


influxDB 学习笔记

influxDB 学习笔记
官方文档:
https://
docs.influxdata.com/inf
luxdb/v1.8/
目录:
一、influxDB
- 简介
- 示例
- 词汇说明
- influxDB下载与安装
- influx CLI
二、influxQL
-
查询
1)常用
2)SELECT
3)WHERE
4)GROUP BY
5)INTO
5)LIMIT - 数据库管理
- 连续查询
- Functions
一、influxDB
1. 简介
InfluxDB 是一个由 InfluxData 开发的开源时序型数据库。使用 GO 语言开发,特别适合用于处理和分析资源监控数据这种时序相关数据。InfluxDB 被广泛应用于存储系统的监控数据,IoT 行业的实时数据等场景。
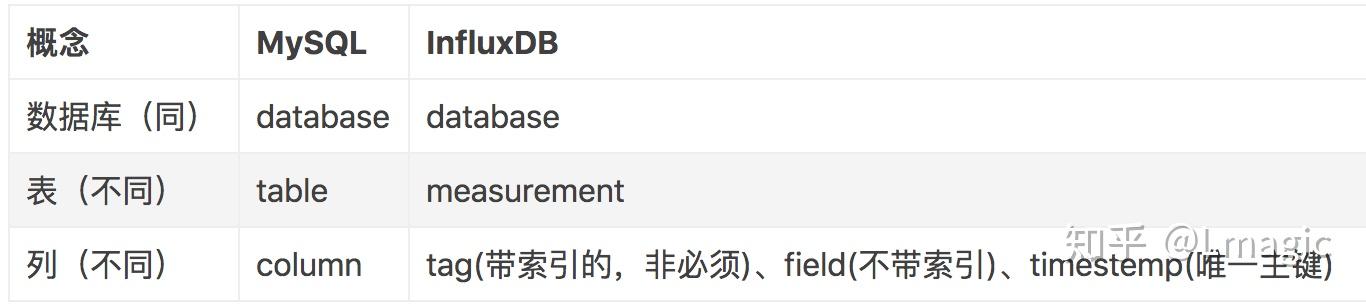
influxDB 与 MySQL 的对比:
InfluxDB 目的是存储大量时间序列数据,并对这些数据快速执行实时分析。
influxDB 支持多种查询语言:Flux 和 influxQL。
influxDB 不是 CRUD,通常来说 influxDB 中的数据来自分布式传感器组、网站的点击数据和性能监控数据和金融交易列表数据等,这些数据需要聚合之后才会更有用。

2. 示例
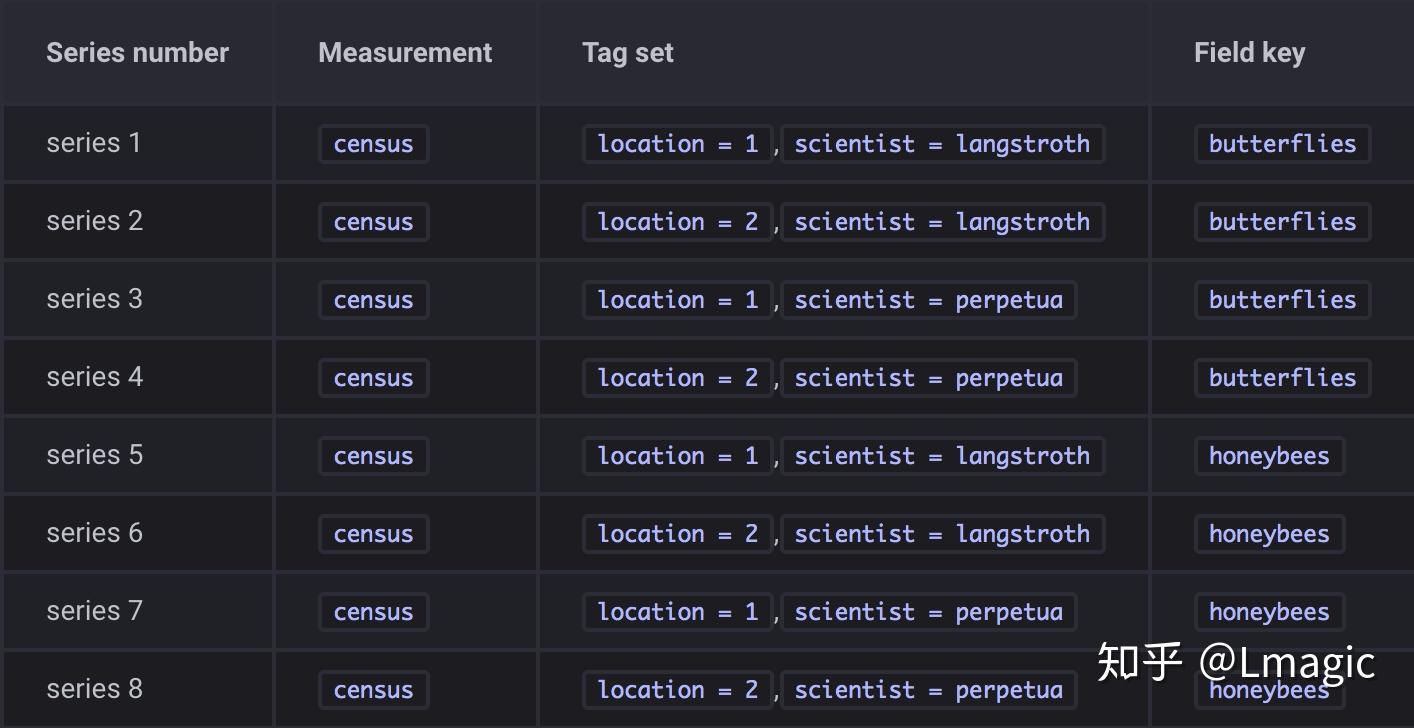
如下示例是两位科学家在两处位置记录的蜜蜂和蝴蝶的数量,数据存储在 census 表中:
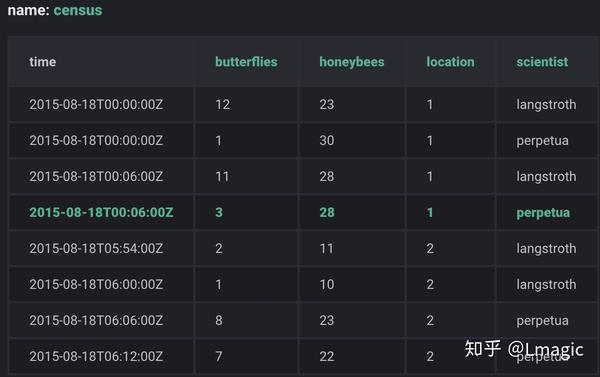
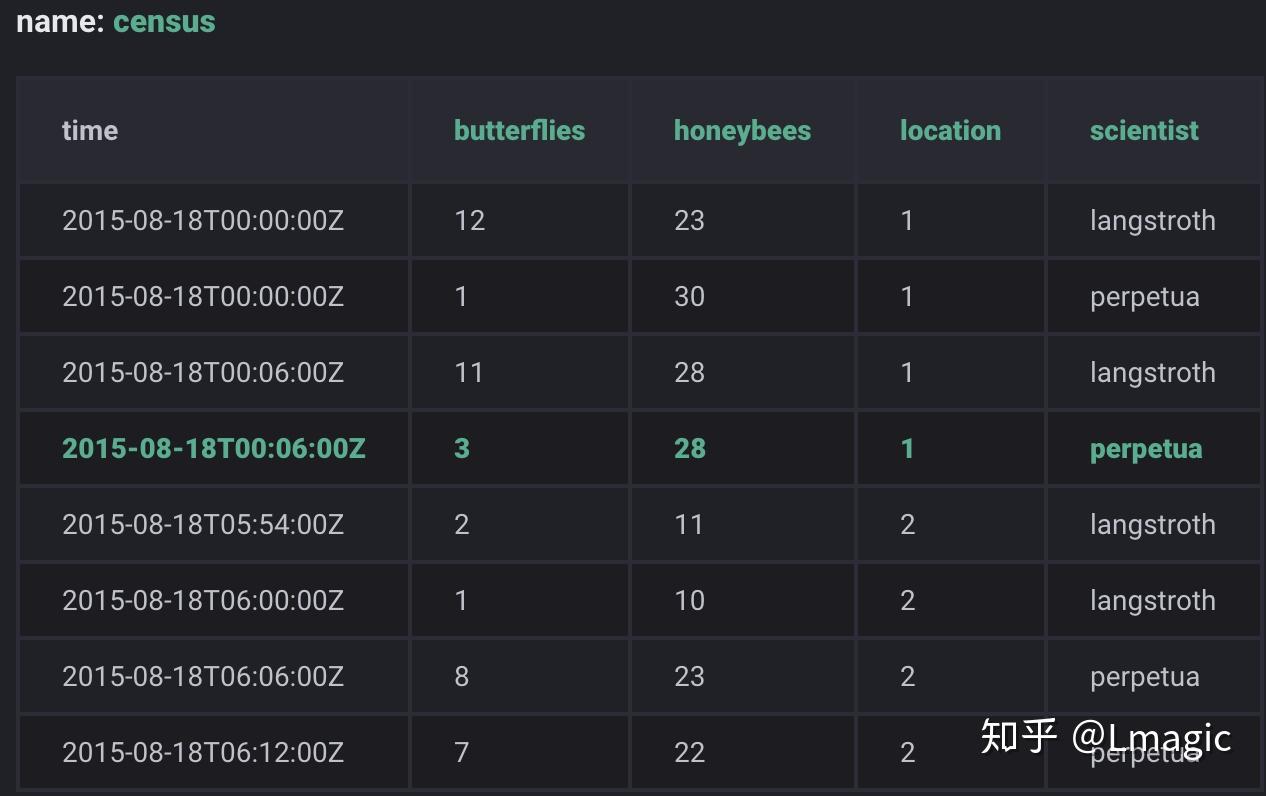
1)所有的 influxDB 数据库表中都有
time
这一列,其存储时间戳。
2)butterflies 和 honeybees 这两列是字段(
fileds
)。字段由字段键(filed keys)和字段值(filed values)组成。filed key 是 string 类型,filed values 就是存储的数据,可以是string、float、integer、boolean。filed set 是 filed keys 和 filed values 的组合。
3)location and scientist 这两列是标签(
