


一文读懂社会网络分析(SNA)理论、指标与应用

硕士求学之路上SNA学习心得的精华之作,欢迎感兴趣的同学交流、点赞、收藏 ♥ !全文约8000字,且持续更新中,适合长期品读~
对于网络,我们该如何构建、衡量、应用和学习它?我会努力给诸位一个全面的答案。
1 引言
开新坑! 社交网络分析(又称复杂网络、社会网络, S ocial N etwork A nalysis)是诞生于数学图论、计算机科学、物理学的交叉碰撞中的一门有趣的学科。
缘起: 我研究SNA已经有近2年的时光,一路坎坷走来有很多收获、踩过一些坑,也在线上给很多学生讲过SNA的入门知识,最近感觉有必要将心得和基础框架分享出来, 抛砖引玉 ,让各位对SNA感兴趣的同学们一起学习进步。我的能力有限,如果有不足之处大家一起交流,由于我的专业的影响,本文的SNA知识可能会带有情报学色彩。
面向人群: 优先人文社科类的无代码学习,Python、R的SNA包好用是好用,但是对我们这这些社科的同学来说门槛太高,枯燥的代码首先就会让我们丧失学习兴趣。
特征: 类综述文章,主要目的是以 通俗的语言 和精炼的框架带领各位快速对SNA领域建立起一个全面的认知,每个个关键概念会附上链接供感兴趣的同学深入学习。
开胃菜: SNA经典著作分享 《网络科学引论》纽曼 (访问密码 : v9d9g3)
2 概述篇:什么是网络?我们从哪些角度研究它?
1) 认识网络
SNA中所说的网络是由节点(node,图论中称顶点vertex)和边(edge)构成,如下图。每个节点代表一个实体,可以是人、动物、关键词、神经元;连接各节点的边代表一个关系,如朋友关系、敌对关系、合作关系、互斥关系等。最小的网络是由两个节点与一条边构成的二元组。
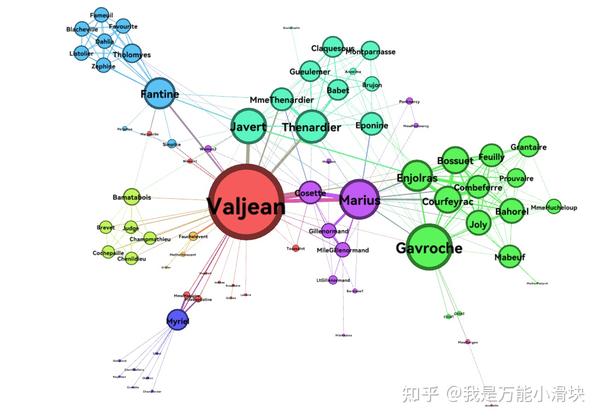

