


mmdetection使用初踩坑

一、git+环境安装
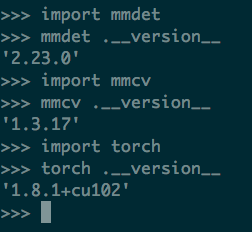
git指路 [1] 安装环境之类的就不赘述了, 需要: windows/linux + cuda, 可参考 [2] . 注意根据torch版本, cuda版本, 安装对应的mncv-full和mmd即可. 我的实验版本:
可能遇到的环境错误:
from .cv2 import *
ImportError: libGL.so.1: cannot open shared object file:
解决方法:
pip3 install opencv-python-headless==4.5.3.56 更新下opencv相关依赖即可.二、inference体验
import torch
from mmdet.apis import init_detector, inference_detector
import mmcv
import cv2
# cd mmdetection_dir
# 模型结构写入config, load官网的checkpoint
config_file = 'configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth'
# init model
model = init_detector(config_file, checkpoint_file)
# test single_img
# score阈值可自行填写
score_thres = 0.1
img = './test.jpg'
image = cv2.imread(img)
# len(result) == 80, 对应index上的检出box则代表对应类别
result = inference_detector(model, img)
# 只为了可视化box, 故我没有利用上这个class_index信息
result = [a for a in result if len(a) > 0]
all_res = []
for res in result:
all_res.extend(res)
for res in all_res:
if res[-1] >= score_thres:
bbox = [int(a) for a in res[:4]] # x1,y1,x2,y2
# test_img上画出box
image = cv2.rectangle(image, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (255, 0, 0), 2)
cv2.imwrite('./res.jpg', image)三、数据集准备
这里我维护了两套数据格式, labelme和coco. 从tianchi上拿到的是coco格式, 需要做一个train-val-split.
1. coco2labelme
# 读入tianchi提供的coco格式train.json
file = '/小log检测/train/annotations/instances_train2017.json'
label = json.load(open(file, 'r'))
imgs = label['images']
annotations = label['annotations']
categories = label['categories']
categories = [a["name"] for a in categories]
print(categories)
json_save_dir = '/小log检测/train/images'
# 对annotations做以img_id为key的dict预处理, value是bbox两个点信息.
img_id_anns = dict()
for dic in annotations:
img_id = dic["image_id"]
categorie_id = dic["category_id"]
if img_id not in img_id_anns:
img_id_anns[img_id] = []
img_id_anns[img_id].append([dic
["bbox"], categories[categorie_id-1]])
for img_dict in imgs:
img_name = img_dict["file_name"]
lab_dict = {"version": "4.5.10", "flags": {}, "shapes": [], "imageData": None}
# 填入infos
id_ = img_dict["id"]
lab_dict["imagePath"] = img_name
for box_name in img_id_anns[id_]:
tmp = {"group_id": None, "shape_type": "rectangle", "flags": {}}
tmp["label"] = box_name[1]
point1 = box_name[0][:2]
h, w = box_name[0][2:][0], box_name[0][2:][1]
point2 = [point1[0]+h, point1[1]+w]
tmp["points"] = [point1, point2]
lab_dict["shapes"].append(tmp)
lab_dict["imageHeight"] = img_dict["height"]
lab_dict["imageWidth"] = img_dict["width"]
lab_dict["id"] = id_
with open(os.path.join(json_save_dir, "{}.json".format(img_name.split('.')[0])) , "w", encoding='utf-8') as fp:
json.dump(lab_dict, fp, ensure_ascii=False,indent = 4)以上代码可得到每张train-img的labelme格式json. 之所以这么做是因为我本地在使用一套labelme标注格式的检测代码.
四、train 自己的数据集
命令:
# 单卡 train model
python tools/train.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py --gpus 1
# 多卡 train model
python -m torch.distributed.launch --nnodes 1 --node_rank 0 --master_addr "127.0.0.1" --nproc_per_node 4 --master_port 29500 tools/train.py configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py --seed 0 --launcher pytorch ${@:3} --work-dir output_cascade4"
# inference test_data(no_label_imgs)
python tools/test.py configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x_coco.py output_cascade/epoch_50.pth --show --format-only --options "jsonfile_prefix=cascade.json""
# finetune train: 加一个 --resume-from=xxx/...pth
python tools/train.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py --gpus 1 --resume-from=work-dir/.../epoch_50.pth多卡训模型更多细节可参考: 指路 [3] .