tags
)。tags 由 tag keys 和 tag values 组成。tag keys 和 tag values 都是 string 类型,记录元数据( metadata)。tag key location 有两个值:1、2,tag key scientist 也有两个值:langstroth、perpetua。tag set 是 tag 不同 key-value 的组合。
4)tag 是可选的,且被索引,意味着 tag 查询 比 filed 查询更快。
5)
measurement
是 fileds、tags 和 time 的容器,可理解为 SQL 中的 table 表。在这个示例中就是 census 表,表名类型为 string。一个 measurement 可以有不同的保留策略(retention policies),即数据保留多长时间(DURATION)、以及数据在集群中存储多少副本(REPLICATION)。
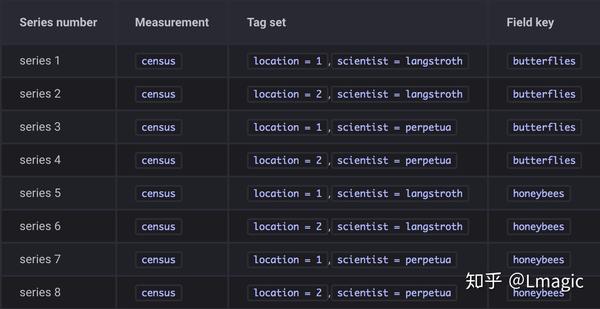
6)
series
是点的集合,由 measurement、tag set、filed key 组成。在这个示例中,就有 8 个 series:
3. 词汇说明
1)filed
字段(fileds)由字段键(filed keys)和字段值(filed values)组成。存储元数据和实际记录的数据,不被索引,所以针对 filed 的查询,查询性能不佳。
2)field key
是 string 类型,存储元数据(metadata)。
3)field value
可以是 string、float、integer、boolean 类型,存储实际的数据。
4)measurement
是 fileds、tags 和 time 的容器,可理解为 SQL 中的 table 表。
5)metastore
包含系统状态的内部信息,包括用户信息、数据库、保留策略、shard metadata、连续查询和订阅。
6)now()
获取本地服务器纳秒级时间戳。
7)point
表示单行数据记录,类似于 SQL 数据库表中行。
包含:a measurement, a tag set, a field key, a field value, and a timestamp。由 series and timestamp 唯一标识。