2) 构建网络就是建模
马克思说过, “人的本质在其现实性上,它是一切社会关系的总和。” 事实上,当我们想快速了解一个领域,无论该领域是由人、知识、神经元乃至其他实体集合构成,利用SNA的方法将实体及其相互关系进行抽象和网络构建,我们就完成了对某一领域的“建模”,这个模型就是网络图,拿科学网络计量学家陈超美的观点来说,借助网络图,“一图胜千言,一览无余”。
3) 社会网络类型
此处展示常见且常用的网络类型名词,想要具体了解可以点击链接仔细查看!
- 网络中节点的来源集合异同
- 一模网络 one-mode
- 二模网络 two-mode
- 隶属网络 affiliation network
- 视角:
- 自我网络 ego network
- 全局网络
- 边权重
- 关系是否有方向
4) 网络分析的5大中心问题
SNA可以帮助我们快速了解该网络中的分布格局和竞争态势, “孰强孰弱,孰亲孰远,孰新孰老,孰胜孰衰”, 这16字箴言是我学习SNA总结的精华所在,初中级甚至高级的社会网络分析学习几乎完全就是围绕着这四个方面开展,后面将要讲到的理论与方法皆为此服务,希望同学们可以重点关注。下面我将简要介绍16个字的内涵:
- 孰强孰弱-个体能力分析: 网络中哪些节点至关重要,哪些节点可以忽略?比如当我在某一社区进行广告投放,我应该寻找哪个节点(意见领袖KOL发现)扩散广告信息可以获得最大信息传递和回报?
- 孰亲孰远-群体结构分析: 网络中是否存在关系紧密的群体?如果有,则如何发现它们?不同群体之间有何差异?比如在某科学领域中是否存在紧密合作的科学家群体,不同群体有何差异?
- 孰新孰老-时间演变分析: 网络是如何发展的,早期网络与晚期网络有何差异?比如随着红楼梦剧情的推进,哪些人消失了,哪些新角色登场了?演变分析可以和个体、群体分析组合,获得更多信息。
- 孰同孰异-实体关系分析: 网络之中哪些节点在某些方面相似或哪些节点之间更有可能产生新的连接关系,这个问题引申出名为链接预测的学问。
- 孰胜孰衰-综合情报决策: 本问题是网络分析的核心目标,它要求我们综合研判当前已收集的群体、个体、时间情报,概括和推断目标领域的分布格局和发展态势,可以帮助政策制定、产业布局、学术规划、人际交往、公司组织调整等,是网络分析的社会价值的体现。
3 数据篇:建构网络需要哪些数据?
看了很多教程都关注于如何分析和计算,但是它们往往忽略最初的也是最重要的网络数据建立,毕竟巧妇难为无米之炊。网络数据由于其多维和复杂性,收集或建立起来将比一般的二维表数据要麻烦很多,许多文献在谈到如何建立网络时总是说“代码处理”或“人工收集”之后一笔带过,让许多我这样的萌新一脸懵逼。
1) SNA常用的数据输入格式
- 边关系数据(边列表 edge list): 包含一列源节点,一列目标节点,和关系权重(比如说两个节点的合作次数)

- 节点属性数据(节点列表 node list): 存储前面关系文件中出现的所有或部分节点实体自身包含的属性。
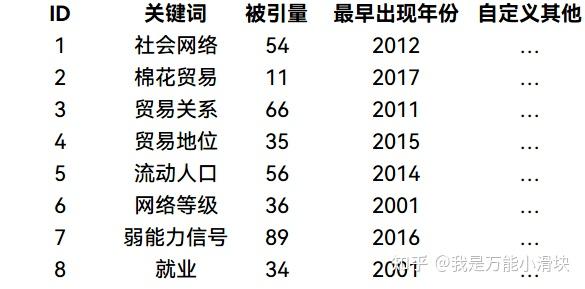

有了这两种数据,常见的SNA软件如Gephi或者Pajek就都可以支持了。
2) 如何处理网络数据?
实际上,以最常见的合作/共现关系为例,要建立这种类型的网络数据,Excel 2016以上版本都可以,并且不会受到数据量处理的影响,虽然VOSviewer或者Citespace这些软件也可以直接读取一些特定格式的文献数据,但是使用是受到格式和数据量的限制,应用场景有限,而excel则不然。
如下图数据,我们将利用关键词列的数据建立关键词共现网络,对于作者合作网络也是一样的道理,因为从数据的角度,合作与共现并没有区别。
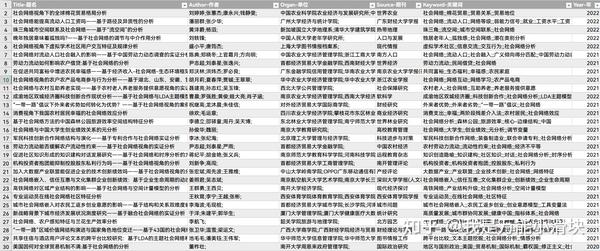

