

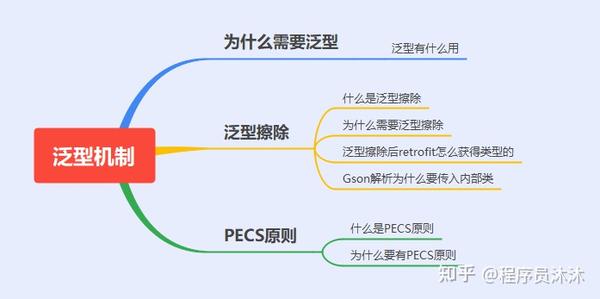
关于Java泛型机制无非就这7个问题

泛型机制是我们开发中的常用技巧,也是面试常见问题
不过泛型机制这个知识点也比较繁杂又不成体系,学了容易忘
本文从几个问题出发梳理
Java
泛型机制知识点,如果对你有用,欢迎点赞~
本文主要包括以下内容
1.我们为什么需要泛型?
2.什么是泛型擦除及泛型擦除带来的一些问题,如
retrofit
怎么获得擦除后的类型,
Gson
怎么获得擦除后的类型?
3.什么是
PECS
原则
本文目录如下

1.我们为什么需要泛型?
我们为什么需要泛型,即泛型有什么用?
首先举两个例子
1.1 求和函数
实际开发中,经常有数值类型求和的需求,例如实现
int
类型的加法, 有时候还需要实现
long
类型的求和 如果还需要
double
类型的求和,又需要重新在重载一个输入是
double
类型的
add
方法。
public int addInt(int x,int y){
return x+y;
public float addFloat(float x,float y){
return x+y;
复制代码如果没有泛型,我们需要写不少重复代码
1.2
List
中添加元素
List list = new ArrayList();
list.add("mark");
list.add("OK");
list.add(100);
for (int i = 0; i < list.size(); i++) {
String name = list.get(i); // 1
System.out.println("name:" + name);
复制代码
1.
list
默认是
Object
类型,因此可以存任意类型数据
2.但是当取出来时,我们并不知道取出元素的类型,就需要进行强制类型转换了,并且容易出错
1.3 泛型机制的优点
从上面的两个例子我们可以直观的得出泛型机制的优点
1.使用泛型可以编写模板代码来适应任意类型,减少重复代码
2.使用时不必对类型进行强制转换,方便且减少出错机会
2.泛型擦除
2.1 什么是泛型擦除?
大家都知道,
Java
的泛型是伪泛型,这是因为
Java
在编译期间,所有的泛型信息都会被擦掉,正确理解泛型概念的首要前提是理解类型擦除。
Java
的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程就是泛型擦除。
举个例子:
public class Test {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<String>();
list1.add("abc");
ArrayList<Integer> list2 = new ArrayList<Integer>();
list2.add(123);
System.out.println(list1.getClass() == list2.getClass());
复制代码
如上
list1.getClass==list2.getClass
返回
true
,说明泛型类型
String
和
Integer
都被擦除掉了,只剩下原始类型
Java
的泛型也可以被称作是伪泛型
- 真泛型:泛型中的类型是真实存在的。
- 伪泛型:仅于编译时类型检查,在运行时擦除类型信息。
看到这里我们可以自然地引出下一个问题,为什么
Java
中的泛型是伪泛型,为什么要这样实现?
2.2 为什么需要泛型擦除?
