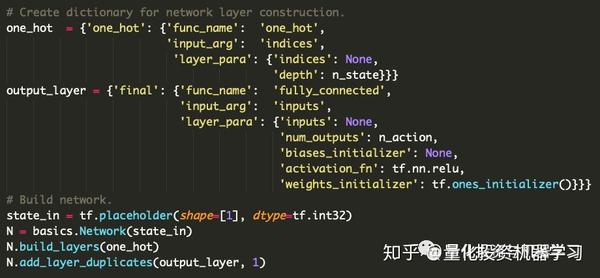

第五步:
创建学习对象并开始训练


第六步:
执行测试分析


训练时的预期奖励如下:
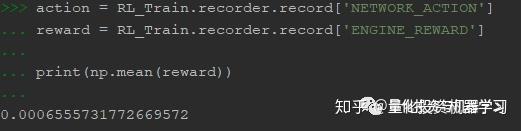

训练中的奖励的分布:
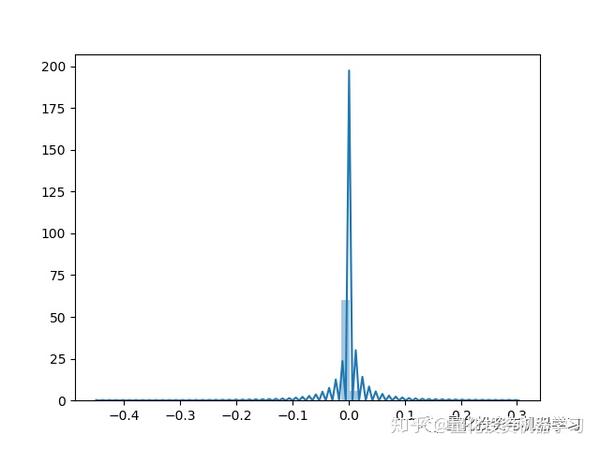

训练好之后,对每分钟数据进行测试交易:
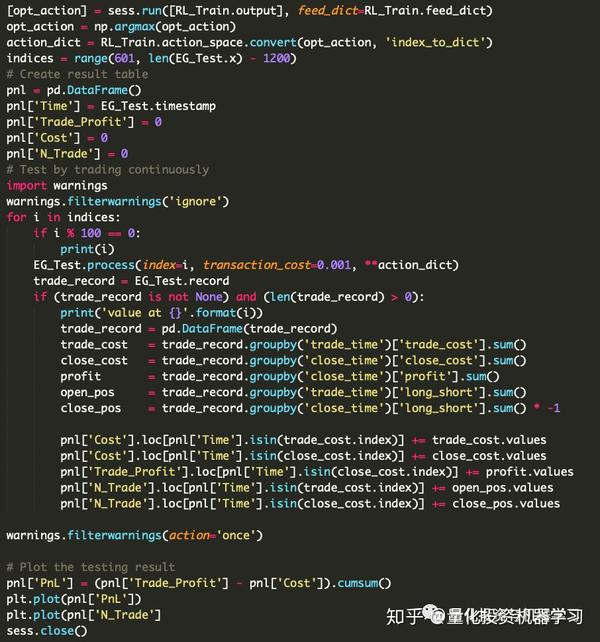

效果如下:
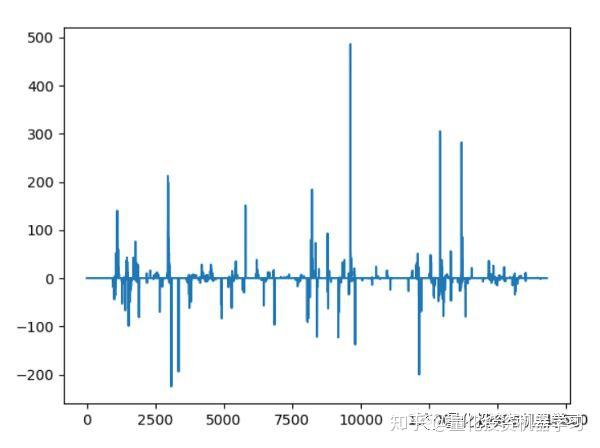

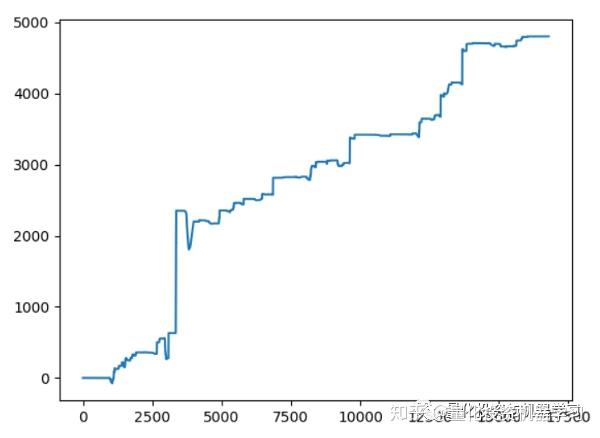

其中上图是每分钟内的交易数量;下图是累计收益(pnl)线。
虽然看起来结果似乎不错,但在现实世界中情况因许多因素而变得复杂,例如买卖差价、执行延迟、保证金、利息、分数股等。但本文的目标是举例说明如何开发一个强化学习交易系统中用到的各种技术,希望对读者有一定借鉴意义。
代码设计逻辑
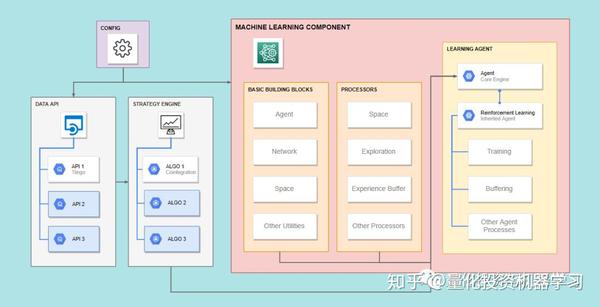

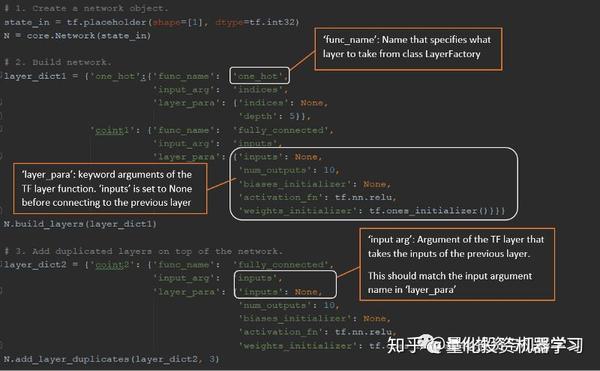
代码讲解
代码讲解部分内容涉及较多,大家自行查看。



参考文献
Dickey, D. A., Fuller, W. A., 1979. Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association. 74(366): 427–431.
Engle, R.F., Granger, C.W.J., 1987, Co-integration and error correction: representation, estimation, and testing. Econometrica 55(2): 251–276
Gatev, E., Goetzmann, W.N., and Rouwenhorst, K.G., 2006, Pairs trading: performance of a relative-value arbitrage rule. The Review of Financial Studies 19(3): 797–827
Granger, C.W., 1981, Some properties of time series data and their use in econometric model specification. Journal of Economics 16(1): 121–130
Johansen, S., 1988, Statistical analysis of cointegration vectors. Journal of Economic Dynamics and Control 12(2–3): 231–254
Krauss, C., 2017, Statistical arbitrage pairs trading strategies: review and outlook. Journal of Economics Surveys 31(2): 513–545
Stock, J.H., 1987, Asymptotic properties of least squares estimators of cointegrating
vectors, Econometrica 55: 277–302.
Sutton, R.S., Barto, A.G., (1998), Reinforcement Learning: An Introduction. The MIT Press, Second Edition
如何获取代码
量化投资与机器学习微信公众号,是业内垂直于 Quant 、 MFE 、 CST 等专业的主流量化自媒体。公众号拥有来自 公募、私募、券商、银行、海外 等众多圈内 10W+ 关注者。每日发布行业前沿研究成果和最新资讯。