将其清洗后导入excel,使用【数据】选项卡的“来自表格/区域”就可以将文献数据导入excel2016版后自带的大数据处理插件PowerQuery中,PQ是微软为了拓展excel仅能存储100万行数据(很多时候十万行就很卡了)的弊端而打造的,它非常擅长处理百万乃至千万级的数据量,现在已被集成到微软的Power BI软件中。
下面的视频是如何将一个单元格内的多个实体(关键词)拆开,并逆透视转换成多行共现关系的数据的操作过程。
 PowerQuery 处理网络共现数据
https://www.zhihu.com/video/1509648599621644288
PowerQuery 处理网络共现数据
https://www.zhihu.com/video/1509648599621644288
拓展阅读:
4 理论篇:SNA有哪些研究理论?
1)网络全局衡量
- 网络规模
- 节点数
- 关系数
- 平均度 Average degree: 网络中所有节点的度的平均值
- 网络结构的连通性
- 密度 Density : 网络中实际存在的边数 M 与最大可能的边数之比;真实的大规模网络普遍表现出稀疏性:
- 网络直径 Diameter :网络中任意两个节点之间的距离的最大值称为网络的直径
- 平均路径长度 Average Path length : 任意两个节点之间的距离的平均值,存在连通路径的节点对之间的距离的平均值
- 最短路径 Shortest path: 网络中两个节点 i 和 j 之间的最短路径是指连接这两个节点的边数最少的路径,也称为测地路径(Geodesic path)。(它的计算结果一般以矩阵形式表现,因为要计算每一个节点到其他所有节点的最短路径)
- 桥( bridge ): 如果网络中的一条边删除后,会导致这条边的两个端结点不再连接,则这条边就是沟通两个节点的唯一边,即“桥”。
- 网络模型
- 小世界特性 Small World
- 全局聚类系数越大;
- 平均最短路径越短;
- 则小世界特性越强。
- 无标度网络 Free-Scale Network
- 复杂网络的无标度性就是一种非同质性 ,是网络结构的一种“序”。
- 在非标度网络中存在极少数具有大量连接的“核心节点” (Hub-node)和大量具有少量连接的“末梢节点”。这样的网络是不均匀的,或者是“非同质的”。
- 两个特征:
- 增长特性 :网络的规模是不断扩大的
- 优先连接 :新的节点更倾向于与那些具有较高连接度的 hub 节点连接
- 推荐一篇无标度网络超经典的文献,是 BARABÁSI 大佬20多年前写的: Emergence of Scaling in Random Networks 。
- ER随机图
- 连通网络
- 连通网络要求该子图网络中的任意两个顶点之间都存在路径(连通性);且网络中不属于该子图的任一顶点与该子图中的任一顶点之间不存在路径(孤立性)。
- 无向图中的节点数最多的极大连通子图,称为 连通分量 Giant component
- 有向图场景
- 强连通图(Strongly connected subgraph): 如果对于图中任意一对顶点 u 和 v ,都既存在一条从顶点 u 到顶点 v 的路径也存在一条从顶点 v 到顶点 u 的路径。则该有向图称为是强连通的
- 弱连通图(Weakly connected subgraph): 如果把图中所有的 有向边 都看做是无向边后所得到的无向图是连通的。则该有向图称为是弱连通的
2)网络节点重要性衡量
- 局部影响力衡量 Local
- 度数中心性 Degree Centrality
- 与节点直接相连的边的数目,网络中一个节点的价值首先取决于这个节点在网络中所处的位置,位置越中心的节点其价值也越大
- 有向网络情况
- 出度 (Out-degree) 从节点 i 指向其他节点的边的数目
- 入度 (In-degree) 从其他节点指向节点 i 的边的数目
- 特征向量中心性 Eigenvector Centrality
- 一个节点的重要性既取决于其邻居节点的数量(即该节点的度),也取决于其邻居节点的重要性。
- 换句话说,在一个网络中,如果一个人拥有很多重要的朋友,那么他也将是非常重要的。
- 基于超链接的主题搜索 HITS算法
- 来源于网络排序算法
- HITS将网页(或节点)分成两类:
- Hub类: Hub类节点似于常见的门户网站,像hao123首页之类的,它提供了大量高质量的网页链接;在文献计量学的角度则更像是综述型文献;
- Authority类: Authority节点更像是用户希望访问的网站或者是优质文献,比如搜索的时候我们希望用百度,购物的时候我们希望进入淘宝和京东等。Hub页面相当于充当了一个中间枢纽的角色,对于用户而言,他们更关注高Authority的网页。
- PageRank: 衡量有向网络中节点重要性的指标,来自受欢迎的网页的跳转应该重于不太受欢迎的网页的跳转。
