

Python学习笔记(2021年10月30日更新)

一、安装和配置Python
要一个给力的VPN
安装Pandas失败的主要原因是VPN不得力,换了一个ExpressVPN,立刻就解决了。
无法安装库的pip版本问题
用下面的命令行解决了。
python.exe -m pip install --upgrade pipPython安装在哪里
在命令行输入where python,就能知道你的Python安装在哪个目录下了。
这个是你Python安装的位置,安装库要在此目录下,与你的项目放置的位置是不同概念。
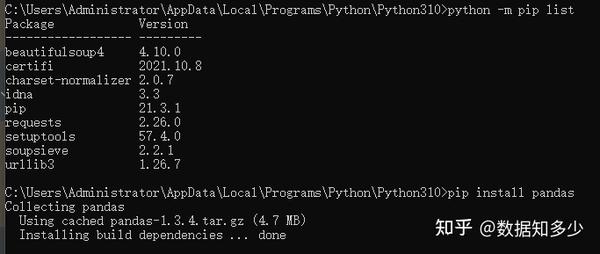
python -m pip list
安装PyCharm
Python requests library - explained with examples | GoLinuxCloud
网上有些反应安装pandas库时会出现问题,提示好像是pip的原因。
这时候大概是自己的pip版本太久啦。所以最好先在cmd更新一下pip好了。
PyCharm的文件夹变动后的Interpreter要如何设置
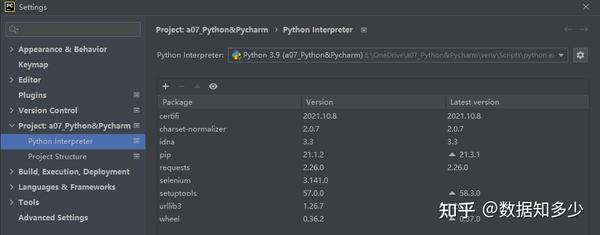
这是要设PyCharm的解释器位置,不是Python的安装位置,可参照如下链接:
pycharm无法运行?系统找不到指定的文件?解决办法及其中的一个小坑_unseven的博客-CSDN博客_pycharm运行找不到指定文件
安装Request库
python中requests库使用方法详解
官方教程python-requests.org/en/latest/api/
JSON格式
JSON Syntax Rules
- Data is in name/value pairs 数据以键与值成对出现,要用双引号吗?没有提到
- Data is separated by commas 数据用逗号分隔
- Curly braces hold objects 对象用大括号{}包起来
- Square brackets hold arrays 数组用方括号[]
许茂:python的dict和json数据有什么区别?
RUNOOB上的JSON 语法 | 菜鸟教程
http://www. runoob.com/ 翻译自 w3schools.com (访问需要工具),重新排版,w3cschool提供的中文版是依托于Google翻译的,所以质量你懂得。
# 是将jason格式转为Python对象
aray = json.loads(response.text)['values']
{"values":[["课程","分数",null],["语文",78,null],["数学",80,null],["英语",100,null],[null,null,null],[null,null,null]]}
以上是jason格式,看里面的冒号、键、值,但其中的值是个二维数组,这是它复杂的一面。
[['课程', '分数', None], ['语文', 78, None], ['数学', 80, None], ['英语', 100, None], [None, None, None], [None, None, None]]
注意是loads不是load.
以下代码的核心部分,在最下面,来自 stackoverflow/writing-a-python-list-of-lists-to-a-csv-file
#以下是通过API将JASON格式,二维数组的值,取得后通过csv库将其转为csv,比较有通用性。
import requests
import json
import csv
from dataclasses
import make_dataclass
import pandas as pd
import numpy
url = "https://shimo.im/lizard-api/files/3g36PwQGv6prYHj3/sheets/values?range=工作表1"
# 注意上面这个url是在ZY我的桌面中的,下面的headers是与此相匹配的,而且是公开的,如果不公开,也会出错。如果是我的空间中的,这个headers是要重新匹配,不然怎么就不对。
# https://shimo.im/sheets/3g36PwQGv6prYHj3/MODOC/ 《无标题》,可复制链接后用石墨文档 App 或小程序打开
payload={}
headers = {
'Cookie': 'acw_tc=2760777c16354039211285318ed1badd8bedac2629d80efeb6cf12f42f6174; deviceId=09329498-58f7-4d77-8e04-04384150d75d; deviceIdGenerateTime=1635403921137'
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)
response.encoding="uft_8"
#将json格式内容变为dictionary,再取得其中的values
aray = json.loads(response.text)['values']
# print(aray)
# #定义其中的行为数组的第一行即0这一串值;将row定义为后面从第2行开始的所有的
# cols = aray[0]
# rows = aray[1:]
#定义pandas的行和列,与前面的相匹配
# df = pd.DataFrame(data=make_dataclass(response.text))
#将pd的表导出为csv格式
# df.to_csv('随便14.csv',index=False, encoding='GB18030')
# pdObj = pd.read_json(response.text, orient='index')
# print(pdObj)
with open("out.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerows(aray)1)将JSON格式通过json.loads转变为字典,并取得其中的values
2)将字典的行标题,即第一行,与后面的记录,即第二行以后的,分离出来。
3)通过pandas的dataframe取得其值。
4)最后导出需要的格式。
import json
# JSON string
employee = '{"id":"09", "name": "Nitin", "department":"Finance"}'
# Convert string to Python dict
employee_dict = json.loads ( employee )
print ( employee_dict )
print ( employee_dict['name'] )