泛型擦除看起来有些反直觉,有些奇怪。为什么
Java
不能像
C#
一样实现真正的泛型呢?为什么
Java
的泛型要用"擦除"实现
单从技术来说,
Java
是完全
100%
能实现我们所说的
真泛型
,而之所以选择使用泛型擦除主要是从
API
兼容的角度考虑的
导致
Java 5
引入的泛型采用擦除式实现的根本原因是兼容性上的取舍,而不是“实现不了”的问题。
举个例子,
Java
到
1.4.2
都没有支持泛型,而到
Java 5
突然支持泛型了,要让以前编译的程序在新版本的
JRE
还能正常运行,就意味着以前没有的限制不能突然冒出来。
假如在没有泛型的
Java
里,我们有程序使用了
java.util.ArrayList
类,而且我们利用了它可以存异质元素的特性:
ArrayList things = new ArrayList();
things.add(Integer.valueof(42));
things.add("Hello World")
复制代码
为了这段代码在
Java 5
引入泛型之后还必须要继续可以运行,有两种设计思路
1.需要泛型化的类型(主要是容器(
Collections
)类型),以前有的就保持不变,然后平行地加一套泛型化版本的新类型;
2.直接把已有的类型泛型化,让所有需要泛型化的已有类型都原地泛型化,不添加任何平行于已有类型的泛型版。
.NET
在
1.1 -> 2.0
的时候选择了上面选项的1,而
Java
则选择了2。
从
Java
设计者的角度看,这个取舍很明白。
.NET
在
1.1 -> 2.0
的时候,实际的应用代码量还很少(相对
Java
来说),而且整个体系都在微软的控制下,要做变更比较容易;
而
Java
在
1.4.2 -> 5.0
的时候,Java已经有大量程序部署在生产环境中,已经有很多应用和库程序的代码。
如果这些代码在新版本的
Java
中,为了使用
Java
的新功能(例如泛型)而必须做大量源码层修改,那么新功能的普及速度就会大受影响。
2.3 泛型擦除后
retrofit
是怎么获取类型的?
Retrofit
是如何传递泛型信息的?
上一段常见的网络接口请求代码:
public interface GitHubService {
@GET("users/{user}/repos")
Call<List<Repo>> listRepos(@Path("user") String user);
复制代码
使用
jad
查看反编译后的
class
文件:
import retrofit2.Call;
public interface GitHubService
public abstract Call listRepos(String s);
复制代码
可以看到
class
文件中已经将泛型信息给擦除了,那么
Retrofit
是如何拿到
Call<List>
的类型信息的?
我们看一下
retrofit
的源码
static <T> ServiceMethod<T> parseAnnotations(Retrofit retrofit, Method method) {
Type returnType = method.getGenericReturnType();
public Type getGenericReturnType() {
// 根据 Signature 信息 获取 泛型类型
if (getGenericSignature() != null) {
return getGenericInfo().getReturnType();
} else {
return getReturnType();
复制代码
可以看出,
retrofit
是通过
getGenericReturnType
来获取类型信息的
jdk
的
Class
、
Method
、
Field
类提供了一系列获取 泛型类型的相关方法。
以
Method
为例,
getGenericReturnType
获取带泛型信息的返回类型 、
getGenericParameterTypes
获取带泛型信息的参数类型。
问:泛型的信息不是被擦除了吗?
答:是被擦除了, 但是某些(声明侧的泛型,接下来解释) 泛型信息会被
class
文件 以
Signature
的形式 保留在
Class
文件的
Constant pool
中。
通过
javap
命令 可以看到在
Constant pool
中
#5 Signature
记录了泛型的类型。
Constant pool:
#1 = Class #16 // com/example/diva/leet/GitHubService
#2 = Class #17 // java/lang/Object
#3 = Utf8 listRepos
#4 = Utf8 (Ljava/lang/String;)Lretrofit2/Call;
#5 = Utf8 Signature
#6 = Utf8 (Ljava/lang/String;)Lretrofit2/Call<Ljava/util/List<Lcom/example/diva/leet/Repo;>;>;
#7 = Utf8 RuntimeVisibleAnnotations
#8 = Utf8 Lretrofit2/http/GET;
#9 = Utf8 value
#10 = Utf8 users/{user}/repos
#11 = Utf8 RuntimeVisibleParameterAnnotations
#12 = Utf8 Lretrofit2/http/Path;
#13 = Utf8 user
#14 = Utf8 SourceFile
#15 = Utf8 GitHubService.java
#16 = Utf8 com/example/diva/leet/GitHubService
#17 = Utf8 java/lang/Object
public abstract retrofit2.Call<java.util.List<com.example.diva.leet.Repo>> listRepos(java.lang.String);
flags: ACC_PUBLIC, ACC_ABSTRACT
Signature: #6 // (Ljava/lang/String;)Lretrofit2/Call<Ljava/util/List<Lcom/example/diva/leet/Repo;>;>;
RuntimeVisibleAnnotations:
0: #8(#9=s#10)
RuntimeVisibleParameterAnnotations:
parameter 0:
0: #12(#9=s#13)
复制代码
这就是我们
retrofit
中能够获取泛型类型的原因
2.4
Gson
解析为什么要传入内部类
Gson
是我们常用的
json
解析库,一般是这样使用的
// Gson 常用的情况
public List<String> parse(String jsonStr){
List<String> topNews = new Gson().fromJson(jsonStr, new TypeToken<List<String>>() {}.getType());
return topNews;
复制代码
我们这里可以提出两个问题
1.