- 半局部中心性 Semi-local Centrality 相比于度中心性的一阶邻居信息,半局部中心性考虑了节点的四阶邻居信息,因此其准确性比度中心性更好,计算复杂度比中介中心性这些全局指标更低。
- 聚类系数 Clustering Coefficient :衡量节点的邻居节点之间也相互连接的程度,聚类系数越大,网络的小团体现象越严重;反应了网络或节点的信息扩散能力
- 全局影响力衡量 Global
- 结构洞
- 指网络中拥有互补的信息来源的两个个体之间未连接形成的空缺。伯特引入这一概念是为了解释 社会资本 差异的根源。处于结构洞位置的节点具有强大的信息控制优势。
- 几种常见的衡量方式( 参考 )
- 中介中心性 Betweeness centrality:
- 表示一个网络中经过该结点的最短路径的数量。在一个网络中,节点的介数越大,那么它在结点间的通信中所起的控制作用也越大。
- 计算网络中任意两个节点的所有最短路径,如果这些最短路径中很多条都经过了某个节点,那么就认为这个节点的介中心性高。
- 网络约束系数 Constraint
- 等级度 Hierarchy
- 有效规模 Effective size :非冗余联系人的总和
- 桥数 bridge numbers
- 桥接中心度 Bridging Centrality :“桥接中心性区分的节点很好地位于高度连通区域之间的连接位置。桥接中心度可以区分桥接节点、流经它们的信息更多的节点以及高度连接区域之间的位置,而其他中心度度量则不能。”
- 紧密中心性 Closeness centrality
- 如果节点到图中其他节点的最短距离都很小,那么它的接近中心性就很高。相比中介中心性,接近中心性更接近 几何上的中心位置 ;
- 一个中心结点应该能更快地到达网络内的其他结点;
- 计算一个结点到网络内其他所有结点的平均距离的倒数。
3)网络群体(社区)发现
在社交网络中,用户之间通过互相的关注关系构成了整个网络的结构。在这样的网络中,有的用户之间的连接较为紧密,有的用户之间的连接关系较为稀疏。其中连接较为紧密的部分可以被看成一个社区,其内部的节点之间有 较为紧密 的连接,而在两个社区间则相对连接 较为稀疏。 Community detection的目标是要探测网络中的“块”cluster或是“社团”community。 以下常用的发现算法在Gephi或Pajek软件中 可以实现,gephi可能需要安装插件。
- 社区划分标准-- 模块度(Modularity)
- 模块度用来衡量一个社区的划分是不是相对比较好的结果;
- 取值为[0, 1]。当模块性接近0时,表明网络中不存在社团结构,即网络中的节点是随意相连的;随着模块化系数的增加,社团结构越来越清晰;
- 一个相对好的结果在社区内部的节点相似度较高,而在社区外部节点的相似度较低。
- 自顶向下划分的思想
- G-N算法 : 迭代删除介数高的桥类型的边,使得网络自顶向下分裂。
- K-核与K-壳(K-core & K-shell)
- K-核网络是一个网络中所有节点度值不小于 K 的节点组成的连通块,也是一种粗粒度的节点重要性分类法。
- 由外向里不断剥离弱连接的节点,发现最核心子网络
- 应用推荐: 微博关注关系网络K-核结构实证分析
- 自底向上划分的思想
- Fast Unfolding算法 / Louvain算法 : 基本思想是网络中节点尝试遍历所有邻居的社区标签,并选择最大化模块度modularity增量的社区标签,直到所有节点都不能通过改变社区标签来增加模块度。
- CPM(派系过滤算法) : 算法首先提取网络中不属于更大的完全子图的所有完全子图(或称派系, clique ),并基于派系重叠关系进行层次聚类。
- Statistical Inference : 较新的统计推断算法
- 链路预测的经典方法(又称节点相似性)
- 共同邻居指标 (Common Neighbor,CN):共同邻居越多,节点之间越相似,其思想类似于Jaccard系数;
- Admic-Adar指标 (AA):AA指标在CN的基础上进一步考虑了节点的度,相当于是加权的CN算法;
- 资源分配指标 (Resource Allocation,RA):AA指标的变体,对节点度开根号后再加权;
- 局部路径指标 (Local Path,LP)
- 互惠性 Reciprocity
- 有向网络中,衡量网络中两个结点形成相互连接的程度;
- 比如在微博中如果我关注了A用户,那么A用户也关注我的概率有多大,相互关注便形成了互惠
- 也称相互性,它与传递性一起成为研究 三元闭包结构 的重要方法。
- 网络同配性 Assortativity: 网络中的度相关系数,衡量网络是否存在度数大的节点更多地和大的节点连接的倾向,即物以类聚,人以群分的程度。
5 工具篇:用什么软件研究网络?
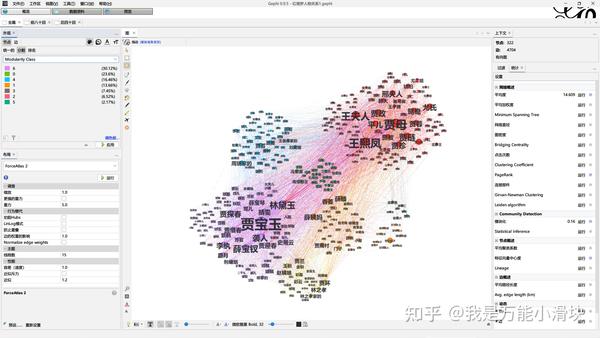
1) Gephi ( 下载 )
Gephi是我最推荐的SNA工具,它界面友好,一键计算,性能强大,尤其是画的图效果远胜同类软件,被誉为“SNA界面的Photoshop”。