8)series
由 measurement、tag set、filed key 组成。同一个 series 的数据在物理上会按照时间顺序存储在一起。
9)tag
InfluxDB 数据结构中记录元数据的键值对。tags 由 tag keys 和 tag values 组成。tag keys 和 tag values 都是 string 类型,记录元数据( metadata)。tag 是可选的,且被索引,对 tag 查询是高效的。
10)timestamp
与 point 关联的时间戳。InfluxDB 中的时间都是 UTC 标准。所有的 influxDB 数据库表中都有 time 这一列。
11)batch
points 数据点的批量集合,减少http请求,是的inluxDB API 写入性能更高。
12)bucket
数据存储的位置,与数据库和保留策略相关。
13)continuous query(CQ)
连续查询。一个 influxQL 查询,该查询会在数据库中自动并定期运行。
在 SELECT 语句需要一个函数,且必须包含 GROUP BY time() 语句。
14)database
数据库。是 users、retention policies、continuous queries、time series data 的逻辑容器。
15)aggregation
是一个 influxQL 函数,返回一组 points 的聚合值。
influxQL 的其他函数:
https://
docs.influxdata.com/inf
luxdb/v1.8/query_language/functions/#aggregations
4. influxDB v1.8 下载/安装
下载地址:
https://
docs.influxdata.com/inf
luxdb/v1.8/introduction/download/
mac OS 下载:
brew update brew install influxdb
配置:
influxd -config /etc/influxdb/influxdb.conf
5. influx CLI
前提是本地已安装 InfluxDB open source
1)进入交互式 CLI:
$ influx -precision rfc3339
2)创建数据库
$ CREATE DATABASE mydb