安装pandas库
import requests
r=requests.get("http://www.baidu.com")
r.status_code
r.encoding='utf-8'
print(r.status_code)
print(r.text)Requests库是什么
是获得网上的网址信息。代码中全部为小写requests。
官网中的Requests: HTTP for Humans
headers是应网站要求提供,如你的身份验证、你的浏览器类型和版本等等
# 以下是抓取网页的通用代码库
import requests
def getHTMLText(url):
r=requests.get(url,timeout=30)
r.raise_for_status() #如果状态不是200,引发异常
r.encoding=r.apparent_encoding
return r.text
except:
return"产生异常"
#以下意思是如果是本模块执行时,下面就要执行。如果是引用本模块,只是用其中的函数,下面的这段语句就不要执行。
if __name__ == '__main__':
url='http://www.baidu.com'
print(getHTMLText(url))如何理解if __name__ == '__main__':
以下意思是如果是本模块执行时,下面就要执行。如果是引用该模块,在if _ name __的执行体中的内容,不会被执行。
你有个主程序,要调用N个子程序,为确保运行检测正常,每个子程序时,你都会安排一些测试的内容,如print看看正常与否,但正式使用时,这些内容不希望看出来,因为样显得主题不突出,什么都显示出来了,太啰嗦了。
这时在子程序的测试范围内容前面加上if __name__ == '__main__':这些范围内的程序只在子程序中执行,主程序调用时是不会被执行的。
if __name__ == '__main__':正确理解
学习HTML
注释的样式
<!--下面那行表达式-->
换行
<br>
Convert an HTML table into excel - 将网页的表格转存为Excel
# Importing pandas
# 前提你要提前安装好pandas的库
import pandas as pd
# The webpage URL whose table we want to extract
url = "https://www.geeksforgeeks.org/extended-operators-in-relational-algebra/"
# Assign the table data to a Pandas dataframe
table = pd.read_html(url)[0]
# Store the dataframe in Excel file
table.to_excel("data.xlsx")Pandas库
官网大全https://pandas.pydata.org/很不错
Pandas for Data Wrangling - tutorial, cheat sheet


通过pandas直接取得jason
以下是最简单的四步了取得其值并转为指定格式
注意的是其取得的URL比较麻烦,涉及权限。另一个是其JSON格式比较复杂,是嵌套了二维数组在里面。{"values":[["课程","分数"],["语文",78],["数学",80],["英语",100]]},而且标题没有区分开,与记录在一起。如果没有上述原因,步骤会更加简单。
#coding:utf-8
import requests
import json
import csv
from dataclasses import make_dataclass
import pandas as pd
import numpy
#第一步取得URL的内容
url = "https://shimo.im/lizard-api/files/3g36PwQGv6prYHj3/sheets/values?range=工作表1"
# 注意上面这个url是在我的桌面中的,下面的headers是与此相匹配的,而且是公开的,如果不公开,也会出错。如果是我的空间中的,这个headers是要重新匹配,不然怎么就不对。
# https://shimo.im/sheets/3g36PwQGv6prYHj3/MODOC/ 《无标题》,可复制链接后用石墨文档 App 或小程序打开
payload={}
headers = {
'Cookie': 'acw_tc=276777880777c16354039211285318ed1badd8bedac2629d80efeb6cf12f42f6174; deviceId=09329498-58f7-4d77-8e04-04384150d75d; deviceIdGenerateTime=1635403921137'
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)
response.encoding="uft_8"
#第二步将json格式内容变为dictionary,再取得其中的values
aray = json.loads(response.text)['values']
print(aray)
# #定义其中的行为数组的第一行即0这一串值;将row定义为后面从第2行开始的所有的
# cols = aray[0]
# rows = aray[1:]
#定义pandas的行和列,与前面的相匹配
#第三步是将字典中的值传到dataframe数据类型中,注意第一行作为索引,后面的作为数据
df = pd.DataFrame(data=aray[1:],columns=aray[0])
print(df)
#第四步是将dataframe转为csv
df.to_csv('随便16.csv',index=False, encoding='GB18030')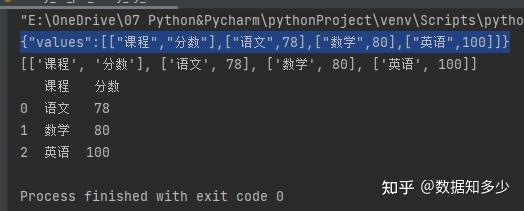
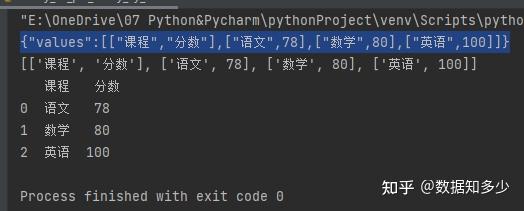
石墨开发人员推荐的Pandas JSON | 菜鸟教程
Pycharm专栏
同时打开并显示多个项目Project
PyCharm的官方介绍
python的Excel专题
How to write Python Array into Excel Spread sheet
Python专题
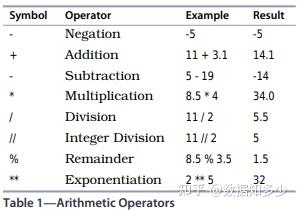