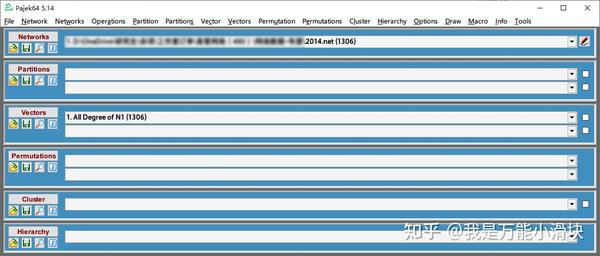
2) Pajek ( 下载 )
Pajek是大型复杂网络分析与可视化工具,可以分析9亿+个顶点规模的网络,在计算性能和计算功能的丰富性方面远胜Gephi,但画图功能和友好性略弱。
对我而言,pajek更像是一个计算工具,gephi则是综合绘图和分析工具,我一般的工作流程是,在excel中完成数据预处理,导入gephi绘图和整理网络,并用gephi导出pajek的.net文件格式并导入pajek计算gephi中无法完成的如结构洞指标的计算。

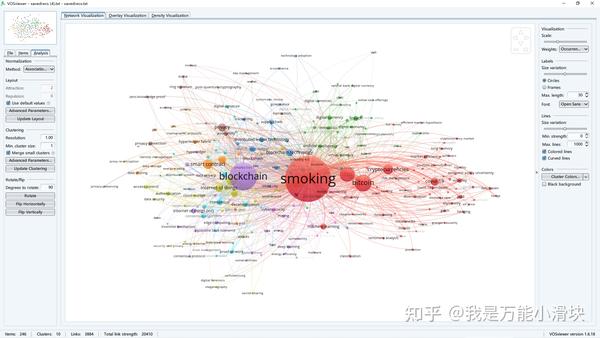
3) VOSviewer ( 下载 )
VOSviewer不是一个真正意义上的SNA软件,但是它具有无与伦比的用户友好性,可以在几分钟内学习并快速完成文献引用网络、关键词共现网络、作者合作网络的构建和计算。最近VOSviewer推出了 在线版本 ,对于分享和展示网络结果非常有帮助,提升展示美感。

4) UCINET
5) R与python的包:igraph+NetworkX
以下两个主要用于网络数据清洗和整理
6) Excel (没想到吧)
- B站资源太多了, 搜索_哔哩哔哩-bilibili
- 我的建议路径: ①基本操作;②数据透视表;③各类公式,尤其是新推出的xlookup、filter、unique等强力函数;④power query与power pivot;⑤Power BI;⑥PPT与美学训练
7) 正则表达式
- SPSS和python著名讲师张文彤也提供了RE的课程: 正则表达式轻松入门_哔哩哔哩_bilibili
- 正则表达式验证和交互编写的在线工具: regex101: build, test, and debug regex
6 应用篇:学了SNA有什么用?
文献计量网络是我的主要研究方向,下面几篇是我之前创作过的有关社会网络或SNA加持下的文献计量学的相关文章,欢迎大家与我交流!