3)查看所有的数据库:
SHOW DATABASES
4)使用特定的数据库(后续命令都是基于该数据库)
USE mydb
5)插入数据
INSERT cpu,host=serverA,region=us_west value=0.64
6)查询数据
SELECT "host", "region", "value" FROM "cpu"
二、InfluxQL
InfluxQL 是一种类似 SQL 的查询语言,用于与 InfluxDB 中的数据交互。
1. 查询
1)常用
官方文档:
https://
docs.influxdata.com/inf
luxdb/v1.8/query_language/explore-schema/
常用查询数据库相关语句:
-- 查询数据库
SHOW DATABASES
-- 查询数据库中的保留策略
SHOW RETENTION POLICIES [ON <database_name>]
-- 查询数据库中的 series 列表
SHOW SERIES [ON <database_name>] [FROM_clause] [WHERE <tag_key> <operator> [ '<tag_value>' | <regular_expression>]] [LIMIT_clause] [OFFSET_clause]
-- 查看所有的 measurement 表
show measurements;
-- 查看一个 measurement 中所有的 tag key
show tag keys
-- 查看一个 measurement 中所有的 field key
show field keys
常用查询数据相关的语句:
-- 查询表中某个 filed key 非空的数量
SELECT COUNT("filed key名称") FROM measurement表名
-- 查询10条数据
select * from measurement_name limit 10;
2)SELECT
语法:语句中必须包含 field_key。
SELECT <field_key>[,<field_key>,<tag_key>] FROM <measurement_name>[,<measurement_name>]
-- 返回所有 fields 和 tags
select * FROM <measurement_name>