

Code Llama是怎样炼成的

8月24日,Meta在官网上发布了专为Coding调教的开源可商用的大语言模型——Code Llama,达到了和ChatGPT 3.5旗鼓相当的水平。不得不说Meta是深诣AI论文创新之道的,既然Generalization上比不上ChatGPT,那就划一个小领域练专精奇技淫巧和ChatGPT打个不相上下。
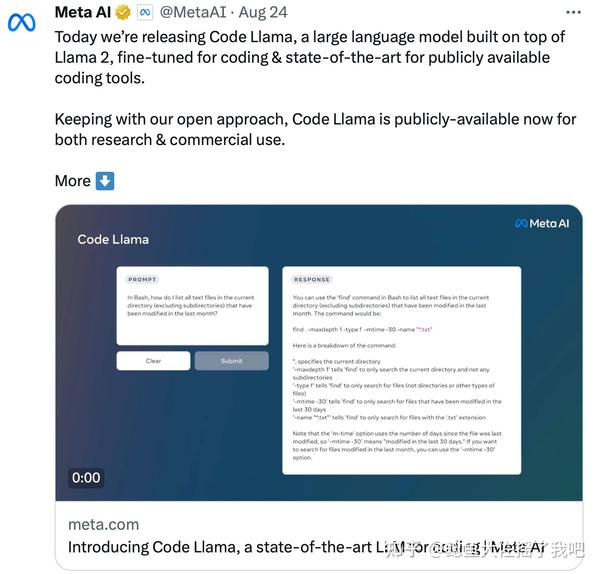
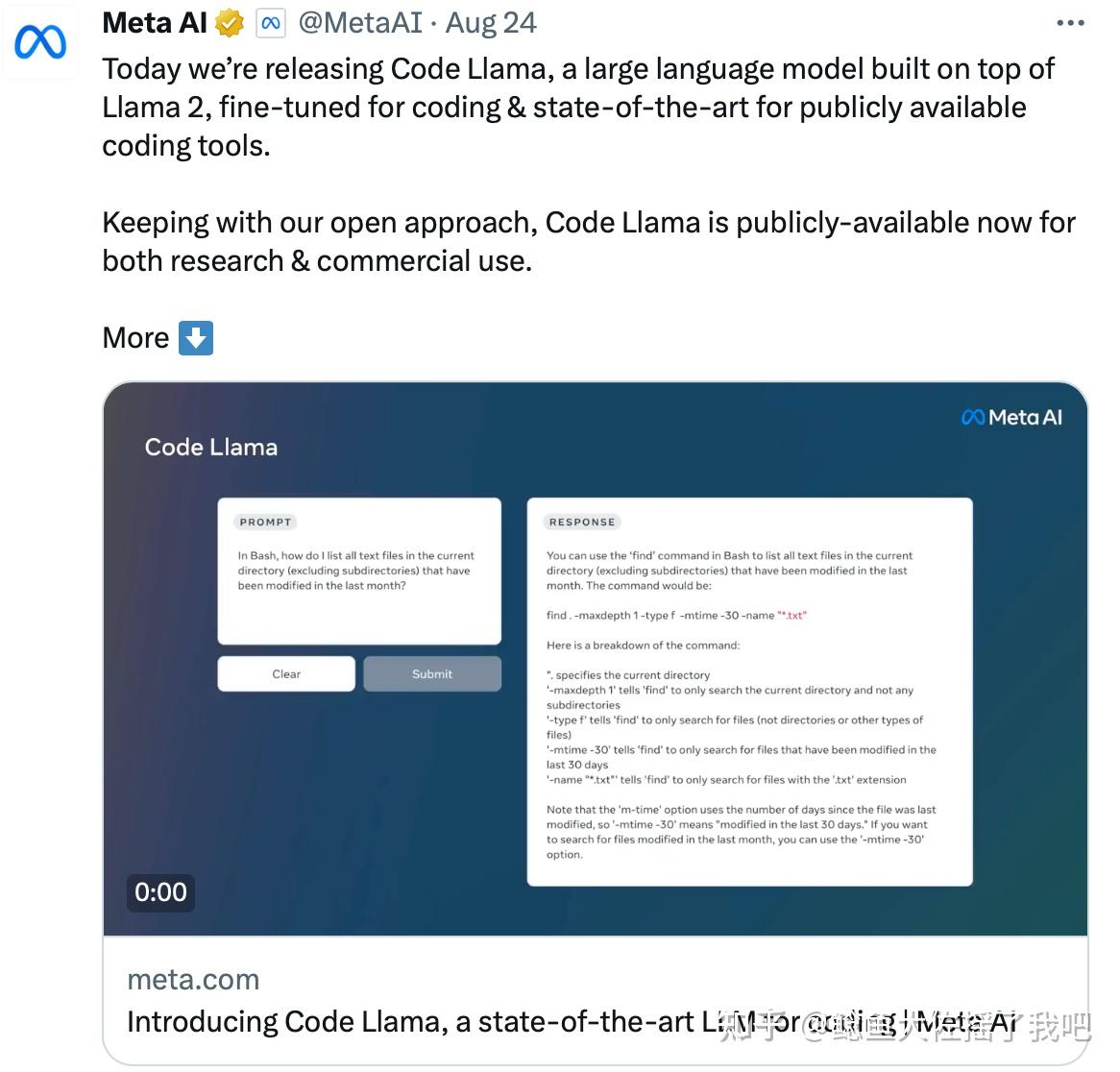
Code Llama使用Llama-2训练集中的代码数据集,基于Llama-2基础模型微调而来。和Llama-2相对应的,Code Llama有3种不同的参数规模的模型:7B、13B、34B,其中7B模型一张显卡就可以拿捏。并且,Code Llama针对不同的Coding需求还在为每个模型调出了三个版本:基础版、Python版、以及指令遵循。
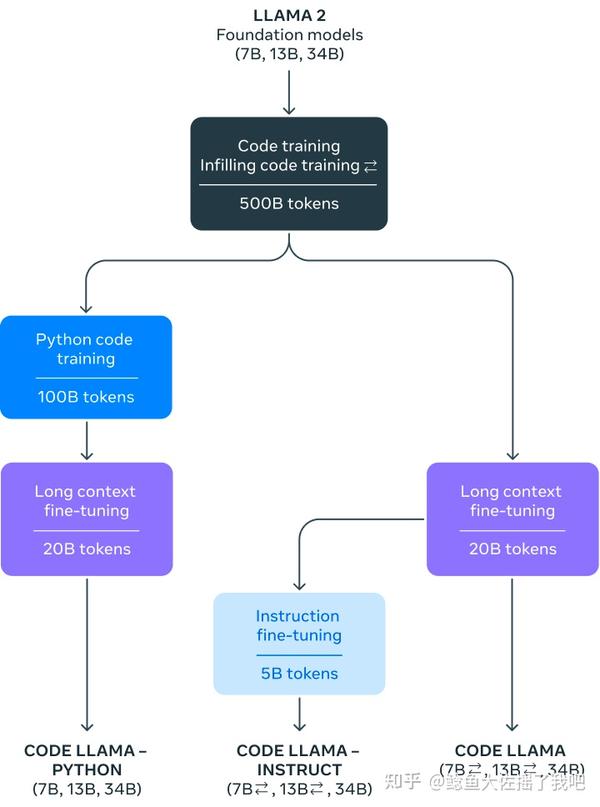
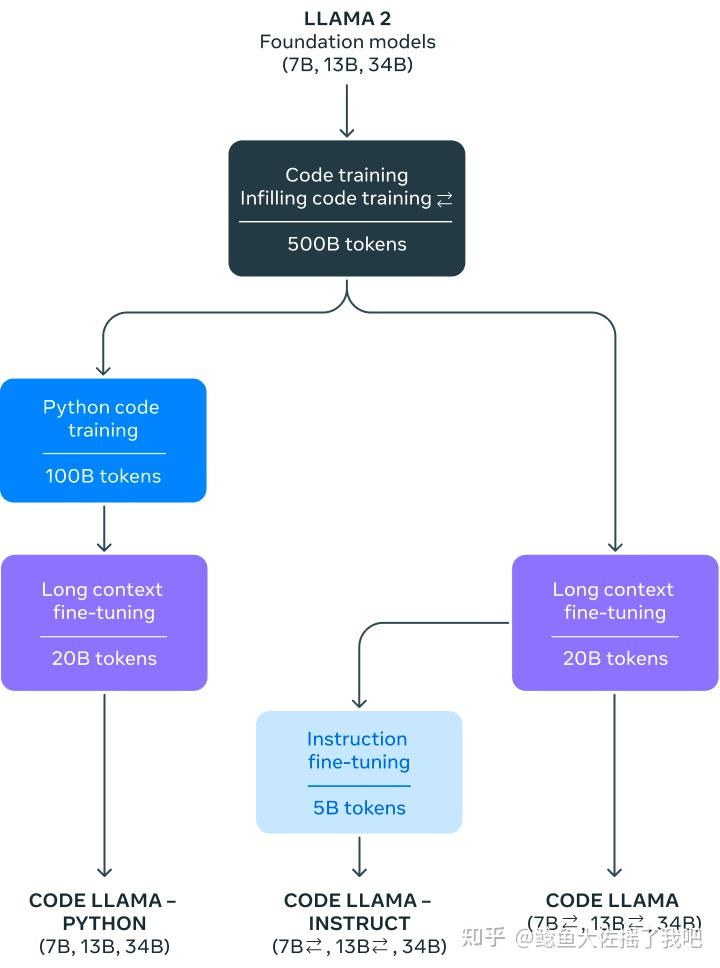
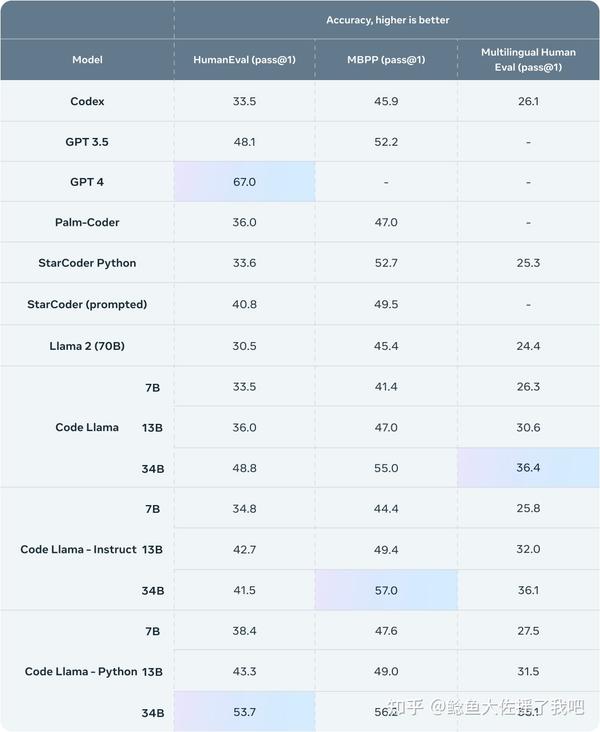
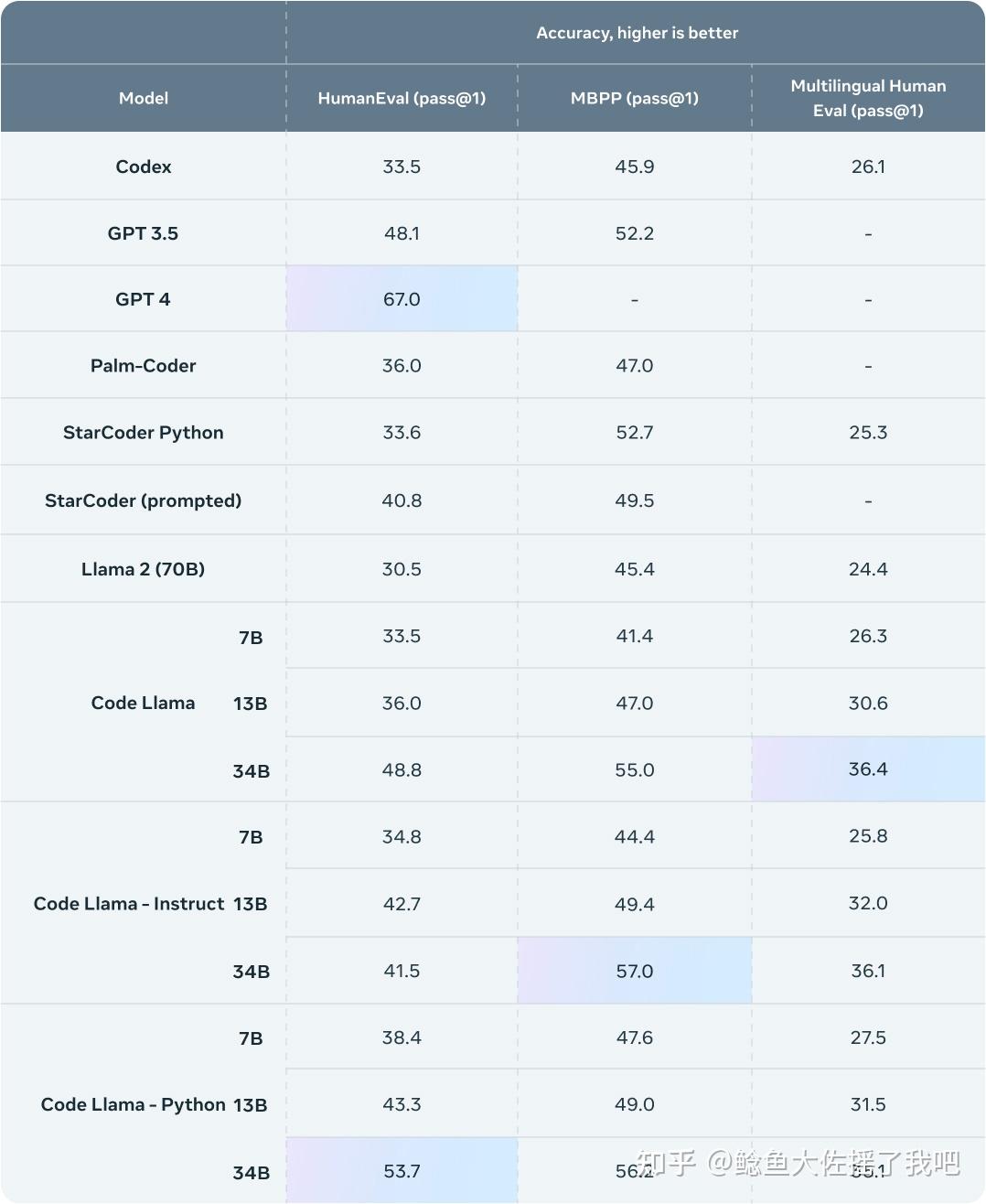
从官博公布的结果来看,Code Llama的性能与GPT 3.5打平,同时Code Llama Python 34B参数的模型在HumanEval指标上,相对接近GPT-4。
以上内容是来自官方博客的宣传,看完之后让人意犹未尽,所以Code Lamma的核心科技在哪里呢?答案就藏在官博侧边栏的Research Paper里。这篇Paper目前还没挂Arxiv,Meta开源工作不够到位啊。
和官博的结果相比,论文里还隐藏了一个效果更好的模型: Unnatural Code Llama ,一个名字让人摸不着头脑的模型。它有着媲美GPT 4的性能表现。
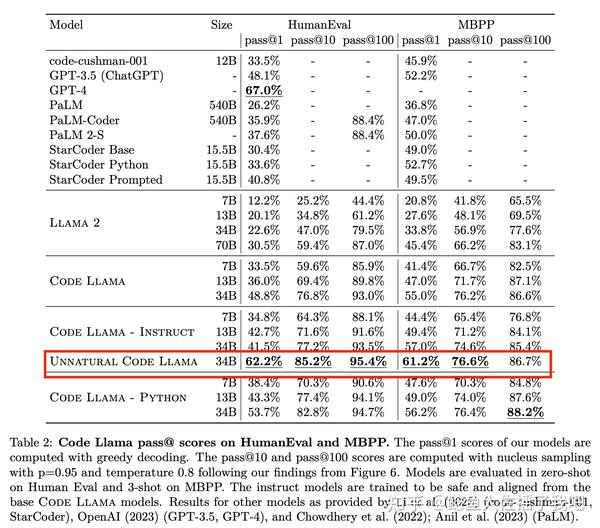
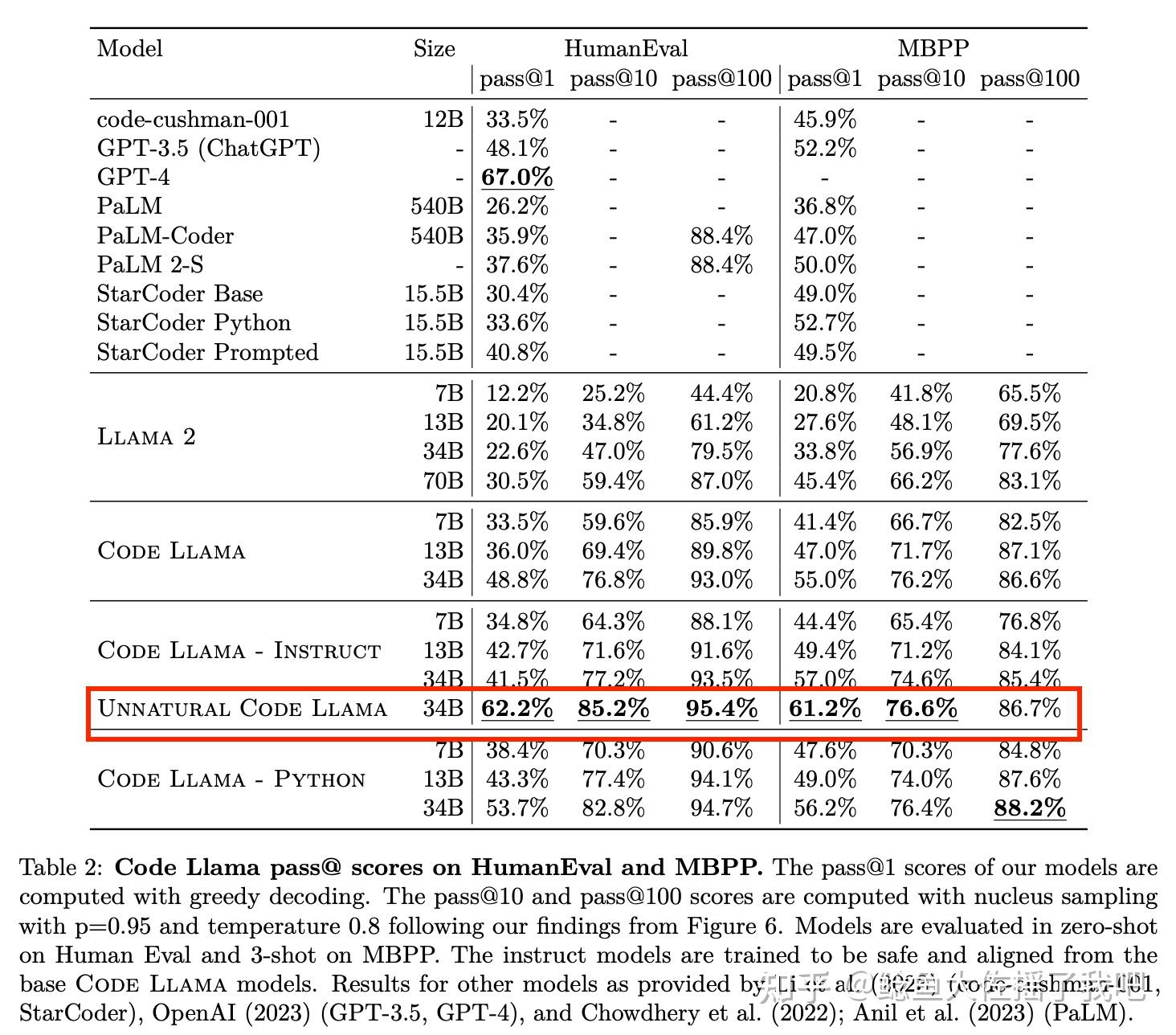
所以什么是Unnatural Model呢?我在3.4.2 Instruction Fine-Tuning找到了定义:


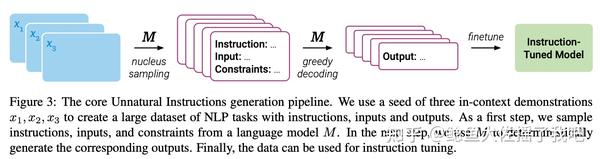
Unnatural Model的核心技术就是用seed instruction examples提示LLM生成更多的synthetic instruction examples,简而言之就是用LLM做数据增强。大概是因为Instruction是模型生成而不是人类撰写的,所以称为Unnatural吧。该技术源于Honovich等人2022年末在Arxiv公开的文章:Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor。
在这篇文章里作者提出了一个数据生成Prompt,用三个Instructions示例提示LLM生成出第四个示例,在没有人工参与的情况下收集了64,000个样本。然后,通过提示模型对每个Instruction重新措辞来扩展数据,创建总共约240,000个Instruction、Input和对应的Output。



虽然原文基于T5调教的结果和基线方法相比旗鼓相当,在部分评价任务上达到SOTA效果,但其改进远没有在Code Llama上那么惊艳。
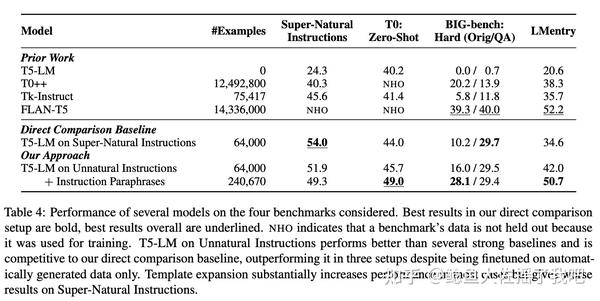
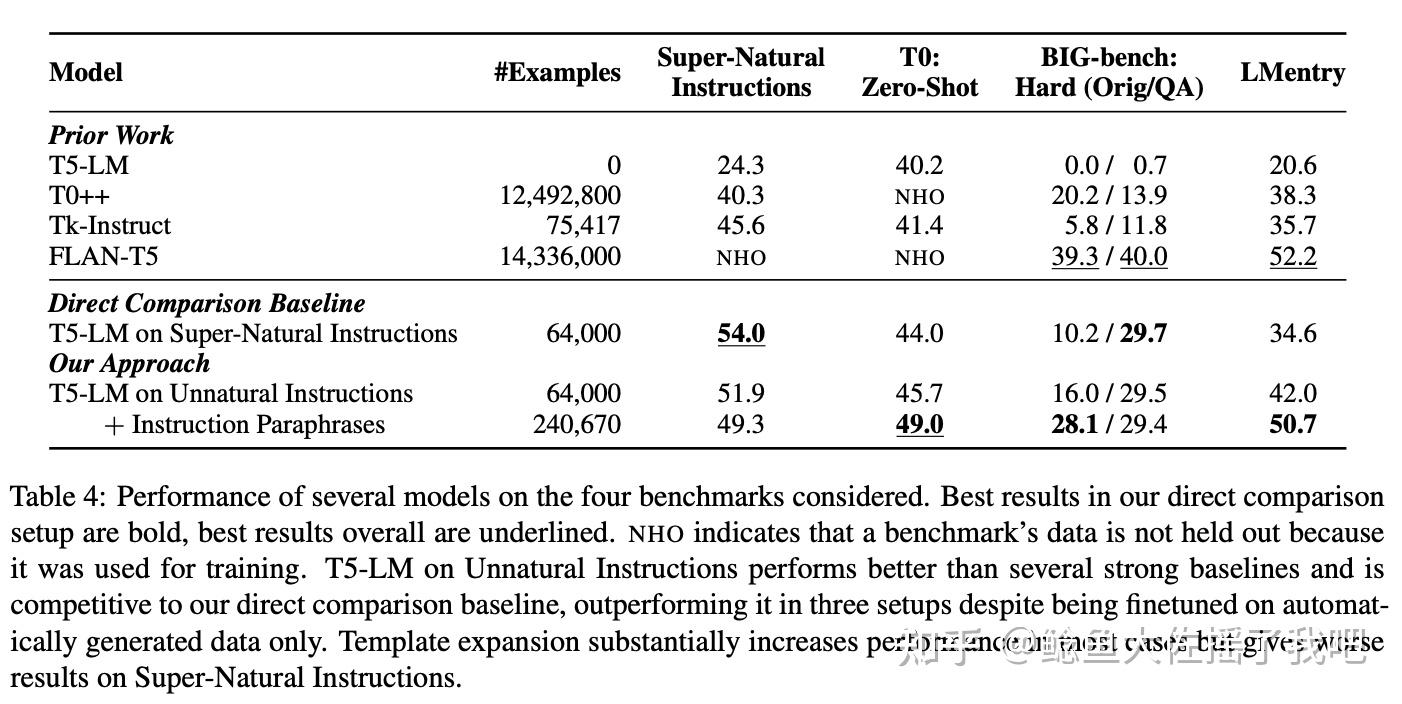
这么看来在Coding任务上AI相比于人类更懂得调教AI,Synthetic Data才是LLM发展的未来啊。但之前也有文章驳斥说用AI训练AI会出现灾难性的退化。究竟谁对谁错暂时无法定论,坐看神仙打架。