以上条命令为例, 来看看我们使用的网络配置:
# configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py', # 在这里修改自己任务的检测类别数
'../_base_/datasets/coco_detection.py', # 在这里添加自己的任务的classes
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py' # 这俩修改一些lr, 训练策略之类的1. faster_rcnn_r50_fpn.py
# 大概31行的样子, 80修改为自己任务的类别数, 我的是50
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=50, # coco80, my_job50
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,2. coco_detection.py
注意用到了albu这个图像增强包, 需要安装:
pip install - requirements/albu.txt
保险起见, 在tools/train.py 头部:
import albumentations as albu 然后是coco_detection.py:
# dataset settings
dataset_type = 'CocoDataset'
data_root = '/path/to/data'
# 这里是自己训练任务的classes信息
classes = ('冰墩墩', 'Sanyo/三洋', 'Eifini/伊芙丽', 'PSALTER/诗篇', 'Beaster', 'ON/昂跑', 'BYREDO/柏芮朵', 'Ubras', 'Eternelle', 'PERFECT DIARY/完美日记', '花西子', 'Clarins/娇韵诗', "L'occitane/欧舒丹", 'Versace/范思哲', 'Mizuno/美津浓', 'Lining/李宁', 'DOUBLE STAR/双星', 'YONEX/尤尼克斯', 'Tory Burch/汤丽柏琦', 'Gucci/古驰', 'Louis Vuitton/路易威登', 'CARTELO/卡帝乐鳄鱼', 'JORDAN', 'KENZO', 'UNDEFEATED', 'BOY LONDON', 'TREYO/雀友', 'carhartt', '洁柔', 'Blancpain/宝珀', 'GXG', '乐町', 'Diadora/迪亚多纳', 'TUCANO/啄木鸟', 'Loewe', 'Granite Gear', 'DESCENTE/迪桑特', 'OSPREY', 'Swatch/斯沃琪', 'erke/鸿星尔克', 'Massimo Dutti', 'PINKO', 'PALLADIUM', 'origins/悦木之源', 'Trendiano', '音儿', 'Monster Guardians', '敷尔佳', 'IPSA/茵芙莎', 'Schwarzkopf/施华蔻')
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
# albu
albu_train_transforms = [
dict(
type='ShiftScaleRotate',
shift_limit=0.0625,
scale_limit=0.0,
rotate_limit=0,
interpolation=1,
p=0.5),
dict(
type='RandomBrightnessContrast',
brightness_limit=[0.1, 0.3],
contrast_limit=[0.1, 0.3],
p=0.2),
dict(
type='OneOf',
transforms=[
dict(
type='RGBShift',
r_shift_limit=10,
g_shift_limit=10,
b_shift_limit=10,
p=1.0),
dict(
type='HueSaturationValue',
hue_shift_limit=20,
sat_shift_limit=30,
val_shift_limit=20,
p=1.0)
p=0.1),
dict(type='JpegCompression', quality_lower=85, quality_upper=95, p=0.2),
dict(type='ChannelShuffle', p=0.1),
dict(
type='OneOf',
transforms=[
dict(type='Blur', blur_limit=3, p=1.0),
dict(type='MedianBlur', blur_limit=3, p=1.0)
p=0.1),
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
# 多尺度训练
dict(type='Resize', img_scale=[(360, 360), (800, 1033)], keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Pad', size_divisor=32),
dict(type='Albu', # 添加albu数据增强包
transforms=albu_train_transforms,
bbox_params=dict(
type='BboxParams',
format='pascal_voc',
label_fields=['gt_labels'],
min_visibility=0.0,
filter_lost_elements=True),
keymap={
'img': 'image',
'gt_masks': 'masks',
'gt_bboxes': 'bboxes'
update_pad_shape=False,
skip_img_without_anno=True),
dict(type='Normalize', **img_norm_cfg),
dict(type='DefaultFormatBundle'),
dict(type='Collect',
keys=['img', 'gt_bboxes', 'gt_labels'],
meta_keys=('filename', 'ori_shape', 'img_shape', 'img_norm_cfg',
'pad_shape', 'scale_factor'))
test_pipeline = [
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
# ann_file=data_root + 'train/labelme2coco/train.json',
ann_file=data_root + 'train/annotations/instances_train2017.json',
img_prefix=data_root + 'train/images/',
classes=classes, # 注意这里, 写入自己训练任务的classes信息.
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'train/labelme2coco/trainok_forval.json',
img_prefix=data_root + 'val/images/',
classes=classes, # 注意这里, 写入自己训练任务的classes信息.
pipeline=test_pipeline),
test=dict(