先附上github链接:
GitHub - muzi-xiaoren/kaobei_Crawler: 拷贝漫画爬虫
主要使用selenium库模拟浏览器来获取kaobei动态加载的html页面。
用BeautifulSoup进行解析。然后传入函数先获取url。
将url传入get.py中使用多线程编程加快下载速率
下面是具体函数及使用方法。
download.py 和 get.py 是方法函数,不需要修改。pic是md图片存放处。
使用临时账号和密码登陆,需要登陆的原因是有一些漫画不登陆不可见 (在50和51行处,可以不用修改 也可以修改成你的账号和密码)
下载的图片新存放于本文件夹中的一个kaobei_images中。
使用的是本机浏览器,例如代码中的Chrome浏览器 如果你的浏览器中已经登陆了拷贝网站,那么就可以省去登陆的步骤。
但是配置起来比较麻烦,教程见
教程
Chrome浏览器的复用_--remote-debugging-port=9222_Mengmeng.Nie的博客-CSDN博客
建议直接使用kaobei_spider_1的账号密码登陆
-
由于使用多线程下载,对每张图片使用一个新的线程进行下载。所以可能会比较吃网速,导致一些报错。如果出现这种情况,可以如下解决。
-
一次运行完后,再次运行py程序,因为图片会先检测是否存在,不会重复下载。基本多运行几次就可以完全下载。
-
取消get.py第20行的注释,让所有下载图像的线程创建完成后停一秒后再返回,时间也可以多加一些。
-
程序运行时请让浏览器的页面保持在屏幕中,不要最小化到任务栏中,不然页面不会进行更新。
-
kaobei_spider_2.py目前运行完成后不能自动关闭,需要手动结束一下进程。当然最好等一会,因为打印出最后下载章数的时候,可能还有一些下载图片的进程在运行。
-
下载的漫画全部存放于一个文件夹中,文件名格式由章节数_图片顺序_url中部分字符串构成。如下所示。
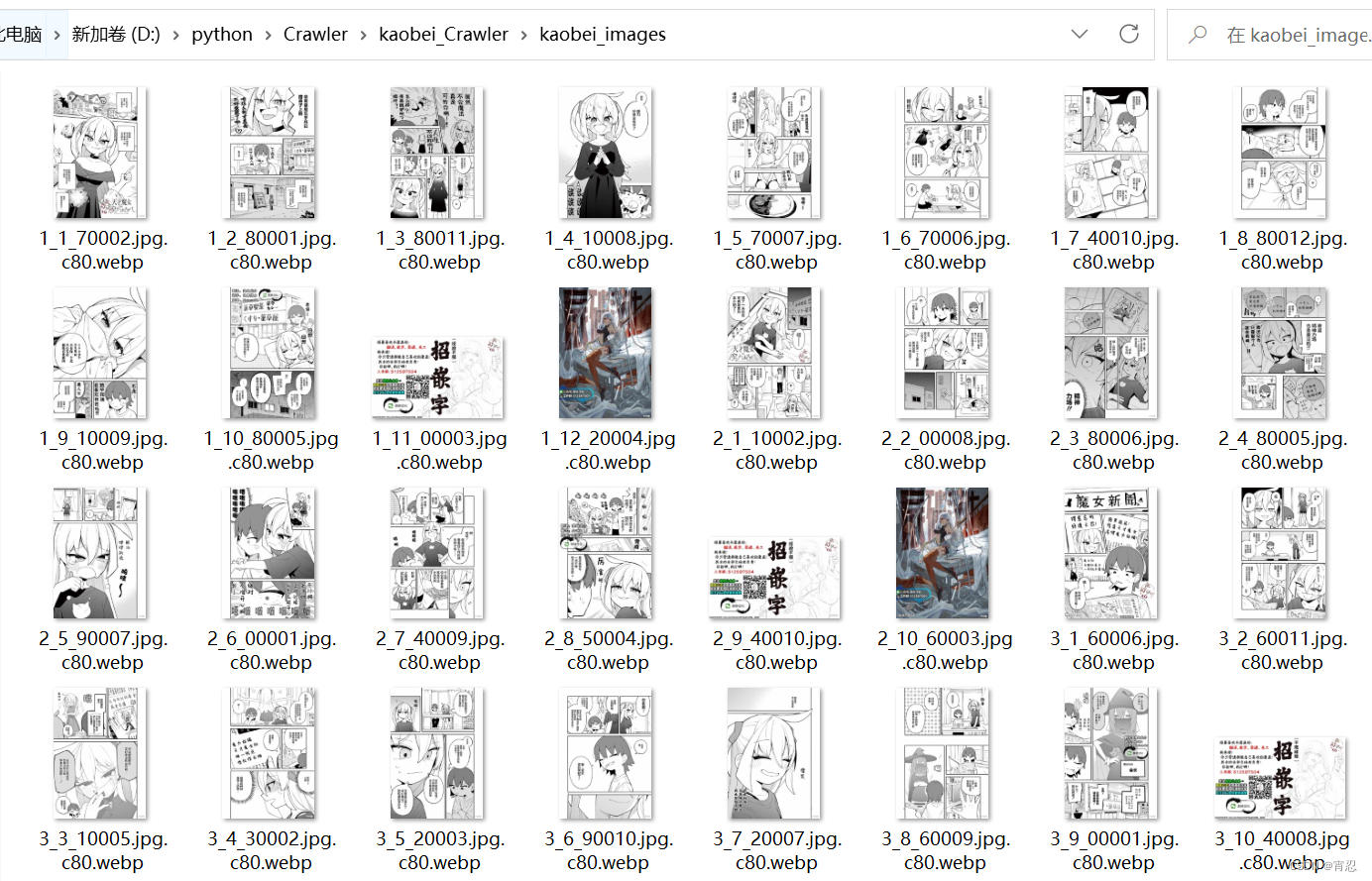
当然最好等一会,因为打印出最后下载章数的时候,可能还有一些下载图片的进程在运行。使用临时账号和密码登陆,需要登陆的原因是有一些漫画不登陆不可见 (在50和51行处,可以不用修改 也可以修改成你的账号和密码)如果出现这种情况,可以如下解决。使用的是本机浏览器,例如代码中的Chrome浏览器 如果你的浏览器中已经登陆了拷贝网站,那么就可以省去登陆的步骤。下载的漫画全部存放于一个文件夹中,文件名格式由章节数_图片顺序_url中部分字符串构成。下载的图片新存放于本文件夹中的一个kaobei_images中。
爬虫
(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。
爬虫
通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。
爬虫
的工作流程包括以下几个关键步骤:
URL收集:
爬虫
从一个或多个初始URL开始,递归或迭代地发现新的URL,构建一个URL队列。这些URL可以通过
链接
分析、站点地图、搜索引擎等方式获取。
请求网页:
爬虫
使用HTTP或其他协议向目标URL发起请求,获取网页的HTML内容。这通常通过HTTP请求库实现,如
Python
中的Requests库。
解析内容:
爬虫
