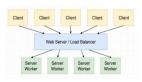
一、同步与异步
- #同步编程(同一时间只能做一件事,做完了才能做下一件事情)
- <-a_url-><-b_url-><-c_url->
- #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后)
- <-a_url->
- <-b_url->
- <-c_url->
- <-d_url->
- <-e_url->
- <-f_url->
- <-g_url->
- <-h_url->
- <--i_url-->
- <--j_url-->
- import asyncio
- #函数名:做现在的任务时不等待,能继续做别的任务。
- async def donow_meantime_dontwait(url):
- response = await requests.get(url)
- #函数名:快速高效的做任务
- async def fast_do_your_thing():
- await asyncio.wait([donow_meantime_dontwait(url) for url in urls])
- #下面两行都是套路,记住就好
- loop = asyncio.get_event_loop()
- loop.run_until_complete(fast_do_your_thing())
tips:
await表达式中的对象必须是awaitable
requests不支持非阻塞
aiohttp是用于异步请求的库
- import asyncio
- import requests
- import time
- import aiohttp
- urls = ['https://book.douban.com/tag/小说','https://book.douban.com/tag/科幻',
- 'https://book.douban.com/tag/漫画','https://book.douban.com/tag/奇幻',
- 'https://book.douban.com/tag/历史','https://book.douban.com/tag/经济学']
- async def requests_meantime_dont_wait(url):
- print(url)
- async with aiohttp.ClientSession() as session:
- async with session.get(url) as resp:
- print(resp.status)
- print("{url} 得到响应".format(url=url))
- async def fast_requsts(urls):
- start = time.time()
- await asyncio.wait([requests_meantime_dont_wait(url) for url in urls])
- end = time.time()
- print("Complete in {} seconds".format(end - start))
- loop = asyncio.get_event_loop()
- loop.run_until_complete(fast_requsts(urls))
gevent简介
gevent是一个python的并发库,它为各种并发和网络相关的任务提供了整洁的API。
gevent中用到的主要模式是greenlet,它是以C扩展模块形式接入Python的轻量级协程。 greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
requests库是阻塞式的,为了将requests同步更改为异步。只有将requests库阻塞式更改为非阻塞,异步操作才能实现。
而gevent库中的猴子补丁(monkey patch),gevent能够修改标准库里面大部分的阻塞式系统调用。这样在不改变原有代码的情况下,将应用的阻塞式方法,变成协程式的(异步)。
- from gevent import monkey
- import gevent
- import requests
- import time
- monkey.patch_all()
- def req(url):
- print(url)
- resp = requests.get(url)
- print(resp.status_code,url)
- def synchronous_times(urls):
- """同步请求运行时间"""
- start = time.time()
- for url in urls:
- req(url)
- end = time.time()
- print('同步执行时间 {} s'.format(end-start))
- def asynchronous_times(urls):
- """异步请求运行时间"""
- start = time.time()
- gevent.joinall([gevent.spawn(req,url) for url in urls])
- end = time.time()
- print('异步执行时间 {} s'.format(end - start))
- urls = ['https://book.douban.com/tag/小说','https://book.douban.com/tag/科幻',
- 'https://book.douban.com/tag/漫画','https://book.douban.com/tag/奇幻',
- 'https://book.douban.com/tag/历史','https://book.douban.com/tag/经济学']
- synchronous_times(urls)
- asynchronous_times(urls)
gevent:异步理论与实战
gevent库中使用的最核心的是Greenlet-一种用C写的轻量级python模块。在任意时间,系统只能允许一个Greenlet处于运行状态
一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
串行和异步
高并发的核心是让一个大的任务分成一批子任务,并且子任务会被被系统高效率的调度,实现同步或者异步。在两个子任务之间切换,也就是经常说到的上下文切换。
同步就是让子任务串行,而异步有点影分身之术,但在任意时间点,真身只有一个,子任务并不是真正的并行,而是充分利用了碎片化的时间,让程序不要浪费在等待上。这就是异步,效率杠杆的。
gevent中的上下文切换是通过yield实现。在这个例子中,我们会有两个子任务,互相利用对方等待的时间做自己的事情。这里我们使用gevent.sleep(0)代表程序会在这里停0秒。
- import gevent
- def foo():
- print('Running in foo')
- gevent.sleep(0)
- print('Explicit context switch to foo again')
- def bar():
- print('Explicit context to bar')
- gevent.sleep(0)
- print('Implicit context switch back to bar')
- gevent.joinall([
- gevent.spawn(foo),
- gevent.spawn(bar)
- ])
运行的顺序:
- Running in foo
- Explicit context to bar
- Explicit context switch to foo again
- Implicit context switch back to bar
同步异步的顺序问题
同步运行就是串行,123456...,但是异步的顺序是随机的任意的(根据子任务消耗的时间而定)
- import gevent
- import random
- def task(pid):
- """
- Some non-deterministic task
- """
- gevent.sleep(random.randint(0,2)*0.001)
- print('Task %s done' % pid)
- #同步(结果更像串行)
- def synchronous():
- for i in range(1,10):
- task(i)
- #异步(结果更像乱步)
- def asynchronous():
- threads = [gevent.spawn(task, i) for i in range(10)]
- gevent.joinall(threads)