换行的两种方式,用括号或者用\,如下图


注释的几种方式,#号是注释用的,在一行的前面或后面都行
批量加注释或解除注释,用Ctrl+/,刚开始与QQ五笔的某个功能相冲突,删除了输入法的冲突快速字段,就正常了。
python批量注释的两种方法:1、选中要注释的代码,使用【Ctrl+/】快捷键多行注释;2、将需要注释的部分代码用三个双引号或者三个多引号括起来多行注释。
"""
这里面是注释
"""在Python中如何调用不同模块的四种方式
知乎Python进阶者:浅析Python模块的引入和调用/比较完整,但没有实例
知乎/槐夏:Python-模块和包/讲得详细,有例子,可学习
1)在Python中缩进要规范,不然老出错;2)中英文都知道的,而且一改名称,相关引用的位置都会修改模块的名称,模块就是个Python文件;3)注意name and main的用法;4)里面讲到“包”的用法,大意是将模块打个包以方便使用,还没有怎么学习。
总结Harry的办法:1)每个文件夹生成__init__.py这个文件。2)Mark Directory as NameSpace Package。3)在根目录下生成root。这样就可以方便在PyCharm中import时就可以自动调出来。
# 1. 导入模块
# 方式一(推荐)
import 模块名
# 方式二:一次性导入多个模块(不推荐)
import 模块名1, 模块名2...
# 2. 调用模块内的功能,注意前面的模块名不能省,否则出错。
模块名.功能名()
调用不同文件夹的函数时要注意的content root
# 1. 导入模块math:数学运算相关的模块
# 方法1:import 模块名
import math
# 2. 调用模块内的功能:模块名.功能名()
num = math.sqrt(4) # 开平方
print(num)
# 1. 导入模块和对应的功能名,这是一次在一个模块中调用多个函数的办法
from 模块名 import 功能名1, 功能名2, ...
# 2. 调用模块的功能名,不需要通过模块名来调用了
功能名()
# 1. 导入模块内部的所有功能:*表示所有的意思
from 模块名 import *
# 2. 调用模块的功能名,不需要通过模块名来调用了
功能名()
# 1. 模块定义别名
import math as mt
num1 = mt.sqrt(4)
print(num1)
# 2. 功能定义别名
from math import sqrt as st
num2 = st(4)
print(num2)
# 定义功能别名之后,再使用功能名就会报错,同理模块
print(sqrt(4))Configuring Project Structure | PyCharm
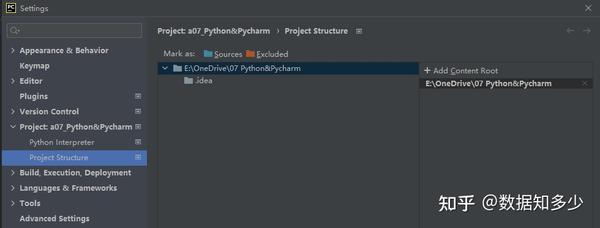
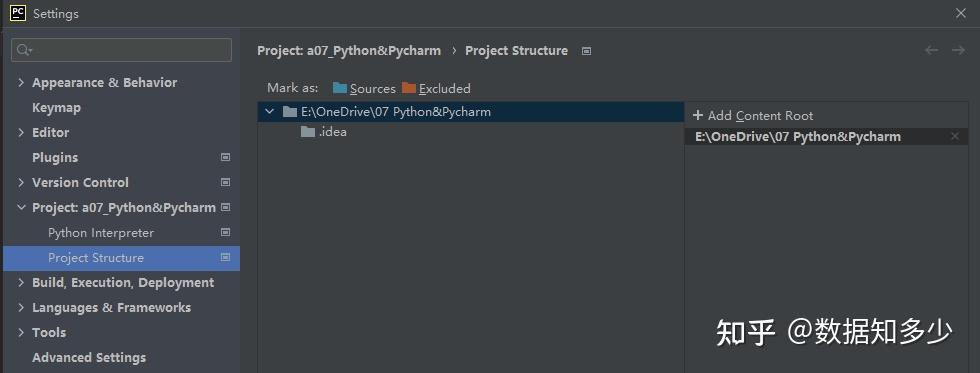
Python文件目录要怎样组织
Foo/
|-- bin/
| |-- foo
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py
| |-- main.py
|-- docs/