Gson
是怎么获取泛型类型的,也是通过
Signature
吗?
2.为什么
Gson
解析要传入匿名内部类?这看起来有些奇怪
2.4.1 那些泛型信息会被保留,哪些是真正的擦除了?
上面我们说了,声明侧泛型会被记录在
Class
文件的
Constant pool
中,使用侧泛型则不会
声明侧泛型主要指以下内容
1.泛型类,或泛型接口的声明 2.带有泛型参数的方法 3.带有泛型参数的成员变量
使用侧泛型
也就是方法的局部变量,方法调用时传入的变量。
Gson
解析时传入的参数属于使用侧泛型,因此不能通过
Signature
解析
2.4.2 为什么
Gson
解析要传入匿名内部类
根据以上的总结,方法的局部变量的泛型是不会被保存的
Gson
是如何获取到
List<String>
的泛型信息
String
的呢?
Class
类提供了一个方法
public Type getGenericSuperclass()
,可以获取到带泛型信息的父类
Type
。
也就是说
java
的
class
文件会保存继承的父类或者接口的泛型信息。
所以
Gson
使用了一个巧妙的方法来获取泛型类型:
1.创建一个泛型抽象类
TypeToken <T>
,这个抽象类不存在抽象方法,因为匿名内部类必须继承自抽象类或者接口。所以才定义为抽象类。
2.创建一个 继承自
TypeToken
的匿名内部类, 并实例化泛型参数
TypeToken<String>
3.通过
class
类的
public Type getGenericSuperclass()
方法,获取带泛型信息的父类
Type
,也就是
TypeToken<String>
总结:
Gson
利用子类会保存父类
class
的泛型参数信息的特点。 通过匿名内部类实现了泛型参数的传递。
3.什么是
PECS
原则?
3.1
PECS
介绍
PECS
的意思是
Producer Extend Consumer Super
,简单理解为如果是生产者则使用
Extend
,如果是消费者则使用
Super
,不过,这到底是啥意思呢?
PECS
是从集合的角度出发的
1.如果你只是从集合中取数据,那么它是个生产者,你应该用
extend
2.如果你只是往集合中加数据,那么它是个消费者,你应该用
super
3.如果你往集合中既存又取,那么你不应该用
extend
或者
super
让我们通过一个典型的例子理解一下到底什么是
Producer
和
Consumer
public class Collections {
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
for (int i=0; i<src.size(); i++) {
dest.set(i, src.get(i));
复制代码
上面的例子中将
src
中的数据复制到
dest
中,这里
src
就是生产者,它「生产」数据,
dest
是消费者,它「消费」数据。
3.2 为什么需要
PECS
使用
PECS
主要是为了实现集合的多态
举个例子,现在有这样一个需求,将水果篮子中所有水果拿出来(即取出集合所有元素并进行操作)
public static void getOutFruits(List<Fruit> basket){
for (Fruit fruit : basket) {
System.out.println(fruit);
//...do something other
List<Fruit> fruitBasket = new ArrayList<Fruit>();
getOutFruits(fruitBasket);//成功
List<Apple> appleBasket = new ArrayList<Apple>();
getOutFruits(appleBasket);//编译错误
复制代码
如上所示:
1.将
List<Apple>
传递给
List<Fruit>
会编译错误。
2.因为虽然
Fruit
是
Apple
的父类,但是
List<Apple>
和
List<Fruit>
之间没有继承关系
3.因为这种限制,我们不能很好的完成取出水果篮子中的所有水果需求,总不能每个类型都写一遍一样的代码吧?
使用
extend
可以方便地解决这个问题
/**参数使用List<? extends Fruit>**/
public static void getOutFruits(List<? extends Fruit> basket){
for (Fruit fruit : basket) {
System.out.println(fruit);
//...do something other
public static void main(String[] args) {
List<Fruit> fruitBasket = new ArrayList<>();
fruitBasket.add(new Fruit());
getOutFruits(fruitBasket);