- print('Synchronous同步:')
- synchronous()
- print('Asynchronous异步:')
- asynchronous()
Synchronous同步:
- Task 1 done
- Task 2 done
- Task 3 done
- Task 4 done
- Task 5 done
- Task 6 done
- Task 7 done
- Task 8 done
- Task 9 done
Asynchronous异步:
- Task 1 done
- Task 5 done
- Task 6 done
- Task 2 done
- Task 4 done
- Task 7 done
- Task 8 done
- Task 9 done
- Task 0 done
- Task 3 done
同步案例中所有的任务都是按照顺序执行,这导致主程序是阻塞式的(阻塞会暂停主程序的执行)。
gevent.spawn会对传入的任务(子任务集合)进行进行调度,gevent.joinall方法会阻塞当前程序,除非所有的greenlet都执行完毕,程序才会结束。
实现gevent到底怎么用,把异步访问得到的数据提取出来。
在有道词典搜索框输入“hello”按回车。观察数据请求情况 观察有道的url构建。
分析url规律
- #url构建只需要传入word即可
- url = "http://dict.youdao.com/w/eng/{}/".format(word)
解析网页数据
- def fetch_word_info(word):
- url = "http://dict.youdao.com/w/eng/{}/".format(word)
- resp = requests.get(url,headers=headers)
- doc = pq(resp.text)
- pros = ''
- for pro in doc.items('.baav .pronounce'):
- pros+=pro.text()
- description = ''
- for li in doc.items('#phrsListTab .trans-container ul li'):
- description +=li.text()
- return {'word':word,'音标':pros,'注释':description}
因为requests库在任何时候只允许有一个访问结束完全结束后,才能进行下一次访问。无法通过正规途径拓展成异步,因此这里使用了monkey补丁
- import requests
- from pyquery import PyQuery as pq
- import gevent
- import time
- import gevent.monkey
- gevent.monkey.patch_all()
- words = ['good','bad','cool',
- 'hot','nice','better',
- 'head','up','down',
- 'right','left','east']
- def synchronous():
- start = time.time()
- print('同步开始了')
- for word in words:
- print(fetch_word_info(word))
- end = time.time()
- print("同步运行时间: %s 秒" % str(end - start))
- #执行同步
- synchronous()
- import requests
- from pyquery import PyQuery as pq
- import gevent
- import time
- import gevent.monkey
- gevent.monkey.patch_all()
- words = ['good','bad','cool',
- 'hot','nice','better',
- 'head','up','down',
- 'right','left','east']
- def asynchronous():
- start = time.time()
- print('异步开始了')
- events = [gevent.spawn(fetch_word_info,word) for word in words]
- wordinfos = gevent.joinall(events)
- for wordinfo in wordinfos:
- #获取到数据get方法
- print(wordinfo.get())
- end = time.time()
- print("异步运行时间: %s 秒"%str(end-start))
- #执行异步
- asynchronous()
我们可以对待爬网站实时异步访问,速度会大大提高。我们现在是爬取12个词语的信息,也就是说一瞬间我们对网站访问了12次,这还没啥问题,假如爬10000+个词语,使用gevent的话,那几秒钟之内就给网站一股脑的发请求,说不定网站就把爬虫封了。
将列表等分为若干个子列表,分批爬取。举例我们有一个数字列表(0-19),要均匀的等分为4份,也就是子列表有5个数。下面是我在stackoverflow查找到的列表等分方案:
- seqence = list(range(20))
- size = 5 #子列表长度
- output = [seqence[i:i+size] for i in range(0, len(seqence), size)]
- print(output)
- chunks = lambda seq, size: [seq[i: i+size] for i in range(0, len(seq), size)]
- print(chunks(seq, 5))
- def chunks(seq,size):
- for i in range(0,len(seq), size):
- yield seq[i:i+size]
- prinT(chunks(seq,5))
- for x in chunks(req,5):
- print(x)
数据量不大的情况下,选哪一种方法都可以。如果特别大,建议使用方法3.
- import requests
- from pyquery import PyQuery as pq
- import gevent
- import time
- import gevent.monkey
- gevent.monkey.patch_all()
- words = ['good','bad','cool',
- 'hot','nice','better',
- 'head','up','down',
- 'right','left','east']
- def fetch_word_info(word):
- url = "http://dict.youdao.com/w/eng/{}/".format(word)
- resp = requests.get(url,headers=headers)
- doc = pq(resp.text)
- pros = ''
- for pro in doc.items('.baav .pronounce'):
- pros+=pro.text()
- description = ''
- for li in doc.items('#phrsListTab .trans-container ul li'):
- description +=li.text()
- return {'word':word,'音标':pros,'注释':description}
- def asynchronous(words):
- start = time.time()
- print('异步开始了')
- chunks = lambda seq, size: [seq[i: i + size] for i in range(0, len(seq), size)]
- for subwords in chunks(words,3):
- events = [gevent.spawn(fetch_word_info, word) for word in subwords]
- wordinfos = gevent.joinall(events)
- for wordinfo in wordinfos:
- # 获取到数据get方法
- print(wordinfo.get())
- time.sleep(1)
- end = time.time()
- print("异步运行时间: %s 秒" % str(end - start))
- asynchronous(words)