对获取的HTML进行解析,提取有用的信息。常用的解析工具有正则表达式、XPath、Beautiful Soup等。这些工具帮助
爬虫
定位和提取目标数据,如文本、图片、
链接
等。
数据存储:
爬虫
将提取的数据存储到数据库、文件或其他存储介质中,以备后续分析或展示。常用的存储形式包括关系型数据库、NoSQL数据库、JSON文件等。
遵守规则: 为避免对网站造成过大负担或触发反
爬虫
机制,
爬虫
需要遵守网站的robots.txt协议,限制访问频率和深度,并模拟人类访问行为,如设置User-Agent。
反
爬虫
应对: 由于
爬虫
的存在,一些网站采取了反
爬虫
措施,如验证码、IP封锁等。
爬虫
工程师需要设计相应的策略来应对这些挑战。
爬虫
在各个领域都有广泛的应用,包括搜索引擎索引、数据挖掘、价格监测、新闻聚合等。然而,使用
爬虫
需要遵守法律和伦理规范,尊重网站的使用政策,并确保对被访问网站的服务器负责。
拷貝漫畫 - 海賊王 海贼王 哥布林殺手 哥布林杀手 漫畫
漫画
FGO FGO 東方 东方 艦娘 舰娘 同人志 本子 更新 全集 在綫漫畫 在线
漫画
- 拷貝漫畫
拷贝
漫画
(copymanga.com)https://www.copymanga.com/
拷贝
漫画
是一个神奇的网站,他的服务器在新加坡,所以可以规避一些风险。资源也丰常丰富,但可惜的是目前还没有ios的客户端,直接看网页端的体验比较一般。所以就萌生出写一个
爬虫
来下到本地观看的想法。
废话不多说直接上
代码
:
外国一位名为 Alex 的开发者整理的人脸转
漫画
数据集:face2comics。
数据集拥有两个版本,v1 主要为深色调(含 1 万张图片),v2 为深红色调(含 2 万张图片)。
漫画
风格偏欧美风,可用于训练 pix2pix 或相似网络。
GitHub
:
github
.com/Sxela/face2comic
Python
爬虫
源码
下载
是指在网上获取
Python
爬虫
的
代码
,以便在自己的项目中使用或研究其工作原理和
代码
结构。
Python
爬虫
是一种通过编写
代码
自动获取互联网上内容的程序,可以用于获取数据、抓取图片、爬取网站等多种任务。以下是关于
Python
爬虫
源码
下载
的介绍:
1.查找网上资源。在互联网上有很多
Python
爬虫
的
代码
可供
下载
,可以通过搜索引擎、
GitHub
等网站寻找。
2.选择合适的源码。在
下载
前需要对源码进行筛选,选择适合自己需求的源码。可以通过查看
代码
的功能、运行效率、稳定性等方面进行筛选。
3.
下载
源码。一般情况下,
Python
爬虫
的源码都可以从
GitHub
等网站上直接
下载
,也可以从开发者的博客等个人网站上
下载
。
4.学习源码。
下载
后需要认真研究源码,了解
代码
结构、注释、变量命名等方面。对于初学者来说,可以通过借鉴源码的思路和结构进行学习和改进。
5.修改源码。
下载
的
Python
爬虫
源码不一定能直接使用,需要根据自己的需求进行修改。可以添加功能、优化
代码
等方面进行改进。
总之,
Python
爬虫
源码是
Python
爬虫
学习和使用的重要资料之一,
下载
和学习源码有助于提高
Python
编程水平和掌握
爬虫
技术。但需要注意的是,不要侵犯他人的知识产权。在使用源码时,要遵循相应的开源协议和著作权法规。
CSDN-Ada助手:



