《Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network》是Wenzhe Shi等人于2016年提出的一种新的SR重建方法,发表于CVPR,在单图像和视频超分辨率上再次表现出了更加良好的速度与性能。
该文章的两个突出贡献:
1、直接将LR图像送入网络进行重建,并在网络的最后一层进行上采样,分辨率和滤波器大小的减少大大降低了计算和内存复杂度;
2、对于L层的网络,学习
 个特征图对应的
个上采样滤波器。与在网络开始使用一个固定的滤波器相比,网络能够更好地学习到更复杂的LR到HR映射。
个特征图对应的
个上采样滤波器。与在网络开始使用一个固定的滤波器相比,网络能够更好地学习到更复杂的LR到HR映射。
网络结构如下图所示:
网络结构:
◇ ESPCN设置网络层数为4,前三层为隐藏层,最后一层为亚像素卷积层;
◇ 隐藏层为普通的CNN卷积,第一层使用64个大小为1×5×5的卷积核,步长为1,padding=2;第二层使用32个大小为64×3×3的卷积核,步长为1,padding=1;第三层的输出通道数为放大因子r的平方(也即滤波器的个数),大小为3×3,步长为1,padding=1;
◇ 亚像素层将像素进行重新排列得到高分辨率图。
图像网络:91-images(训练集),Set5和Set14(测试集)、BSD300(100张图片)和BSD500(200张图片)(测试集)最终模型使用来自ImageNet的50000张随机选择的图像进行训练。对于每个上采样因子训练一个特定的网络。
视频网络:公开的Xiph数据库中的1080p高清视频(包含8个高清视频的集合,长度约为10秒,分辨率为1920×1080)、Ultra Video Group数据库(包含7个分辨率为1920×1080,长度为5秒的视频。)
数据预处理:
训练阶段首先从HR图像中提取17r×17r大小的子图像(r为放大因子),为了生成初始LR图像,对HR图像使用高斯模糊,并通过放大因子对其进行降采样,子图像以
 ×r的步幅从HR图像中提取,并以
的步幅从LR图像中提取,以确保原始图像中的所有像素出现一次。
×r的步幅从HR图像中提取,并以
的步幅从LR图像中提取,以确保原始图像中的所有像素出现一次。
实验中LR图片尺寸裁剪为大小
 的中心像素,之后再通过双三次插值缩小r倍;对应的HR图像大小为
。
的中心像素,之后再通过双三次插值缩小r倍;对应的HR图像大小为
。
def calculate_valid_crop_size(crop_size, upscale_factor): # 计算有效切割尺寸
return crop_size - (crop_size % upscale_factor)
def input_transform(crop_size, upscale_factor): # 输入图片切割
return Compose([
CenterCrop(crop_size), # 将图片进行中心切割得到给定size大小图片
Scale(crop_size // upscale_factor, interpolation=Image.BICUBIC)
]) # 将图片使用双三次插值法缩小scale倍
def target_transform(crop_size): # 标签图片切割
return Compose([
CenterCrop(crop_size)
参数设置:
实验使用tanh激活函数。设置迭代次数epoch为100,初始学习率设置为0.01,最终学习率设置为0.0001,在损失函数小于阈值µ时逐步更新。使用PSNR作为性能指标。
网络实现:
class Net(nn.Module):
def __init__(self, upscale_factor):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))
self.conv2 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))
self.conv3 = nn.Conv2d(32, 1 * (upscale_factor ** 2), (3, 3), (1, 1), (1, 1))
self.pixel_shuffle = nn.PixelShuffle(upscale_factor)
def forward(self, x):
x = F.tanh(self.conv1(x))
x = F.tanh(self.conv2(x))
x = F.sigmoid(self.pixel_shuffle(self.conv3(x)))
return x
由于笔记本硬件条件有限,num_workers改为0后每个mini-batch有16700/64=261张图片,共需100个epoch,训练时间较长,且源代码没有提供训练好的模型,所以仅训练了10个epoch,重建效果较差,故在此不展示复现后的重建结果,使用论文中的结果。
PS:pytorch中的反卷积函数nn.PixelShuffle(n)——一种通道合并的上采样方法
输入size:( N , C × 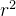 , H , W )
, H , W )
输出size:( N , C , H × , W × )
《Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network》是Wenzhe Shi等人于2016年提出的一种新的SR重建方法,发表于CVPR,在单图像和视频超分辨率上再次表现出了更加良好的速度与性能。
这篇文章推出了一种具有亚像素卷积层结构的SR算法——ESPCN;相比于SRCNN直接对HRHRHR领域像素做卷积,ESPCN是直接对输入LRLRLR像素做特征提取,在当时来说,可以算是一种提高计算效率的有效途径。
参考文档:
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural NetworkAbstract1 Introduction2 Method2.1.
cvpr2016
论文下载:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
代码:https://github.com/leftthomas/ESPCN
ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。网络的输入是原始低分辨率图像,通过三个卷积层以后,得到通道数为放大倍数**2的与输
Real-Time Single Image and Video Super-Resolution Using an EfficientSub-Pixel Convolutional Neural Network
我挑选了论文中最有趣的部分翻译并加上了自己的理解
Abstract
最近,几种基于深度神经网络的单张图片超分辨率重构方法在重构精确度和计算性能上都取得了突破性的进步。在那些方法中,输入的...
cvpr2016
论文下载:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
代码:https://github.com/leftthomas/ESPCN
ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。网络的输入是原始低分辨率图像,通过三个卷积层以后,得到通道数为放大倍数的立方的与输
ESPCN(Efficient Sub-Pixel Convolutional Neural Network)网络是用于super-resolution task的网络,super resolution的task训练时一般是用原图片作为label,然后用原图resize成的更小的图片作为输入,让网络学习怎么去还原这个resize的过程。
ESPCN全过程:
对于一堆的训练集图片,将其首先crop成128*128的大小,然后将它缩小4倍,变成32*32的大小(注意是缩小,不是裁剪crop),将这个...

