import numpy as np
# 得到所有正样本的索引
z_index = np.array(z.index)
# 下采样就是从多量的样本中抽取一部分数据直到和少量的样本达到平衡,并取其索引
random_f_index = np.random.choice(f.index,len(z),replace = False)
random_f_index = np.array(random_f_index)
# 有了正样本负样本后把它们的索引都拿到手
under_sample_indices = np.concatenate([z_index,random_f_index])
# 根据索引得到下采样所有样本点
under_sample_data = data.iloc[under_sample_indices,:]
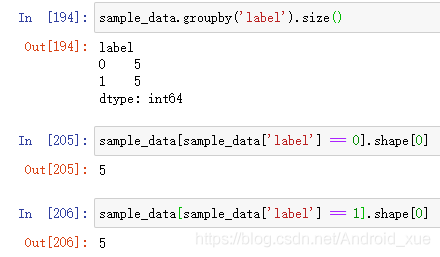
前言由于工作数据量较大,训练模型很少直接单机python,一般都采用SparkML,最近把SparkML的工作使用python简单的写了一下,先写个上下采样,最终目的是为了让正负样本达到均衡(有人问:正负样本必须是1:1吗?1:1效果就一定最好吗?答:不一定)数据准备共20条数据,正样本1共有5条,负样本0共有15条。基础知识准备如何获取dataframe的行数pandas.DataFrame.shape 返回数据帧的形状df.shape[0] 返回行数de.shape[1] 返
一、下采样
所有数据存在DataFrame对象df中。数据分为两类:多数类别和少数类别,数据量相差大。数据预处理已将多数类别的Label标记为1,少数类别的Label标记为0。从多数类中随机抽取样本(抽取的样本数量与少数类别样本量一致)从而减少多数类别样本数据,使数据达到平衡的方式。
import numpy as np
import pandas as pd
def lower_sam...
分类问题中,经常会碰到类别极度不平衡的情况,这个时候可对样本进行上下采样,让训练数据集的类别接近平衡即可。
数据格式是一个dataframe,数据分为两类:多数类别和少数类别,数据量相差大。一般而言一个数据集中负样本数量远远大于正样本,故数据预处理已将多数类别的Label标记为0,少数类别的Label标记为1。以下分别是python实现采样代码:
一.下采样
下采样则是从多数量的类别中随机抽取样本(抽取的样本数量与少数类别样本量一致)从而减少多数量的类别样本数据,使数据达到平衡的方式。
impor
K-Means欠采样python实现
1. K-Means欠采样原理
为解决分类问题中效果受样本集类间不平衡,并提高训练样本的多样性,可以使用K-Means欠采样对样本进行平衡处理。该方法利用K-means方法对大类样本聚类,形成与小类样本个数相同的簇类数,从每个簇中随机抽取单个样本与风险样本形成平衡样本集。K-means欠采样过程如下:
Step1:随机初始化k个聚类中心,分别为uj(1,2,…,k);
Step2:对于大样本xi(1,2,…,n),计算样本到每个聚类中心uj的距离,将xi划分到聚类最小的簇,c(i)为样本i与k个类中距离最近的那个类,c(i)的值为1到k中的一个,则c(i)